
中亚留学生汉语有标因果类复句习得难度考察
2022-06-09 02:47张恒君
焦作大学学报 2022年2期
张恒君 黄 清
(1.河南师范大学文学院,河南 新乡 453007;2.信阳学院文学院,河南 信阳 464000)
复句下连小句、上及篇章,在汉语语法系统中居于重要地位,因果复句作为现代汉语复句系统的重要成员,一直是国际中文教学的重点,但又因其句法语义的复杂性、句式结构的多样性,也是国际中文教学的难点。关于留学生复句习得难度的考察,余敏(2012)、张利蕊(2018)的研究较有代表性,前者以韩国为研究对象,后者以欧美国家为研究对象。中亚5国均为“一带一路”沿线国家,汉语学习者的数量与日俱增,本文对中亚留学生汉语有标因果类复句习得难度的考察,不仅可以丰富汉语习得理论,而且具有较强的实践意义,可以用于指导汉语复句的教学。
1.句式范围及语料来源
1.1 句式范围界定
本文主要采用邢福义(2001)关于复句的分类原则和标准,研究“广义因果关系”中的因果类复句,且限定于对有标复句的研究。“从关系出发,用标志控制”,各类有标因果类复句有:因果句(“因为……,所以……”“由于……,……”);推断句(“既然……,就……”);假设句(“如果……,就……”“要是……,就……”);条件句(“只有……,才……”“只要……,就……”);目的句(“……,以便……”“……,以免……”“……,免得……”)[1]。
为了更好地服务于国际中文教学,本文着重考察了《汉语水平等级标准与语法等级大纲》[2]《国际汉语教学通用课程大纲》[3]中的相关因果类复句句式的情况,同时参考《对外汉语教学语法大纲》《高等学校外国留学生汉语长期进修教学大纲》《HSK大纲》等大纲,将重合4次及以上的句式作为本文的研究对象,最终确定了16个因果类复句标志,具体见表1(为了方便描述,将各类句式进行了编号)。

表1 有标因果类复句句式
1.2 语料来源
本文的语料来源有4种路径:一是来自河南师范大学国际教育学院语言班学生的书面作业;二是来自全球汉语中介语语料库;三是来自HSK动态作文语料库;四是来自其他高校(暨南大学、福建师范大学)的中介语语料库和留学生书面作业。语料共计180万字,获取相关有标因果类复句共2171条。
2.选定句式使用频次考察分析
句式的使用频率与习得难度是有关联的。余敏(2012)指出,“不同复句句式使用数量的多少、使用频率的高低,可以从一定程度上反映句式习得的难度。容易习得的复句句式自然使用率高,相反,难度大的复句句式使用频率就会相对较低”[4]。本文考察的句式种类较多,使用频次有高有低,各类句式使用量多至上千条,少则没有。现将因果类复句下位的16种句式在中亚留学生的自然语料中分别进行穷尽搜索,然后对其进行数量统计,结果如表2。
因果句的构成较为复杂,其前后分句之间的关系既可以是“由因溯果”,又可以是“由果溯因”,而且关联词的省略现象较普遍,因此,我们将Y1句式又细分为三种变换句式分别进行统计。由表2可知,中亚留学生在使用因果类复句时,他们使用各小类的频次由高到低依次是:因果句(1124)、假设句(709)、条件句(298)、目的句(29)、推断句(11);使用各下位句式的频次由高到底依次是Y1(964)、J1(660)、T4(92)、T1(86)、Y3(83)、Y2(77)、T2(64)、T3(56)、J3(47)、M1(14)、TD(11)、M3(8)、M2(7)、J2(2)、Y4(0)、Y5(0)。不可否认,句式使用频次的高低只能在一定程度上反映中亚留学生有标因果类复句的习得难度,句式使用数量的差异跟作文体裁也有很大关系,在本文考察的语料中,议论文篇数最多,占4/5以上,应用文与记叙文篇数很少,这也会让某些复句句式的使用受到一定的限制,因此,我们还需要从别的角度去考察。
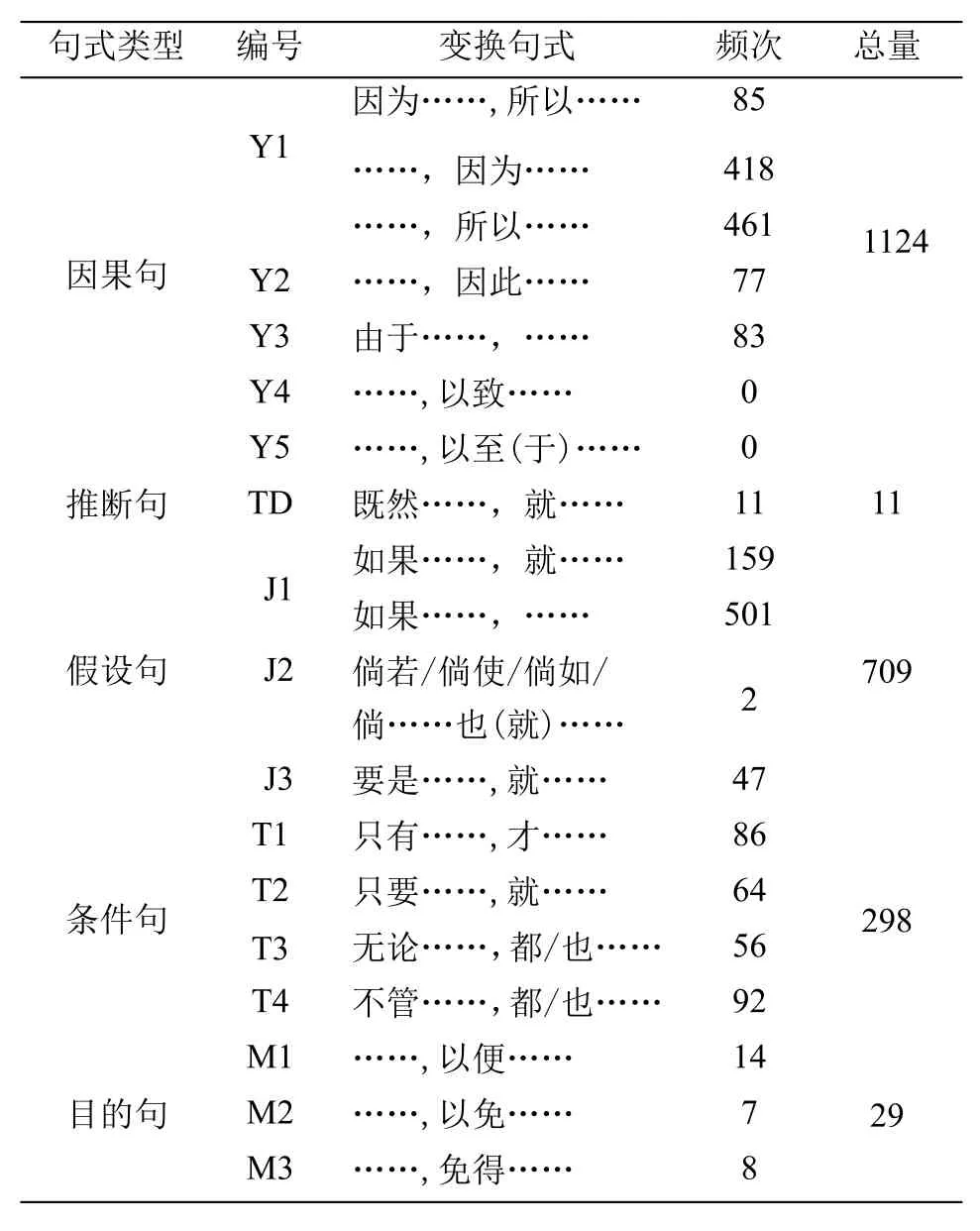
表2 因果类复句句式及使用频次统计
3.选定句式正确使用相对频率考察分析
句式的正确使用相对频率某种程度上能够反映习得难度。正确使用相对频率法是指某一句式或词语在整个这一类句式或相关词语中的正确使用率。具体的计算方法为:某一句式的正确使用相对频率=该句式的正确使用频次/该类句式中所有句式的使用总频次。例如,“由于……,……”句式的正确使用相对频率=“由于……,……”句式正确使用频次/因果类复句16个句式的使用总频次。施家炜(1998)认为,“在语料库出现的语料中,句式的正确使用频次或正确使用相对频率越高,就越容易,越早习得”[5]。据此,我们对自然语料中16种句式的正确使用率和正确使用相对频率进行了计算,具体数据见表3。
由表3可知,16种句式共出现2171次,根据表3中因果类复句句式的正确使用相对频率,可以概括出16个句式的习得难度顺序(由易到难)为:Y1(32.8%)、Y3(27.18%)、J1(21.83%)、Y2(2.95%)、T4(2.90%)、T1(2.35%)、T3(1.70%)、T2(1.57%)、J3(1.29%)、TD(0.32%)、M2(0.32%)、M1(0.23%)、M3(0.23%)、J2(0.09%)、Y4(0.00%)、Y5(0.00%)。句式的使用频次与句式的正确使用频率具有相关关系,通常是句式使用频次越高,相应的正确使用频次也越高,从而影响到该句式的正确使用相对频率。结合本文语料的实际情况,收集到的因果类复句句式多则近千条,少则没有,如果仅仅依靠正确使用相对频率法得出有标因果类复句各句式的习得难度,这也是不科学的。
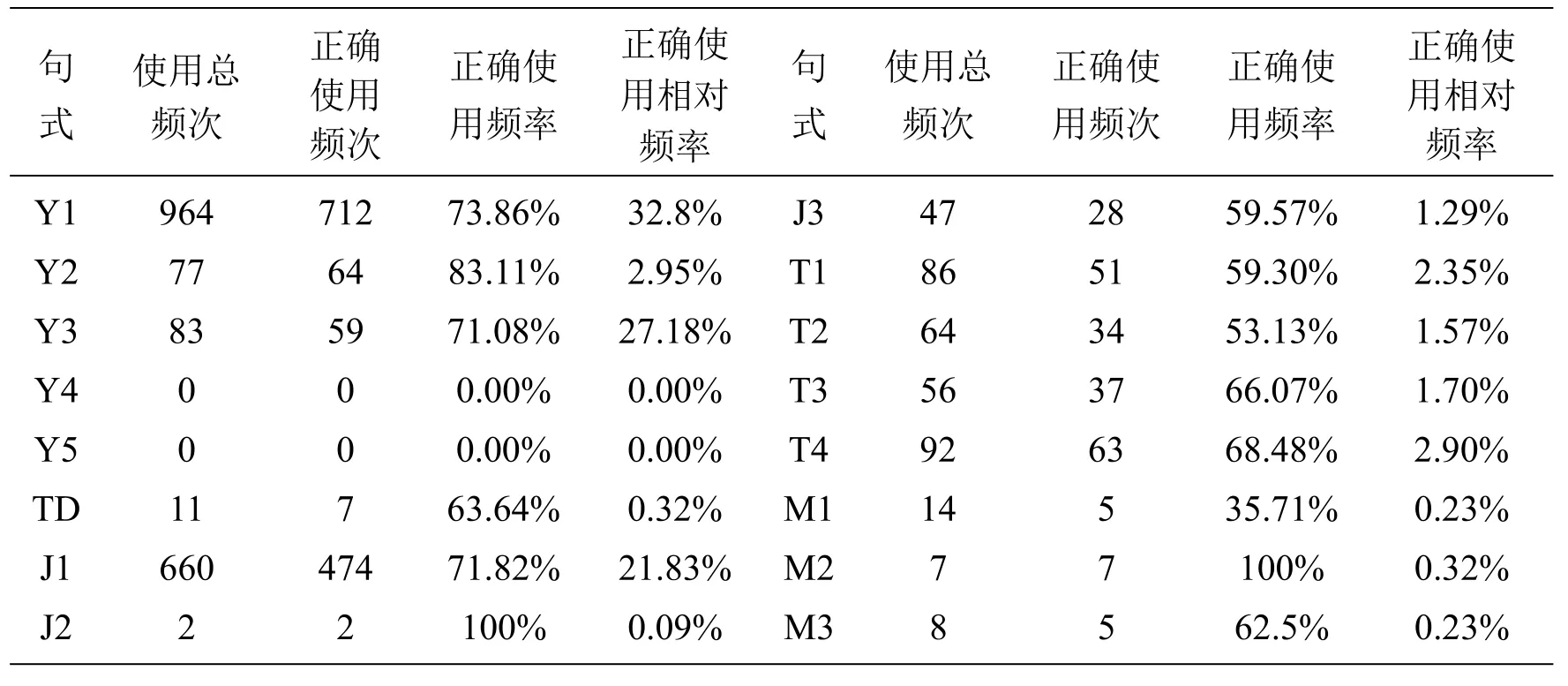
表3 因果类复句句式正确使用相对频率统计
4.选定句式蕴含量表考察分析
“蕴含量表法是建立在各类句式在不同学时水平等级的正确使用频率上的,描述了个体或群体在语言要素的使用和习得过程中分层级的共现模式,得到X蕴含Y,而不是相反”[5]。这里,我们的基本思路为:首先,计算出16种复句句式在每一水平层级上的正确使用频率,其次,将各句式各层级的正确使用率转换为二分变量,以0.70为标准分界,大于或等于0.70记为“1”,表明该句式在该水平等级已被习得,小于0.70记为“0”(某句式在自然语料中使用次数小于30次以下的,为“缺失语料”,也记为0),表示该句式未被习得,接着,将这些转换为二分变量的数据根据“1”的总数量按照由小到大的顺序从左往右依次排列,则左端表示“较难习得”,右端表示“较易习得”,再次计算各等级群体“1”的数量,根据数量总和由大到小的顺序从上到下依次排列,从而形成蕴含量表矩阵;最后根据每一行“1”的数量,从右往左数出等量的列数画出每行分界线,将每行分界线连接起来从而形成整个量表的分界线。
根据蕴含量表的理想模型假设,折线左下区域的项目都应为“0”,折线右上区域的项目都应为“1”,若折线左下区域出现了“1”,说明该项目本不该习得而被习得,反之,若折线右上区域出现了“0”,说明该项目本该习得而未被习得。量表下方“正确”和“错误”的数量则根据以上假设得出,符合假设的视为“正确”,不符合假设的视为“错误”。量表最后一行根据每一列“0”和“1”的数量列出边缘值,第一个数字表示的是每一列中“0”的数量,第二个数字表示的是每一列中“1”的数量。
基于上述讨论,我们首先对收集到的语料进行分级处理,我们将HSK动态作文语料库中证书等级A和B定为“高级”,证书等级C定为“中级”,无级定为“初级”。自建语料库和全球汉语中介语语料库样本中已通过HSK汉语水平考试五级和六级的定为“高级”,四级和三级定为“中级”,二级以下及未考取证书(零基础)的定为“初级”。然后按照高级、中级、初级三个等级来计算特定句式在某一阶段水平上的正确使用频率。最后得到因果类复句句式蕴含量表,如下所示。
蕴含量表创建好后,并不能直接进行说明语法项目习得的等级差异,还需要通过再生系数(Coefficient of Reproducibility)①、最小边缘再生系数(Minimum Marginal Reproducibility)②、再生提高百分比(PercentReproducibility③以及可测量性系数(Coefficient of Scalability)④等这些数据来检验蕴含量表的有效性。计算结果得到Crep=1、MMrep=0.875、%improvement=0.125、,由此说明表1-3的蕴含量表是有效的,而且可预测性高(Crep=1>0.9)。因此,根据上述蕴含量表,可以得出以下结论:

表4 因果类复句句式蕴含量
最易掌握的句式有:Y1、Y2、Y3;
较易掌握的句式有:J1、T4、T3;
较难掌握的句式有:T1、T2、J3;
最难掌握的句式有:TD、M2、M1、M3、J2、Y4、Y5。
与任何研究测量工具一样,蕴含量表法也有其局限性,只能在一定程度上反映中亚留学生有标因果类复句的习得情况。语料分级的准确性、一些因回避策略而造成的语料缺失等因素都会影响到蕴含量表的效度。
5.结语
前文中通过使用频次法、正确使用相对频率法和蕴含量表法分别考察了中亚留学生有标因果类复句习得难度,为了方便最终考察,现将以上研究结果归纳如下:
句式使用频次排序:Y1、J1、T4、T1、Y3、Y2、T2、T3、J3、M1、TD、M3、M2、J2、Y4、Y5;
句式正确使用相对频率排序:Y1、Y3、J1、Y2、T4、T1、T3、T2、J3、TD、M2、M1、M3、J2、Y4、Y5;
句式蕴含量表排序:Y1、Y2、Y3、J1、T4、T3、T1、T2、J3、TD、M2、M1、M3、J2、Y4、Y5。
我们可以发现,通过使用频次法、正确使用相对频率法和蕴含量表法得出的结果存在着差异性,无论是使用频次法、正确使用相对频率法还是蕴含量表法都有其不足之处,因此,单纯使用上述的某一方法去判定因果类复句句式的习得难度是不科学的,得出的结论也必将有悖于事实。彭淑莉(2008)认为,“各句式使用率和正确率两项排名之和越小,表明该句式的习得情况越好”[6]。据此,为了尽可能得到客观、有效的研究结果,现将各个句式在以上统计分析中出现的次序依次相加,认为得出的和越小,则说明该句式的习得难度越低,具体结果见表5。

表5 因果类复句句式使用排序
通过综合使用频次分析法、正确使用相对频率法以及蕴含量表分析法分析所得出的结果,根据“总分之和越小,习得难度越低”,可以概括出16个句式的习得难度顺序(由易到难)为:Y1(3)、J1(9)、Y3(10)、Y2(12)、T4(13)、T1(17)、T3(21)、T2(23)、J3(27)、TD(31)、M1(34)、M2(35)、M3(38)、J2(42)、Y5(45)、Y4(48)。具体结论如下:
最易掌握的句式:Y1(因为式)、J1(如果式)、Y3(由于式);
较易掌握的句式:Y2(因此式)、T4(不管式)、T1(只有式)、T3(无论式)、T2(只要式)、J3(要是式);
较难掌握的句式:TD(既然式)、M1(以便式)、M2(以免式)、M3(免得式);
最难掌握的句式:J2(倘若式)、Y5(以至式)、Y4(以致式)。
注释:
① Crep=1-错误的数量/等级数量X句式数量,系数大于0.90,越接近1, 则预测的把握越大。
② MMrep=最大边缘值(边缘值中每列最大数值相加)/等级数量X句 式数量,此值小于再生系数,可预测性大。
③%improvement=Crep-MMrep.
④ Cscal=%improvement/1-MMrep,此值超过0.60时,则具有可测量性。
猜你喜欢
金桥(2022年10期)2022-10-11
成都理工大学学报·社会科学版(2022年1期)2022-05-26
华北电力大学学报(社会科学版)(2021年2期)2021-07-21
海外华文教育(2016年1期)2017-01-20
中亚信息(2016年3期)2016-12-01
当代教育理论与实践(2015年9期)2015-12-16
语文学刊(2015年24期)2015-08-15
能源(2015年8期)2015-05-26
民族古籍研究(2014年0期)2014-10-27
西安航空学院学报(2014年4期)2014-07-13
