
最大熵和规则相结合的藏文句子边界识别方法
2011-06-28 06:27才藏太姜文斌吕雅娟
中文信息学报 2011年4期
李 响,才藏太,姜文斌,吕雅娟,刘 群
(1. 中国科学院 计算技术研究所,中国科学院 智能信息处理重点实验室,北京 100190;2. 青海师范大学 计算机学院,青海 西宁 810008)
1 引言
藏语是属于汉藏语系的一种古老语言,在漫长的语言演变过程中,藏语形成了独特的标点符号体系,并仍然在现代藏语文本中得到广泛使用。
藏文标点符号体系仅含有限的标点符号,并且标识句子结束的标点符号存在较多的歧义,功能不确定,严重影响了藏语句子边界的准确识别。作为藏文信息处理的一项基础性工作和藏语自然语言处理的一项关键技术,藏语句子边界识别问题解决的好坏直接影响到词性标注,词语切分、句法分析及机器翻译等其他藏文自然语言处理应用的性能,因此,解决现代藏语句子边界的自动识别问题显得日益重要。
现有的藏语句子边界识别方法主要以采用规则方法为主[1],可以对特定领域的藏文文本实现较好的识别准确率,但是该方法需要制作针对性的规则,人工代价较大,同时领域适应性较差。本文提出了一种最大熵和规则相结合的藏语句子边界识别方法。最大熵模型可以增强对不同领域文本句子边界识别的鲁棒性,但由于最大熵模型会因训练语料稀疏或低劣而产生对句子边界的错误识别,而引入规则方法可以提高最大熵模型的准确率。本文提出的方法首先利用人工总结和分析藏语语料得到的藏语句子边界词表和非边界词表识别藏语句子边界,对于无法识别的藏语句子边界,最后利用最大熵模型进行识别。实验表明,本文提出的方法可以对现代书面藏语文本的句子边界进行较好的识别。
本文包括如下部分: 第2节首先介绍藏语标点符号体系和对藏语句尾的分析,提出基于规则方法的藏语句子边界识别方案;第3节主要说明最大熵模型的原理,提出基于最大熵方法的藏语句子边界识别方案;第4节为实验结果;第5节为总结和展望。
2 规则方法
2.1 藏语标点符号体系
藏语独特的标点符号系统中涉及标识句子结束的标点符号主要有[2]:
在这些标点符号中,楔形符在藏文句子中主要用于句末,也可用于词或者短语之后,在功能上相当于汉语标点符号的顿号、逗号、句号、问号及叹号。例如:

第二条 活佛转世应当遵循维护国家统一、维护民族团结、维护宗教和睦与社会和谐、维护藏传佛教正常秩序的原则。活佛转世尊重藏传佛教宗教仪轨和历史定制,但不得恢复已被废除的封建特权。
从上面的例句中我们可以通过逗号、顿号和句号的位置准确识别出汉语句子边界,但是对应的藏语句子共出现了6个楔形符,导致无法准确识别藏语句子边界。
2.2 藏语句尾结构分析
藏语的句子语序结构属于SOV型,即{主语+宾语+谓语}的语序结构。藏语句子的构成是以动词为核心,运用各种关系词将词语联接起来组成句子的过程。动词的句法位置始终位于句子结尾部分,因此藏语句子中谓语部分的末端应当是整个句子的结尾。但是单独分析谓语部分时,其谓语结构又各有不同的特点,构成要素之间相互影响。一般在藏语句子的谓语部分中核心动词后总是附加包含有一些其他成分,例如辅助动词等,其谓语的语序格式为: { (谓语动词 (+状语补语) (+助动词[情态和趋向]) (+体貌-示证标记) (语气词)}[3]。
另外,藏语句子的主要成分一般都要与格助词相关联。格关系是动词和其周围对象发生事件的约束关系,只有这样才能把句子各成分之间的语义关系表达清楚[4]。通过对48 000句藏文语料中歧义句子边界左侧的格助词等词的分析和统计,我们从中总结出406个非边界词和166个边界词,这些词可以确定性地表示藏语句子边界的功能,如表1和表2所示。

表1 非边界词表(部分)
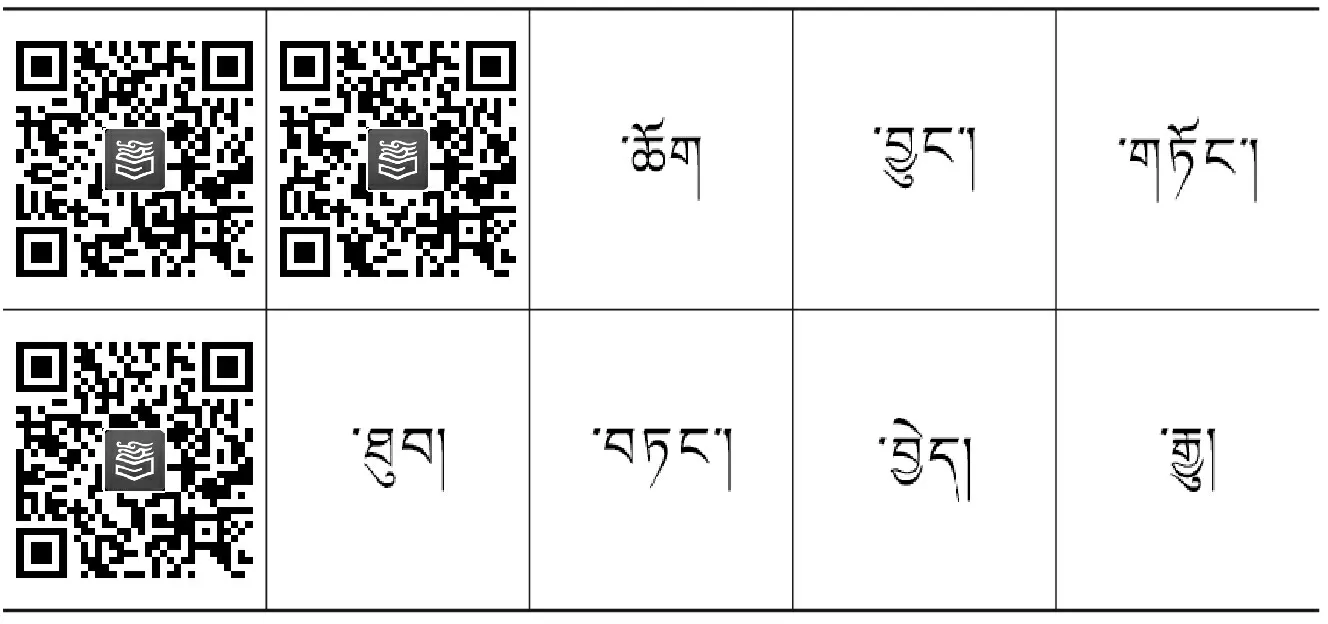
表2 边界词表(部分)
基于规则的方法利用表1和表2的词表识别歧义的藏语句子边界,对于每一次的识别结果,标记该句子边界的确定功能,从而根据该标记决定最大熵模型需要识别的未确定的句子边界。
3 最大熵方法
现有许多机器学习方法可以应用于句子边界识别问题,例如,决策树[5]、神经网络[6]和条件随机场[7]等。由于最大熵模型已经非常成熟,可以采用那些可以开源的最大熵训练工具包来进行训练,因此本文选择最大熵模型来解决藏语句子边界识别问题。
3.1 最大熵原理
如果将一段文本看作一个词序列,则可将句子边界识别问题视为一个将文本划分为句子的随机过程,建立随机过程的联合概率分布模型p,p∈P,输出值集合Y={sb,nsb},y∈Y,其中y是歧义句子边界是否为有效边界的结果,在这个随机过程中,Y受到上下文信息x的影响,上下文集合X,x∈X,其中x表示此序列中所有可能的上下文特征组合,同时,从训练数据中获得N个样本的集合S={(x1,y1),(x2,y2),…,(xn,yn)},其中(x1,y1)是观察到的一个事件,我们可以根据这些样本定义一个事件空间X×Y,而对于句子边界识别问题,特征是一个二值函数f:X×Y→{0,1}。
对于一个特征(x0,y0),定义特征函数如下:
(1)
对于一个特征(x0,y0),在样本中的期望值如下:
(2)

对于一个特征(x0,y0),在模型中的期望值如下:
(3)
最大熵模型的约束条件为对每一个特征(x,y),模型所建立的条件概率分布的特征期望值应与从训练样本中得到特征的样本期望值一致,如公式:
(4)
联合概率分布模型p的熵函数如公式:
H(p)=-∑p(x,y)logp(x,y)
(5)
最大熵模型如公式:

(6)
其中,C是满足条件约束的模型集合,下面需要寻找p*,p*具有如下的形式:
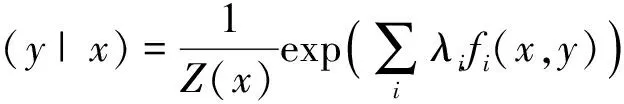
(7)
其中,Z(x)是归一化常数,表示形式如下:
(8)
λi是模型参数,每一个特征fi对应一个λi,λi决定了每个特征fi对概率分布的贡献程度,同时,可以采用GIS算法[8]对这些模型参数进行参数估计。
3.2 特征选择
针对藏语句子边界识别问题,选择有效的句子边界特征是使用最大熵模型需要解决的一个关键问题。根据藏语句子边界上下文的特点确定模型的上下文激发环境,从而选择所需特征。本文考察了影响藏语句子边界识别的多种因素,定义了藏语句子边界识别的特征模板,具体的特征模板如表3所示,其中单词表示藏语中两个音节点之间的字串。

表3 藏语句子边界识别的特征模板
同时,由于训练语料存在较多的数字、标点和英文等非藏文字符,为了避免数据稀疏对藏语句子边界识别效果的影响,我们采用泛化的方法,对这些字符进行分类处理,形成了如表4所示的单词类型表。

表4 单词类型表
下面通过图1来简要说明对2.1节中例句边界特征模板的抽取,其中采用简单的特征集合{L2, L1, L1Len, R1}。如图1所示,将每一个句子边界的功能标记为断句(sb)或不断句(nsb),用左斜线划分藏语单词,空格表示非有效句子边界,@符号表示有效句子边界,共抽取了5个边界特征。


4 实验
实验采用的藏语训练语料规模为48 000句,测试语料规模为140句,对应的参考语料规模为560句,测试语料和参考语料的句数比为1∶4,从而可以较客观地测试句子边界识别性能。
本文采用了张乐开发的最大熵模型训练工具包*网址: http://homepages.inf.ed.ac.uk/lzhang10/maxent_toolkit.html.,在训练过程中,迭代次数设为100次,为了避免过训练,高斯先验设为1.0,其他的参数都为缺省设置。
4.1 评价指标
为了客观评价本文提出的藏语句子边界识别方法的性能,依据本文提出的方法,我们实现了一个藏语句子边界自动识别系统,以准确率、召回率和F1值为指标对系统的藏语句子边界识别结果进行评价,相关计算公式如下所示。
对于基于最大熵模型解决藏语句子边界识别问题,当需要对藏文文本识别句子边界时,利用公式(7)可以获得句子边界标记的概率,而句子边界识别可以看作两类情况的分类问题,因此,实验采用p(y=sb|x)≥0.5作为判别句子边界的阈值。
4.2 特征模板的选择
由于特征模板可以形成很多特征集合,但在对藏语句子边界进行充分分析的情况下,没有必要尝试所有的特征集合,根据经验和分析,在表3描述的特征模板的基础上选择特征形成如下6个特征模板集合。
(1) 特征集合A: A={L2L1, L2, L1Syl, L1Len, L1, R1, R1Len, R1Syl, R2, R1R2},包含了表3中的所有特征模板,作为评估其他特征模板的参考。
(2) 特征集合B: B = {L1Len, L1},用于评价句子边界左侧第一个单词及单词长度对句子边界识别的影响。
(3) 特征集合C: C = {L1Syl, L1Len, L1},用于评价句子边界左侧第一个单词的尾部字对句子边界识别的影响。
(4) 特征集合D: D = {L2, L1Syl, L1Len, L1},用于评价句子边界左侧第二个单词对句子边界识别的影响。
(5) 特征集合E: E = {L2L1, L2, L1Syl, L1Len, L1},用于评价句子边界左侧第二个单词和第一个单词共现对句子边界识别的影响及句子边界左侧特征对句子边界识别的贡献。
(6) 特征集合F: F = {L2L1, L2, L1},用于评价候选句子边界左侧第二个单词和第一个单词共现,第二个单词以及第一个单词这种简单特征模板集合对句子边界识别的影响。
为了验证每个特征集合的性能以及选择最有效的特征集合,分别采用以上每个特征集合识别藏语句子边界,实验结果如图2所示。
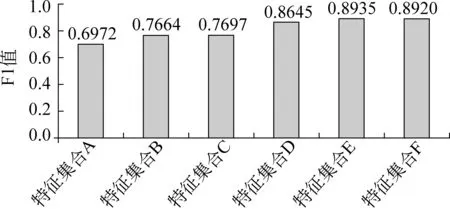
图2 6个特征集合的测试结果
实验结果表明,采用特征集合E的实验结果最好,特征集合A的实验结果最差,因此选择特征集合E作为最有效的特征模板集合。另外,从实验结果比较可见,特征集合A的实验结果最差,说明句子边界右侧特征并不能对实验结果产生较大贡献,所含信息量较少。
4.3 不同识别方法的比较
为了验证不同方法对句子边界识别性能的影响,分别采用基于规则的方法、基于最大熵模型的方法以及最大熵模型和规则相结合的方法,对相同测试语料测试藏语句子边界识别性能,其中特征集合采用4.2节中的特征集合E,实验结果如表5所示。

表5 不同边界识别方法的实验结果
表5表明,虽然最大熵模型方法已经实现了较好的性能,但是小规模训练语料并不能较好地反映藏语复杂的边界特征分布,通过结合藏语句子边界的规则,藏语句子边界识别性能得到大幅提高,减少了最大熵模型对歧义句子边界识别的误判,具有对错误识别较好的约束作用。
5 总结与展望
藏文标点符号的特殊性和复杂性使我们不易准确地识别藏语句子边界,从而影响其他藏文自然语言处理的相关工作。通过对藏文语料以及对藏语句尾结构的分析,结合藏文语法规则,本文总结出大量的边界词及非边界词,可以利用词表在一定程度上确定歧义的藏语句子边界的功能,而对于规则不能识别的藏语句子边界,采用最大熵模型进行边界识别。实验结果表明,本文提出的最大熵与规则相结合的藏语句子边界识别方法能够较好的解决藏语句子边界识别问题。
在此基础上,我们一方面计划扩大训练语料,减少数据稀疏,提高语料质量,从而改善最大熵模型的判别能力,另一方面,将针对识别错误的句子优化边界规则和特征模板选择;其次,尝试解决解决藏语复句以及嵌套语句的边界识别问题;最后,我们希望利用其他机器学习方法尝试解决藏语句子边界识别的问题,从而比较不同方法的优劣。
[1] 赵维纳,刘汇丹,于新,等. 基于法律文本的藏语句子边界识别[C]//第五届全国青年计算语言学研讨会论文集,2010: 480-486.
[2] 胡书津.简明藏文文法[M]. 昆明: 云南民族出版社,1988.
[3] 格桑居冕,格桑央京. 实用藏文文法教程[M]. 成都: 四川民族出版社,2004.
[4] 扎西加,顿珠次仁. 自然语言处理用藏语格助词的语法信息研究[J]. 中文信息学报,2010,24(5): 41-45.
[5] Riley, M. D. Some applications of tree-based modeling to speech and language indexing [C]//Proceedings of the DARPA Speech and Natural Language Workshop, 1989: 339-352.
[6] Palmer, D.D., Hearst M.A. Adaptive Multilingual Sentence Boundary Disambiguation [J]. Computational Linguistics, 1997, 23(2): 241-269.
[7] Liu, Y., Stolcke, A., Shriberg, E. and Harper, M. Using Conditional Random Fields for Sentence Boundary Detection in Speech[C]//Proc. ACL, 2005: 451-458.
[8] Darroeh J. N. and D. Ratcliff. Generalized Iterative Scaling for Log-Linear Models [J]. The Annals of Mathematical Statistics, 1972, 43(5): 1470-1480.
[9] 胡书津. 书面藏语常用关联词语用法举要[M]. 昆明: 云南民族出版社,1993.
[10] 格桑居冕. 藏语复句的句式[J]. 中国藏学,1996,(1): 132-141.
[11] 王诗文. 汉、藏语句子结构对比研究[J]. 西南民族大学学报(人文社科版),2007,28(4): 50-55.
[12] 祁坤钰. 信息处理用藏文自动分词研究[J]. 西北民族大学学报(哲学社会科学版),2006,(4): 92-97.
[13] 艾山·吾买尔,吐尔根·依步拉音. 统计与规则相结合的维吾尔语句子边界识别[J].计算机工程与应用,2010,46(14): 162-165.
[14] Berger A. L., Della Pietra, S. A. and Della Pietra V. J. A Maximum Entropy Approach to Natural language Processing [J]. Computational Linguistics, 1996, 22(1): 39-71.
[15] Ratnaparkhi, Adwait. A Maximum Entropy Model for Part-of-speech Tagging [C]//Proceedings of EMNPL, 1996: 133-142.
[16] Mikheev, A. Tagging Sentence Boundaries [C]//Proceedings of ANLP-NAACL 2000: 264-271.
[17] Reynar, J. C. and Ratnaparkhi, A. A Maximum Entropy Approach to Identifying Sentence Boundaries[C]//Proceedings of the Firth Conference on ANLP, 1997: 803-806.
[18] Glenn Slayden, Mei-Yuh Hwang, and Lee Schwartz. 2010. Thai Sentence-Breaking for Large-Scale SMT [C]//Proceedings of the 1st Workshop on South and Southeast Asian Natural Language Processing at COLING 2010: 8-16.
[19] Jiang Di. Identification of Boundaries of Object Clauses in Causative Verb Sentences in Modern Tibetan [J]. Journal of Chinese Language and Computing, 2006, 15(4): 185-192.
猜你喜欢
客联(2022年2期)2022-04-29
西藏研究(2021年1期)2021-06-09
小天使·一年级语数英综合(2020年11期)2020-12-16
小读者(2020年4期)2020-06-16
布达拉(2020年3期)2020-04-13
西藏研究(2017年3期)2017-09-05
快乐语文(2017年12期)2017-05-09
西藏大学学报(自然科学版)(2016年1期)2016-11-15
西藏大学学报(自然科学版)(2016年1期)2016-11-15
西藏研究(2016年5期)2016-06-15
