
基于Web挖掘的信息抽取系统的研究
2010-01-06 03:45方少卿胡学钢
铜陵学院学报 2010年4期
方少卿 胡学钢
(1.合肥工业大学,安徽 合肥 230009;2.铜陵职业技术学院,安徽 铜陵 244000)
基于Web挖掘的信息抽取系统的研究
方少卿1,2胡学钢1
(1.合肥工业大学,安徽 合肥 230009;2.铜陵职业技术学院,安徽 铜陵 244000)
文章讨论了Web挖掘的一些基本概念,针对Web数据的特点提出了一个基于Web挖掘的信息抽取系统的结构模型。模型通过对XML文档的解析生成DOM树,在此基础上,通过对样本页的DOM树的先序遍历生成抽取规则,再以此规则对Web页进行数据抽取,所抽取的数据保存在数据库中,以便利用数据库技术进一步利用这些数据。
Web挖掘;信息抽取;抽取规则
在当今信息社会,随着Internet的迅猛发展,因特网上的信息资源呈爆炸式增长。Web已成为人类传播与共享科技、教育、商业和社会信息最重要和最具潜力的巨大信息源,其中蕴含着大量具有潜在价值的知识。同时也带来了如何有针对性地快速获取有效信息的严重挑战。如何快速高效地从其中搜寻到所需要的内容?已成为人们越来越迫切的渴望,作为解决这一需求的研究领域——Web挖掘(Web Mining)应运而生,并成为目前研究的一个热点。
一、Web挖掘概述
1.Web挖掘的定义
Web挖掘是由Oren Etzioni在1996年首先提出的,“data mining on the Internet”(因特网的数据挖掘)、“Knowledge Discovery in Web”(网络信息知识发现)、“网络信息挖掘”、“Web信息挖掘”等可以认为也是Web挖掘的同义词。Web挖掘是一门综合性的技术,涉及信息检索、统计学、模式识别、神经网络、机器学习、数据库技术、自然语言处理以及Web技术等领域。Web挖掘目前尚无统一的定义。下面是关于Web挖掘定义的几种典型描述:
(l)运用数据挖掘技术从World Wide Web中发现和分析有用的信息。
(2)从WWW相关的资源和行为中抽取感兴趣的、有用的模式和隐含信息。
(3)所谓Web挖掘是指从大量的数据集合c中发现隐含的模式p。如果将c看作输入,将p看作输出,那么Web挖掘的过程就是从输入到输出的一个映射ξ∶c→p。
2.Web挖掘的分类
与传统的信息资源相比,Web信息资源有着信息海量、数据环境异构、数据源的半结构化等特性,Web数据复杂而类型多样,Web数据的多样性决定了Web挖掘任务的多样性。根据挖掘对象的不同,Web挖掘可以分为Web内容挖掘(Web content mining)、Web 结构挖掘(Web structure mining) 以及Web使用记录挖掘(Web usage mining),如表1所示。Web内容挖掘又分为Web文本挖掘和Web多媒体挖掘。
Web信息抽取(Web Information Extraction简称Web IE)属于Web内容挖掘范畴。目前Web数据大都以半结构化的HTML形式出现,由于HTML缺乏对数据本身的描述,不含清晰的语义信息,模式也不明确。这使得应用程序无法直接解析并利用Web上的海量信息。Web信息抽取技术通过包装现有Web信息源,采用一定的方式增加了语义和模式信息,将网页上的信息以结构化的方式抽取出来。现有的Web信息抽取技术不但可以直接定位到用户所需的信息,而且为Web查询提供了更为精确的方法,使应用程序利用Web中的数据和Web信息的再利用成为可能。
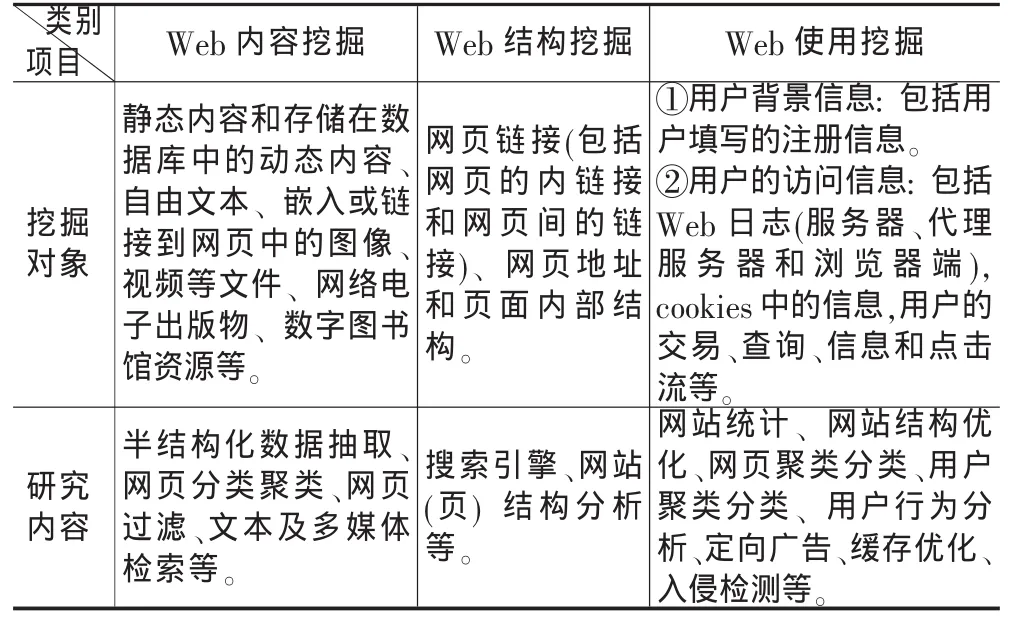
表1 Web挖掘分类
3.Web挖掘的步骤
与传统数据库和数据仓库相比,Web上的信息是非结构化或半结构化的、动态的、并且是容易造成混淆的,所以很难直接对Web网页上的数据进行挖掘,必须经过数据处理,Web挖掘主要的处理过程是对Web文档集合的内容进行分词处理、特征提取、结构分析、文本摘要、文本分类、文本聚类、关联分析等。
典型Web挖掘过程一般可分成以下四个阶段,如图1所示:
(1)数据采集:Web环境目前能提供的数据源包括Web页面数据、超链接数据、电子邮件、新闻组、网站的日志数据以及通过Web形成的交易数据库。按照主题相关的原则,数据采集主要是采集Web网页,即检索所需的网络文档,为后面的Web挖掘提供素材和资源;
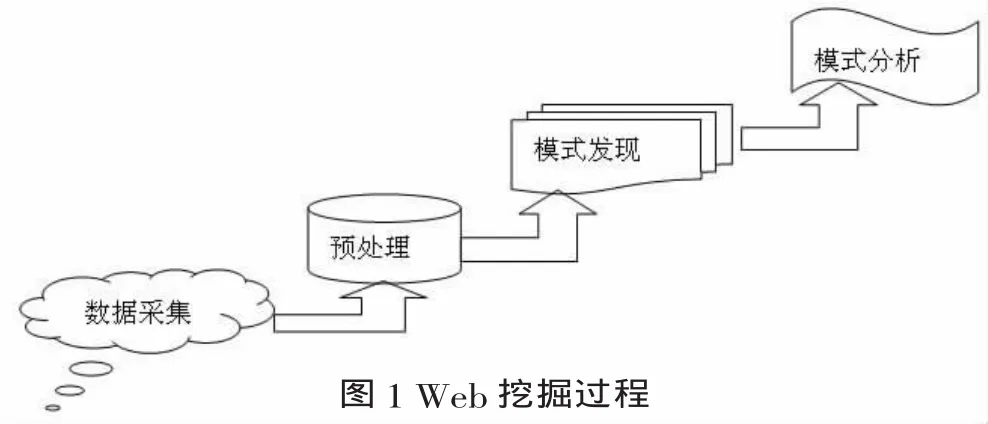
(2)信息筛选和预处理:从获取的网页中自动筛选和预处理特定的信息。数据的预处理是对源数据进行加工处理和组织重构,为下一步的Web挖掘提供基础平台,做好前期准备。它包括:数据整理、数据集成、数据转换和数据约简等工作;预处理过程是Web挖掘过程中最关键的一环,处理质量关系到后面挖掘过程和模式分析过程的质量。
(3)模式发现:通过实施挖掘算法,例如关联规则挖掘算法,序列模式挖掘算法和分类、聚类算法,发现存在于单个网站或跨越多个网站的潜在的、有用的模式。
(4)模式分析:对所挖掘的模式进行评估,验证并解释上一步骤产生的模式,该工作可以是机器自动完成,也可以是与分析人员进行交互来完成。利用一些方法和工具对挖掘出的模式、规则进行分析,找出我们感兴趣的模式和规则。通过模式挖掘之后,生成的规则数目可能非常庞大,表达也可能比较晦涩,因此需要对模式进行分析评价,并将结果以易于理解和接受的方式显现出来。
二、基于Web挖掘的信息抽取系统
本文采用的数据源是基于数据导向型页面,通过对数据导向型页面结构特点分析得到启发式规则——页面中大量表现形式相同的信息块就是关键信息。故本文研究基于以下假设:
☆ 待抽取页面和样本学习页面包含要抽取的信息。
☆ 一个页面中含有相似的信息块,如果用搜索引擎进行搜索,搜索结果的展示方式应该是一样的。
本系统抽取前提是基于格式良好的XML文档。采用XML表示抽取结果的原因是:
☆ XML数据结构性很强,可以直接被其他系统访问。这样信息抽取系统可以方便地为信息集成、信息过滤等其他重要的信息抽取结果的系统服务。
☆ 抽取结果可以很容易地表示和转换为不同格式,满足不同用户的需要。
1.基于Web挖掘的信息抽取系统框架
首先通过网络爬虫heritrix获取Web站点的数据(多数为HTML文档),再利用W3C Tidy工具对HTML源码进行清洗整理处理并生成格式良好的XML文档,通过对XML文档解析得到该文档的DOM树结构,通过对DOM树进行先序遍历,得到文档的内容,再通过用户交互选择将感兴趣文本信息抽取出来保存至数据库中,同时利用这些信息生成一组规则,将此规则加入到某一规则模板中,某个规则模板中的规则可以通过多个相似结构的样本页学习来提高规则的健壮性。利用这些规则对相似结构的Web页文本数据进行挖掘,并将挖掘到的数据存入数据库。具体系统结构框架见图2。

图2基于Web就业信息抽取系统结构图
从图2可知系统包含数据采集模块、数据整理模块、信息抽取模块三部分,其中信息抽取模块是本系统的核心。
2.数据采集模块
首先通过heritrix获取整个Web站点的数据,即得到Web站点的镜像,这些数据作为信息抽取的信息源,是整个信息抽取系统的起点。
3.数据整理模块
主要针对待学习页面和待抽取页面进行优化处理,将结构不完整或不规范的HTML页面转化成为结构良好的XHTML文档。为加快清理速度和提高清理质量,先清理