
基于LCS的特征树最大相似性匹配网页去噪算法
2011-08-09 05:04罗传飞
电视技术 2011年13期
宋 鳌,支 琤 ,周 军,罗传飞 ,安 然
(1.上海交通大学 电子工程系图像通信与信息处理研究所,上海 200240;2.上海交通大学 上海市数字媒体处理与传输重点实验室,上海 200240;3.上海文广互动电视有限公司,上海 200072)
责任编辑:史丽丽
0 引言
一个网页一般包含一些内容块,但除了这些内容块,文献[1]中往往包含导航栏、版权信息、公告消息以及各种各样形式的广告,它们的存在是为了商业目的或者便于用户使用,这些与主题无关的信息称之为网页噪声块。如何降低网页中的噪声,对于网页分类、特征提取、内容聚合具有重要意义,已成为在三网融合的大背景中,基于多媒体内容融合[2]的研究热点。笔者提出了一种基于LCS的特征树结构最大相似性匹配算法,对目标网页及其相似网页生成的特征树进行相似性匹配,然后根据匹配结果的不同之处生成内容块候选集,并对候选集根据内容块的相似程度和树结构进行聚集,对聚集结果的特征进行分析评分得到最后的内容块,达到网页去噪的目的。
1 相关研究
目前已有很多种网页去噪算法,有基于网页视觉特性的,利用一个网页布局来建立视觉结构,同时利用这个视觉结构将网页分块[3-4];在对网页分块之后,利用人工标注并通过神经网络和支持向量机来对网页块特性到块重要性的映射函数进行学习,最后得到通用的映射方法[5]。也有基于规则的,通过定义一些映射规则,将网页的一些特征转化为权值,通过权值比较来实现内容块和噪声块的区分[6-9]。其中文献[6]中提出了一种利用文本块大小和位置得到一个阈值,再利用链接数和非链接文字长度的比值来和该阈值进行比较,得出内容块。文献[7]中提出对来自同一个站点的多个网页实现主要内容块的寻找,通过一些块特性,如文本长度、图片数目、链接数目、词汇矩阵、位置等来判断网页块的相似性,在同一网站中获取到的页面中,在多个网页中出现的相似的网页块是非内容块。文献[8]中提出将网页当成内容单元序列,且每个内容单元有其权值的山峰模型,并利用SVM对块特征进行分类找出主要内容块。文献[9]中提出将DOM树的节点分为HTMLItem和Content两种节点,将Content按种类(图片、文字、链接)和数量计算权值,加在其所属HTMLItem节点上作为其重要性的度量,同时HTMLItem自己也有权值,且随着其深度递减。最后按权值的大小去除噪声块。这些方法各有各的特点,但也各有各的局限性,如基于视觉特性的算法,忽略了内容的重要性;机器学习太复杂,效率不高;基于规则的算法只适用于某些类型的网页等。文献[10]中提出一种使用限制从上到下映射的树编辑距离来自动获取网页新闻的算法,他们的算法在对节点比较时只有相同和不相同两种绝对状态,而实际网页节点之间可能有部分特征是相同的。
针对以上方法的不足,本文提出了基于LCS的特征树最大相似性匹配算法,将网页特征树转化为节点序列来实现全局最大匹配,同样也是利用树的相似性匹配来实现网页去噪,不同的是采用了特征树,保留了DOM树中必要的特征属性以及由这些属性转换而来的新特征,另外对节点的匹配采用了相似度的概念,用一个介于0到1之间的数来表征节点之间的相似程度,且对内容节点和结构节点区别对待。
2 网页去噪算法与系统实现
2.1 整体系统概述
本文利用LCS的特征树最大相似性匹配算法来实现网页去噪。分为以下几个步骤:网页修复与初步清理、目标网页的相似网页获取、由网页DOM生成特征树、特征树的LCS最大相似性匹配、网页内容块候选集聚集、寻找最可能的内容块聚集。系统流程图如图1所示。

2.2 网页的预处理
Internet上的网页往往有很多与网页信息无关的标签,同时也有很多不符合W3C标准的错误,这些错误得不到修正会影响接下来的算法分析,有必要在这之前进行一些预处理工作。
去除掉一些与网页内容无关项(如JavaScript脚本、注释等),JavaScript是动态客户端脚本,一般用于网页与用户的互动,与网页内容无关;注释是网页设计者为了方便设计而添加的网页页面不可见的内容,因此也可以直接删除。
同时修正相对路径问题,由于网页是下载到本地后进行处理,处理完后无法放到原网站环境下去显示,因此需要把相对URI地址转化为绝对URI地址,这包括链接、图片、CSS文件、iframe、frame的URI地址。
修正不符合W3C标准的网页错误,这包括标签的错误嵌套,标签不成对出现等。
2.3 特征树与基于LCS的特征树最大相似性匹配算法
算法的核心思想是将树形结构转化为等价的序列结构,并对序列进行最长子序列匹配,找出两个序列不同之处,再映射到树上找出不同的树枝。匹配的序列越长,得出的不同树枝越少,得到的内容块候选集就越少,因此序列的全局最长匹配有利于寻找最重要内容块。下面首先定义特征树,然后简要分析了要将LCS算法应用于树形结构的匹配,其需要修改的地方,最后给出了LCS的特征树最大相似性匹配算法的步骤。
2.3.1 特征树
网页DOM树是一种能充分表示布局和样式的模型,但很难根据它去研究一个HTML所有的样式和内容,而且DOM树的有些属性特征是最原始的没有经过处理的信息,无法用于树的相似性比较。使用DOM树来作为两个网页的相似性最大匹配是不适合的,因此需要构造一个新的树形结构来表示网页,需要既简洁又能充分表示网页信息。笔者引入了特征树(CTree)。
特征树由特征节点(CNode)构成,以网页body节点为根节点。CNode去除了DOM树节点中不利于做相似性匹配的属性,加入了一些由DOM树种的属性进行变换融合的属性,这包括深度、上边距、左边距和文本率,CNode的定义如下:
定义1:CNode,一个特征节点对应网页中的一个标签,它表征了一个标签的内容特征、结构特征和空间特征。内容特征是节点本身的属性,结构特征是该节点与其他节点之间的关系,空间特征是网页布局特征,即网页块的位置、大小等。每个节点包含以下属性:
1)标签名(tagName):如body,div,span等;
2)节点ID(id):唯一表征一个节点的ID,不一定每个标签都有;
3)样式表类名(className):表示该节点所应用的样式表的类;
4)父节点(parentNode):表示该节点的父亲节点;
5)子节点(children):表示该节点所有的子节点;
6)深度(Depth):表示该节点在特征树中的层次深度;
7)宽度(Width):节点所代表的网页块的宽度;
8)高度(Height):节点所代表的网页块的高度;
9)上边距(Top):节点所代表的网页块距页面顶部的距离;
10)左边距(Left):节点所代表的网页块距页面左边的距离;
11)外部HTML(outerHTML):包含该节点的所有网页代码;
12)内部HTML(innerHTML):该节点内部的所有网页代码;
13)内部文本(innerText):该节点内部的所有文本;
14)文本率(textRate):表征该节点文本含量。
其中,1),2),3),11),12),13),14)是内容特征;4),5),6)是结构特征;7),8),9),10)是空间特征。
2.3.2 基于LCS的特征树最大相似性匹配算法
LCS算法[11]常用于比较两段文本的相似性或两个序列的相似性,如在生物上可以比较两个DNA序列的相似性。LCS算法不能直接运用于树,原因有以下3点:
1)LCS算法是针对序列结构的全局最大匹配算法,因此需要将特征树转化为特征节点队列,然后再做匹配。本文中使用的是逐层遍历。
2)与平常文本或DNA匹配不同,树节点之间的比较不能用相等和不相等来描述,例如,图2中特征树CT1的B节点和CT2中B’节点,它们在树的位置上一致,同时假设其id、标签名、位置、大小等特征属性是相同的,显然应该认为它们是相似的,但B节点有三个子节点,而B’只有两个子节点,它们不是完全相同的。所以应该用相似性来描述,通过比较节点的各个特征来得到节点之间的相似度,相似度是一个介于0到1之间的数值,0表示完全不同,1表示完全相同,而在0和1之间则表示有部分相同。

3)在将特征树转化为节点队列时,已经没有了树的结构,这可能出现以下的情况:
特征树CT1转换为序列为ABCDEFG,特征树CT2转换为序列为A’B’C’D’E’F’G’,假设A与A’相似,B与B’相似……,按LCS算法它们是完全相同的,但对树来说,F节点的父节点是B,F’节点是C’,它们属于不同的树枝,显然这两棵树是不同的,在比较两个节点相似性时还需要考虑其父亲节点是否相似。
在介绍基于LCS的特征树最大相似性匹配算法之前,先定义几个算法中用到的概念如下:
定义2:文本率(textRate),是指该节点的文本(不包含子节点的)与该节点内的所有文本(包含子节点的)之间的比值,它表征了该节点在以该节点为根节点的子树中的文本含量。
定义3:内容标签(contentTag),是指网页中常用于显示内容的标签,这包括 P,SPAN,B,STRONG,H1,H2,H3,H4,H5,H6等。
定义4:内容节点(contentNode),如果一个特征节点的标签是内容标签,那么它是内容节点;否则如果它的文本率大于75%,那么也是内容节点。
定义5:结构节点(structureNode),所有特征节点中除了是内容节点以外的那些节点。
定义6:相似度阈值(Ts),是一个介于0到1之间的值,大于该值,认为两个特征节点是相似的,否则是不相似的。
定义7:目标网页内容块候选集,指目标网页特征树不同于相似网页特征树的节点的集合。
下面是基于LCS的特征树最大相似性匹配算法步骤:
假设有两棵特征树CTree1和CTree2,将它们按逐层遍历得到数组序列S1和S2。定义两个二维数组scoreTable和pointerTable,分别保存子问题相似度累和与回溯方向,可以将scoreTable这个二维数组看成一个表格,第一维对应表格的行,第二维对应列。与LCS算法不同,此处表格单元格不再代表最长子序列长度,而是子序列相似度累加的最大值。假设scoreTable行方向的序列是S1,列方向的序列是S2,算法步骤如下:
1)初始化两个二维数组
scoreTable所有单元格赋值为0;pointerTable第一行除第一个单元格外全部记录向左方向,第一列除第一个单元格外全部记录向上方向。
2)循环计算子问题的相似度累和以及回溯方向
从scoreTable第二行第二列开始逐行计算单元格值和pointerTable对应单元格的方向值。


其中,CompareTwoCNode是计算两个特征节点相似性的函数,输入为两个节点,输出是一个介于0~1之间的值,即相似度。CompareTwoCNode的实现方法如下:
(1)如果两个节点标签名不同,返回0。
(2)如果两个节点都是BODY节点,返回1,BODY节点是一个特殊的节点,它是每棵特征树的根节点,对于BODY节点,不管它们是否有特征不相同,都认为它们是相似的,而且相似度为1。
(3)如果一个是BODY节点,一个不是,返回0。
(4)如果两个节点的父节点不相似,返回0。
(5)如果两个节点都是内容节点,则比较它们的in⁃nerHTML,相同返回1,否则返回0,对于内容节点,在比较时要求比较苛刻,除了在特征上要求相似,还要求其在内容上相同。
(6)如果两个节点一个是内容节点,一个是结构节点,返回0。
(7)在上面所有情况都不满足的情况下,计算两个节点各特征相同的数目与特征总数目的比值,返回比值。这里的特征包括ID、样式表类名(className)、节点在特征树中的深度(Depth)、节点代表的网页块的宽度、高度、左边距、上边距等。
算法中用到的getDirection用于计算回溯方向,输入是三个方向上的相似度累和,输出是上、左、左上中的一个方向。其计算方法如下:
(1)在不相同的情况下,选取相似度累和最大的那个方向;
(2)在有两个或三个方向上相似度累和相同的情况下,按优先选取左上,然后是上,最后是左的原则。
3)算法回溯
假设CTree1是目标网页的特征树,CTree2是相似网页的特征树。与LCS算法不同,大家感兴趣的不是两棵树相似之处,而是希望得到CTree1上特有的,而CTree2上没有或不同的树枝或节点。回溯从二维数组对应的表格的右下角开始,pointerTable记录了回溯方向。考虑要将S1变换为S2,对于向上的方向,对S1来说此处发生了添加操作,添加操作意味着该节点是S1没有而S2有的节点,不是S1不同于S2的节点,忽略。对于向左的方向,S1发生了删除操作,意味着S1有而S2没有的节点,将其加入目标网页内容块候选集。对于左上方向,本单元格的值是左上单元格相似度累和与本单元格位置上的S1序列和S2序列的节点之间的相似度之和,因此可以用本单元格值减去左上单元格值得到此处两节点的相似度,与相似度阈值(Ts)进行比较,如果大于阈值,则认为两节点相似,忽略;如果小于阈值,此处发生替换操作,意味着S1有S2也有但不相似的节点,将其加入目标网页内容块候选集。
2.4 目标网页内容块聚集
聚集的目的是消除内容块候选集中的祖先和子孙关系,并将在特征树位置上比较接近的节点汇聚在一个集合里面,有利于将内容块和孤立的噪声块分开,以便进行下一步的评分。在前面算法的处理中基本消除了导航栏、固定位置或固定内容的广告,但一些页面独有的广告或其他噪声块还是混杂在候选集里,但它们在布局上和结构上与内容信息块是孤立的,很容易通过聚集将它们区别开来。在本文实验中首先检查候选集类是否有某个节点的子孙节点,有则将子孙节点从候选集中去除;然后随机选取一个候选集中的节点,在候选集其他节点中寻找与其有相同父亲节点的节点或那些爷爷节点是其父亲节点的节点,将它们置于同一个集合中,继续对剩下的节点做同样的操作,直到候选集中所有节点都处理完毕。最后得到多个集合,被称之为网页内容块聚集簇。
2.5 评分筛选
实验的最终目的是要找出网页中的内容块,对网页内容块聚集簇中的每个集合进行特征分析并评分,找出最重要的内容块。
定义8:主要视觉区域(mainVisualArea),是指网页设计中常将主要内容置于靠中间的区域,这个区域是用户打开网页后目光集中的区域。
特征分析将从以下几个指标入手:文本长度、面积、有效面积、内容标签数目、链接率、文本代码比率。文本长度是一个聚集簇中所有节点的内部文本长度的总和,噪声往往文字较少,因此文本越长其越有可能是内容块。面积是一个聚集簇中所有节点对应的网页块其所占区域面积的总和,占有面积越大越有可能是内容块。有效面积是指一个聚集簇中所有节点对应的网页块与主要视觉区域重合的面积的总和,在网页中的有效面积是区分内容块和噪声块的一个重要指标。内容标签数目是指一个聚集簇中包含定义3中定义的内容标签的个数总和,显然内容标签数目越多,越有可能是内容块。链接率是指一个聚集簇中所有节点中(包括子孙节点中的)链接节点的代码长度总和与所有节点代码长度总和的比值,这是抑制噪声的一个重要指标,噪声往往含有大量链接,通过计算这个比值,很容易区分内容块和噪声块。文本代码比率是表征文本占总HTML代码的百分比,内容块有较大的文本代码比率。
在计算了上述指标之后,接下来对每个聚集簇进行评分,对于有助于寻找内容块的指标(如文本长度),给排名靠前的聚集簇加分,对于有利于寻找噪声块的指标(如链接率),对排名靠前的减分惩罚。对于每个指标对聚集簇按从大到小排序,对前三个进行打分。对于链接率,按-5,-3,-1分值打分;对其他指标按5,3,1分值打分。最后每个聚集簇都有一个评分,对其进行排名,选取靠前的几个分值比较接近的聚集簇作为最后的结果,即目标网页的内容块。
3 实验结果和分析
笔者从几个著名中文门户网站(新浪、腾讯、网易和搜狐)获取共计2458个不同类别的网页地址,作为输入来测试本文提出的网页去噪算法和系统。这些类别包括新闻、体育、娱乐和军事,笔者的算法达到了总的平均95.1%的正确率。选取网页测试集如表1所示。

表1 网页测试集
经过对系统输出的网页内容块与原目标网页进行对比,通过人工判断对每一个网页比较正确性。最后计算网页去噪正确率[9],其计算方法为

测试结果见表2和表3,表2中按每个网站每个类别分别计算,从中可以看出对各类别都有很好的去噪效果,尤其对内容型网页。搜狐军事结果较差的原因是较多页面是flash视频播放页面,包含文字较少,难于找出内容块。表3是对各个网站的综合统计结果,可以看出对不同网站都能有很好的去噪效果。
4 结论与未来展望
本文描述了一种基于LCS的特征树最大相似性匹配的网页去噪算法,同时具有高准确率和高覆盖率的优点,尤其对于内容型网页。通过分析目标网页的链接找到相似网页,再将目标网页和相似网页转化为特征树,并将特征树映射为一个特征节点序列,利用LCS算法能获得最长子序列全局最优解的特点,找出两棵特征树之间的不同节点作为目标网页内容块候选集,并对候选集进行聚集评分找出网页重要内容块。实验表明本文的算法在正确率方面表现得很好。

表2 各网站分类表测试结果
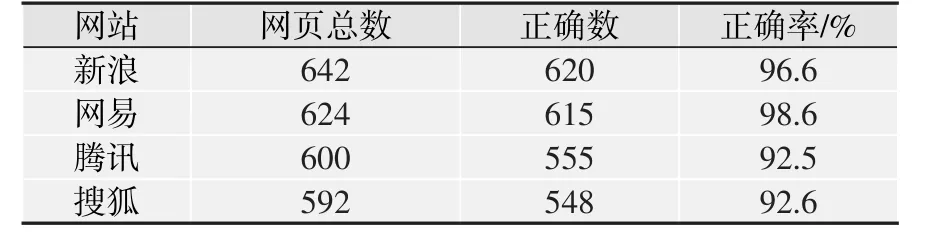
表3 各网站总测试结果
[1]YILan,LIU Bing,LIXiaoli.Eliminating noisy information in web pages for data mining[C]//Proceedings ofthe ninth ACM SIGKDD international conference on knowledge discovery and data mining.Washington,DC:s.n.,2003:296-305.
[2]王厚芹,车士义.推进我国三网融合势在必行[J].电视技术,2010,34(6):109-112.
[3]CAID,YU S,WEN J R,etal.Extracting contentstructure for web pages based on visualrepresentation.Asia Pacific[C]//Proceedings ofthe 5th Asia-Pacific web conference on Web technologies and applications.Xi’an:s.n.,2003:406-417.
[4]CAID,YU S,WEN J R,etal.VIPS:a vision-based page segmentation algorithm[R].MicrosoftTechnicalReport:MSR-TR-2003-79,2003.
[5]SONG Ruihua,LIU Haifeng,WEN JiRong,et al.Learning block importance models for web pages[C]//Proceedings of ACM SIGKDD Explorations Newsletter.New York:[s.n.],2004(6):14-23.
[6]刘晨曦,吴扬扬.一种基于块分析的网页去噪音方法[J].广西师范大学:自然科学版,2007,25(2):149-152.
[7]DEBNATH S,MITRA P,PAL N,etal.Automatic identification of informative sections ofweb pages[J].IEEE Transactions on Knowledge and Data Engineering,2005,17(9):1233-1246.
[8]Lidong Bing,Yexin Wang,Yan Zhang,etal.Primary Content Extraction with Mountain Model[C]//Proceedings of 2008 IEEE 8th International Conference on Computerand Information Technology.[S.l.]:IEEE Press,2008:479-484.
[9]LI Yuancheng,YANG Jie.A novelmethod to extractinformative blocks from web pages[C]//Proceedings of the 2009 International Joint Conference on ArtificialIntelligence.2009:536-539
[10]REIS D C,GOLGHER P B,SILVA A S,et al.Automatic web news extraction using tree editdistance[C]//Proceedings ofthe 13th International Conference on World Wide Web.New York:ACM,2004:502-511.
[11]BERGROTH L,HAKONEN H,RAITA T.A survey oflongestcommon subsequence algorithms[C]//Proceedings of the Seventh International Symposium on String Processing Information Retrieval.Washington,DC:s.n.,2000:39-48.
猜你喜欢
数学物理学报(2022年5期)2022-10-09
河北画报(2020年8期)2020-10-27
车迷(2018年11期)2018-08-30
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
海峡姐妹(2018年3期)2018-05-09
电子制作(2017年2期)2017-05-17
浙江大学学报(工学版)(2016年2期)2016-06-05
公民与法治(2016年10期)2016-05-17
电子测试(2015年18期)2016-01-14
