
基于机器学习的上市公司财务预警模型的构建
2010-05-18 08:03蒋盛益蔡余冲
统计与决策 2010年9期
蒋盛益 ,汪 珊,蔡余冲
(广东外语外贸大学a.信息学院,b.财经学院,广州 510420)
陷入经营危机的企业几乎毫无例外地都是以出现财务危机为征兆。财务危机的出现有一个逐步显现、不断恶化的过程,最终会通过财务指标反映出来。因此,财务管理作为企业经营管理的一个重要组成部分,自然也要求建立相应的财务预警系统。构建一个有效的财务危机预警模型,及早获得上市公司财务状况出现严重恶化的预警信号,满足利益相关者日益迫切的需要,具有很重要的研究价值和现实意义。此外,正确预测企业财务风险,对于保护投资者和债权人的利益、经营者防范财务危机,以及政府管理部门监管上市公司质量和证券市场风险,都具有十分重要的现实意义。本文采用多种机器学习方法对2005~2007年的非金融企业上市公司财务数据进行了分析。
1 数据样本选取
本文实验的原始数据来源于CCER中国上市公司非金融企业财务数据库中2000~2007年一般上市公司的真实财务报表数据,将中国证券市场中上市公司被ST(特别处理)和被*ST(退市预警)视为公司陷入财务危机的标志。选取Normal(财务正常)、ST以及*ST作为目标变量。
基于对样本个体差异的考虑,一般认为金融行业的财务指标和非金融行业的财务指标有明显的差异,因此,本文仅针对非金融上市公司进行研究。并根据中国上海证券交易所和深圳证券交易所所有非金融行业A股的年度报告中的财务数据,同时删除不属于Normal,ST以及*ST的数据后分别得到二组测试数据,第一组将2000~2005年5183条正常公司数据和521条非正常公司数据(ST为449条,*ST为72条)作为训练集,对应2006年1253条正常公司数据和55条非正常公司数据(ST为26条,*ST为29条)以及2007年1347条正常公司数据和116条非正常公司数据 (ST为57条,*ST为59条)作为测试集;第二组将2000~2006年6436条正常公司数据和576条非正常公司数据(ST为475条,*ST为101条)作为训练集,对应2007年1347条正常公司数据和116条非正常公司数据(ST为57条,*ST为59条)作为测试集。在训练集上建立预测模型,在测试集上检验模型的有效性。
2 财务指标选取
企业陷入财务困境是一个渐进的过程,其生产经营状况逐步恶化通常会快速地反应在企业的财务报表上,表现出一些财务指标数据异常。影响企业财务状况的因素很多,但有些指标的数据很难取得,需要耗费大量的人力和物力,因此那些取得成本很高的财务比率不予考虑。根据可操作性原则,结合财务报告中所提供的指标,本文选取综合反映盈利能力、偿债能力、营运能力和现金流量等方面的29个财务指标用于构建财务预警模型,其中包含了一般论文中没有涉及但我们认为对财务风险预测有较大影响的公司规模和成长能力方面的4个财务指标(log(总资产),log(净资产*股东权益合计),总资产增长率,营业收入增长率)。所选指标具体如表1。
3 预警模型的建立及优化
我们使用数据挖掘软件Weka提供的贝叶斯网络(BayesNet)、决策树(J48)、基于规则的分类(JRip)、最近邻分类(1NN)、 多层感知机 (MultilayerPerceptron)、BP神经网络(RBFNetwork)、逻辑回归(Logistic)等7个分类方法建立各类预警模型并进行分析比较。从两个方面进行了大量的数据分析,首先使用所有财务指标利用7种分类方法进行风险建模分析,然后利用数据挖掘方法进行指标选择,再利用选定的指标进行风险建模分析。
3.1 未经属性(指标)选择的预警模型的建立
这里建模过程基于未经属性选择的原始数据集,针对每种分类算法分别进行两种模型的建立:2000-2005年度数据集和2000-2006年度数据集分别作为训练集;2006年度相关数据和2007年度相关数据分别作为测试集。表2给出了不同分类方法在两组数据上的测试结果。
实验结果表明,最近邻分类、多层感知机、BP神经网络及逻辑回归四类方法的性能基本相当,而贝叶斯网络、决策树、基于规则的分类三类方法的性能差异不大,整体性能明显低于前四类方法,但对于ST的识别精度(60%左右)明显高于前四类方法。

表1 财务危机预警指标列表
从实验结果可以看出,利用2000年到2005年的数据作为训练集进行建模,来预测2006年至2007年的数据,大部分方法的预测准确率低于利用2000年到2006年的数据预测2007年的预测准确率。注意到2006年股市“全面型牛市”以及2007年度 “全民炒股”的真实市场现象,可以理解2006、2007年股市的规律明显不同于2000~2005年,因而,模型的预测精度不够理想。
3.2 属性(指标)选择后的预警模型的建立
对2000~2005年的数据,通过运用weka中的BestFirst,GreedyStepwise,LinearForwardSelection三种属性选择方法进行属性选择,综合得到9项保留属性,即每股收益(摊薄营业利润),债务资产比率,log(总资产),log(净资产 *股东权益合计),总资产增长率,现金负债比率,营业利润,所有者权益合计(包括少数股东权益),净资产等。
对于选定的9个指标,针对每种分类算法分别建立两种模型:2000-2005年度数据集和2000~2006年度数据集作为训练集;2006年度相关数据和2007年度相关数据作为测试集。表3给出了试验结果。
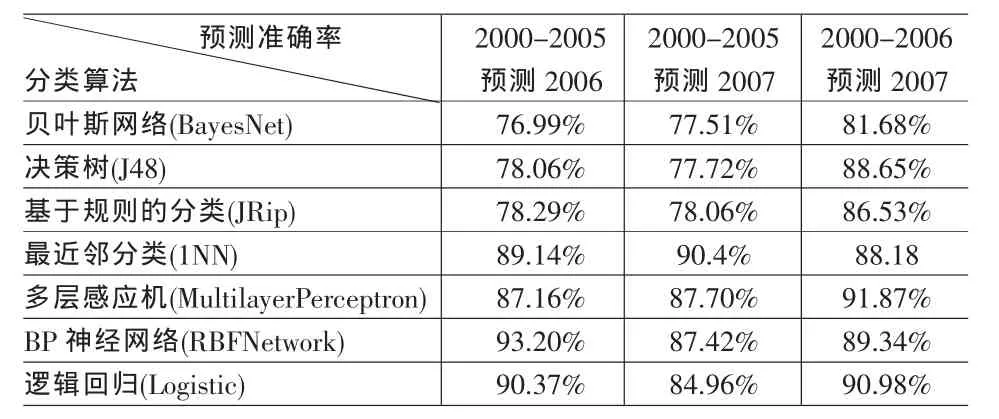
表2 属性选择前各种分类算法对两类不同数据集的预测准确率
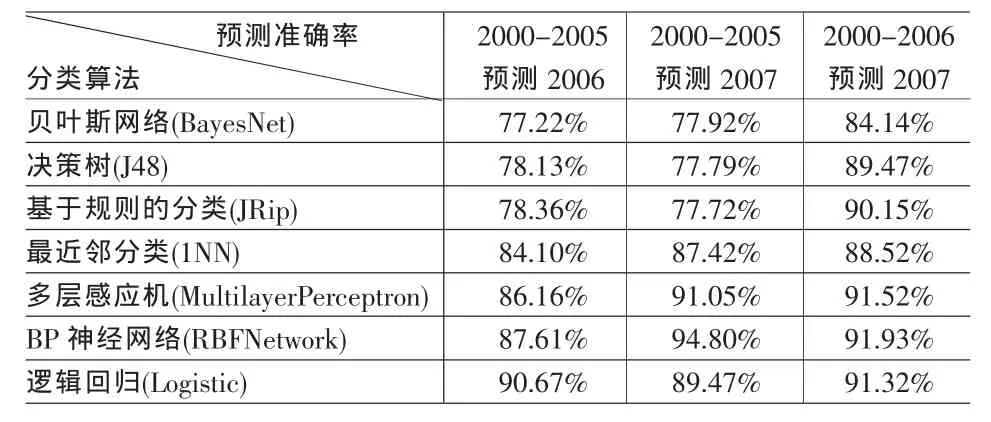
表3 属性选择后各种分类算法对两组不同数据集的预测准确率
从表2、表3可见,通过属性选择后,各种模型的预测准确率变化不大,大部分略有提升,但数据量相对于属性选择前减少近2/3,因此模型的建立时间大大缩短,采用多层感知机算法时,模型的建立时间缩短为属性选择前的16.5%,其它分类方法的建模时间也有不同程度的减少,建模时间缩短为属性选择前的24.74%至57.57%不等。同时,属性选择后模型的表示更为简洁,检测新数据的时间也相应缩短,由此可见属性选择后的模型具备更好的适用性。此外,注意到经过属性选择后,本文所提出的4个创新指标保留了3个(log(总资产),log(净资产 *股东权益合计),总资产增长率),说明本文所加入创新指标的构思是正确的。
4 结论
通过对2000~2007年非金融企业上市公司财务数据的分析,引入了log(总资产)、log(净资产*股东权益合计)、总资产增长率、营业收入增长率等四个新的指标,总计29个指标用于风险分析,并采用7种不同的分类方法来进行财务风险建模,结果表明最近邻分类、多层感知机、BP神经网络及逻辑回归四类方法的性能基本相当,并可以用9个有代表性的指标来建立风险预警模型,可以较好地实现风险预测。
经统计,沪深两市上市公司中被特别处理的上市公司占上市公司总数的12%左右,在我们选取的所有数据中,被特别处理的股票数据占总数的近10%,因此,总体来说我们处理的数据集是不平衡(正常上市公司数据占有绝对比例)的,所采用的经典机器学习方法对不平衡数据中少数类的分类性能不理想。在后续的研究中我们将研究针对不平衡数据集的分类方法并应用到上市公司财务风险建模,在基本保持对正常数据分类精度的前提下,尽量提高对ST、*ST数据的分类精度;同时采用数据融合技术,运用多种分类方法以提高模型预测的准确性;借助数据挖掘与财务知识,进一步分析财务指标之间的关系,选择更有代表性的财务指标用于建模,以尽可能简化模型和提高数据分析的效率。
[1]William H.Beaver.Financial Rations as Predictors of Failure[J].Journal of Accounting Research,1966,4.
[2]Edward I.Altman.Financial Rations Discriminate Analysis and the Prediction of Corporate Bankruptcy[J].The Journal of Finance,1986,23(4).
[3]Deakin,E.B.A Discriminant Analysis of Predictors of Failure.[J]Journal of Accounting Research,Spring,1972,10(1).
[4]K Skogsvik.Current Cost Accounting Ratios as Predictors of Business Failure:The Swedish Case[J].Journal of Business Finance and Accounting,1990,17(1).
[5]陈静.上市公司财务恶化预测的实证分析[J].会计研究.1999,4.
[6]吴世农,卢贤义.我国上市公司财务困境的预测模型研究[J].经济研究,2001,6.
[7]杨保安,季海,徐晶,温金祥.BP神经网络在企业财务危机预警之应用[J].预测.2001,20(2).
猜你喜欢
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
今日农业(2019年12期)2019-08-13
电子制作(2018年17期)2018-09-28
现代营销(创富信息版)(2018年8期)2018-09-08
通信电源技术(2018年5期)2018-08-23
消费导刊(2018年8期)2018-05-25
现代园艺(2017年22期)2018-01-19
中国财政年鉴(2017年0期)2017-07-04
中国财政年鉴(2016年0期)2016-06-05
火控雷达技术(2016年3期)2016-02-06
