
基于双语约束的蒙古语无监督依存分析
2011-06-28 06:27乌日力嘎斯钦图姜文斌
中文信息学报 2011年4期
刘 凯, 乌日力嘎,斯钦图, 姜文斌, 刘 群
(1. 中国科学院 计算技术研究所,中国科学院 智能信息处理重点实验室,北京 100190;2. 内蒙古大学 蒙古学学院,内蒙古 呼和浩特 010021)
1 引言
由于国家对少数民族语言研究的重视,近年来对少数民族语言及其他次主流语种的研究越来越广泛和深入。这几年来在相应的研究方面取得了不少可喜的成果。但是大多数研究都是基于序列化结构上的许多研究,较为复杂的树结构上许多的研究[1-4]都是偏向理论语言学方面的,直接应用到自然语言处理上还是有比较大的困难的。
目前,主流语言(英语、汉语等)的句法分析的研究已经有了比较系统和成熟的方法:
1) 有监督的句法分析
2) 无监督的句法分析
3) 基于双语映射的句法分析[5]
其中,有监督的句法分析方法需要有一定标准和规模的树库。而以目前少数民族语言的研究现状来看,藏语、蒙语没有较成熟的句法理论研究和标准树库。而维语虽然有较成熟的句法理论研究,但是并没有一个能够使用的公开的句法树库。并且维语的短语成分树和依存树之间的相互转换的研究也基本处于空白阶段。所以要使用有监督的句法分析方法,对这些少数民族语言进行句法建模和分析是十分困难的。而现有的无监督方法的效果并不理想,对语言的词性标注要求较强,并且在算法上的费效比高,所以并不适合用于实际应用中。基于双语映射的方法,需要双语语料库,双语对齐及一端单语的依存树。此方法的效果介于有监督及无监督方法之间。鉴于我们拥有汉语和各个少数民族互译的平行语料,及较成熟的汉语句法分析方法,利用双语映射方法对少数民族语言进行依存句法分析是较为可取的方法。
我们在本文中提出了一种基于双语约束的无监督依存句法分析方法,并在蒙语上进行了实验、测试,取得了较好的效果。本文将在下一节(第2节)介绍相关背景技术,特别是双语依存相似性(2.2节)及蒙语依存约束假设(2.4.2节);在第3节中详细介绍了训练及进行依存分析的算法;在第4节中我们在蒙语200句人工标注的语料上进行了相关实验,并且取得了73%的正确率;本文的最后对我们的工作做了总结。
2 相关技术简介
2.1 依存句法
依存语法最先由法国语言学家L.Tensniere提出的。尽管在理论语言学中其受重视的程度越来越小,但是由于其在机器翻译、语义消歧、语义角色标注等方面的潜在价值,使得其在自然语言处理的实际应用中扮演着越来越重要的角色。
20世纪70年代,Robinson提出了依存语法中关于依存关系的4条公理:
1) 一个句子只有一个成分是独立的;
2) 其他成分直接依存于某一成分;
3) 任何一个成分都不能依存于两个或以上的成分;
4) 如果A成分直接依存于B,而C成分处于A,B之间,那么C或者直接依存于A,或者直接依存于B,或者直接依存于A和B之间的某一部分。
图1为一英文依存树实例。
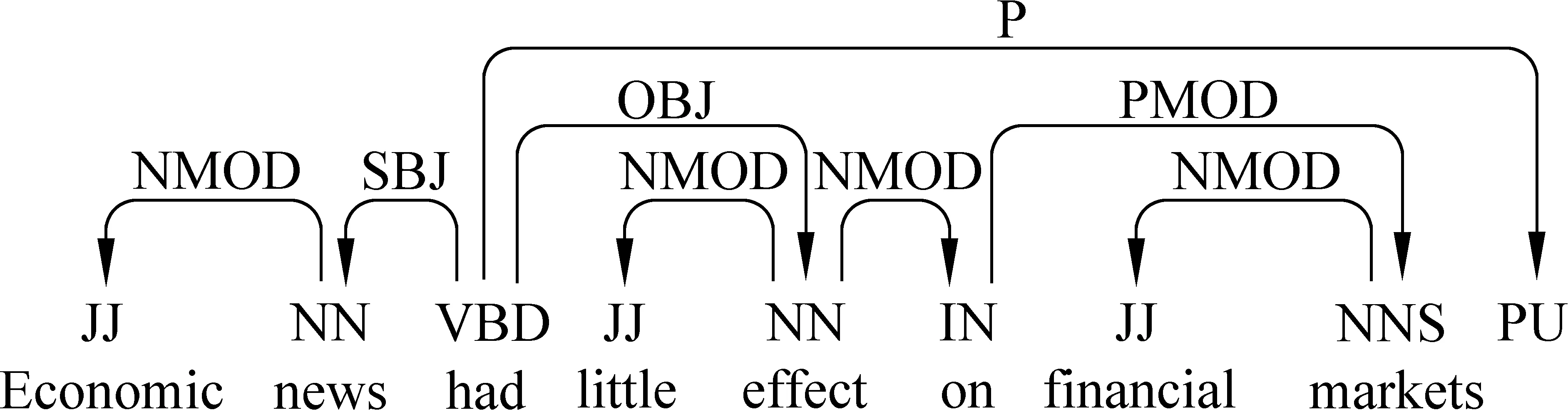
图1 英文依存树实例
2.2 判别式依存句法模型
基于最大生成树的判别式句法分析最早由McDonald提出[6-7]。模型利用了依存边两端的特征信息,进行有监督的判别式训练。利用最大生成树进行依存句法分析。在英语和汉语上取得了很好的效果。其中训练和分析时,所取的特征为依存边两端词的上下文特征。如表1。
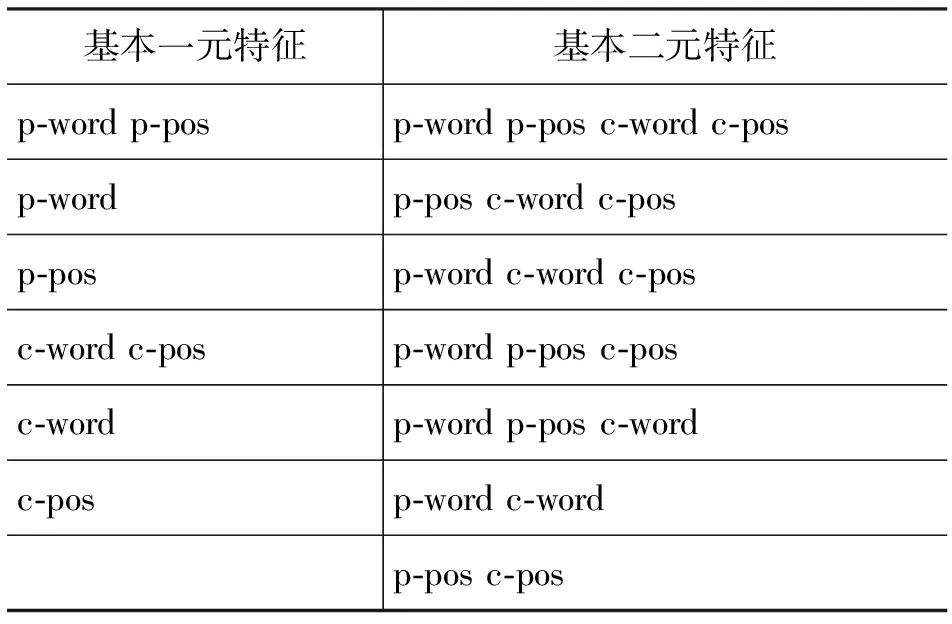
表1 依存分析最大熵特征模板
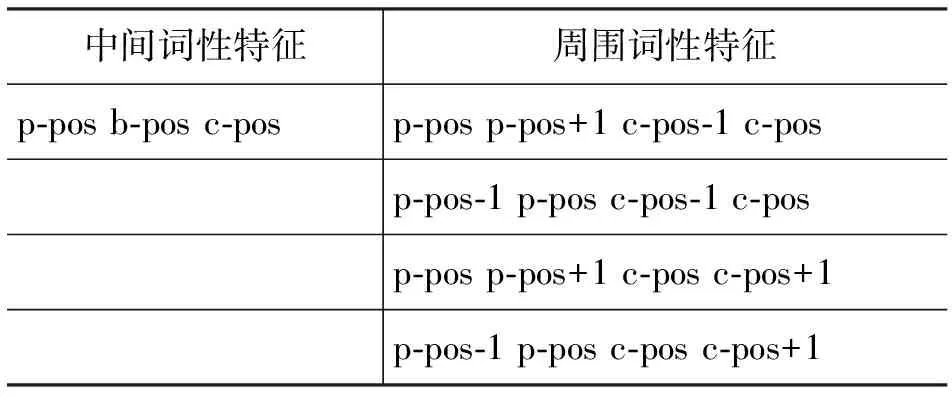
中间词性特征周围词性特征p-pos b-pos c-posp-pos p-pos+1 c-pos-1 c-posp-pos-1 p-pos c-pos-1 c-posp-pos p-pos+1 c-pos c-pos+1p-pos-1 p-pos c-pos c-pos+1
在表1中,p-word:在依存边上父节点上的词。c-word: 在依存边上子节点上的词。p-pos:父节点的词性。c-pos:子节点的词性。p-pos+1:父节点右边词的词性。p-pos-1:父节点左边词的词性。c-pos+1及c-pos-1同理。
由于判别式句法模型利用的是依存边两端的信息,简单直接,易于使用。本文中基于双语约束的方法,就是将源端依存约束信息通过判别式依存模型,对目标端进行约束的。
2.3 双语依存相似性
2.3.1 双语依存相似度定义
本文中提出了一种基于双语对齐的依存相似度评价方法。由于双语的异构性和对齐的多种情况,需要设计一种相对模糊的相似度评价方法。这里相似度评价的原理是: 考察双语句子对应对齐的词之间,相互的直接或间接的依存一致性。
我们定义源端句子为F,单词为f;目标端句子为E,单词为e;源端依存树为Tf,目标端依存树为Te;双语对齐信息为A;
Count(
=|{∀
(1)
而其相似的映射关系总数为:
并且直接相似的映射关系总数为:
在依存树上依存关系
相似的映射关系总数为:
则源端依存树上依存边
在目标端不存在依存树,只存在目标端句子,源端依存树及双语对齐时,我们定义依存连线值Edge(
根据式(7)定义的依存关系,依存边示例如图2。
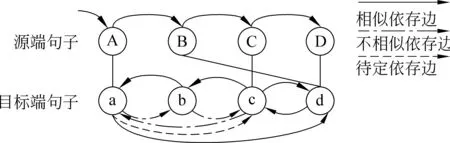
图2 依存边相似性示例图
其中实线为我们认为相似的依存边,点划线为不相似依存边,虚线则为目前无法确定的依存边。
2.3.2 双语依存相似性实验
进行语言间信息映射的前提是语言之间依存的同构性。如果语言间依存同构性假设无法满足的话,双语之间的语言信息映射也就没有了理论基础。
现分别在蒙汉在双语依存句对上依据式(6)计算出的双语依存相似度如图3。
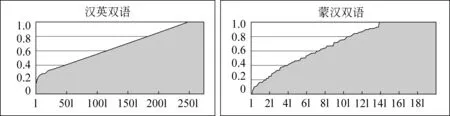
图3 英汉和蒙汉在互译语料上所得的双语相似度面积图
图3中,横坐标为按相似度排好序的句对的编号,纵坐标为相似度评分。左图: 在滨州树库汉英 2 745 互译句对上的相似度结果,其均值为0.66;右图: 在人工标注的蒙汉200句互译语句对上的相似度结果,均值为0.69。
由图3中依存相似度得分的面积图可以看出英汉双语和蒙汉双语之间的依存结构是存在比较强的同构现象的。由于语言的同构性,我们认为汉蒙双语之间也是具有相似性,可以利用双语相似信息进行双语依存映射分析。
2.4 黏着语特点
黏着语是一种通过在词根的前中后粘贴不同的词缀来实现语法功能的语言语法类型。日语、土耳其语是典型的黏着语。语法意义主要由加在词根的词缀来表示的,词缀分为前缀、中缀、后缀,常见的有前缀、后缀。
2.4.1 蒙古语特点
蒙古语同样属于黏着型语言。蒙古语的构词、构形都是通过在词干后面缀接不同的词尾而实现的,并且它们还可以层层缀接。蒙古语的附加成分包括构词附加成分和构形附加成分。构词词缀具有构造新词的功能,构形只表达语法意义。
2.4.2 蒙语端依存约束假设
根据Kemal Oflazer等人长期的对土耳其语等黏着性语言的研究及分析[8]: 一个黏着语的单词中一般有且只能有一个成分能够与外界发生依存关系。也就是说单词之间具有相对的封闭性。在参考文献[8]中,Kemal Oflazer等人就是利用黏着语这个特点进行的土耳其语的依存分析。同样我们也可以对蒙古语进行类似的依存结构假设:
假设1: 所有词只有词干能和词外的依存成分发生依存关系;
假设2: 在假设1的基础上,所有词缀都只能直接依存到词干上。
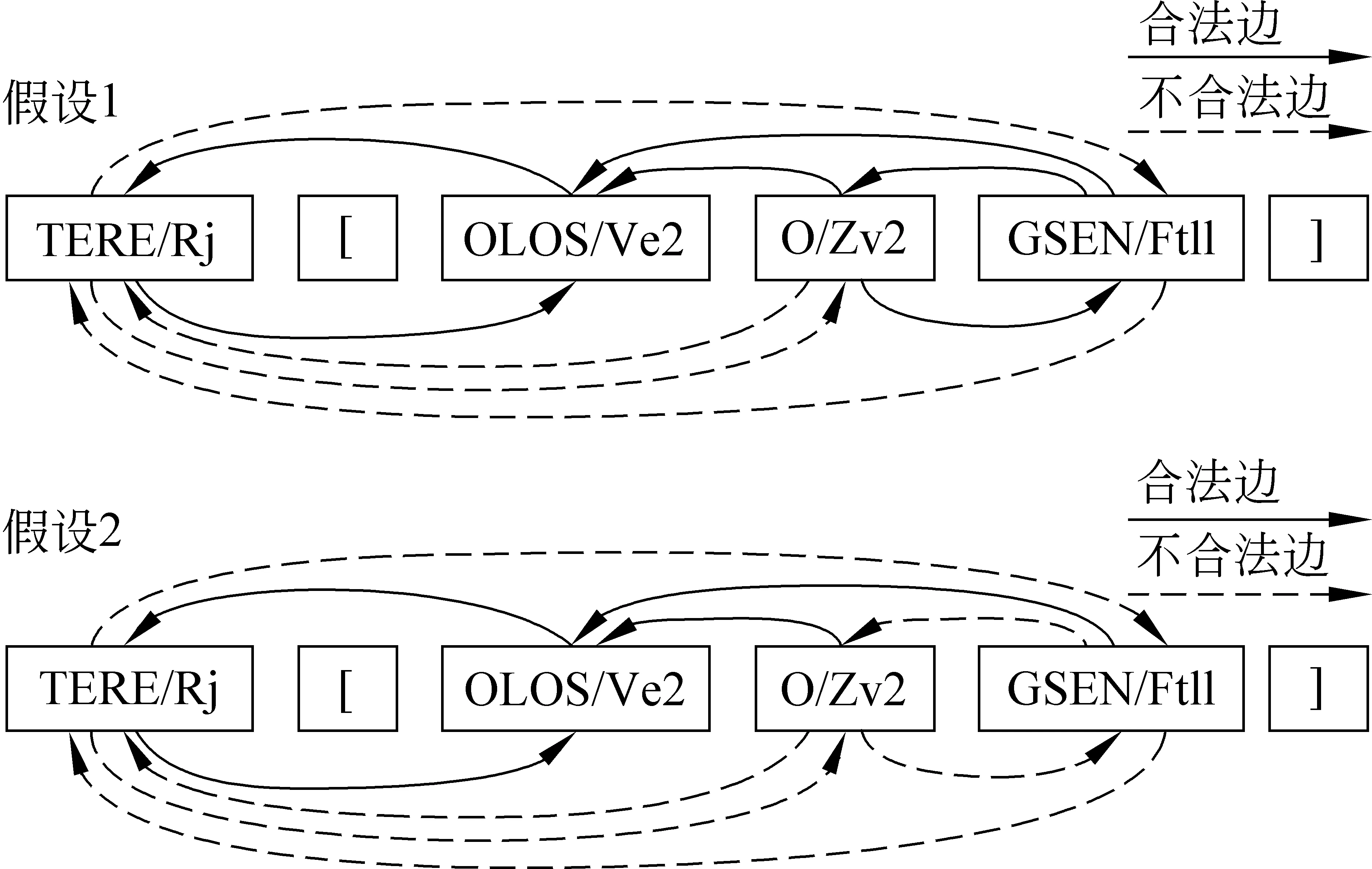
图4 两种假设分别合法和不合法的边的示例图
如图4所示,“THERE/Rj”和“OLOS/Ve2-O/Zv2-GSEN/Ft11”分别为一个词。其中THERE/Rj和OLOS/Ve2分别为两个词的词干。图中,实线为各假设的合法依存边,而虚线则为根据假设不合法的依存边。我们将在后继实验中证明这两种假设的合理性。
3 基于双语映射的无监督依存分析
3.1 最大熵训练
本文中利用成熟的有监督的判别式依存模型,作为双语约束方法的基础模型。运用判别式进行有监督训练时,一般运用在线的训练方法,如MIRA、感知机等。因为有监督分类训练对正、反例的比例有一定要求,使用离线算法无法保证正反例特征的合理性,所以一般效果较差[9-10]。但是,本文中的方法是基于双语约束方法的,本身就无法确保正例和反例特征的正确性。由于最大熵方法训练精度高、速度快,所以本文中采用离线的最大熵训练方法进行模型训练。同时训练所用的抽取特征的模板与2.2节表1中的一样。
3.1.1 语料处理
首先,对蒙汉双语句对中的汉语端,进行依存句法分析,获得所有汉语端的依存树。并对蒙语语料进行词法分析,获得蒙语的词干、词缀及词干、词缀标记信息。再对蒙汉平行语料进行词语对齐,获得蒙汉双语词对齐信息。
3.1.2 分类特征抽取及训练
根据2.3.1节中的定义,在获得的汉语依存树、双语对齐上抽取,从目标端抽取所有的Edge=1的相似依存边(如图2中的实线边),并随机抽取当前句子Edge=1的边的数目两倍的Edge=-1的不相似边(如图2中的点画线边)。使用表1中的特征模板,在已抽取的相似和不相似依存边上,分别抽取目标端蒙语的句子上的正反例特征。
最后利用最大熵训练对抽出的分类特征进行训练,获得一个基于当前汉语依存和对齐约束的蒙语判别式依存模型M。
3.2 依存分析
3.2.1 最大生成树依存分析
进行依存分析时,对等待依存分析的蒙语句子上每一个可能的依存边,计算最大熵的正反例得分。设w(e1,e2|E,y,M,+1)为蒙语句子E上,依存关系边
我们要对当前进行依存分析的句子E进行依存分析,就是要找出句子上模型概率最大的依存树T:
从式(8)可以看出,寻找概率最大的依存树就是最大生成树问题。本文中利用Chu-Liu-Edmonds的最大生成树算法寻找最佳依存树。
最大生成树依存分析算法
1: 输入: 句子E
2: 计算句子E上所有依存关系的模型概率=>buffer //将候选依存边存入buffer
3: buffer=>Chu-Liu-Edmonds最大生成树算法=>TreeMax //将树存入TreeMax
4: 输出: TreeMax
3.2.2 蒙语依存分析
在第2节中,利用上了汉语映射到蒙语的依存结构信息。笔者认为可以在进行依存分析的同时,利用一些蒙语端的依存结构信息,从而进一步提升蒙语依存分析的正确率。
为此我们在2.4.2节中对蒙语依存结构进行了两个适当的假设。并且在进行最大生成树依存分析算法的同时,利用上这些假设。具体做法,就是在上一节中依存分析算法的第2步中,分别将两种不同假设的不合法边删除。利用剩下的合法候选依存边进行最大生成树分析。则最后生成的依存树就分别符合两种假设的约束。
4 实验
我们利用CLDC上公开的蒙汉6万平行句对,作为训练语料。使用ICTCLAS对中文端语料进行分词,在分词结果上使用斯坦福大学的standfordparser,对中文语料进行依存分析。使用中国科学院计算技术研究所研制的蒙语词法分析器,对蒙语语料进行词法分析。使用GIZA++对中文分词结果和蒙语词法分析结果进行双语对齐。
然后在处理好的语料上进行特征抽取和最大熵训练。分别利用假设1和假设2的约束进行依存分析。并在人工标注好依存树的200句长度小于10的蒙语句子的测试集上进行了测试。
图5中使用不同约束信息在200句测试集上所得的依存边正确率。其中双向约束指的是同时使用源端依存约束和目标端依存假设约束,其中约束1和约束2是分别在蒙语假设1和假设2上做出的结果;源端约束结果是直接使用汉语依存的映射约束的结果;目标端约束的结果是直接利用假设2在目标句子上随机生成的依存树(有向的正确率是在计算正确率时考虑依存边的方向,而无向的正确率则不考虑方向)。
由图5的测试结果可以看出,不管是仅用源端约束或目标端约束所得的效果,都远低于两者结合一起使用的效果。可以看出双语两端的信息具有极强的互补性。同样由于目标端约束所起的效果十分明显,可以在本实验中证实,我们基于目标端蒙语依存结构约束的假设是合理的。并且假设2比假设1更为合理一些。其中双语约束2的有向和无向正确率分别达到了67.2%和73.3%。
我们在2.3.1节中定义了映射的相似边、不相似边及待定边。在抽取特征时是否使用待定边,把待定边定义为正例还是反例的多种情况依次进行了实验(均是在双向约束2上进行的实验),如图6所示。
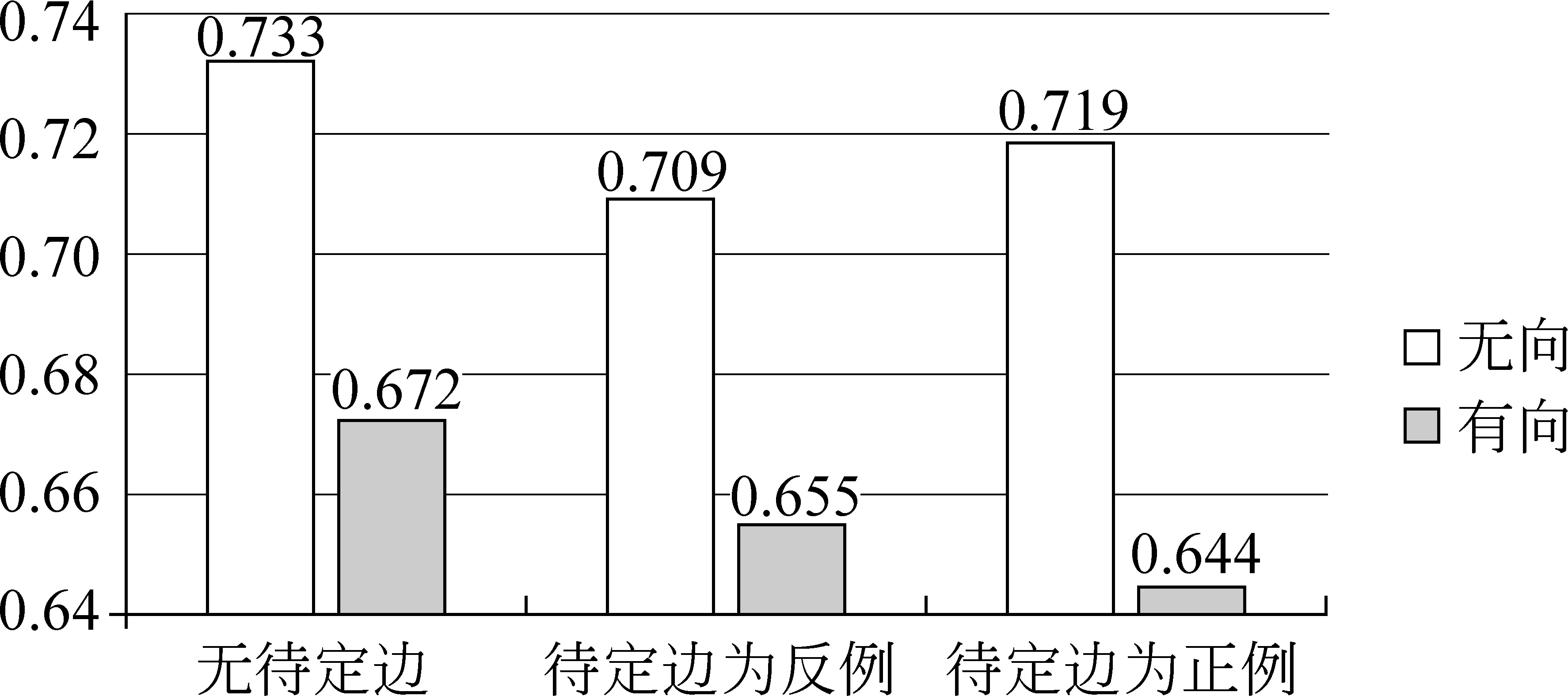
图6 在训练中对待定边赋予不同角色的测试结果
由图6中可以看出,不管是把待定边作为正例还是反例,结果都不如不使用待定边的效果好。所以我们认为在2.3.1节中对待定边角色的定义是合理的。在训练中不使用待定边的特征,去除了一些互相冲突的信息,保留了蒙语端的自身的一些特征,使得源端的映射约束效果更好。
5 结论
本文利用中文端依存信息映射到蒙语端,约束蒙语依存树结构。并且对蒙语的依存结构进行了合理的假设。最终利用双语约束信息对蒙语进行依存分析,最终得到了满意的效果,其中无向正确率为73.3%,有向正确率为67.2%。本文基于双语约束的方法,只需双语平行句对,无需人工标注的词法及句法信息,有很强的自适应性和鲁棒性。可以直接应用到蒙语树库的构建上,应用在蒙语初始树库的构建可以极大的减少人工成本。并且还可以直接应用到其他自然语言处理领域上,同时无需标注好的蒙语依存树库,例如: 在机器翻译、文本摘要、信息过滤、自动问答等领域,有广泛的应用空间。
[1] 力提甫·托乎提.从短语结构到最简方案——阿尔泰语言的句法结构[M].北京: 中央民族大学出版社,2004.
[2] 亚热·艾拜都拉. 维吾尔语句法分析方面存在的一些问题[J]. 新疆大学学报: 哲学社会科学维文版,2010,31(2): 46-53.
[3] 玉素甫·艾白都拉. 维语句法分析器中的词义排岐问题的研究[J]. 计算机应用与软件,2002,19( 4): 59-62.
[4] 阿布都克力木·阿不力孜,哈里旦木·阿布都克里木,吐尔根·依布拉音,等.基于自顶向下算法的维吾尔语句法分析初探[J]. 电脑知识与技术, 2010(2)Z: 1182-1183,1185.
[5] Wenbin Jiang, Qun Liu. Dependency Parsing and Projection Based on Word-Pair Classification[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics (ACL). Uppsala, Sweden 2010: 12-20.
[6] Ryan McDonald, Koby Crammer, Fernando Pereira. Online Large-Margin Training of Dependency Parsers [C]//Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL). University of Michigan, USA, 2005: 91-98.
[7] Klein, D. and Manning, C.D. Corpus-based Induction of Syntactic Structure: Models of Dependency and Constituency[C]//Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics (ACL). Barcelona, Spain, 2004: 478-485.
[8] Gulsen Eryigit, Kemal Oflazer. Statistical Dependency Parsing of Turkish[C]//11th Conference of the European Chapter of the Association for Computational Linguistics(EACL). Trento, Italy, 2006: 89-96.
[9] E. Charniak. A Maximum-entropy-inspired Parser[C]//Proc.NAACL. Seattle, Washington, USA, 2000: 1396-1400.
[10] A. Ratnaparkhi. Learning to Parse Natural Language with Maximum Entropy Models[J]. Machine Learning, 34: 151-175.
猜你喜欢
通信技术(2021年12期)2022-01-25
中华养生保健(2020年7期)2020-11-16
神州·下旬刊(2018年8期)2018-09-03
报刊荟萃(上)(2018年4期)2018-05-09
北方文学·中旬(2017年7期)2017-07-27
科教导刊·电子版(2017年9期)2017-05-17
家教世界·创新阅读(2016年11期)2016-12-27
天津护理(2016年3期)2016-12-01
故事会(2016年15期)2016-08-23
民族古籍研究(2014年0期)2014-10-27
