
基于机器学习实现海上气田陆地终端液态产品产量预测与挖潜
2020-03-10 13:52羊新州闫正和罗睿乔唐圣来
石油天然气学报 2020年4期
羊新州,闫正和,罗睿乔,杨 鹏,唐圣来
中海石油深海开发有限公司,广东 深圳
1.引言
南海某天然气陆地处理终端处理来自海上5 个气田产量的天然气,装置设计天然气处理能力达到80 亿方/年。上岸天然气经过脱碳、脱水等处理之后,进入液烃分馏单元,实现重烃组分分离之后,外输干气。分离的重烃组分经过多级分馏,产出不同种类液烃产品。常规副产品的预测往往是通过简单的线性回归进行计算,忽视了设备故障、参数波动、环境变化等因素的影响,预测结果与实际副产品的产量存在一定差异。机器学习是一种用于设计复杂模型和算法并以此实现预测功能的方法,它由数据分析习得,而不依赖于规则导向的程序设计,它能够基于对现有结构化数据的观察,自行识别结构化数据中的模型,并以此来输出对未来结果的预测。通过建立可靠的机器学习模型,使计算机从数据中自动分析出相关规律,并利用这些规律对未来的变化进行预测,该方法已经在油气行业的各个方向进行了广泛的应用[1]-[10]。本文通过建立机器学习模型来学习各海上气田产量与终端各对应副产品产出的相关关系,识别出影响副产品产出的关键设备,继而对关键设备进行异常标注,以提高副产品产量预测的准确度。
2.终端液态产品处理设备异常标记
多个海上气田开采出的天然气在海上中心平台进行简单的脱水处理后,通过海底管道输送到终端,由海管登陆的天然气首先在天然气进站预处理单元经调压系统稳压后,进入段塞流捕集器进行气液分离。分出的凝液去凝析油稳定单元处理,生产稳定凝析油,稳定后的凝析油进入储罐储存,可装船或装车外输,亦可通过管道外输至精细化工;分离出的气相脱除夹带的微量汞和机械杂质后进入脱碳单元,脱碳后的湿净化气的CO2含量控制在2.8%以下,随后进入两套并联的脱水、制冷、分馏单元处理,生产干气、丙烷、丁烷、液化石油气及稳定轻烃产品,干气通过天然气管道外输至广东管网,丙烷、丁烷、液化石油气、轻烃等液态产品进入储罐储存,可装船或装车外输,相关工艺流程见图1 所示,其中,可以简单将副产品划分为2 类,一为凝析油产品,一为丙烷、丁烷、轻烃等的液态烃类产品。
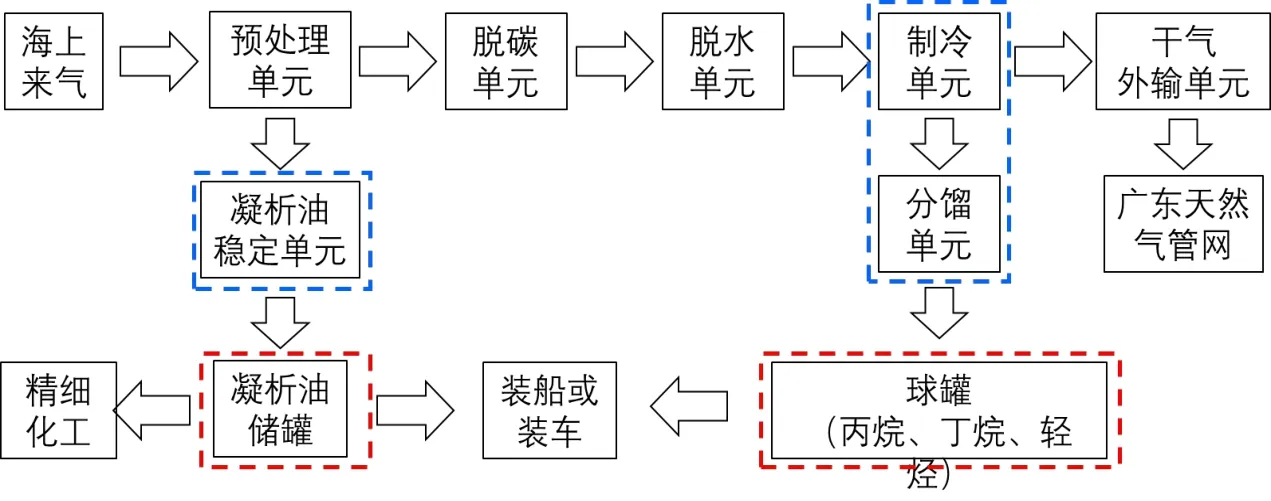
Figure 1.Schematic diagram of processing flow of natural gas processing terminal图1.天然气处理终端处理流程示意图
聚类算法是指将一堆没有标签的数据自动划分成几类的方法,属于无监督学习方法[11][12][13]。一般的天然气藏在一定时间范围内,副产品的产量与天然气的产量比是一个相对稳定的值,当天然气产量一定时,对应的副产品产量接近一个定值,当副产品产量明显偏离这个定值时,则判断为设备出现了异常。本文通过收集海上各平台和陆地终端生产数据,经过聚类分析,划分出副产品产量的异常点。
本文采用K 均值聚类算法,其步骤是,将各类副产品析出系数分为2 组,随机抽取2 个对象作为初始的聚类中心,然后将每个对象与2 个中资聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。本文将该方法应用于终端及上游气田凝析油和液态烃类产品析出系数的异常判断,通过分析该终端及上游气田19 年1 月至2020 年5 月生产数据,判断结果如图2 和图3 所示。其中,在2019 年12 月,烃类产品的析出能力发生显著降低,通过对比设备工况,当时制冷单元设备出现异常,制冷效率为达到设定值,导致烃类产品产出量减少。可见,通过K 均值聚类算法可以有效识别副产品的析出能力异常。
3.终端液态产品产量预测
根据上述分析和现场对处理设备的异常标记,应用气田与终端的生产数据作为训练数据,用以预测2020 年1 月至2020 年5 月的副产品的产量。建模过程如图4 所示。
3.1.数据预处理
从图1 可知,天然气从海上各气田采出输送到终端后,整个处理流程中,除了脱碳系统有化学反应以外,其余工艺基本以物理变化为主。上岸天然气经过脱碳、脱水等处理之后,进入液烃分馏单元,实现重烃组分分离之后,外输干气。分离的重烃组分经过多级分馏,产量不同种类液烃产品。因此本次建模的初始特征选择海上5 个气田的井口气产量和终端设备异常标记值,用以预测终端各副产品的产量。

Figure 2.Scatter diagram:abnormal judgment of liquid hydrocarbon products precipitation图2.液态烃类产品析出异常判断

Figure 3.Scatter diagram:determination of condensate output anomaly图3.凝析油产量异常判断

Figure 4.Process:the modeling process of predictive liquid hydrocarbon and condensate图4.副产品预测建模预测流程
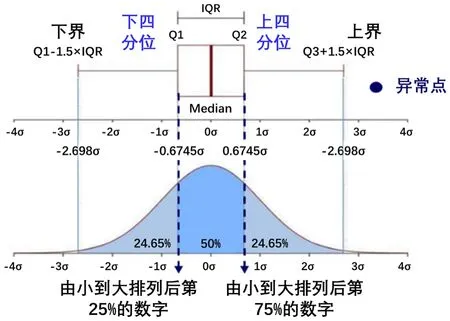
Figure 5.Curve:apply box diagrams for outliers determination图5.应用箱型图进行异常值处理
应用箱型图来对各气田产量进行异常值判断,如图5 所示。箱型图,主要包含六个数据节点,将一组数据从大到小排列,分别计算出他的上边缘,上四分位数Q3,中位数,下四分位数Q1,下边缘,还有一个异常值。它也可以粗略地看出数据是否具有对称性,分布的分散程度等信息,特别可以用于对几个样本的比较,无需对数据进行正态分布要求。异常值在箱型图中被定义为小于Q1 − 1.5IQR 或大于Q3 +1.5IQR 的值,经过异常值处理后的气田群产量数据集如表1 所示。
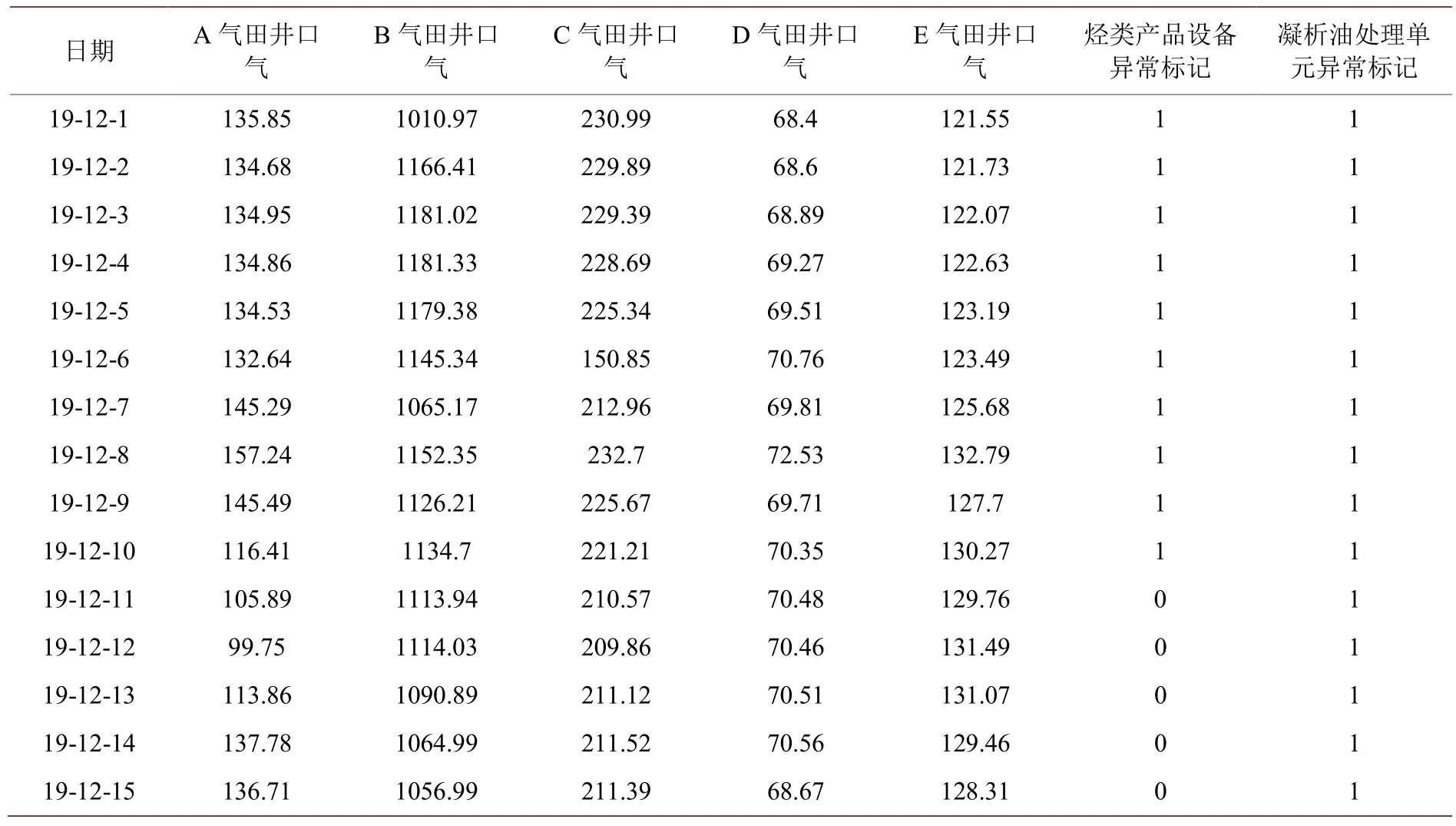
Table 1.Data set after outlier processing表1.异常值处理后数据集
为进一步提取数据集的相关特征,我们对各气田产量结合异常标记进行稀疏化处理,通过稀疏化实现特征的自动选择,去除影响最终预测的无用特征,即将无用特征对应的权重设置为0,以凝析油数据集为例,数据稀疏化后处理结果见表2。
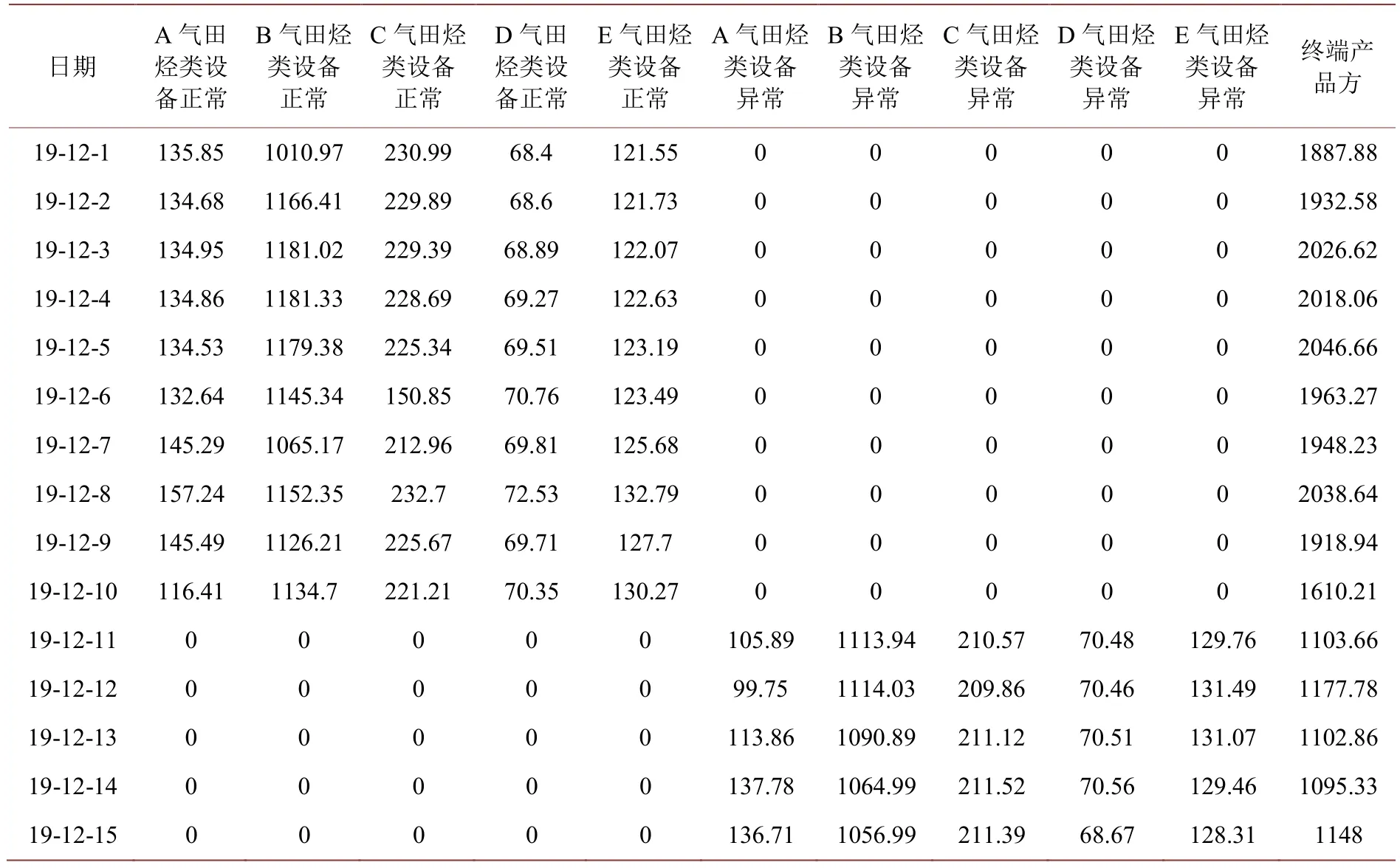
Table 2.Modeling data set for predicting hydrocarbon product output after data sparsity表2.数据稀疏化后预测烃类产品产量建模数据集
最后,选择2019 年的生产数据作为训练集,2020 年的生产数据做测试集,进行机器学习建模。
3.2.机器学习建模
将终端凝析油产量与终端液烃产品分开进行预测,对上述产品的预测即为一个回归问题,假设训练集样本T={(x1,y1),(x2,y2),…,(xN,yN)},需要回归(x1,x2,…,xN)与(y1,y2,…,yN)之间的关系。用于回归的机器学习模型有很多,常用的有多元线性回归、支持向量回归、决策树回归、神经网络等,本次选取多元线性回归与梯度提升决策树进行回归预测。
在多元线性回归分析中,如果有两个或两个以上的自变量,其方程形式为:

其中自变量的观测值为(1,x11,…,x1p),(1,x21,…,x2p),…,对应的因变量观测值为y1,y2,…,通过引入矩阵来表示:

多元回归即是需要求得相应的参数β,使得训练集的预测值与真实的回归目标值之间的均方误差最小。
提升树是迭代多棵回归树来共同决策,提升树模型可以表示为决策树的加法模型,计算方法如下:
1) 初始化提升树模型f0(x)=0
2) 对m=1,2,…,M
a) 计算残差
b)rmi=yi−fm−1(xi),i=1,2,…,N
c)拟合残差rmi学习一个回归树,得到 T (x:Θm)
d)更新fm(x)=fm−1(x) +T(x:Θm)
分别应用上述2 个方法对2019 年的生产数据进行训练,然后通过2020 上半年的气田生产数据预测终端液烃产品和终端凝析油的产量,结果如图6、图7 所示。
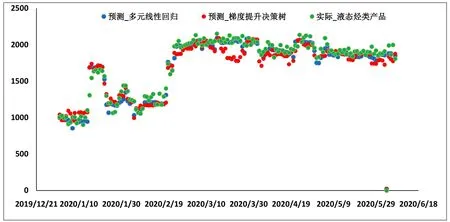
Figure 6.Scatter diagram:comparison between prediction of terminal hydrocarbon products and actual production图6.2020 年预测终端烃类产品与实际对比
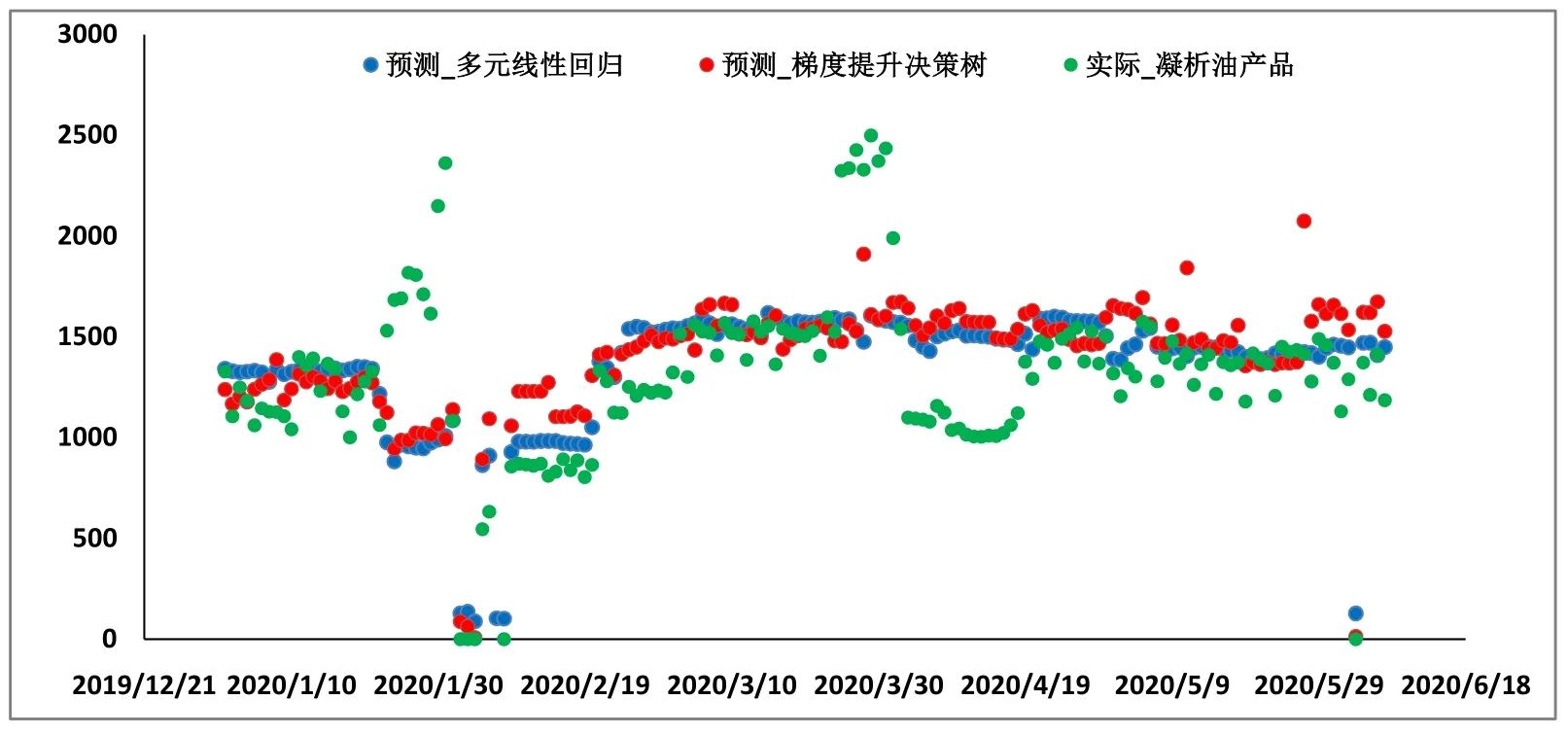
Figure 7.Scatter diagram:comparison between prediction of condensate oil and actual production图7.2020 年预测终端凝析油与实际对比
由图6 可以看出,无论是采用多元线性回归还是梯度提升决策树回归,预测的结果与终端烃类产品实际产量相一致。相比较来说,采用多元线性回归的方法更能准确的反应实际的产量波动。由图7 可知,部分计算结果与终端凝析油的产量存在一定的差异,经过与现场核实,该波动主要是由于现场操作的改变,主动降低了凝析油稳定单元的液位导致的。截止到2020 年6 月,预测的累积凝析油产量,液态烃类产品产量与实际产量对比见图8。

Figure 8.Histogram:comparison between prediction of cumulative production and actual cumulative production图8.预测累积产量与实际累积产量对比
4.终端液态产品产量潜力挖掘
根据对终端设备异常统计,2020 年液态烃类处理设备的异常已经出现了15 天,每年凝析油处理设备的异常约为10 天,因此,我们可以在预测模型中人为的修改设备的异常标记,假设在设备运作完好的条件下,结合年度的产量计划,预测最优运行条件下的液态烃类产品与凝析油的产量,各气田的年度产量计划如表3 所示。

Table 3.Annual production plan for each gas field表3.各气田年度产量计划
分别计算两种条件下终端各液态产品,计算结果如表4 所示,可以看出,最优运行条件下比现有的液态产品产量总计大约增加了2.26 万方,约为14 万桶,按30 美元/桶原油计算,可增加经济效益420 万美元。

Table 4.Optimal production of liquid products under operating conditions表4.最优工况条件下液态产品产量
5.结论
1) 通过聚类分析进行析出比异常判断可以迅速定位出终端设备的异常情况,结合后续对终端相关设备的异常标记,建立机器学习模型,可以精确预测各类液态产品产量。
2) 通过训练好的机器学习模型,可以进行终端液态产品生产潜力挖掘,预测在设备运行最优条件下液态产品产量,预测后的结果可以为后续进行设备升级改造,或者进行工艺优化提供决策依据。
猜你喜欢
中国生殖健康(2020年4期)2021-01-18
——彗星猎手的副产品
奥秘(创新大赛)(2020年1期)2020-05-22
英语文摘(2020年12期)2020-02-06
科技创新与应用(2018年4期)2018-01-31
中学生数理化·高二版(2017年3期)2017-07-07
中学生数理化·高二版(2017年3期)2017-07-07
领导文萃(2016年12期)2016-06-24
中国新技术新产品(2014年13期)2014-08-26
