
文化大数据:驱动文艺融合研究的范式转型*
2023-02-21 09:41徐剑钱烨夫
艺术百家 2023年6期
徐剑,钱烨夫
(1.上海交通大学 媒体与传播学院,上海 200240;2.上海交通大学 中国城市治理研究院,上海 200030)
数字化的浪潮正从信息技术领域溢出,开始席卷人们社会生活的各个领域。就像“上网”不再是个动作,而成为人们日常生活的一种状态,数字技术正在重塑人们对社会的系统认知和思维方式。与社会科学相比,数字化对人文艺术研究的影响虽没有在学科体系内引起颠覆性的变革,但在近十年开始逐步渗透到研究的对象、议题、方法等层面,潜移默化地推动着一场范式的变革。被西方学术界称为“下一个大事件”的数字人文(digital humanities),正是在这样的时代浪潮下进入国内学界并迅速成为一个热点概念。然而,作为一个新兴领域,数字人文的发展始终在对人文研究计算方法的重组与批判性反思中艰难前行。[1]288-290安妮·伯迪克(Anne Burdick)认为:“数字人文不是一个统一的领域,而是更像一组相互交织的实践活动。这些实践活动探索在不以印刷品为知识生产与传播的主要媒介的新时代出现的各种问题。”[2]121尽管数字人文的边界还有待商榷,但其作为实践活动的底层基础——数据,无疑已经成为这一领域不可或缺的生产性要素。[3]79-88
文化大数据,正是伴随着数字人文实践的不断演进而逐步成熟的一个复合性概念。2022年5月,中办、国办印发的《关于推进实施国家文化数字化战略的意见》将“统筹推进国家文化大数据体系”作为重点任务之一,明确了到2035年建成国家文化大数据体系的目标。政策层面的战略布局表明,文化大数据已经成为文化数字化转型过程中的关键推动力;而从学术研究的具体实践来看,文化数字化与数字人文研究又有着千丝万缕的联系。智能时代数字人文研究的飞速发展再一次唤起了“文化”与“大数据”的会遇,一座连接理论概念与实践路径的桥梁正悄然浮现。那么,文化大数据究竟有何内涵,如何在数字人文的经纬中理解其概念、边界及其与文艺研究的关联,又能从何种意义上给予研究者以新的启迪和思考,从而推动新时代的文艺研究在转型中不断前进?为了回答上述问题,本文基于对文化大数据的源起和发展历程的梳理,着重考察了文艺研究领域的学者对这一概念的阐述和实践运用,并尝试提出一种数据驱动下的文艺融合研究范式,以此探讨文化大数据推动数字时代文艺研究的可能方向。
一、文化大数据的概念及特征
数据体量和规模的庞大是“大数据”概念最直观的特征之一,这同时也在数字时代海量的文化内容数据中得到了印证。数据显示,谷歌图书馆扫描并编目了2500多万本图书[4]16-37;脸书(Facebook)的资源库每周新增50亿条内容[2]38。因而,“文化”与“大数据”的相遇,似乎是数据规模指数级膨胀趋势下的一种必然,但又不局限于此。数据规模本身的增长,势必会对提取、把握和分析数据的研究方法提出新的挑战。因此,文化大数据作为一个独立概念的出现,标志着对于海量的文化数据资源的技术运用进入了新的阶段,呼唤着新的文化基础设施和技术手段的到来。尽管技术变革与政策规划的双重语境已将“文化大数据”的概念推至时代前台,成为近年来文化领域热议的关键词之一,但学界对于这一在大数据浪潮中孕育出的组合型概念却缺乏系统的梳理与思考。基于此,本文尝试从新技术背景下的文艺研究视角出发,通过一个金字塔结构框架(图1),对文化大数据所包含的概念层次加以阐释。

图1 “文化大数据”概念的三层次结构
从作为底层基座的数据要素来看,文化大数据是数字时代文艺创作的本体与外延,这一本质属性又嵌套在文化数字化的过程之中。随着文艺创作的手段、工具、存储和呈现方式越来越与数字媒介相互融合,数字媒介作为“元媒介”,展现出前所未有的“开放、迭代生长、(几乎)无限变化和拓展”的特性,改变了文艺创作的底层机制。[2]14-15大数据不仅已嵌入文化活动的各个单元,并且也深刻地影响和改变了作品的创作方式、内容形式、存储和呈现方式,甚至在某种意义上成为作品本身。如数字文学、超文本小说、数字影像艺术、互动艺术、虚拟现实艺术等数字文艺形态,基于数字化、网络化、虚拟化的技术平台,采用更加动态、多元、开放和非线性的叙事模式,将声音、图像、文本转换为可反复读写和编辑的开放式代码,这也意味着数字时代的文艺发展必然会生成海量的数据。毕达哥拉斯学派曾提出“万物皆数”的本体观,在数字媒介环境下,一切都可以被数据化,数据可以成为不同形式艺术作品的表征。即使是原本没有通过数字介质存储的艺术内容,也可以通过多种文化数字化的手段转化为数据。同时,文艺作品通过互联网、社交网络的传播也催生了海量的“相关数据”,即文艺创作的外延性数据,如作品在网络空间的传播、销售、出版,读者的阅读、转发、评论等等,这些数据经由网络快速产生和不断变化,使得文艺表达所承载的内容进入一个广阔的、动态变迁的场域中,并且极大地拓展了文艺研究的范畴与边界。
文艺作品和文化内容的数字化,在网络空间形成了一系列连接性的网状数据结构,但这种数据依然是独立、分散的数据集,需要通过数据库和数据平台加以统筹、整合并建立连接。因此,从中间层意义上看,文化大数据是在文化数字化的基础上,使数据进一步标准化并搭建形成的,可以有效服务于广泛意义上的文化研究的复合型数据库和开展数据管理及中转的(云端)数据平台,是一种大数据运行管理机制和数字文化基础设施。数据库建设是数字人文的基础工程,数据全面、分类清晰、有效联通、标准化的数据库资源,是学术研究范式转型和理论创新的必要准备。[5]1-11大数据的特性在于多种不同类型数据之间的关联性。文化大数据并非一个单一的大规模数据集,而是一连串与文化相关且连通的数据库的组合。弗雷德里克·开普兰(Frederic Kaplan)用三个同心圆的结构阐述了文化大数据、数字文化、数字体验之间的关系:文化大数据可以被视为一连串线性的大规模数据库组成的集合,位于研究的中心;在其外圈的数字文化研究侧重于讨论不同类型的参与者或对象(如媒介话语、大型文本、网络社群、数字软件)之间的相互关系;而上述内容又都包含在数字技术所带来的新的更大的数字体验的语境之中。[6]1
文化大数据的数据库建设是文化数字化战略中的核心环节。我国文化大数据的搭建、整合和连接工作是一个在时代语境下阶段性、渐进性发展的过程。早在2019年公开征求意见的《文化产业促进法(草案)》和科技部、中宣部等6部委发布的《关于促进文化和科技深度融合的指导意见》中,就已经将文化大数据体系建设工作作为一项重要的战略任务。中宣部2020年发布的《关于做好国家文化大数据体系建设的通知》指出,文化大数据体系是新时代文化建设的重大基础性工程。在这一框架下,我国的文化大数据作为一种标准化、结构化的数字基建,有其特殊的战略意义。2021年以来,国家文化大数据体系建设的一系列相关标准陆续发布。文化大数据体系的建立,是面向“数据壁垒”、解决文化资源数据孤岛化问题的重要举措。可以预见的是,随着文化大数据体系的完善,以及数据资源开放共享的不断深化,海量数据势必成为文艺研究中重要的分析要素和工具。
在文化数字化技术和大数据基础设施的基础上,文化大数据进入了第三个层次,即充分利用海量的文化数据资源,综合使用数字技术分析和解决前沿研究问题的一种新的方法和手段。20世纪40年代,意大利学者罗伯特·布萨(Roberto Busa)将计算机技术引入人文研究,从而建立起一种新型文化研究模型,这种取向被称为“人文计算”(humanities computing)。[7]1-19从人文计算到数字人文,其概念内涵与边界不断拓展,但始终没有离开数据技术与计算方法的本质。今天,基于大数据的技术工具已经越来越多地应用到文艺研究的实践之中,如文本挖掘、聚类分析、主题分析、社会网络分析、语义建模、知识图谱等方法和辅助分析手段,已在文学史、艺术史、文艺理论、艺术风格与流派、审美范式等不同领域的系统性研究中发挥了重要作用,并在更大范围与不同学科、不同研究领域展开对话。
综合上述定义阐释不难发现,文化大数据是在信息传播进入互联网时代后,与文化相关的大规模数据共同催生的产物。在这一背景下,“文化”与“大数据”并非简单的相遇或组合,而是演变为一种互动共生、互相形塑的关系。一方面,文化艺术对于数字媒介技术的使用不仅使得数据成为不可或缺的生产要素,导致相关数据的海量化,更催生了围绕数据展开的新兴艺术形式和表现样式;另一方面,海量的生产数据和相关数据也为文艺工作者提供了丰富的矿藏,它既承载了规模庞大的数字文化资源,同时也蕴藏着从海量数据中挖掘新发现、助推文艺理论和内涵发展的巨大动能。可以说,文化大数据为文艺研究提供了多元的议题界面、基础要素和研究工具,它不仅代表了一种底层数据意义上的变革——与文艺研究相关的诸多领域的文化材料、资源、内容都正在被快速地数字化,并进行系统性的整合和重构;而且在更深的意义上,它正在推动一种文艺融合研究范式的转型——这种转型不仅仅局限于技术手段的突破,而更在于一种打破固有研究规程与版图壁垒的观念更新、视野拓展及理论创新。
二、大数据时代文艺融合研究的范式转型
在文化数字化浪潮的席卷下,数据已经渗透至社会生活和文艺生产的方方面面。以文化大数据为代表的新的文艺形式、技术工具和研究方法把研究者带往了一个新世界,而这也为文艺研究的范式转型提供了前所未有的契机。库恩的科学革命理论诠释了科学发现和技术进步在范式变化中的重要意义。这一理论能够在一定程度上解释大数据技术如何促使传统意义上的文艺研究理论和方法的调整变化,以及数字人文作为一个新的领域的诞生与演进。这种变化并非一种激进的取代与颠覆,也非温和的改良主义,而是重新提出了多维度、多角度的思考模式,帮助研究者在单一线性的研究取向之外找到新的视角。库恩笔下的“范式”可以被视为科学共同体的结构、群体信念的集合、共有的范例,代表着某一类研究集合体的整体面貌。[8]237-254范式之变不仅仅是理论与方法的创新,更多的是一种思维框架之变,它既包含研究的视角与尺度,也包含工具与手段,提供了更加广阔的研究视野和更加丰富的可能性。从这个意义上说,文化大数据所提供的范式变革的驱动力核心在于,以数据为牵引力而贯穿不同领域的研究版图,有效连接宏观与微观视角,并通过更加直观的技术手段对研究结果进行呈现,从而突破文艺研究中长期存在的圈层壁垒,实现研究范式的融合创新。
(一)视角融通:以数据为牵引的超学科方法论
尽管数字技术并未充分地从根本上改变具体的学科,但人文学科无疑已经随着数字技术在各类研究中的应用而风云变幻。[9]3从历史上看,现代学科概念经历了一个不断分化的发展过程,其形态大体上在20世纪40年代左右发展进入成熟期,[10]13-17+24这为现代性的发生提供了合理化的工具。但过度细分专业领域带来的学科边界也造成了不同研究领域互为壁垒的“孤岛效应”。尽管文艺研究的议题日益多元,但对其他学科的影响,尤其是和社会科学、自然科学的交叉对话仍显贫乏。而从文艺理论的内部视角来看,不同研究取向所造成的理论分野也如鸿沟一般阻隔了不同范式之间的对话与交融。艾布拉姆斯从文学理论的坐标谱系出发,归纳出著名的“四要素”论,即任何一件艺术品总涉及作品、艺术家、世界、受众这四个要点,而“几乎所有力求周密的理论总会在大体上对这四个元素加以区辨”[11]8。这一观点对应了20世纪西方文学理论所经历的从作家到文本、再到以读者为中心的理论转型。伊格尔顿将现代文学理论的发展史划分为三个阶段——“专门研究作者(浪漫主义和19世纪);专注于文本(新批评派);近年来明显地把注意力转向读者”[12]91。朱立元将其归纳概括为西方文论研究重点的“两次转移”,即第一次是“从重点研究作家转移到重点研究作品文本”,第二次则是“从重点研究文本转移到重点研究读者和接受”。[13]4但上述有关理论范式的划分几乎始终是围绕着相互独立的各元素展开,在作者、文本、读者被明确为独立的研究取向的同时,其相互之间也陷入一种自然的分野,如探讨作品与世界的关系的存在主义、女性主义,分析作品与艺术家关系的表现主义、象征主义、精神分析,探讨作品与读者关系的阅读现象学、读者反应理论,以及讨论作品本身的形式主义、结构主义、符号学等。20世纪以来西方文学研究形成的若干理论坐标由于其自身的取向具有根本性的差别,彼此之间很难实现跨领域对话,甚至难以在同一研究框架之下兼容共存,从而愈发扩大了不同研究谱系的割裂和理论之间的鸿沟。尽管也有研究者认识到需要发展对所有文学元素进行整体把握的综合性研究,[14]5但却因为缺少整体性的分析框架与研究手段而在具体实践中困难重重。
理论的断裂和互斥本质上源于缺乏共同对话的基础。艾布拉姆斯说:“实际上许多艺术理论根本就不可能相互比较,因为它们没有共同的基础……这些理论之所以不能相互比较,或者是因为术语不同;或者是术语虽同而内涵各异;或者是因为它们分别属于一些更大的思想体系,但这些思想体系的前提和论证过程都大相径庭。”[11]8而今,文化大数据提供了一种以数据为桥梁的文艺理论的连接融合范式,这种数据驱动下的连接具有天然的对话与整合作用,可以为弥合理论分野的鸿沟提供新的可能。在文化大数据牵引下,我们可以将艾布拉姆斯的四要素分析图式修改为以下的锥形六面体形式。(图2)首先,作品、艺术家、世界、受众位于一个正四面体的各个端点,这意味着上述不同面向的研究尽管各自占据一种独立的位置,但并不是孤立存在的,而是相辅相成、互为整体的。位于底层基础位置的文化大数据为上述各元素的连接提供了桥梁,可以指涉作家、文本、读者乃至更广阔的文化世界,实现不同元素间的对话,同时又能够通过数据赋予新的研究视野。事实证明,这种连接不仅是必要的,并且已经通过数字技术应用逐步变为现实。例如,王兆鹏团队运用数字人文技术开发的唐宋文学编年地图平台,试图在文献资料集成化的基础上实现文学编年史的时空一体化,将对作家活动、作品创作地理分布的考察与作家年谱、别集编年笺注之类的时间信息结合到一起,不仅能够帮助实现古代文学研究“时空分离”的重新连接,更能以此管窥不同时期作家的社会活动空间特征,从更大的历史文化背景下实现不同学科、不同领域的“异类关联”。[15]108-129+206-207实践表明,无论是文献资料的分散还是理论取向的分离,其连接是完全可以建立在数据的基础与功能之上的。这种连接能够将长期以来相互独立的学术分野以超学科的框架统一起来,实现超越学科边界和理论分野的整合。换言之,文化大数据并非研究者聚焦的研究对象本体,而是以一种超学科视野中的融合方法论的形式服务于文艺研究,从而建构起具有实践性和整合性的文艺理论体系。
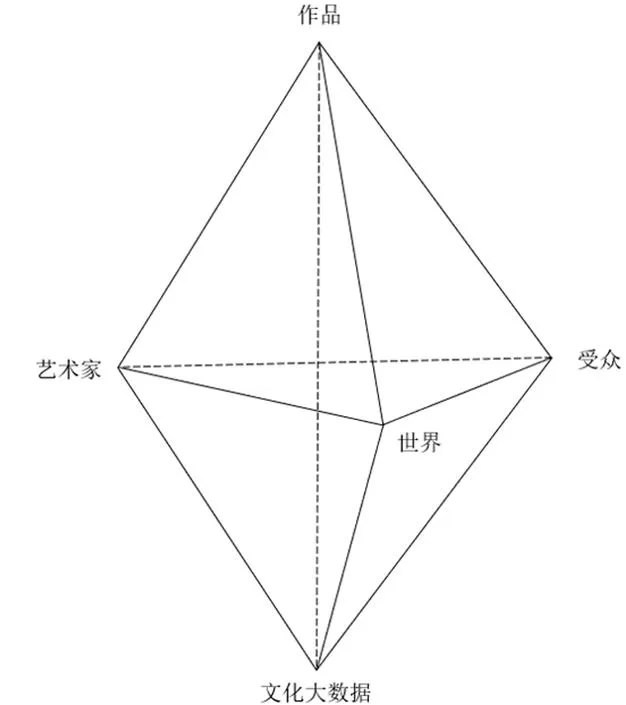
图2 文化大数据牵引下的理论分析图式
文化大数据的本质是数字,它围绕规模化的数据展开,也聚焦于数据本身来进行自我的完善与发展,并未预设任何学科属性与边界壁垒,因此它天然具备一种超学科性。以数据为牵引,可以有效刨除学科话语体系自设的藩篱,将人文学科的研究土壤向社会科学和自然科学开放,从而推动理论的对话与范式的创新。这种超学科融合方法论并非简单地将大数据或其他数字技术迁移或者应用到文艺研究领域,而是以一种更加广阔的视野,推动数据与研究产生如锥形结构一般相辅相成、相得益彰的“两级效应”。首先,是以文艺为“中心极”。所谓大数据研究并非以数据分析取代文艺史长期以来发展形成的传统研究范式,而是立足于文艺之本,通过数据的渗透与挖掘去深入理解文艺与其他学科、其他文化活动之间相互影响的关系,而最终需要从外延的数据回归到文艺研究的本体。其次,是以文化大数据为“牵引极”。作为一种整合性、连通性的系统,文化大数据不仅仅是简单地将文艺作品数字化,而是连接更加宽泛的文化内容,可以帮助研究者以更加开阔的视角去平视文艺研究与“大文化研究”及其他相关学科之间的关系,揭示文艺的发生、表达、传播、发展与更广阔的社会文化现实的内在联系及相互影响。例如,斯坦福大学文学实验室(Stanford Literary Lab)的两位学者莱恩·霍伊舍(Ryan Heuser)与龙莱克(Long Le-Khac)通过对2958部19世纪英国小说文本的规模化数据分析发现,在这一特定时期,英国小说中与道德约束有关的“抽象价值”语义场(如“谦逊”“尊重”“德行”等词语)呈现出稳步下降的趋势,而描述动作的动词语义场却呈现明显的上升趋势。[16]11-27而要想充分解释这种趋势变化,就必须将其置于该时期文学和文化史的整体背景之下,批判性地回归到更加广阔的社会经验上来。进一步的分析表明,19世纪英国小说的叙事风格更加侧重于物理细节的展现,这种具体化转变的背后是小说中社会空间的普遍扩张,而这也对应了这一历史时期英国现实社会空间的平行变化。[16]45
当大数据的分析技术与思维方式介入文艺研究的具体语境时,规模化数据往往会自然地揭露在单一文本中难以洞见的特定变化趋势,而这种变化趋势又能够驱使研究者进入更大的批评语境之中,与更多理论展开对话,从更广阔的视角思考文艺作品中所隐藏的规律,这也即文化大数据不断显现的“连接”潜力。类似的探索反过来又会作用于文艺研究自身,实现理论范畴的兼容与互补。超学科融合方法论正是从文艺研究的本体出发,以大数据为牵引,在经历一番漫溯式探索之后又回到文艺的本体上来。它不局限于文艺作品本身,而是以数据为强有力的证据,在更大范围内揭示文艺研究与其他学科门类之间的内在关系,最终实现对文艺研究本身的反思与复归,通过不断丰富研究的理论体系与方法组合,在实践中实现对自身的深化与超越。
(二)尺度放缩:“远读”与“近读”的有机统一
自弗兰克·莫莱蒂(Franco Moretti)提出“远读”(distant reading)的阅读尺度以来,有关“近读”与“远读”的争论始终未有停歇。在新批评出现后,“细读”(close reading,直译为“近读”)逐渐作为一种主要的批评策略被确立起来。[17]63020世纪以来的语言学转向几乎将文本细读塑造为文学批评的核心范式。[18]114-124因此在相当长一段时期,这种基于对文本“精耕细作”的近距离阅读方法一直占据着主导地位。“近读”的实质是根植于特定文本,并对其细部内容进行具体分析,结合研究者的阅读记忆和个体感知进行经验性阐释。然而,面对数字时代文艺创造的新形态和新规模,这种方法正暴露出越来越多的局限性。莫莱蒂认为,晚期资本主义时代尤其是电子媒介诞生后,文艺创作和传播的速度空前加快,其内容体量以指数级的速度增长,批评者很难通过单一或少量的文本细读方式去了解巨量的文本内容,从而产生了“大量未读”(great unread),这意味着可能有99%以上的作品被研究者遗忘,而这恰恰是文学研究所需要正视的问题。[19]207-227同时,由于缺乏对海量文本的整体把控力,“近读”的研究方法往往缺少历史性的文本洞见与纵向的比较分析。随着外部内容空间与形式空间的不断放大,坚守固有思维的文艺研究在尺度上将会显得越来越小,从而失去一种整体性的认知。
数字人文视野中的远距离阅读,是“一种关注更大单元和更少元素,并通过形状、关系、模型和结构揭示模式和相关性的分析形式”[2]39。尽管“远读”概念诞生的原初语境并非围绕着计算分析展开,但不可否认的是,简化和抽象是“远读”本身最重要的特点,而定量分析则是在方法演进中所产生的一种必然。因为抽象模型需要宏观数据的支撑,这正是“近读”方法所不具备的。规模化的海量文本内容意味着研究者需要跳出单一文本的藩篱,用数据库与计量技术去关注数字化的“宏文本”。[20]123-129正如莫莱蒂所说,“研究者对世界文学范围大小的选择与研究者到文本的阅读距离成正比:项目所涵盖的范围越广,那么研究者离文本的距离就应该越远”[21]70-77。从这一视角出发,文化大数据能够为远距离阅读提供两个重要的研究工具箱:一是大规模文本分析。通过文本挖掘、主题建模、网络分析等技术,实现对尽可能多的作品的整体性计算分析,从而将大量的“未读”作品拉回到文学的整体性研究上来。这些设想在莫莱蒂关于欧洲小说(1800—1900)[22]141-197,英国小说(1740—1850)[23]134-158,《哈姆雷特》、《红楼梦》人物关系网络的研究[24]211-240中得以付诸实践探索。类似的取向不仅能够帮助研究者更好地理解数字时代单一阅读难以获取的海量文艺作品本身,还可以从社会、文化、历史、经济等角度透过作品观察和分析更广阔的非文艺范畴,从整体脉络和系统认知层面拓展文学概念。二是协作性知识生产。数字人文视野中的文艺研究,可以扩大学术研究的范围,并与普通大众产生交集,使之成为一个“在世界范围内可参与、相关联的多人在线游戏”[2]27。通过文化大数据的连接性系统,文艺研究可以不局限于个人或少数主体的分析和解读,而是通过数据接口进行集体协作,甚至实现人工批评与机器分析之间的协作。例如,爱尔兰第一个公众参与的数字人文项目“1916年的信件”(Letters of 1916)面向公众收集1915至1916年间与爱尔兰有关的书信文件,并通过数字化、转录、编码建立大型数据库,以更具复杂性的大数据分析手段展现这一特定时期的爱尔兰历史。[25]506-525此外,亚马逊的众包网络平台“土耳其机器人”等支持团队工作的新技术模式,也为“大人文研究”提供了新的生产方式。[9]96
当然,也有批评者认为,“远读”方式始终无法摆脱机器与数据黑箱的制约,集中于对数据驱动的“工具性”问题的批判。事实上,对大数据技术在文艺研究中应用的批评,或对数字人文的指摘,本质上来源于将人文学科与科学技术的知识领域进行“二分”的思维惯性。[26]88-97+177莫莱蒂当然也意识到局囿于数据的定量研究的缺陷。他指出:“定量研究提供了独立于阐释的理想数据类型,但那也是它的缺陷:提供数据而非阐释。”[27]9我们认为,“远读”和“近读”不一定非得是对立和互斥的,也可以是平行和互补的。远距离阅读可以帮助研究者发现大规模的趋势、模式和关系,但对于个体性文本的具体特点、内涵的分析,依然需要通过“近读”加以深究。应当引入一种“放缩法”,在“大”与“小”、“远”与“近”中寻找一种平衡,使二者在数字人文的框架下有机结合在一起。有学者指出,应对由数字技术引起的大规模和小规模的调适方式之一是利用“显宏镜”(macroscope),它能够“帮助我们综合集成各种相关元素,发现各种隐藏的模式、趋势和异常,同时也让我们看到无数的细节”。[28]一个典型的例子是安德鲁·派珀(Andrew Piper)和马克·阿尔盖·休伊特(Mark Algee Hewitt)在关于歌德(Johann Wolfgang von Goethe)小说《少年维特的烦恼》(theSorrowsofYoungWerther)的语言特征研究中,通过“拓扑阅读”①的方式发现歌德早期和后期作品风格之间的连续与断裂关系,从而在大量文本中发掘值得进一步分析的原材料,并使之接受传统意义上的“近读”分析。[29]11-20数字人文研究者正是通过这样的方式,形成在“远读”与“近读”间不断切换的分析模式,从而实现二者的互补。类似的方法能够启示研究者,宏观的模式规律与微观的细节元素是不应被割裂开的,“近读”与“远读”也应当在特定的运行框架下进行有机的统一与结合。这里的“结合”,可以是基于文本学分析、类型分析、作者风格或写作模式的比较与基于对文本数据或语料库快速、大规模的信息处理的结合。[2]18在这一过程中,定量主要解决“是什么”的问题,而阐释则可以解决“为什么”与“怎么样”的问题。[30]43正如库恩所言,新现象的出现并不一定会破坏先前的研究,新理论的出现也可能只是将一系列旧理论重新联系并组合在一起,而不会对其造成实质性的改变。[8]96“远读”所带来的尺度之变并非从根本上抛弃传统研究方式的细部和深度发掘能力,而是通过引入新的观察角度与研究手段,与传统的、根植于人文学科特质的研究表达方式进行有机融合,从而达到“宏微合一”的效果,在范式的相互补充中实现研究方式与手段的进步。
(三)方法更新:面向数据复杂性的可视化研究
文化大数据所蕴含的超大规模的数据体量以及多领域的数据资源导致其边界呈现不断扩张的动态弹性特征。而当若干可变的数据单元组合到一起时,势必会形成一种新的复杂系统。对于计量语言学、计量历史等常规意义上的计算人文方法而言,其计算的对象尽管也可能具有相当庞大的数据体量,但其类型依然是单一的文本对象。而在文化大数据的语境中,研究者需要面对的无疑是更加丰富多元、广泛连接和相互嵌套的多维数据库,因而文化大数据分析研究的对象更多地表现出多种数据规则之下的复杂性。显然,这种面向文化大数据背后复杂系统的探索正逐步超越传统定量方法的解释力,呼唤着新的研究方法和研究工具的到来。从另一个角度看,文化大数据所形成的复杂系统天然具有“涌现”的特征。所谓涌现性,通常是指多个要素组成系统后,出现了系统组成前单个要素所不具有的性质,这个性质并不存在于任何单个要素之中,而是当系统由低层次向高层次构成时所表现出来的特质。[31]48-51当更多的数据彼此关联起来时,面对多元数据的复杂性,研究者需要通过合理的分析手段将数据中隐含的某种趋势或特定的表现机制直观地呈现到研究界面之上,从一个更高的视角观察复杂系统中的涌现性规律。近年来在数字人文领域快速发展的可视化手段则为应对大数据的复杂性特征提供了有效的工具。
图表作为一种最朴素的数据可视化方式,早在中国古代的历史实践中就已得到体现。南宋郑樵《通志·年谱序》:“为天下者不可以无书,为书者不可以无图谱,图载象,谱载系。为图所以周知远近,为谱所以洞察古今。”唐代张彦远《历代名画记》:“记传所以叙其事,不能载其容;赋颂有以咏其美,不能备其象。图画之制,所以兼之也。”[32]3在古人看来,图像不仅可以在远与近、古与今的历史尺度中体察全貌,还能实现“容”与“象”的统一,客观呈现事物的真实样态。而在大数据语境中,可视化有助于实现大量数据集的多维描述,为研究者提供以更直观的方式呈现和分析研究结果的可能性。典型的可视化形式包括聚类树状图、生命基线图、词汇速写图、日历视图、同心圆图、文本可视化分析、历史地理地图等。[9]133对多数人来说,可视化并非一项新鲜的技术。从本质上说,可视化是视觉图形对数据内容的一种转译。而在文化大数据语境中,可视化不仅仅局限于一种数据的表征方式,更可能成为推动研究范式创新的一股重要力量。正如克利福德·伍尔夫曼(Clifford Wulfman)指出的那样,受众通常认为数据可视化只是一种发现工具,但数据可视化不仅可以用于说明已经发现的结论,还可以用于改进提出的论点;数据可视化,已经成为数字人文的一个重要标志。[33]94-109
在文化大数据驱动下的融合研究范式中,可视化的重要性正日益凸显。首先,可视化能够帮助研究者在复杂的数据海洋中透视“涌现”。读屏、读图时代的到来不仅在阅读习性和文化惯性上引发了“图像转向”,而且影响到研究者阅读信息和探索规律的方式。从神经科学的角度看,人类大脑对于图像内容具有先天的敏感性。因而,可视化具有超越文字、数据本身的直观性优势。当快速增长的文化大数据不断呈现出复杂性与动态性特征时,海量的数据代码就像层层包裹的迷雾,往往会使研究者迷失在数据的海洋中。而数据分析与可视化技术的结合,为应对这种复杂数据集提供了有效途径,能够使研究者拥有在复杂数据中发现和把握宏观趋势的能力。这种方式通过对大规模数据的抽象提炼而作整体性考察,突破了传统方法选择性关注的局限,从而达到“既见树木,又见森林”的效果,特别是在文学史研究中展现出了巨大潜力。比如在前文提到的斯坦福大学文学实验室关于19世纪英国小说的研究中,作者总结到,“从数据中涌现出的可能是一个系统,一部具有明确形态的小说史,这才是最惊人的发现”[16]46。其次,可视化是一种表征文化大数据所形成的复杂系统结构的直观方式。无论是作品中的人物关系网络、作家的文学活动抑或是受众对文艺作品的传播行为,其在本质上都可以表征为一种复杂的网络结构,而可视化无疑是帮助研究者洞察其中的关系特征和动态演变的最有效手段。比如芝加哥大学的霍伊特·朗(Hoyt Long)和理查德·索(Richard So)将20世纪初美国主要诗人在美国文学刊物的作品发表情况转化为可视化的复杂网络结构图谱,并试图借助社会网络分析探究全球现代主义诗歌演变背后的协作网络。[34]147-182目前,这种方法已经越来越多地应用于文本的叙事网络及文学社会学的研究中。
此外,可视化也是将基于本文的历史数据与空间要素相统一的一种重要手段。近年来,在数字人文视野中,以文学空间研究为中心的文学地理学正随着研究技术的进步和研究视线的转向而异军突起。[35]122-136+160莫莱蒂在《图表、地图、树形:文学史的抽象模型》一书中,将远距离阅读具体化为一种综合运用图表(定量分析)、地图(空间分析)与树形(形态分析)去研究文学现象的方式。[27]69其中,地图这一要素不仅能够将文字序列与空间要素联系在一起,还能将大量未读文本的空间结构展现在研究者面前,勾勒出文学构造空间模型的能力。[30]47在《欧洲小说地图集》(AtlasoftheEuropeanNovel)中,莫雷蒂从文学地理的角度研究伦敦的空间结构,绘制了狄更斯(Dickens)小说中的人物住宅地图和柯南道尔(Conan Doyle)笔下的犯罪地图。[22]121-138马修·威尔肯斯(Matthew Wilkens)在将美国小说文本(1851—1875)中的地名与特定的地理坐标关联后发现,内战前后出版的美国小说中超过40%的地理位置都在美国境外,呈现出跨越大西洋两岸的空间分布特征。这些数据表明19世纪美国文学日益跨国化,同时也表明与移民和城市化相关的人口和经济流动是这一时期文学发展的重要驱动因素。[36]803-840如今,以文学地理为中心的可视化研究正逐渐演进为开放式、可交互的大型数字人文研究平台。比如斯坦福大学的“绘制书信共和国地图”项目[37]59-64,中南民族大学王兆鹏团队开发的“唐宋文学编年地图平台”,浙江大学徐永明团队开发的“学术地图发布平台”等[15]108-129+206-207。
最后,文化大数据的动态呈现与可交互技术,赋予了数据以更加鲜活的生命力,将成为未来数字人文领域的重要发展方向。文化大数据的交互式可视化可以为用户提供一种自由获取视觉图像和数据信息的方式,同时也可以为研究者提供更加动态且高度集成的一体化研究平台。通俗而言,传统的数据可视化手段所呈现的视觉内容是固定的、静态的表征,而交互式可视化提供的是一个“活”的可交互、可实时反馈的信息图像系统。比如浙江大学开发的学术地图发布平台,用户不仅可以查看变量的各种属性与数值,还能够通过不同的索引检索项分析各层数据之间的关系,通过不同类型数据层的交互发掘其中的内在关联。[38]113在数字馆藏、视觉艺术、文化遗产的图像分析研究领域,交互式可视化无疑具有更加丰富的应用前景,已经被广泛应用于数字馆藏策展分析[39]159-183、大规模图像艺术作品比较[40]249-278等具体研究之中。一个典型的例子是清华大学向帆等开发的交互式可视化项目“Award Puzzle”(图3)。通过收集2276幅全国美展油画获奖提名及入围作品(1984—2014),该项目建立了一个全国美展油画作品图像数据库,不仅能够帮助研究者辨别油画作品中的同质化趋势,还能让研究者更加直观地观察艺术对象,从中发现集体趋势和个体特征的关联。[41]92-94
三、余论
在实践与反思中前行的数字人文,正不断启迪研究者以新的视野、方式与手段应对数字浪潮的冲击。在这一背景下,文化大数据作为一个多层次的概念网络无疑将在文艺研究中发挥愈加重要的作用。如果说数字人文是使未来文艺研究枝繁叶茂的耕耘重点与前进方向,那么文化大数据则是其中最粗壮的枝干。本文初步阐释了文化大数据对文艺融合研究范式转型的驱动作用,但要想使文化大数据这棵树苗茁壮生长,仍需要有更多纵深式理论挖掘与研究实践。
在当前的现实语境中,文化大数据无论是从基础设施还是从方法层面对于文艺研究的支持作用都尚未得到充分发挥,依然面临诸多问题与挑战。一个不可回避的问题是,以文化大数据为驱动的融合研究范式仍需直面数字人文领域长期以来的批判性论争与学理困境,需要在实践探索中寻求作为文艺研究新形式的合理性通路。应当意识到,与人文研究对于经验主义和科学性的渴望相对应的,是其长期以来形成的内在的保守主义观念。计算机技术与大数据赋予了文艺研究新的理论范式、技术工具及分析方法,但计算的思维方式所造成的局限与定势无疑也需要研究者进行不断反思。尤其是当数据和技术愈发成为一种潜在的研究纲领和研究的可能性条件后,如果我们单纯或过度地依赖数据,将计算机视为“真理机器”,则不可避免地走向数字的暗面。近年来,已有不少学者从意识形态和主体性角度展开对数字人文的集中批判。[43]120-129我们认为这种反思是必要的,然而对于一个方兴未艾的研究领域,更为重要的是如何在更加深入的实践中不断寻找批判性思考的新路径。马克思指出:“全部社会生活在本质上是实践的。凡是把理论引向神秘主义的神秘东西,都能在人的实践中以及对这个实践的理解中得到合理的解决。”[44]501事实上,我们可以将以文化大数据为驱动的一系列探索性研究视为数字人文视野中的一种实践过程。以文化大数据为代表的实践范式,恰恰提供了一种突破数字人文所面临的定位困境,并在数字时代开放流动的对话范式中建立新的分析方法的路径。正如前文所述,所谓的“转型”过程并非是对传统研究方式的根本性颠覆,而是通过不断的互补与借鉴尝试开辟新技术语境中的研究道路,并真正将数据所连接的一系列交叉性实践活动的目标置于具有真知灼见的启发性研究中。相比于数据所传递的信息本身,透过计算界面探索数据背后隐藏的、被传统研究实践所忽略的内容,从而不断延展文艺研究的可能性则更为重要。在这一过程中,围绕文化大数据的实践性探索有助于建立起数字时代有关人类与非人类、人文与技术有效对话的理论体系,并不断对其衍生的新理论进行检视。
从关于实践的讨论出发,我们认为在文化大数据的牵引下,围绕文艺“中心极”的超学科融合研究仍然有很大的空白地带与发展空间。其中尤为值得关注和思考的问题是,如何在实践中更好地发挥国家文化大数据体系建设的优势,将文化大数据的数字资源优势更好地转换为立足于中华文化遗产的学术优势,通过挖掘自身丰富多元的民族传统与文化遗产以构建新时代的文艺理论体系。2021年以来,《文化遗产数字化采集技术要求》《文化资源数据与文化数字内容重构技术要求》等十余项国家文化大数据建设标准先后发布,中华文化的数字化内容和数据库体系的羽翼正日益丰满。在文化大数据体系的建设及应用层面,目前国家文化大数据体系已经形成以文物普查和高清图像为基础的中国文化遗产标本库、以红色纪念馆和国家一级博物馆藏品高精度采集和标注为核心的中华民族文化基因库,以及整合不同类型文化资源的中华文化素材库②等数据库体系。但在纷繁浩大的数字化采集工作背后,从文化大数据到知识生产的通道及实践体系还有待完善。以研究较为集中的中华古籍资源为例,当前工作主要集中于信息处理层面,如古籍数字化转化、内容标注与识别、图像库与知识库构建等,即文化大数据的基础层次。而如何能够将数字化文化资源的利用与前沿大数据分析技术相结合,如何从海量的传统文化数字资源中挖掘出中国古代文论的批评传统与理论传承,孵化出具有汉语理论原创力的成果,还需要大量的探索与思考。最后,数字人文的不断演进,势必催生更多、更加丰富的文艺研究议题、目标、对象及方法。新时代的文艺研究,正在知识体系创新、学科交叉融合的浪潮中,呼唤立足于新的历史阶段与技术背景的研究范式和理论体系的创新。这种转型浪潮不仅是研究层面的,而且同时也是研究者层面的。数字人文学者苏珊·施赖布曼(Susan Schreibman)与霍伊特·朗都强调跨学科参与者的重要性,[45]14-28这也意味着研究者本身需要更好地了解和掌握一定的大数据知识和基于数字技术的分析研究手段,并且能够将人文精神与文艺理念贯穿于研究始终。面对数字时代技术飞速发展变迁的趋势和愈发多元开放的学术环境,研究者不仅需要深刻把握“新文科”战略背景下数字人文实验室等新型实践空间对于交叉型研究团队的支撑作用,而且更为重要的是,需要形成以文艺研究实践为中心的超学科融合意识,真正突破传统研究预设的学科壁垒,将文化大数据的牵引力充分渗入本土化研究的各个层面,推动更多具有中国特色文化身份的创新型研究,在以实践为中心的范式中不断延展数字时代语境中中国文艺理论探索的新向度。
① 拓扑阅读方法是指基于词频分析的方法建立大量文本中特定高频词(组合)之间的拓扑关系,并绘制拓扑图,由此可以发现不同作品在风格上的结构性差异。
② 中华文化素材库包括高校、科研机构和文化企事业单位建成的一系列文化资源数据库,如中华经典古籍库、中国文物志、延安时期文献档案数据库等。
猜你喜欢
环球人物(2022年8期)2022-04-25
甘肃教育(2021年10期)2021-11-02
福建江夏学院学报(2021年6期)2021-08-10
河池学院学报(2021年1期)2021-07-10
大连民族大学学报(2020年2期)2020-06-16
意林·全彩Color(2019年7期)2019-08-13
英语文摘(2019年2期)2019-03-30
英美文学研究论丛(2018年1期)2018-08-16
中华手工(2018年6期)2018-07-17
非公有制企业党建(2017年12期)2017-12-19
