
关于理想点多属性决策方法中权值的确定
2010-05-18 08:03肖小英
统计与决策 2010年9期
肖小英
(江西理工大学 南昌校区,南昌 330013)
1 理想点评定法及权值的确定
理想点评定法(TOPSIS法),又称“逼近于理想解的排序方法”[1],是多目标有限方案决策分析的一种常用决策方法,具有计算简便、结果合理、应用广泛等特点。它借助于多目标决策问题的“正理想点”和“负理想点”,正理想点是一假设的最好方案,它的各属性值都达到各候选方案中最好的值,负理想点是另一假设的最坏方案,它的各属性值都达到各候选方案中最差的值。通过计算某一方案与最好方案和最坏方案间的加权欧式距离,得出该方案与最好方案的接近程度,以此作为评价该方案优劣的依据[1],从而实现对方案进行排序的一种决策方法。
理想点评定法中各属性指标权重的确定通常有二类方法,一是主观法,主观法是由决策分析者根据以往经验和属性的重要程度而赋权的方法,主要有:专家调查法[1]、最小二乘法[1]环比评分法[2]、层次分析法[3]等;客观法是指单纯利用属性的客观信息而确定权重的方法,主要有信息熵法[4]、线性规划法[5]等。主观法所确定的属性权重体现了决策者的意向,但决策或评价结果具有较大的主观随意性,由此会带来决策方案选择上的偏差和失误。客观法所确定的属性权重具有较强的数学理论依据,例如,为了减少权值确定当中的主观性和随意性,东南大学的徐泽水先生提出了基于优化模型的理想点评定法[6-7]。其主要思路如下:
(1)首先在规范化决策矩阵中,设定正理想点为Z+[1,1,…,1],负理想点为 Z-=[0,0,…,0],待确定的属性指标权重为W=(w1,w2,…,wm)。
(2)由于决策方案ai越接近正理想点越优,可令方案ai与正理想点之间的加权偏差为
(其中 Y=|yij|nm,i=1,2,…,m 为规范化数据矩阵)。
(3)对于确定的权重向量 W=(w1,w2,…,wm),ei+(w)越小方案ai越优,于是可建立多目标决策模型:
由于每个方案都是公平竞争,不存在任何偏好关系,则可将上述模型等权集结为如下的单目标模型:
解此单目标规划模型,就可以得到权重向量W=(w1,w2,…,wm)。
在上述方法中,虽然权重的确定剔除了任何人为因素的影响,但是也带来了其他的问题:一是上述单目标规划最优解的存在性问题?二是假如其存在最优解,得到了最优权重向量W=(w1,w2,…,wm),但这却是为使得每一方案与正理想点的加权偏差最小的属性指标权重,而不是属性指标按重要性比较的真正权重,这样的权重会随着样本数据的变化而变化。
例如,评价某一地区企业的创新能力问题。假如设定的属性指标为:R&D经费投入占销售收入的比重(X1)、科技人员占从业人员比重(X2)、技术装备水平(X3)、新产品销售收入占产品销售收入的比重(X4)、新产品销售利润占利润总额的比重(X5)、拥有发明专利数(X6)、技术性收入占销售收入的比重(X7)。对于评价5个企业和7个企业的样本决策矩阵数据(如表1和表2所示)。
将这两个决策矩阵进行向量规范化后,代入模型(1),所得到的最优权重向量分别为:

因此,对于评价企业的创新能力这个主题,在这两个问题中的属性指标完全一样,并且前5个企业的数据完全一致,但是属性指标在这两个问题中却表现出了不同的重要性权重,这是不合情理的。
2 基于主成分的属性指标权重确定
为了减少属性指标权重确定中的主观性随意性,以及指标权重随样本数据变化而变化的缺点,真正体现权重表示指标的重要性之比,本文认为以下的基于主成分分析的权重确定方法具有更好的适用性。
主成分分析[9]是设法将原来众多具有一定相关性的m个指标Xj,重新组合成一组新的相互无关的p(p≤m)个综合指标Fk(称为主成分)来代替原来的指标,并且用每一主成分的方差Var(Fk)来表示该主成分综合原来指标信息的多少。如果方差Var(Fk)越大,说明第k主成分Fk包含原来指标的信息越多。这也就说明在所有的主成分中,Fk的作用越大。因此,我们可以用某一主成分的方差Var(Fk)在所有主成分方差中所占的比例来表示该主成分的权重。本文将基于主成分的属性指标权重确定方法叙述如下:
(1)将样本决策矩阵进行标准化处理
设样本决策矩阵为:X=|xij|n×m,
为了消除不同指标间的量纲影响和正、逆指标的影响,将样本数据按下式标准化,得标准化后的矩阵为Y=(yij),yij=

(2)计算相关系数矩阵的特征值与特征向量
用标准化后的矩阵的m个向量作线性组合
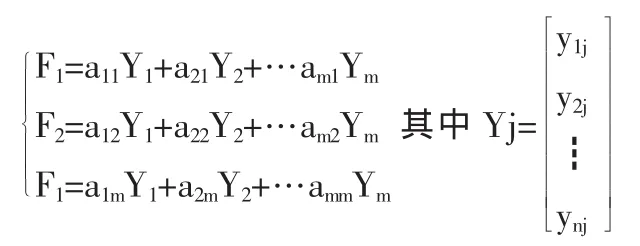
则F1,F2,…,Fm就为m个主成分。我们希望在这些主成分中,越在前面的包含原有指标的信息越多,而包含信息的多少一般用方差来表示,所以主成分F1,F2,…,Fm需要满足以下条件:
①Fi与 Fj(i≠j,i,j=1,2,…,m)不相关;
②F1是X1,X2,…,Xm的一切线性组合中方差中最大的,F2是与F1不相关的X1,X2,…,Xm的一切线性组合中方差中最大的,……,Fm是与 F1,F2,…,Fm-1都不相关的 X1,X2,…,Xm的一切线性组合中方差中最大的。
可以证明,满足上述条件的主成分F1,F2,…,Fm线性组合中的系数向量(a1i,a2i,…,ami),i=1,2,…,m 恰好是 Y 的协方差矩阵Σ的特征值对应的特征向量。当协方差矩阵Σ未知时,可用其估计值S(样本协方差矩阵)来代替。
S=(sij) 其中
而相关系数矩阵:R=(rij) 其中
由于 Y1,Y2,…,Ym已标准化,所以有
计算时为简单起见,不妨取R=YTY,因为这时的R与YTY只相差一个系数,显然YTY与的特征根相差n倍,但它们的特征向量不变,并不影响求主成分。
由特征方程|λE-R|=0可求得相关系数矩阵R的m个特征值为 λ1,λ2,…,λm,将其按大小顺序排列 λ1≥λ2≥…≥λm≥0,然后再由(λiE-R)X=0求出对应于每一特征值λi的特征向量(a1i,a2i,…,ami),i=1,2,…,m。
设相关系数矩阵 R 的 m 个特征值为 λ1,λ2,…,λm,称第一主成分的贡献率为λ1它是第一主成分的方差在全部方差中的比值,这个比值越大,表明第一主成分综合原指标X1,X2,…,Xm信息的能力越强。前两个主成分的累计贡献率为,前k个主成分的累计贡献率为如果前p个主成分的累计贡献率达到85%以上,表明取前p(p≤m)个主成分基本包含了全部测评指标所具有的信息,这样既减少了变量的个数,又便于对实际问题进行分析和研究。
(3)提取p个主成分的权重系数
将累计贡献率达到85%以上的p个主成分F1,F2,…,Fp作为理想点评定法中的属性指标,并将矩阵 Z=F1,F2,…,Fp」n×p作为理想点评定法中的规范化矩阵,F1,F2,…,Fp的权重为即为各主成分的方差贡献率。
3 实例验证
仍以表1和表2中的数据为例,用基于主成分的权重确定方法计算结果如下:
(1)对于表1中5个企业的数据,获得4个主成分及权重如下表3。
(2)对于表2中7个企业的数据,获得6个主成分及权重如下表4。
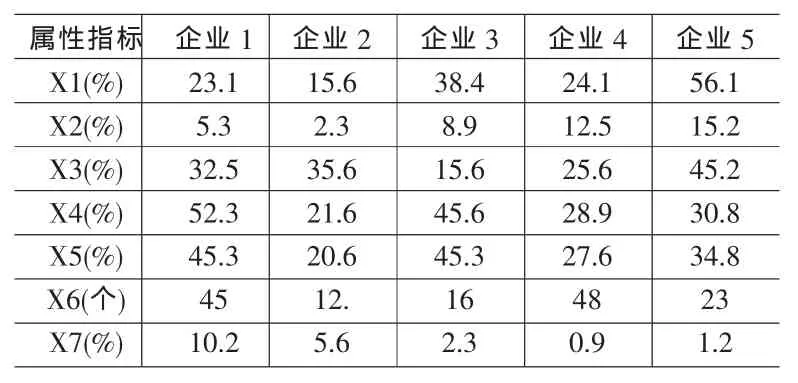
表1 5个企业的创新能力指标样本值
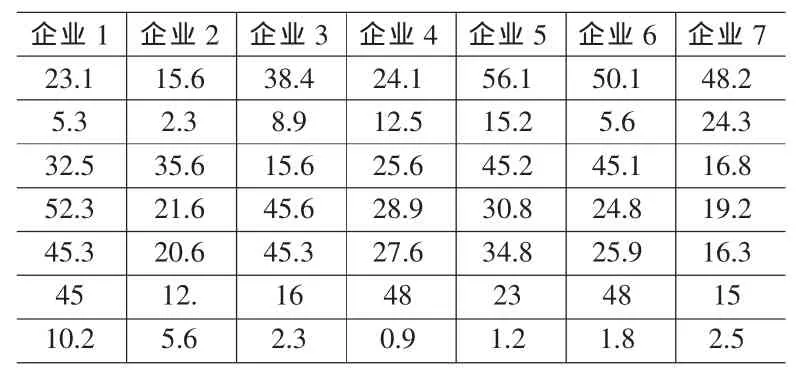
表2 7个企业的创新能力指标样本值
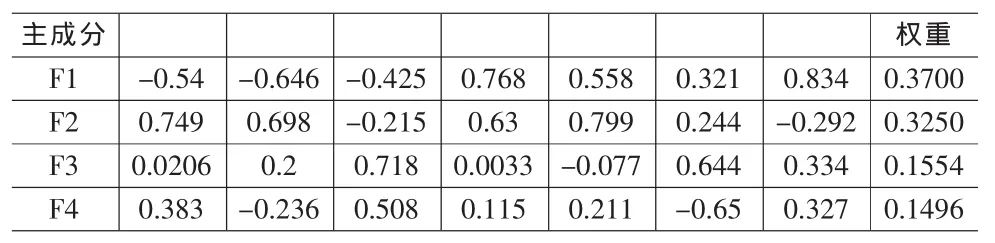
表3 5个企业的主成分及权重

表4 7个企业的主成分及权重

表5 5个企业的综合排序情况

表6 7个企业的综合排序情况
4 结论
本文将决策问题中的m个属性指标X1,X2,…,Xm通过选择适当的线性组合,将其综合成互不相关的p个新的主成分指标来反映原指标的信息,并通过计算主成分的方差贡献率,得到了主成分指标的权重,从而获得了理想点评定法中的属性指标的权重。这种方法完全基于样本数据信息,在指标权重选择上克服了主观因素的影响,避免了人为因素带来的偏差,有助于保证客观地反映样本间的现实关系。并且对于综合样本信息多的指标赋予了较大的权重,对于综合样本信息少的指标赋予了较小的权重,这也符合了指标权重表示指标重要性的基本含义。
虽然从表3和表4看到的是,5个企业和7企业获得的主成分个数不一样,得到的权重也不一样。这是因为不同主成分所包含的原样本信息不一样,包含信息多的,权重取值相对大一些,包含信息少的,权重取值相对小一些。而利用这些主成分和权重计算的企业排序却具有相对的稳定性,如下表5和表6所示。
[1]岳超源.决策理论与方法[M].北京:科学出版社,2004.
[2]陆明生.多目标决策中的权系数[J].系统工程理论与实践,1986,6(4).
[3]T.L.Saaty.The Analytic Hierarchy Process[M].New York:Mc Graw-Hill,1980.
[4]郭显光,多指标综合评价中权数的确定,数量经济技术经济研究,1989,6(11).
[5]Pekelman D,San S K.Mathematical Programming Models for the Determination of Attributes Weights[J].Management Science,1974,20.
[6]徐泽水.不确定多属性决策方法及应用,北京:清华大学出版社,2004.
[7]钱钢,徐泽水.三种基于理想点的不确定多属性决策最优化模型[J].系统工程与电子技术,2003,25(5).
猜你喜欢
金桥(2022年7期)2022-07-22
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09
汽车观察(2021年11期)2021-04-24
中学生百科·大语文(2021年2期)2021-03-08
花火彩版A(2021年11期)2021-02-08
当代陕西(2020年17期)2020-10-28
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
人大建设(2018年5期)2018-08-16
初中生世界·九年级(2017年10期)2017-11-08
