
基于知识图谱的农作物良种问答系统的设计与实现
2024-01-20 06:59李成林赵珍威李国厚侯志松
河南科技学院学报(自然科学版) 2024年1期
李成林,赵珍威,李国厚,侯志松
(河南科技学院信息工程学院,河南 新乡 453003)
农业是国民经济的基础,是人类的衣食之源、生存之本[1].随着全球人口的不断增长,粮食供应和粮食安全问题变得日益严峻,已成为全球面临的重要挑战之一.在农业生产中,种子作为重要的生产资料,直接影响着农作物的生长、产量和质量[2].因此,在解决粮食供应和安全问题的过程中,选用高品质的种子,并对其进行科学的保护和繁育,是确保农作物高产优产的核心环节.
随着基因编辑技术的发展,育种效率得到了显著提高[3].但是,由于市面上农作物品种繁多,农户缺乏相关知识,往往难以选择适合当地生态环境种植的品种.针对这一问题,应当充分考虑农民对农作物品种信息获取的需求,为其提供高效、准确的信息获取渠道,以更好地促进农业生产的发展.传统的农业信息获取方式主要通过农业书籍、杂志、报纸等印刷媒体,或者利用搜索引擎、农业网站等网络媒体获取农作物品种相关信息.但是,这些方式在信息获取效率、实用性、时效性等方面存在一些不足,难以更好满足农民在农业生产过程中的信息需求.随着信息技术的发展,问答系统为农民更好地获取作物品种信息和种植知识提供了新的思路和方法[4].
近年来,在人工智能技术的支持下,问答系统逐渐应用到农业领域.例如,白皓然等[5]提出了一种改进的BiLSTM-CRF(Bidirectional Long Short-Term Memory- Conditional Random Fields,BiLSTM-CRF)模型,设计并开发了农业信息智能问答系统,实现了农业知识的信息化.薛慧芳[6]采用自然语言处理技术和机器学习技术,通过分析用户的历史提问记录和搜索行为,建立了用户偏好模型,利用模型对问题进行分类并推荐相应的技术.Chen Y 等[7]人利用自然语言处理技术和深度学习技术,自动识别非结构化文本中的农业实体,并构建知识图谱,为农业领域的下游任务提供了参考依据.在水稻专家的指导下,Wang H 等[8]利用人工收集和公开数据两种方式获取水稻数据,并成功构建了水稻知识图谱,为农民提供了更加全面的水稻种植技术指导.
虽然问答系统成为人机交互的重要方式,但现有的问答系统大多是基于自然语言处理技术,存在着语义理解和知识表示方面的局限性.相比之下,知识图谱技术可以将数据和知识以图谱的形式进行建模和表示,形成结构化、语义化的知识库,为问答系统提供更加准确、全面的知识支持.然而,尽管基于知识图谱的问答系统具有广阔的应用前景和研究价值,但目前在农业相关研究方面相对较少,需要更多的探索和实践.因此,本文基于知识图谱构建了一个农作物良种问答系统,旨在帮助农民更好地选择和种植适宜的农作物品种.本文的主要研究内容如下:①农作物品种知识图谱的构建;②通过问题预处理模块、问题分析模块和问题求解模块对用户提出的问题进行分析和返回最佳答案;③农作物良种知识问答系统的设计与实现.
1 相关工作
1.1 Scrapy 爬虫
Scrapy 是一个基于Twisted 异步网络库的爬虫框架[9],提供了一组包括调度器、下载器、爬虫序列、实体管道等组件.其框架如图1 所示.
Scrapy 网络爬虫框架各流程功能如下:
Scrapy 引擎:引擎承担着整个爬虫系统的协调、调度和控制任务.它用于控制整个爬虫系统的数据流处理,并触发各种事务.
调度器:调度器用于管理爬虫请求的顺序、处理重复请求以及控制爬虫速度等,通过将爬虫生成的请求发送给下载器下载对应的页面.
下载器:下载器是从互联网上下载农作物品种网页内容,为构建农作物品种知识图谱提供数据源.
爬虫序列:爬虫序列是从特定的网页中提取所需信息的规则集合,为爬虫提供了数据抓取和处理的基础.
项目管道:项目管道负责处理爬虫从网页中抽取的项目数据,为爬虫的数据处理和存储提供了关键支持.
1.2 知识图谱
知识图谱是一种表示和组织知识的方式,将现实世界中的实体、概念以及它们之间的关系抽象为可视化形式,从而构建一个系统、全面、准确的知识体系[10].知识图谱已成为自然语言处理[11-12]、推荐系统[13-14]、智能问答[15-16]等领域中重要的研究方向,引起了学术界和企业界的广泛关注.企业可以利用知识图谱技术构建本身的知识图谱,为用户提供更精准、更智能的服务.例如,在搜索引擎领域[17],知识图谱可以提高搜索准确率和检索效率,为用户快速找到自己需要的信息提供帮助.在医学领域[18],知识图谱可以帮助医生快速准确地了解疾病的诊断、治疗和预后,从而更好地支持临床决策和医疗工作.在农业领域[19],农业人员可以获得全面、精准、及时的农业知识.
1.3 BiLSTM-CRF 模型
BiLSTM-CRF 应用于自然语言处理领域,是一种结合了双向长短时记忆网络和条件随机场的神经网络模型,用于解决序列标注任务[20].BiLSTM-CRF 模型主体包括嵌入层、BiLSTM(Bidirectional Long ShortTerm Memory,BLSTM)层和CRF(Conditional Random Fields,CRF)层,模型图如图2 所示.
输入层:模型的输入为序列文本,本文使用农作物品种的字符序列作为输入.
嵌入层:嵌入层的工作是将字符序列中的数据转换为计算机可以处理的向量表示,为BiLSTM层做序列编码的铺垫.
BiLSTM层:BiLSTM层由前向LSTM层和后向LSTM层组成,它可以同时考虑前向和后向的上下文信息,从而更好地捕捉序列中的依赖关系和语义信息.BiLSTM层输入的是嵌入层输出的向量序列,输出的是一个包含上下文信息的隐藏状态序列,可作为CRF 层的输入.
CRF 层:CRF 层用于对输入序列进行标注,并考虑标签之间的依赖性关系,以提高标注的准确性和泛化性.
输出层:输出层的功能是将BiLSTM层提取的上下文信息和CRF 层建模的标签之间的依赖关系结合起来,生成对输入序列进行标注的最终输出标签序列.
2 农作物品种知识图谱构建
在构建农作物品种知识图谱的过程中,通常采用由农业专家设计的本体模式来描述农作物品种的各种属性和关系.本文结合了农业专家的指导,参考朱银等[21]和Jarvis 等[22]在农业领域的工作,并在此基础上增加了农作物品种特有属性.为了保证知识图谱的准确性,本文进行了本体层构建、数据预处理、知识抽取和知识融合等步骤.经过这些步骤,最终构建了农作物品种知识图谱,为下游的问答系统提供了高质量的知识支持.农作物知识图谱构建流程图如图3 所示.
2.1 本体层构建
本体构建的准确性和覆盖性对整个知识图谱的构建至关重要.本文根据农作物品种关键词,结合农业专家的建议,考虑真实情况选出具有代表性的农作物品种的核心类目,然后使用本体构建工具,采用七步法进行农作物品种本体构建.具体步骤如下:
(1)确定农作物品种本体的构建范围.根据农业专家的建议和需求分析确定构建本体的对象,以中国种业大数据平台作为数据的主要来源,确定以农作物品种内容要素为研究对象.
(2)考虑复用现有的本体.在构建农作物品种本体之前,本文通过研究DBpedia 和Wikidata 中已有的农业本体,并根据我们的需求和目标进行筛选和修改,构建农作物品种本体.
(3)列出本体所涉及的农作物品种的重要术语.提取农业领域的专业术语的路径主要有3 个:①从农业著作和论文等文献中进行人工筛选;②从农业词库中提取;③从网页中进行爬虫.通过以上途径获取的专业术语经过农业领域专家的审核和确定,对农作物相关知识进行系统性的分析.
(4)定义分类概念和概念分类层次.本文使用混合的方法构建农作物品种知识图谱.
(5)定义属性和关系.本文通过定义属性和关系,可以更加准确和详细地描述农业领域的内部结构和成员之间的关系.
(6)定义本体属性约束.在将农业加入到本体中时,可以通过定义本体属性约束限制和规范农业领域内部属性值的取值范围和类型,以确保本体的准确性和一致性.
(7)构建农作物品种本体实例.完成对农作物品种本体类、对象属性和数据属性的添加,利用本体构建工具对农作物品种相关的审定内容、特征特性、农作物病害等实例和属性值进行添加,最终形成农作物品种知识组织体系,如图4 所示.
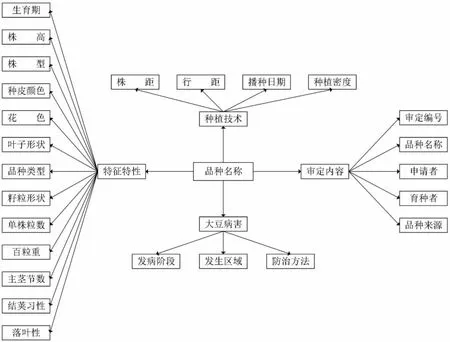
图4 大豆品种本体建模设计Fig.4 Design diagram of soybean variety ontology modeling
图4 为本文构建的大豆品种本体建模设计图,小麦、玉米、水稻和花生与大豆品种本体建模设计类似.图4 展示了每一种农作物品种的实体之间的关系,例如:大豆病害与发病阶段之间存在“发病”的关系、审定内容与申请者之间存在“审定”关系等.
2.2 数据获取与预处理
2.2.1 数据获取本文通过Scrapy 框架在中国种业大数据平台获取了包括小麦、玉米、大豆、棉花和水稻5 种农作物在内的、共计1 634 个农作物品种数据.不同农作物的信息来源和数量如表1 所示.

表1 农作物信息来源和数量Tab.1 Crop information sources and number of varieties
2.2.2 数据预处理为构建农作物品种知识图谱,本文采用爬虫技术获取大量文本数据.然而,由于这些数据存在繁体字、非文本信息、停用词和单位量词不统一等问题,因此为提高数据质量和准确性,本文对文本数据预处理的具体方法如表2 所示.

表2 数据预处理方法Tab.2 Data processing method
经过数据预处理,定义了5 类实体和69 个属性,具体信息如表3 所示.其中第一行为小麦、玉米、大豆等5 种农作物的公共属性,而第二至第六行分别为这些农作物各自的特有属性.

表3 实体类型及其属性表Tab.3 Entity types and their attributes
2.3 知识融合
多源异构的数据源能够丰富知识图谱的数据量,但数据源中经常存在许多重复、异名同义的实体.如果直接使用预处理后的数据构建知识图谱,必然会产生知识冲突与冗余.为保证设计问答系统的准确性,需要通过知识融合相关技术对数据进行处理,获取后的数据可以构建知识图谱的数据.本文利用规则和实体对齐方法构建了一套农作物品种别名实体库,并在此基础上通过实体映射融合多源数据.本文使用的部分实体别名如表4 所示.

表4 部分实体别名表Tab.4 List of partial entity names
2.4 知识存储及可视化
为了实现农作物品种知识图谱的查询和分析,本文采用适当的存储和管理技术.Neo4j 图数据库是一种高效的知识图谱存储和管理技术,可以提高查询和处理效率,优化知识图谱的可视化效果.
Neo4j 采用Cypher 语言进行数据库管理和查询.为了构建农作物品种知识图谱,将预处理后的数据按照Cypher 语句要求的CSV 格式进行转换.转换完成后,通过Python 的Py2neo 库将整理好的CSV 文件导入Neo4j 图数据库中,从而完成农作物品种知识图谱的构建.农作物品种知识图谱局部结构图如图5 所示.
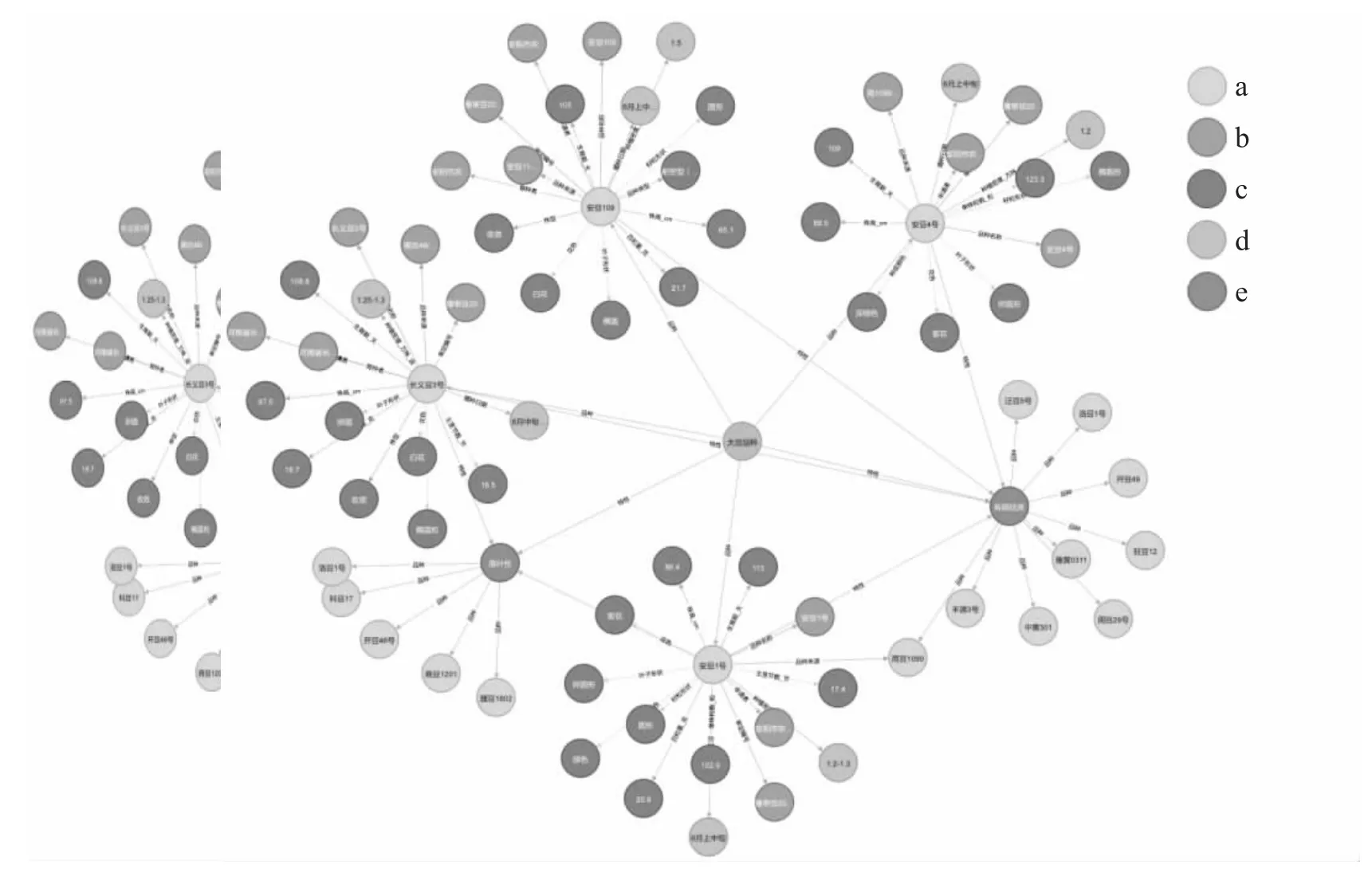
图5 农作物品种知识图谱局部结构图Fig.5 Partial Structure Diagram of Crop Variety Knowledge Graph
图5 为农作物品种知识图谱局部结构图.该知识图谱包含了39 933 个实体节点,297 308 条关系.其中,a 为大豆品种,b 为农作物审定内容,c 为农作物特征,d 为种植技术,e 为大豆的特性.农作物品种知识图谱提供了更好地了解农作物品种、特征和种植技术等信息,能够为农业领域的数据分析、知识发现和智能决策等方面提供强有力的基础数据支持.
3 基于知识图谱的农作物良种问答系统
本文设计并开发的农作物良种问答系统总体架构图如图6 所示,主要包括前端和后端两大模块.前端模块主要包括问题的输入和答案的输出;后端模块主要包括问题预处理、问题分析和问题求解三部分.首先,对问题进行中文分词、词性标注和实体识别等预处理;其次,通过对用户输入的问题进行分类,根据分类的结果进行问句模板的匹配;最后,将匹配的问句模板,生成查询语句,在Neo4j 图数据库中进行答案查询并返回最终的答案.
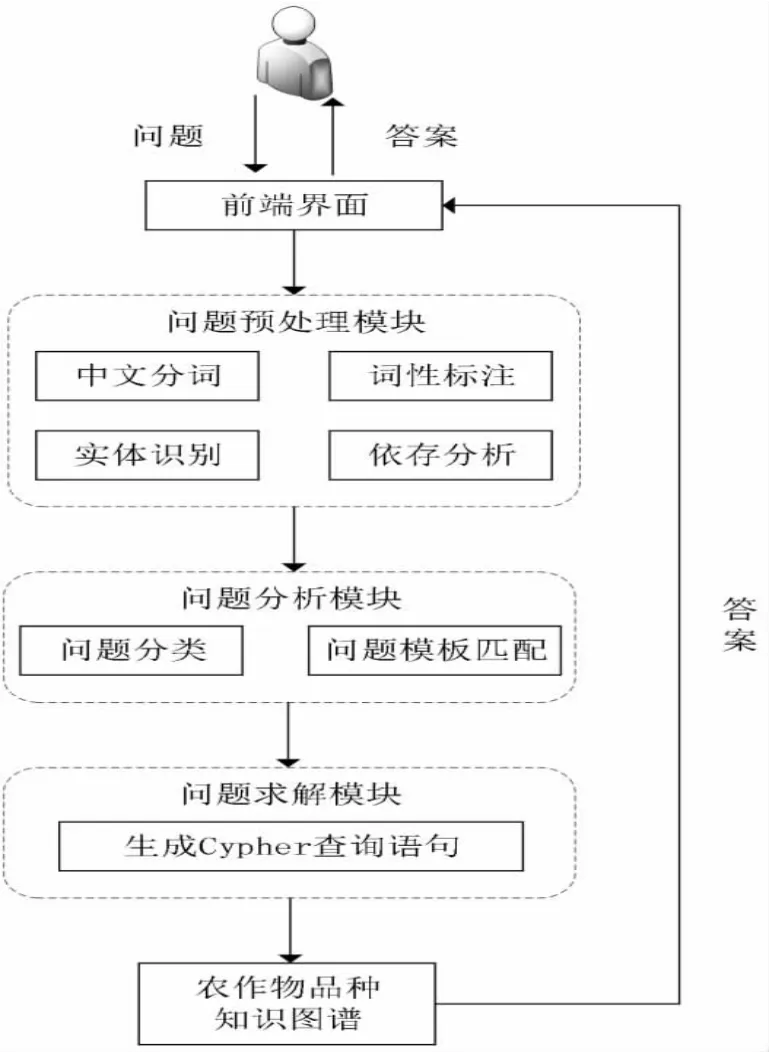
图6 农作物良种问答系统架构图Fig.6 Architecture Diagram of Crop Elite Variety Question-Answering System
3.1 中文分词
分词是中文加工的第一步.它将一段连续的自然语言文本按照一定的规则或算法进行切割,将文本划分为具有语义的单元.中文分词是自然语言处理中的一个重要环节,为后面的词性标注、句法分析及文本分析打下坚实的基础.目前常见的分词工具主要有Jieba、HanLP、NLPIR、LTP、THULAC 等.本文使用由清华大学自然语言处理与社会人文计算实验室研发的THULAC 分词工具[23]进行中文分词和词性标注.词性标注示例表如表5 所示.

表5 词性标注示例表Tab.5 Examples of part-of-speech tagging
3.2 农作物品种实体识别
中文分词和词性标注后,将标注好的数据输入到BiLSTM-CRF 模型中[24].由于BIO 标注[25]提供模型需要的真实标签,因此本文采用BIO 标注方案对农作物品种实体识别进行标注,其中B(Begin)代表的是一个实体的开始,I(Inner)代表的是一个实体的中间,O(Other)代表的是非实体.根据问答系统最后测评的准确率可以得出还需要进一步改进BiLSTM-CRF 模型.
3.3 语义依存分析
本文在农作物品种实体识别后,使用LTP-parser 对问句依存句法分析,得到问题与实体之间的关系.LTP-parser 是一种基于语言技术平台的词组分析工具,可以帮助用户分析句子中的词组,并获取词组的依存句法关系,从而更好地理解句子的含义.依存句法分析标注关系及含义如表6 所示.
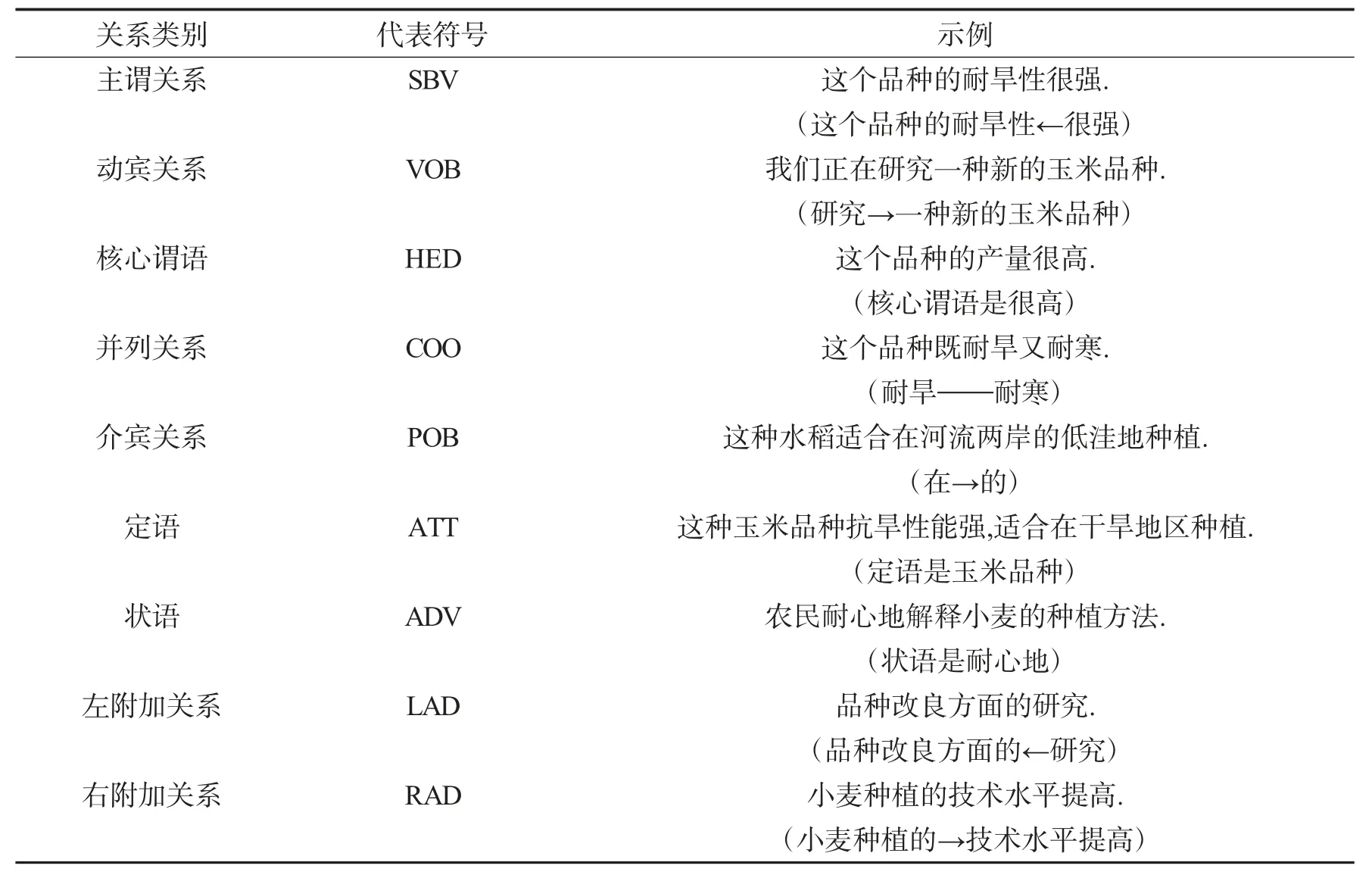
表6 依存句法分析标注关系及含义Tab.6 Dependency parsing tagging relationship and meaning
如问题“中豆49 使用什么药物来预防病害?”依存句法分析如图7 所示.在农作物品种命名实体识别之后可得到“中豆49”品种实体,与“中豆49”实体关联的动词是“使用”,“使用”的宾语是“药物”.动词“使用”这个词使“中豆49”与“药物”之间建立了关系,形成了<中豆49,使用关系,药物>的三元组.

图7 依存句法分析Fig.7 Dependency parsing
3.4 问题分类
根据获取到的农作物品种数据,本文将常见问题分为四类:审定信息类问题、品种特征类问题、品种病虫害类和品种种植技术类问题.审定信息类问题主要回答“品种审定的基本信息”;品种特征类问题主要回答“品种的特性”;品种病虫害类问题主要回答“品种生长过程中可能有哪些病虫害”;品种种植类问题主要回答“品种种植过程中的栽培技术要点”.农作物品种问题分类如表7 所示.

表7 农作物品种问题分类表Tab.7 Classification of crop varieties
3.5 问题模板匹配
为了在农作物品种知识图谱中查询到问题的答案,将问题三元组转换为问题类别分别对应的Cypher 查询语句.农作物品种部分特征查询模板如下:
(1)生育期类问题Cypher 查询模板
MATCH(a:wcros)- [rel:生育期]->(b:wcros_growthperiod)where a.name="{name}" return b.growthperiod'
(2)穗粗类问题Cypher 查询模板
MATCH(a:wcros)- [rel:穗粗cm]->(b:c_eardiameter)where a.name="{name}"return b.eardiameter'
(3)株高类问题Cypher 查询模板
MATCH(a:wcros)-[rel:穗位高cm]->(b:c_spikeheight)where a.name="{name}"return b.spikeheight
(4)衣分类问题Cypher 查询模板
MATCH(a:wcros)-[rel:衣分]->(b:co_ginningoutturn)where a.name="{name}"return b.ginningoutturn
(5)株型类问题Cypher 查询模板
MATCH(a:wcros)- [rel:株型]->(b:wcros_planttype)where a.name="{name}"return b.planttype
3.6 答案生成
农作物品种问答系统利用Py2neo 模块实现了Neo4j 数据库的查询接口,并使用Cypher 查询语句在知识图谱中查询相关的三元组.根据用户提出的问题类别,系统选择不同的查询模板,并根据查询结果将最佳的答案返回给用户.
4 实验验证
4.1 问答系统演示
本文面向农业领域开发了一种基于知识图谱的农作物良种问答系统.该系统使用Flask 框架作为Web 框架,Neo4j 作为后端数据库,主要使用Python 语言,可视化界面使用的技术是HTML、JQuery、CSS.问答系统界面如图8 所示.用户可以提问农作物品种相关的问题,系统将自动回答用户提问的问题.

图8 问答系统界面Fig.8 Interface of Question Answering System
4.2 系统性能分析
为了测试农作物品种问答系统的准确性,在专家指导下,设计了300 个与农作物品种有关的问题作为问答系统的测试数据,对系统返回的答案进行测评,以检验问答系统的性能.本文使用准确率进行分析.分析见式(1)
式(1)中:P 代表准确率,t 代表回答正确问题的条数,T 代表测试问句的条数.
农作物品种数据集下问答系统测评结果见表8.

表8 农作物品种数据集下问答系统测评结果Tab.8 Evaluation results of question and answer system under crop variety data set
通过表8 可知,在专家指导下设计的4 类问题中,审定信息类问题回答效果最好,品种特征类问题回答效果较差,系统的平均回答准确率为87.67%.分析得出,本文开发的问答系统能够较好地回答农作物品种方面的问题.由于数据集中品种特征类问题的数据存在大量缺失值,因此该类问题的回答准确率较低.
5 结论
基于中国种业大数据平台,通过数据预处理、本体构建和知识融合等步骤,本文构建了一个农作物品种知识图谱.该知识图谱包含了审定信息、品种特征、品种病虫害等信息,结合BiLSTM-CRF 模型实体识别、LTP-parser 依存句法分析和Cypher 查询语句等技术构建了一个农作物良种问答系统.该系统能够根据用户的需求和条件,推荐适合当地生态环境的良种.实验表明,本文构建的农作物良种问答系统在回答准确性和推荐效率方面表现优异,回答准确率达87.67%,能够满足农户的生产需求.未来的研究工作将进一步完善农作物品种知识图谱,包括扩充数据集、增加属性等.同时,不断优化推荐算法,探索更加精细、个性化的推荐策略,提高系统的推荐准确性和效率,为提高农业生产效率做出更大贡献.
猜你喜欢
哲学分析(2023年4期)2023-12-21
今日农业(2022年16期)2022-11-09
房地产导刊(2022年10期)2022-10-18
今日农业(2022年15期)2022-09-20
今日农业(2022年13期)2022-09-15
今日农业(2021年16期)2021-11-26
现代信息科技(2021年21期)2021-05-07
中国音乐学(2020年4期)2020-12-25
电子测试(2018年1期)2018-04-18
电子制作(2017年9期)2017-04-17
