
图书馆书目推荐系统的研究与设计
2011-04-02 11:26黄燕
图书馆研究 2011年2期
黄燕
(西南政法大学图书馆,重庆 401120)
高校图书馆是师生读者获取知识的主要场所,一方面大量新书的采购为高校图书馆增加了藏书量,另一方面图书的利用率却不高。造成高校图书馆图书利用率不高的原因是多方面的,但图书馆书目推荐系统的不完善是其中重要的原因之一。本文基于关联规则挖掘,在满足最小支持度和最小置信度的基础上对图书管理系统 (这里指亚德公司的Lib 2.0)的流通日志进行关联规则挖掘,找出读者借阅书目之间的强关联规则,根据这些强关联规则,设计了一种新的书目推荐系统的体系架构,并运用实例分析了该系统的推荐流程。
1 书目推荐系统
推荐系统是一种为了减少使用者在搜寻信息过程中所附加的额外成本而提出的信息过滤机制。Resnick认为一般信息过滤系统也泛称为推荐系统,可以依据使用者的偏好、兴趣、行为或需求,推荐出使用者可能有所需求的潜在信息、服务或产品。书目推荐系统是一种根据读者爱好、兴趣、行为、需求,向读者推荐书目的一种服务系统。
1.1 书目推荐方式分析与设计
目前书目推荐方式主要有以下几种:(1)热门图书推荐。这种方式主要是向读者推荐图书馆里借阅量大的图书,表明很多读者喜欢这些图书。虽然这种推荐方式简单、可信度高,但个性化程度低,仅能满足少数人的要求;(2)新书推荐。此种方式是向读者推荐图书馆刚入藏的新书,与热门图书推荐相似;(3)相似读者推荐。这是一种相互推荐的方式,系统将读者的借阅轨迹记录下来,当另一位读者借阅到轨迹中的某一种文献,系统就会向该读者推荐轨迹中的其他文献,是一种主动性的个性化信息推荐;(4)相似书目推荐。此种方式以某一种文献为基准,当读者借阅了该种文献,系统就能自动地搜索出与该文献题目、内容相似的文献推荐给读者;(5)读者兴趣相关的书籍推荐。此种方法是基于读者兴趣爱好的推荐方法,将适合读者兴趣的书推荐给读者。掌握读者的兴趣是关键,也是决定推荐系统个性化服务的质量。目前,获取读者兴趣的主要方法有:利用聚类算法对读者进行聚类,然后对每一类读者的借阅记录进行分析,得到每一类读者的借阅文献的关联规则,然后有目的地向读者推荐满意的图书。这种推荐是个性化、主动的基于用户兴趣度的推荐,也是本文所提倡的书目推荐方式。
1.2 书目推荐系统现状
清华大学图书馆通过多种途径向读者提供书目推荐服务,如通过编写《图书馆与读者》发布有关推荐书目信息,但并不具有广泛性。虽然OPAC系统提供图书评论功能,允许读者对每本书进行打分,根据读者的评分分5个等级,但尚未就评分结果进行研究分析,也就无法开展更多样的服务。中山大学图书馆的书目推荐系统“我的图书馆”根据读者自己选择的感兴趣的分类,推荐该分类的书目。这种推荐的书目针对性和个性化都不强,对读者利用图书的价值不大,未能很好地根据读者的个体差异推荐。西南政法大学图书馆的“我的书斋”也有推荐功能,但只侧重于新书推荐。目前,国内还没有一所高校图书馆利用关联规则对读者的借阅数据进行分析,对兴趣度相同的读者进行聚类,然后对每一类读者的借阅记录进行关联规则挖掘,并将规则存入规则库,当读者进行借阅时,针对读者兴趣度进行书目推荐。
1.3 书目推荐系统基本架构设计
如图1所示,图书馆书目推荐系统包括三层结构:(1)数据仓库。数据仓库处于书目推荐系统的最底层,我们把流通数据、读者信息、馆藏数据信息等数据从图书集成管理系统中提取出来,去除无关信息,并经过必要的处理存放到数据仓库,形成事物数据库,为以后的数据挖掘做好准备;(2)数据挖掘引擎。数据挖掘引擎是一组程序代码,其主要任务是对数据仓库进行关联规则挖掘,得出读者借阅各类图书的潜在关联规则知识,从而向用户层输出得到的结果,向用户推荐合适的图书。它是整个推荐系统的技术核心;(3)用户层。它是用户和书目推荐系统的用户界面。读者通过它输入相应的信息,如借阅证号、专业、年级,而推荐系统将向读者推荐出相应的图书,推荐出的结果也由用户层来显示。所以,这一层主要是读者提交信息和查看结果的一层。
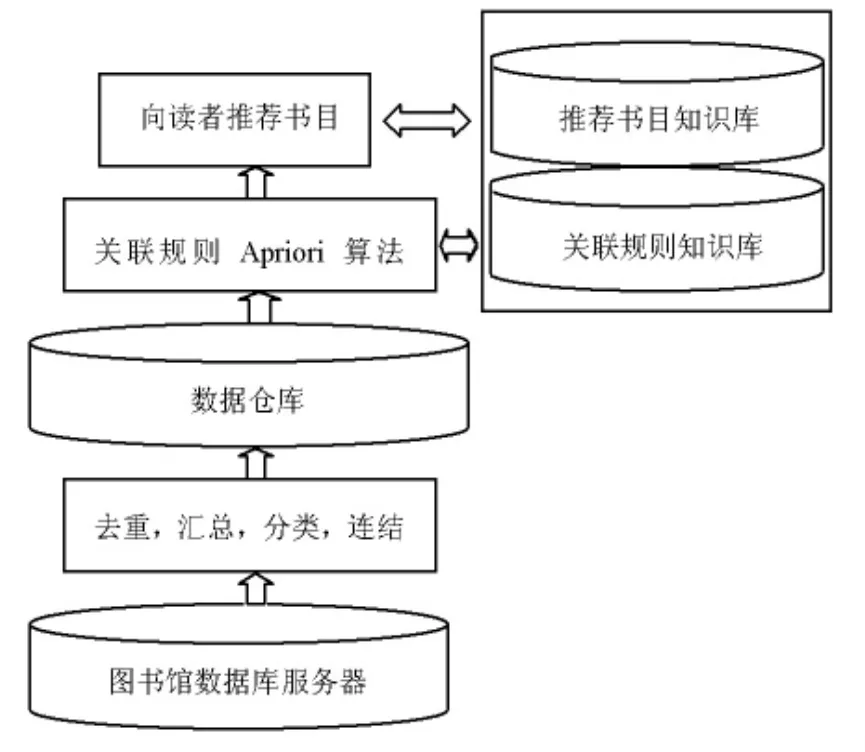
图1 书目推荐系统结构图
2 书目推荐系统工作流程
通过图1,我们大致了解了书目推荐系统的基本架构,下面分析书目推荐系统工作流程。书目推荐系统的工作流程是根据读者要求从数据库中抽取数据源然后进行数据清洗,并进行相应的分类汇总 (这里根据读者的年纪和专业进行汇总),并把处理好的数据存入数据库 (即建立数据仓库),再进行关联规则挖掘并提交结果,最后将结果提交给WEB服务器,显示给用户。工作流程图如图2所示。书目推荐系统主要由三大模块来实现其功能,每一个模块都有自己的功能,其中最主要的是关联规则挖掘这个模块,它是整个书目推荐系统的核心。

图2 书目推荐系统工作流程图
3 书目推荐实例分析
3.1 数据的采集与清洗
读者到图书馆借阅图书,都会在图书馆自动化系统中留下借阅记录,包括读者号、借阅时间、馆藏地、书名等流通日志。本文实验数据均来自西南政法大学图书馆的图书管理系统lib 2.0,从该系统中抽取10名法律硕士2009年9月1日~2010年1月10日的流通日志进行实例分析。通过对流通日志的分析,主要目的是为了了解读者与图书、图书与图书之间的关系。提取出的流通日志中包括8个字段,这里只提取其中两个字段即读者号与索书号。对于索书号只取四位号码,即把索书号前五位相同的数看成一类,同类书目借阅多次,只算作一次。为方便叙述,笔者对数据再作了一定的处理,分别用A、B、C、D、E、F、G 分别表示 D(9)997、D(9)20.5、 D(9)90、D(9)22.281、 D(9)22.29、D(9)22.282、D(9)22.5,从而建立读者借阅信息表,如表1所示:

表1 读者借阅记录
3.2 找出最大频繁项目集
本文运用的是Apriori算法,Apriori算法是由Rakesh Agr,awal和Ramakrishnan Srikant于 1994年提出,其后又扩展到对数值型关联规则及分类关联规则的挖掘。它是最有影响的一种挖掘布尔关联规则频繁项集的算法,其核心原理是非频繁项目集的超集一定是非频繁项目集,频繁项目集的子集一定是频繁项目集。Apriori算法是基于这一原理对候选集进行剪枝的,它是关联规则挖掘的经典算法。首先设定最小支持度为30%,那么最小支持度计数应该为10*30%=3。下面叙述此算法挖掘的实例过程:(1)扫描事物数据库。将支持度计数小于3的1-候选项集剔除,生成1-频繁项集L1,如表2所示;(2)将1-频繁项集两两相连接,生成2-候选项集,并扫描事物数据库,对其进行支持度计数,得到2-候选项集C2,将支持度计数小于3的项集进行剪枝,得到2-频繁项集L2,如表3、表4所示;(3)将2-频繁项集两两相连接,生成3-候选项集,并扫描事物数据库,对其进行支持度计数,得到3-候选项集C3,将支持度计数小于3的项集进行剪枝,得到3-频繁项集L3,如表5、表6所示。
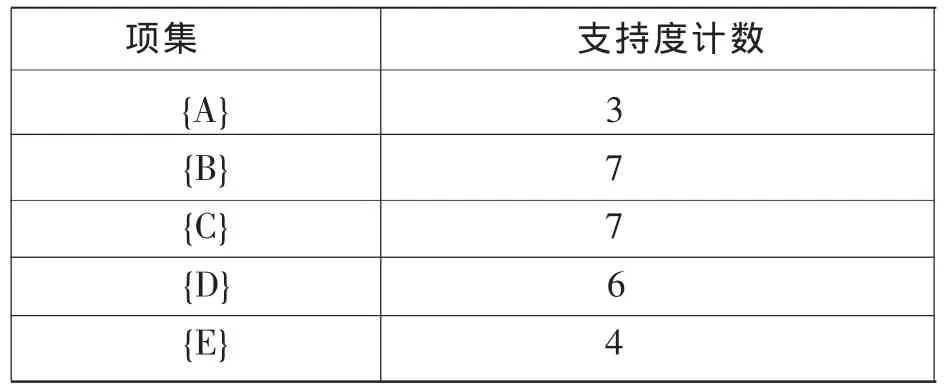
表2 1-频繁项集L1
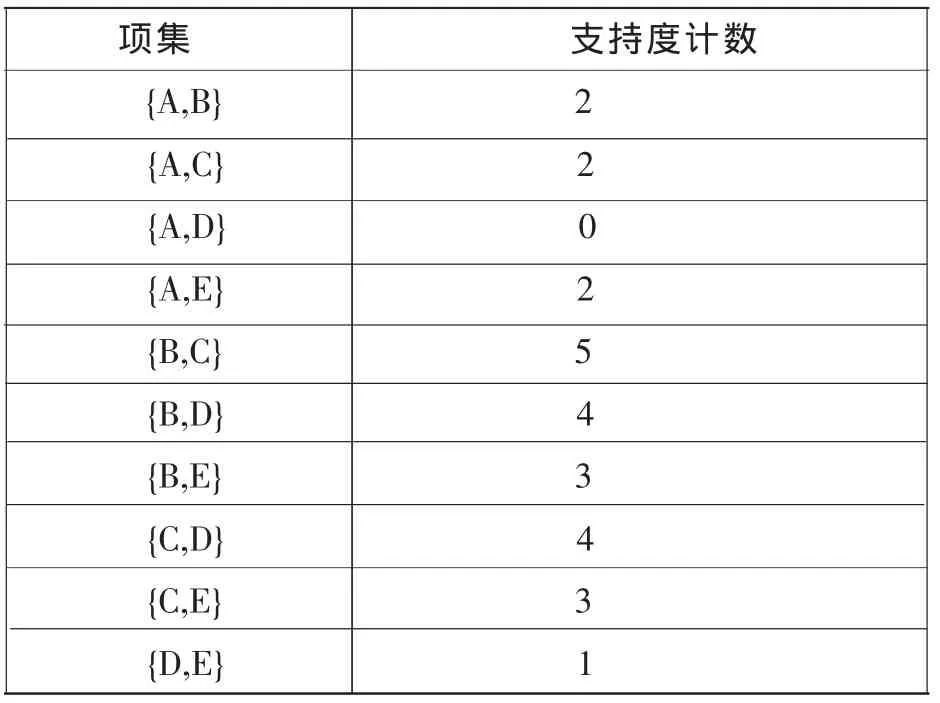
表3 2-候选项集C2

表4 2-频繁项集L2

表5 3-候选项集C3

表6 3-频繁项集L3
3.3 书目关联推荐
利用Apriori算法进行挖掘,得到了两个最大频繁项集,利用置信度对这两个频繁项集所能产生的关联规则进行判定是否是强关联规则,利用提升度判定关联规则是否是正向关联。关于置信度和提升度的定义如下:如果有关联规则如下:,规则中,且。则规则R的置信度(conf)和提升度(lift)可定义为:
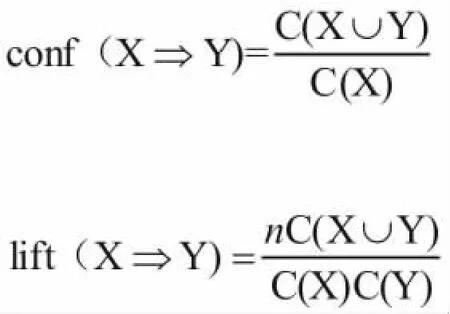
在上面公式中表示在事务数据库中出现X的事物的个数,n为事务数据库中所有事务的个数。由频繁项目集的性质可知道最大频繁项目集已经隐含了所有的频繁项目集,所以可以将发现频繁项目集的问题转化为发现最大频繁项目集的问题。定义:如果频繁项目集L的所有超集都是非频繁项目集,那么称L为最大频繁项目集(或模式),所有L的集合称为最大频繁项目集集合,记为MFS(MaximalFrequent Sets)。经过上面的挖掘产生的最大频繁项集有{B,C,D}和{B,E},{C,E},将这些最大频繁项集生成关联规则,求出置信度和提升度如表7所示。
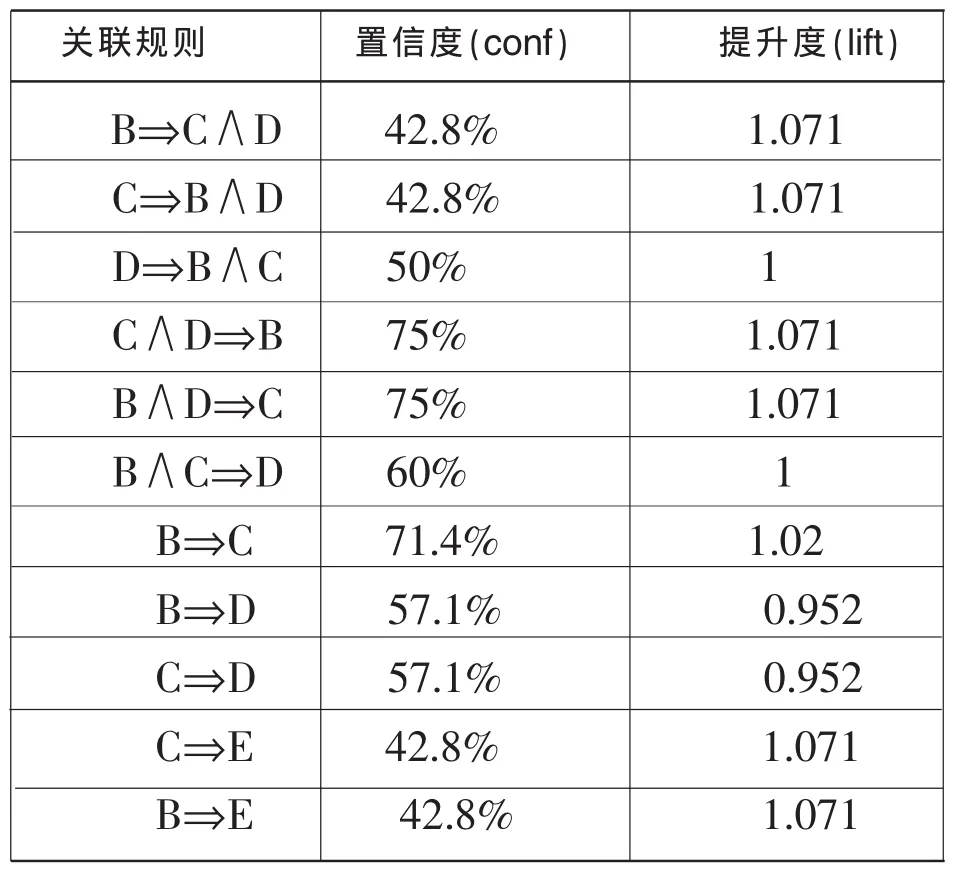
表7 关联规则各项指标
提升度是评判关联规则好坏的一个重要标准,它的取值范围为{0,+∞}。当提升度大于1时,说明得到了正相关规则,也就是说在同一个事务中出现了相集X,那么出现相集Y的可能性就很大,是很好的关联规则;当提升度等于1时,说明相集X与相集Y相对独立,属于同概率事件,关联规则没有什么意义,称为不相关规则。设定最小置信度为50%,符合标准的关联规则有:B⇒C,B∧D⇒C,C∧D⇒B。据此可以做以下结论:如果读者借阅的书目包含了B文献,我们可以向读者推荐书目C;如果读者借阅的书目包含B和D文献,我们可以向读者推荐书目C;如果读者借阅的书目包含了C和D文献,我们可以向读者推荐书目B。
由于B⇒C包含了B∧D⇒C,所以只将B⇒C和C∧D⇒B存入到规则库里面。当读者登录系统借阅文献,就将文献的书目与关联规则进行匹配,进行相应的书目推荐。
4 总结
通过上面的实践,在进行关联规则数据挖掘的过程中,应该注意以下三个问题:(1)首先应该注意必须结合使用三项技术标准 (即支持度 、置信度、提升度),缺少任何一项都有可能造成挖掘出的关联规则错误或者无意义。从上面的实践过程可以看出,虽然B⇒D的支持度和置信度都满足要求,但是它的提升度却不是很理想,说明该班借阅B或者D图书的都不少,但同时借阅了B和D学生太少,所以这样的关联规则不是很理想;(2)关联规则知识具有单向性,它表示的是“某类项目或特征与另一类项目或特征间所存在的单向影响关系”。关联规则知识X⇒Y是强关联规则并不代表Y⇒X也是强关联规则,这种知识具有单向性。如果说某班借阅了D(9)1就有借阅D(9)2的趋势,那并不一定存在借阅D(9)2就借阅了D(9)1的趋势;(3)人的主观原因对关联规则挖掘有较大影响。读者群的选择对于确定挖掘目标具有非常重要意义。选择范围过大的读者群只会使研究者迷失在庞大复杂的数据海洋中,加大研究者发现有用信息的难度。在合理的时间周期提取适当规模的数据,能够保证数据挖掘工作的顺利开展。过大的数据量会明显增加挖掘的复杂度和难度,降低数据挖掘的效率;过小的数据量则难以说明挖掘出来的结果具有普遍实用性,容易使结果产生偏差,给用户带来错误的指导。在实际操作过程中,我们可以根据预定的目标和规则产生的实际数量,来适当地调整最小支持度、最小置信度和提升度标准,这样可以避免过少或过多关联规则的出现。在实际工作中,图书馆主要通过读者访谈、读者问卷调查等方式获取读者对图书的需求。这些方式主要存在两方面的局限:一是人的学识、观察力、认知力和沟通能力等综合素质,导致不同的馆员对读者信息需求的理解停留在不同的广度和深度上;二是这些方式所获取的信息仅仅来源于馆员的感知,没有量化的标准。因此,这些方式欠缺全面性和准确性。流通数据进行关联规则挖掘,不但能够发现庞杂的流通数据中所存在的隐含关联规则,而且也为这种隐含的指示提供了科学的技术手段,从而使图书馆对读者的信息需求分析由定性上升到定量的水平。毫无疑问,这会对图书馆的信息服务工作和决策管理工作起到很好的指导作用。
5 结束语
本文在基于关联规则挖掘的基础上研究设计了书目推荐系统,用实例证明了此系统在图书馆行业有着良好的发展前景。这种推荐系统具有很高的可靠性。
[1] RESNICK P,VARIAN H.R.Recommender Systems[J],Communications of ACM,1997(3):56-58.
[2] INMON W H.数据仓库[M].王志海,林友芳,译.北京:机械工业出版社,2000.
[3] HAN J,KAMBE M.数据挖掘概念与技术[M].范明,孟小峰,译.北京:机械工业出版社,2001.
[4] 毛国君,段立娟,王实,等.数据挖掘原理与算法[M].北京:清华大学出版社,2005:1-21,64-68,72.
[5] 魏育辉,潘洁.图书流通数据的关联挖掘量化分析方法[J].现代情报.2005:11,109-110.
猜你喜欢
小型微型计算机系统(2022年4期)2022-05-09
都市人(2022年3期)2022-04-27
核科学与工程(2021年4期)2022-01-12
机电产品开发与创新(2020年2期)2020-05-07
天津科技大学学报(2018年4期)2018-08-22
计算机应用(2018年5期)2018-07-25
大连理工大学学报(2017年5期)2017-09-20
中国民间疗法(2012年1期)2012-07-27
浙江师范大学学报(自然科学版)(2010年2期)2010-01-11
全国新书目(2009年1期)2009-04-13
