
基于CEVA平台的WMV视频解码器优化
2011-10-09 09:45赵建仁
电子设计工程 2011年23期
赵建仁,邢 玲,陈 蕾
(西南科技大学 信息工程学院,绵阳 四川 621010)
在当今多媒体技术的不断进步下,手机视频、IP机顶盒、HD-TV(高清电视)、Bluetooth(蓝牙)成为其发展前沿的代表,这就需要低功耗的嵌入式处理器和具备高分辨率的输出设备。为了支持高清视频的实时编解码,必须提供有效的硬件体系结构,因为在视频编解码过程中包含了大量的数据处理,这些数据的处理大部分都是在像素(8 bits)水平进行的,比如说在宏块(16×16)里面的每个像素点上,其处理的方式包含乘法、累加、加法、像素扫描、四舍五入、移位、饱和度计算等。考虑到相同的处理将在宏块内所有的像素点上进行,这里采用并行的处理方式将有效地提高编解码效率,CEVA的VLIW和SIMD技术在这里有突出的作用[1]。
现在许多用于无线和移动多媒体应用的复杂SOC都采用多处理架构来提供最佳性能和所需的丰富功能集,这种多处理器方案通常意味着整个应用的调试会更为复杂,增加了开发成本。CEVA与ARM9的组合简化了调试过程,同时也加强了对嵌入在子系统和软硬件应用解决方案中的全面多处理器的支持[2]。CEVA指令集在视频编解码算法优化上也有着非常好的适用性。
现有许多新的复杂的算法被运用到不同的处理器上[3],但这些算法并不适用于CEVA的SIMD结构。文中通过VLIW实现并行算法的操作,多数据的处理利用SIMD技术通过单指令完成,VLIW允许一个周期同时执行8条单指令,这样不仅仅提高了DSP的处理能力,也降低了能耗。
笔者着重于利用SIMD技术对WMV解码器算法进行优化设计与仿真实现。所描述的VC-1解码器[4]优化方法也同样适合于其它的编解码如MPEG-4、H.264等。
1 CEVA体系结构
文中所采用的是CEVA-X1622型号的DSP芯片[5],它具备的一些主要特性包含:高代码密度,支持16位和32位两种指令长度、9级流水线、16个40位的累加寄存器、16个32位的存储器访问和寻址寄存器、支持多种寻址方式、丰富的指令集功能、对8位和16位的分离操作提供全面支持。
CEVA-X系列是一个基于超长指令字结合单指令多数据处理的DSP芯片,利用这一特点能够更好的实现数据并行处理,提高代码密度,并有效地降低功耗。如图1所示,CEVA-X块图大致分为3个部分:PCU(程序控制单元)、DAAU(数据地址运算单元)、CBU(运算与位操作单元)。PCU分为3个子单元:指令分派器、程序排序器和OCEM(片上仿真模块)。CBU负责所有的DSP计算和移位操作,它包含4个计算子单元(M0、M1、S、L),子单元是相互独立的并且能够进行并行处理,CBU还包含有16个40位寄存器组成的累加寄存器文件(ACF),如图2所示,每一个40位的累加器由2个16位部分和一个8扩展位组成,扩展位主要在计算中起保护作用。DAAU主要用于控制所有的数据存储单元,它有2个相同的加载/存储单元(LS0和 LS1),还包含有 25个 32位的地址寄存器文件。

图1 CEVA-X块图Fig.1 CEVA-X architecture diagram

图2 40位累加寄存器结构图Fig.2 40-bit accumulate register structure
2 VC-1解码器优化设计
VC-1[6]是源于微软公司视频压缩编码技术WMV9,经过美国电影与电视工程协会(SMPTE)审批并命名的。VC-1支持3个类别:简单类主要针对低复杂度的图像压缩应用,主要类是在高码率或高复杂度的视频传输中得到广泛应用,而高级类是在主要类的基础上增加了隔行方式的广播级应用,本文把研究的重点放在了主要类,解码流程如图3所示。
VC-1区别于其它视频编解码标准主要是采用了自适应块变换、16位精度的变换处理、多种方式的运动补偿、环路滤波和重叠平滑化、均匀与非均与量化[7]。通过上述优点,它能够利用较低的计算复杂度实现高清的视频编解码(类似与H.264/AVC)。 VC-1 支持不同尺寸的块变换 (8×8、8×4、4×8、4×4),大尺寸的块变换有利于计算空间域里面的相似点,小尺寸的块变换能够有效地减少边界与块边缘不连续区域的振铃效应,这里所采用的16位定点算术运算将有利于SIMD操作。VC-1运动补偿支持16×16和8×8块大小,运动矢量精度可达到1/4像素,它采用不同的模式来实现运动补偿,主要参数为运动矢量精度、预测块大小和内插滤波器类型,有如下4种组合方式:
1)混合块尺寸(16×16,8×8),1/4 像素精度,四抽头双三次滤波器。
2)16×16块,1/4像素精度,四抽头双三次滤波器。
3)16×16块,1/2像素精度,二抽头双三次滤波器。

图3 VC-1主档次解码流程Fig.3 VC-1 Main profile decoder block-diagram
4)16×16块,1/2像素精度,二抽头双线性滤波器。
这4种模式能够提供足够的灵活性去获得运动补偿的参考块,同时,由于没有提供上述参数的所有组合,降低了算法复杂度。VC-1的去方块滤波不仅仅是一个后处理过程,在编码环中引入能有效的提高图像质量,其环路滤波将减少经过反量化和反变换产生的边缘失真,它是一个高条件度算法,所以在处理器上实现它具有一定的难度,为了降低其复杂度,VC-1每隔4个像素判断一次是否需要滤波。环路滤波不能有效地区分块真实边界和量化导致的伪边界,所以通过重叠平滑化来解决这一问题。重叠平滑将加强边缘的预处理并在后处理过程中进行平滑化,执行它的过程并不需要满足很多条件,因此它能够被用于低复杂度简单类的实现。VC-1同时允许使用死区量化器和常规均匀量化器,在低码率情况下,采用死区量化器,在高码率时,采用均匀量化器。
2.1 运动补偿模块优化
运动补偿通过参考块和运动矢量来生成预测块,如果运动矢量指向了小数部位的像素,那么就需要用像素插值来获得该位置的像素值 (1/2,1/4),VC-1使用 3种滤波器进行运动补偿,一种是1/4像素处的四抽头双三次滤波器,另一种是1/2像素处的二抽头双三次和二抽头双线性滤波器。公式(1)、(2)、(3)是四抽头双三次滤波器在 1/4、1/2、3/4 像素处插值方法[8]。Xnm表示第m行第n列处的像素值。假如需要在一个宏块的垂直1/4像素处进行像素插值,为了能对整个宏块的小数位置进行插值,需要在所有列都运用该滤波器。如果想充分利用SIMD来实现像素插值 (并行处理8个像素),那么如图4所示,在前4行采用四抽头滤波器进行插值操作。这里把一个宏块分为4个8×8子块,对于一个8×8块,把它一行的像素全部放入累加寄存器中,那么一个8×8块需要8个累加寄存器(不考虑扩展位),然后在利用SIMD技术来并行计算8个内插像素值。除法操作通过移位来实现,Ymn表示垂直1/4位置处的像素值,uint8表示8位无符号整型数据。
1/4像素处:

1/2像素处:
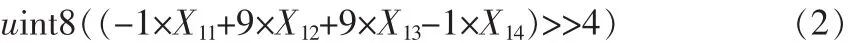
3/4像素处:


图4 像素垂直方向插值Fig.4 Pixel vertical interpolation
为了利用SIMD技术实现水平方向的插值,需要对数据进行一个特殊的排列,如图5所示,给出了采用SIMD技术对第一行8个像素进行滤波的数据排列方式。这里Xnm表示第m行第n列处的像素值,剩下的过程类似于垂直插值。

图5 水平方向像素插值的数据排列方式Fig.5 Data arrangement for horizontal filtering
2.2 去方块滤波模块优化
去方块滤波[9]主要用于消除由反变换、反量化、运动补偿造成的块效应,有利于获得更好的参考图像,进而提高运动估计的精度,但由于它计算量较大,同时也消耗大量解码时间。 去方块滤波的执行区域基于块(8×8、8×4、4×8、4×4)的边缘,对于P和B类的图像来说,块边界能出现在第4、8或12个像素位置处 (行或列),这取决于它们采用何种块变换尺寸。对于I图像而言,块边界只出现在第8、16、24行或列像素处,因为它只采用8×8块变换。
由于CEVA具备足够的寄存器资源,在加上其丰富的SIMD指令集,能够同时对4个4×4块或2个8×4/4×8块进行去方块滤波,这种方法有利于提高缓存效率和减少解码时间。如图6所示为水平方向的去方块滤波,块分割类型为两个4×8块,优化时利用CEVA寄存器装载P0,P1,……,P7像素值,在经过合理的指令操作,计算出P3,P4滤波后的像素值,余下的像素采用相同的处理过程。滤波并不是针对原始图像的真实边界,而是对因为变换、运动补偿所造成的伪边界进行处理。对于P帧图像而言,如果相邻两块具有同样的运动矢量或两块残差为0,则不做任何处理。

图6 水平滤波Fig.6 Horizontal deblocking
2.3 反量化模块优化
反量化恢复出量化系数,它是量化的逆过程。利用CEVA丰富的寄存器资源能对4个4×4块并行处理,反量化能够运用斜向扫描或光栅扫描两种方式,为了更有效利用SIMD指令,可以选择光栅扫描方式,这样能同时装载8个量化系数,并重新调整它们。扫描操作会在所有的系数包括零系数处被执行,因此,有效增益依靠在一个块中的非零系数。由于这些不必要的计算和光栅扫描命令相关,优化时把反量化的计算合并到VLD中。
2.4 反变换模块优化
VC-1 反变换尺寸支持 4 种模式:8×8、8×4、4×8、4×4,能够只通过加法和移位操作实现,而不需要乘法等计算复杂度高的运算,这样大大提高了运算效率,如图7所示为4种变换模式。反变换优化[10]时,同时执行两个8×4或4×8块、4个4×4块的反变换,加法和移位操作利用SIMD指令(add、shift)实现。这里能并行处理8个系数,在对行变换计算以后,利用CEVA指令进行矩阵转置,行变换后的系数能够直接作为列变换的输入,这样能降低内存的实用,减少中间步骤,有效地提高处理效率。

图7 变换模块尺寸Fig.7 Variable block sizes for the transform
3 实验仿真
文中主要针对VC-1主档次解码算法进行了优化处理,采用Apollo-1 pro开发板进行移植和性能测评。这款开发板基于ARM9采用多核多总线结构,通过CEVA-X1622与Apollo-1 pro的结合,实现对解码器的优化和调试。
表1给出了核心模块优化前和优化后占用解码时间比,有如下 3 个参考序列[1]:Foreman(QVGA-384Kbps),Akiyo(Qvga-384Kbps)和 Stefan(QVGA-384Kbps)。 Akiyo 序列的运动量很少并且背景基本没有变,Foreman序列包含中等的运动量和纹理变化,Stefan序列有较高的运动量和幅度较大的纹理变化。我们发现其中Foreman序列的运动补偿优化最为明显,导致它的整体优化效果最好,根据2.1的分析,我们知道整个解码过程中,大部分时间是用来进行运动补偿的,Akiyo序列比不上Foreman和Stefan的优化效果正是因为它包含较少的运动补偿。
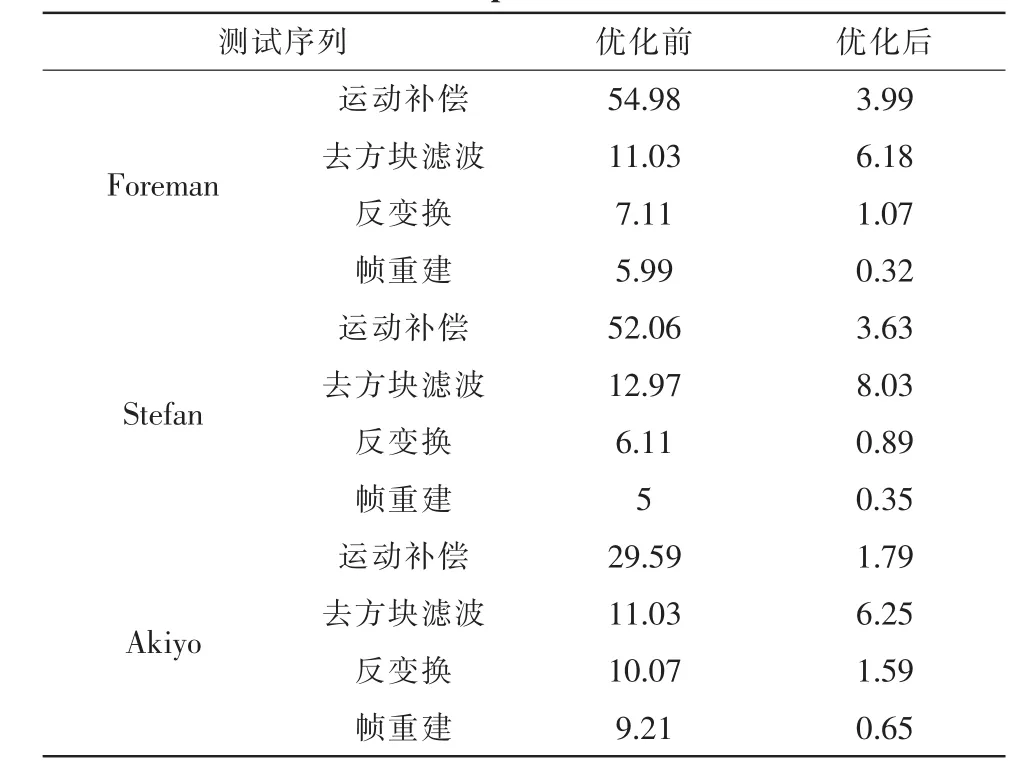
表1 测试序列优化前后不同模块解码时间占有比/%Tab.1 Module decoder time improvement in percentage after optimization
表2给出了经过了优化后,每个序列解码速度的提高值。Foreman相对于其它两个序列优化效果更明显,根本原因归结于对运动补偿模块的优化程度,可见整体优化性能的提升与序列运动补偿多少成正比。实验时同时发现视频参考序列在该平台上解码速度最高可达30 fp/s。

表2 测试序列解码器优化后整体性能比较Tab.2 Overall performance improvement in FPS
4 结束语
文中重点研究了CEVA开发平台下WMV实时解码的算法优化及实现。主要完成了以下几方面工作:针对CEVAX1622的体系结构,对解码器部分核心模块的算法结构做了优化,并且利用SIMD技术进行了DSP实现。结果表明在经过优化处理后,解码算法的各个模块所需的解码时间得到了降低,同时解码器解码速度能够有效支持标清和高清视频的解码需求。
[1]沈钲,孙义和.一种支持同时多线程的VLIW DSP架构[J].电子学报,2010,(2):352-353.
SHEN Zheng,SUN Yi-he.Architecture design of simultaneous multithreading VLIW DSP[J].Acta Electronica Sinica,2010(2):352-353.
[2]CEVA和ARM联手增强CEVA DSP+ARM多处理器SOC的开 发 支 持 [EB/OL].(2008-06-10)http://www.eefocus.com/article/08-06/4322410100603d0oY.html.
[3]Srinivasan S,Regunathan S L.An overview of VC-1[J].Visual Communications and Image processing,Proc.Of SPIE, 2005(5960):720-728.
[4]Srinivasan S,Hsu P,Holcomb T,et al.Windows Media Video 9:overview and applications[C]//Signal Processing:Image Communication,2004(19):851-875.
[5]CEVA-X ARCHITECTURE CEVA-X1620/1622[EB/OL].[2011-09-27]http://www.ceva-dsp.com/products/cores/pdf/cevax1622_datasheet.pdf.
[6]Proposed SMPTE Standard for Television VC-1 Compressed Video Bitstream Format and Decoding Process[C]//SMPTE Technology Committee C24 on Video Compression Technology,2005.
[7]尹明,王宏远.VC-1视频编码技术研究[J].电视技术,2005(11):19-20.
YIN Ming,WANG Hong-yuan.Technical study of VC-1 video encoding[J].Digital TV&Digital Video,2005(11):19-20.
[8]冯丽.VC-1解码算法研究及其DSP移植与优化[D].北京:北京交通大学,2008.
[9]VC-1 Compressed Video Bitstream Format and Decoding Process[S].SMPTE 421M-2006,SMPTE Standard,2006.
[10]聂胜猛,张泽建,欧建平,等.多重频解模糊中降低频道量化误差的新方法[J].现代电子技术,2011(11):179-181,185.
NIE Sheng-meng,ZHANG Ze-jian,OU Jian-ping,et al.A new method to reduce channel quantization error in resolving velocity ambiguity by PRF varied method[J].Modern Electronics Technique,2011(11):179-181,185.
[11]张坤,王莹,高凯.基于TOD信息的长周期跳频序列产生及其性能分析[J].现代电子技术,2010(9):4-6,10.
ZHANG Kun,WANG Ying,GAO Kai.Generation of long period FH sequences vbased on TOD and property analysis[J].Modern Electronics Technique,2010(9):4-6,10.
猜你喜欢
中国石油石化(2022年12期)2022-07-16
有色金属设计(2022年4期)2022-02-04
计算机应用(2020年5期)2020-06-07
中国外汇(2019年19期)2019-11-26
西南石油大学学报(自然科学版)(2019年1期)2019-01-28
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
电测与仪表(2016年10期)2016-04-12
电测与仪表(2016年14期)2016-04-11
电测与仪表(2014年11期)2014-04-04
