
基于决策树的知识获取方法研究
2011-05-11 04:02张晶
制造业自动化 2011年8期
张 晶
(聊城大学 东昌学院 电子科学系,聊城 252000)
基于决策树的知识获取方法研究
张 晶
(聊城大学 东昌学院 电子科学系,聊城 252000)
1 决策树知识获取方法
知识获取是指从大量数据中去除无用信息、提取有用信息的过程。决策树学习的目的就是从大量实例中归纳出以决策树形式表示的知识,因此决策树的学习过程就是一种知识获取过程。所以可以把决策树的学习与知识获取问题联系起来,从而把知识获取问题转换为决策树的学习问题,从而实现知识的自动获取。
由于决策树知识获取即为决策树学习,而决策树学习的核心就是决策树的学习算法,因此研究决策树的知识获取方法实际上也就是研究决策树的学习算法。所以在此就可以直接利用这一算法生成决策树,以实现通过决策树进行知识的自动获取(即机器学习)。
1.1 生成树的构造算法
决策树构造可以分为两步进行。第一步,决策树的生成:通过训练样本集生成决策树的过程。在一般情况下,训练样本数据集是根据实际需要由历史的、综合性的、用于数据分析处理的数据集。第二步,决策树的剪枝:决策树的剪枝就是对上一阶段生成的决策树进行检验、修正的过程。主要是用新的样本数据集(称为测试数据集)中的数据校验决策树生成过程中产生的初步规则,将那些影响预测准确性的分枝剪除掉。
在决策树生成的过程中,训练样本数据集作为输入的内容,决策树作为最终的输出结果。决策树的每一个决策节点对应着要进行分类的下一个决策属性(测试属性),分支则对应着按该属性进一步划分的取值特征,叶子代表类或者类的分布。首先,根据用户的实际需要选择类别标识属性及其决策树的决策属性集,决策属性集是指在候选属性中选择属性集,然后构造决策树。决策树归纳的基本算法被称为贪心算法,是以自顶向下递归各个击破的方式来构造决策树。
其算法描述如下:
1)树从表示训练样本的单个节点作为起始点。
2)如果样本属于同一类,则该节点将成为叶节点,并用该类做标记。
3)否则,算法将选择最有分类能力的属性作为决策树的当前节点。
4)根据当前决策节点属性取值的不同,将训练样本数据集划分为若干子集。每个取值形成一个分枝。根据上一步得到一个子集,重复进行上面步骤,最后递归形成每个划分样本上的决策树。
5)如果某个属性出现在一个节点上,就不能在该节点的任何后代中考虑它。
递归划分步骤当且仅当下列条件之一成立时结束:
1)给定节点的所有样本属于同一类。
2)剩余的属性可以用来进一步划分样本。在这种情况下,通过多数表决的形式,将给定的节点转换成叶节点,并以样本中元组个数最多的类别作为类别标记; 同时,还可以存放该节点样本的类别分布。
3)如果某一个分枝test_attribut=ai没有样本,则以该样本的多数类来创建一个树叶。
假设用F 代表当前样本集,当前候选属性集用F.attributelist表示,则 C4.5算法C4.5formtree(F,F.attributelist)的伪代码如下:
1)创建根节点M;
2)IF F都属于同一类C,则返回M为叶节点,标记为类C;
3)IF F.attributelist为空 OR F中所剩的样本数少于某给定值则返回M
为叶节点,标记M为F中出现最多的类;
4)FOR EACH F.attributelist中的属性
计算信息增益率information gain ratio;
5)M的测试属性test.attribute = F.attributelist具有最高信息增益率的属性;
6)IF 测试属性为连续型则找到该属性的分割阈值;
7)FOR EACH 由节点M一个新的叶子节点
{IF 该叶子节点对应的样本子集 F 为空
则分裂此叶子节点生成新叶节点,将其标记为 F 中出现最多的类
ELSE
在该叶子节点上执行 C4.5formtree(F,F.attributelist),继续对它分裂;}
决策树是由训练集构造的,所以它能正确处理训练集中的大部分记录。事实说明,这样将会导致决策树非常复杂,使得决策树不平衡,个别分支很长,这就需要对决策树进行剪枝。决策树的剪枝就是指用单个的叶节点来替换整个子树。
1.2 转化规则算法
决策树生成以后,需要从决策树中提取分类规则,一般需要两个步骤,先获得简单规则,然后再精简规则属性。
1)获得简单规则:对于已经生成的决策树,可以非常容易地从中提取分类规则,并以if-then的形式表示。对从根节点到树叶的每条路径创建一个规则,沿着给定路径上的每个属性值对形成规则前件(if部分)的一个合取项,叶节点包含类预测,形成规则后件(then部分)。If-then规则易于理解,特别是当给定的树很大时。
2)精简规则属性:从决策树上直接获得的简单规则,有可能包含了许多无关属性,在不影响规则预测效果的情况下,应该尽量删除那些不必要的条件。
设规则的形式为W
if C then CLASS E
精简之后的规则形式为R-
if C-then CLASS E其中C-是从C中删除条件Q之后的形式。这样,规则W-覆盖的实例可分为以下4个部分:满足条件C,属于类E的;满足条件C,属于其他类的;满足条件C-,但不满足条件Q,属于类E的;满足条件C-,但不满足条件Q,属于其他类的,以上四类实例分别用Y1,F1,Y2,F2来表示。
规则W覆盖了Y1+F1个实例,其中误判实例数目为F1。规则R-覆盖了Y1+F1+Y2+F2。所以规则R的误判概率为UCF(F1,Y1+F1),规则 R-的误判概率为 UCF(F1+ F2,Y1+ F1+ Y2+ F2) 。如果 UCF(F1,Y1+ F1)≥ UCF(F1+ F2,Y1+F1+Y2+F2) ,则可以从条件C中删除条件Q。
获得最优规则的前件集是一个重要问题。Quinlan 提出了一种贪婪搜索方法,即每次从条件集合中删除一个对预测效果影响最小的条件,如果删除该条件后,误判概率减少了,则上述过程继续。如果删除后,误判概率增加了,则不能够删除该条件,而整个精简过程也同时结束。
将决策树转化为规则后,因为他们是易于理解的,所以它们可以构成专家系统的基础。对规则的剪枝将比对树的剪枝算法提供更高的准确率,原因是规则的剪枝等价于在树的剪枝中只剪一个叶节点,而这在树的剪枝中是无法做到的。
2 决策树构造应用举例
为了验证构造决策树方法在系统知识获取上的有效性,选取网络设备信息中的7种属性组成故 障 识 别 参 数 集 B。B= {B1,B2,B3,B4,B5,B6,B7},其中B1代表网卡状态、B2代表配置是否正确、B3代表CPU利用率、B4代表DISK利用率、B5代表网卡收包错误率、B6代表是否重启动、B7代表网卡是否捕获到包,共60个样本实例来建立故障决策树,其中选取20个作为测试数据。选取的样本数据如表1所示。

表1 选取的样本数据
产生的故障决策树如图1所示,最终属性“配置是否正确”为决策树的根,将“配置是否正确”的值分为2段,左子树和右子树。而后在2个分枝的基础上以相同的属性选择算法递归构造各自的子节点以及最终的叶节点,这里得到的决策树结构比较简单。当数据样本变得很大,故障类别也很丰富的时候,会形成一个较为复杂的决策树,得出的规则更适合用于故障的识别。
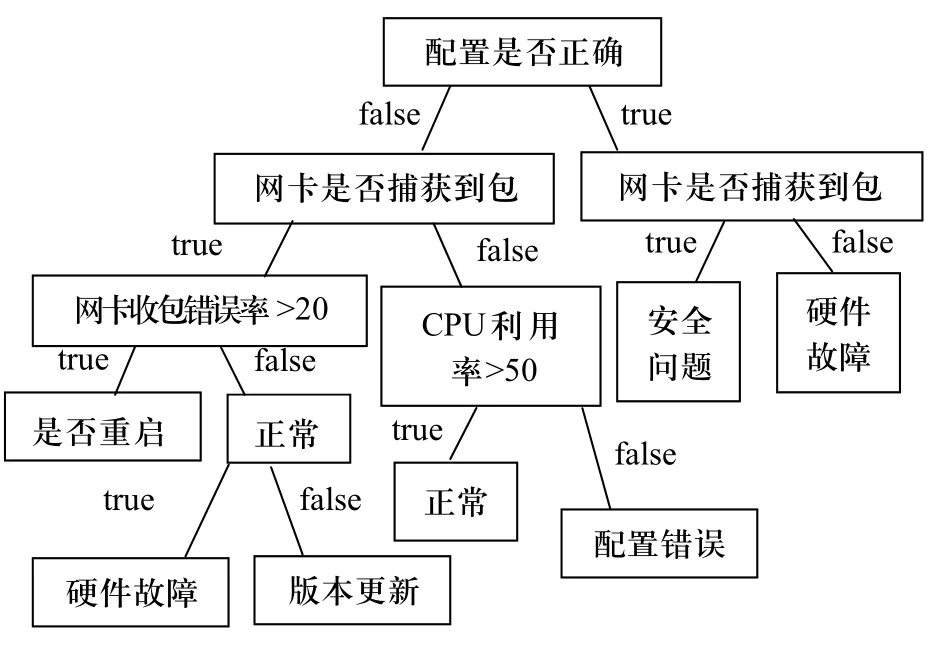
图1 产生的故障决策树
从树根遍历整个决策树,得到的7条分类规则如下所示:
if配置正确,网卡不能捕获到包,then 出现硬件故障;
if配置正确,网卡能够捕获到包,then 出现安全问题;
if配置不正确,网卡不能捕获到包,CPU利用率≤50,then 正常;
if配置不正确,网卡不能捕获到包,CPU利用率>50,没有重启,then 版本更新;
if配置不正确,网卡不能捕获到包,CPU利用率>50,已经重启,then 硬件故障;
if配置不正确,网卡能够捕获到包,网卡收包错误率≤20,then 配置错误;
if配置不正确,网卡能够捕获到包,网卡收包错误率>20,then 正常;
这些规则表现了故障的特征。最后把这些规则存入知识库,利用它对故障分类提供决策依据,并给出故障原因。
3 决策树知识获取性能分析
就目前的知识获取方法而言,主要包括神经网络、遗传算法、Petri网等,它们与决策树比较如下:
1)决策树与Petri网一样,知识获取过程简单、计算复杂度低,但决策树能实现知识的自动获取,而Petri网的构建是由人工完成的。
2)遗传算法虽然也能实现知识的自动获取,但它的计算复杂度远远高于决策树,并且它只是一种知识获取方法,不能实现知识表示,而决策树是把知识的获取与表示融于一身的。
3)神经网络与决策树一样,不仅可以实现知识的自动获取,并且也能实现知识的表示;但与决策树相比较,神经网络学习收敛速度稍慢、网络参数的确定困难,而且它的适应性差,系统的任何变化都需要重新训练。
4 结束语
决策树知识获取方法具有知识获取过程简单、计算复杂度低、适应性强的特点,并且能够实现知识获取与知识表示的融合,是一个性能优良的自动知识获取方法(即机器学习方法)。
[1]朱福喜, 朱三元, 伍春香. 人工智能基础教程[M]. 清华大学出版社, 2006: 78-83.
[2]田盛丰, 等. 人工智能与知识工程[M]. 中国铁道出版社,1999: 121-127.
[3]Shyi-Ming Chen, Jyh-Sheng Ke, Jin-Fu Chang. Knowledge representation using fuzzy Petrinets. Knowledge and Data Engineering IEEE Transactions, 1990, 2: 311-319.
[4]Crosbie, Mark, and Gene Spafford. Applying Genetic Programnning to IntrusionDetection. The AAAI Fall Symposium on Genetic Programming, 2003: 1-8.
Based on the decision tree of knowledge acquisition method
ZHANG Jing
本文以决策树理论为基础,提出了基于决策树知识获取的方法。该方法充分利用决策树把知识表示与获取融于一身的优点,使知识表示与知识获取同时进行,克服了传统人工智能系统中知识表示与知识获取分离的缺点。
决策树;知识获取;贪心算法
张晶(1975-),女,山东聊城人,讲师,硕士,研究方向为计算机软件与理论。
TP391
A
1009-0134(2011)4(下)-0154-03
10.3969/j.issn.1009-0134.2011.4(下).46
2010-12-22
猜你喜欢
保健医苑(2022年5期)2022-06-10
成都信息工程大学学报(2021年6期)2021-02-12
计算机应用(2020年5期)2020-06-07
网络安全和信息化(2020年3期)2020-04-20
网络安全和信息化(2019年1期)2019-02-15
电子制作(2018年16期)2018-09-26
天津诗人(2017年2期)2017-03-16
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
智能系统学报(2015年4期)2015-12-27
电脑爱好者(2015年15期)2015-09-10
