
基于语料库的中国大学生汉式写作特点研究
2011-11-02 06:48朱湘华绍兴文理学院浙江绍兴312000
长春理工大学学报(社会科学版) 2011年2期
朱湘华(绍兴文理学院,浙江绍兴,312000)
基于语料库的中国大学生汉式写作特点研究
朱湘华(绍兴文理学院,浙江绍兴,312000)
通过采用差错分析的研究方法,从WECCL语料库中提取部分非英语专业大学生的写作语料,对其中的写作错误进行统计和分类后,发现了语法、词汇、语篇衔接等语言知识运用能力低这一当今大学生普遍存在的写作问题。此外,还运用AntConc和SPSS,以FLOB为参照对所提取的语料进行统计分析,发现与本族语者相比,中国大学生高频写作错误具有汉式特点。
英语写作;错误分析;母语迁移;汉式英语
作为交际能力的重要组成部分,英语写作历来受到教育界的高度重视。众多学者和外语教师经过多方面深入研究,发现写与读、说都有着密不可分的关系。换言之,写可以促进语言技能的全面发展[1,2]。然而,虽然研究者在写作研究领域已取得了丰硕成果,加快了英语写作教学的改革,但学生的写作水平始终难以有所突破亦是不争的事实。有关统计表明,历届CET-4和CET-6的作文平均分一直徘徊于7分左右(15分制),相当于47分(100分制),尚未达到及格水平[3]。因此,英语写作能力的培养已成为中国英语教育者和学习者所面临的最大挑战。
事实上,随着我国对英语综合能力培养的日益重视,大学生英语水平总体在稳步提高,多数学生能够在规定时间内,围绕指定主题完成写作,但往往这些作文的内容组织条理不清,语言错误层出不穷,令人费解的句子时而有之[4,5]。究其原由,除语言基础知识薄弱及缺乏写作技巧训练之外,中国大学生的写作能力很大程度上受汉语思维习惯和表达方式的影响,带有浓厚的“汉式”特点,即“母语的干扰(mother-tongue interference)”。语言学家普遍认为这种“语言之间的干扰”是造成学生第二语言写作犯错的最重要因素,如Corder就认为“转换错误”是造成学生写作错误的首因[6];Selinker也将“转换错误”置于9类错误之首[7];此外,Habbard同样地将“母语干扰”排在第一位[8]。鉴于此,本文基于以往相关研究,利用语料库研究工具,量化统计学生作文中的错误,着重分析大学生写作错误中汉式英语的类型及分布,并运用AntConc和SPSS,以FLOB为参照对所提取的语料进行统计分析,以检验中国大学生写作中的高频错误是否具有汉式特点,并就其成因做出探究,从而提出相应的教学对策来改进英语写作教学,帮助英语学习者突破写作这一重大难关。
一、研究综述
(一)错误分析及母语迁移理论
国外的错误分析(erroranalysis)始于20世纪60年代。当时,Corder发表了The Significance of Learner's Errors(《学习者错误的意义》)一文,开创了错误分析理论的新篇章。Corder认为学习者的错误为研究者提供了三方面信息:学习者已经学习到什么程度,学习者如何学习语言,以及学习者通过犯错误学习语言。根据错误分析理论,分析错误应遵循:选择语言→确认错误→错误分类→解释错误→评估错误5个步骤。
对于语言迁移的研究始于20世纪50年代。Lado在其代表作《跨文化的语言学》中强调母语中的原有习惯有时会促进二语的学习(正迁移),有时会阻碍二语的学习(负迁移)[9]。Lado认为,外语学习中所犯的错误是语言学习者母语负迁移的结果。而语言负迁移主要产生于语言间的差异。母语与目标语相似时将促进目标语的学习,而有差异时则对学习者造成困难。由此不难理解,受汉语思维模式和文化影响的中国大学生,在写作时不可避免地写出大量违背英美文化习俗的汉式句子。
(二)基于学习者中介语料库的差错分析
Ellis曾经指出,必须在科学的语料抽样基础上,对外语学习者的语言差错进行分析,才能清楚地回答学生到底是在什么情况下犯了哪类错误等问题[10]。近年来,随着语料库语言学的兴起和发展,研究者们能够借助计算机和大型语料库,对语言进行系统、全面的对比分析,获得各种客观实用的研究成果。基于学习者中介语料库的差错分析不但可以揭示错误的类型和分布,从错误的频率判断其严重程度,还便于对学生的差错进行共时和历时的研究。目前,对英语学习者中介语的语料库研究正在我国逐步展开,如广东外语外贸大学的杜诗春和上海交通大学的杨惠中教授联合主持建立了中国大、中学生英语作文语料库(CLEC),北京外国语大学的文秋芳等研究者建立了中国学生英语口笔语语料库(SWECCL)以及香港大学创建了香港中学生书面英语语料库(TELECStudent Corpus)等等。基于这些中介语语料库,我们可以从多种语言功能的角度及其表达形式来调查分析学习者对目的语的掌握和使用情况。
二、研究设计
(一)研究问题及语料
此次研究拟在前人研究的基础上回答以下三个方面问题:(1)中国大学生英语写作错误的类型和分布情况如何?(2)与本族语者相比,中国大学生高频写作差错是否具有汉式特点?(3)这些汉式特点形成的原因是什么?
在此使用的学习者中介语料库为文秋芳等建立的中国学生英语口笔语语料库 SWECCL(2005)中的书面作文子库WECCL(Written English CorpusofChinese Learner),约为 100万词。用于参照的语料库为英国本族语者语料库FLOB(Freiburg-LOBCorpus ofBritish English),也为100万词左右。此外,笔者还从WECCL中随机抽取5万词左右的非英语专业书面语料,用于错误标注和统计分析。
(二)研究方法及目的
研究遵循James的错误分类标准,从语言学的角度入手对所收集到的错误进行分类描述,即按照物质、词汇、语法、衔接与连贯这四个语言等级,将错误分为与之相对应的物质错误、词汇错误、语法错误和语篇错误[11]。物质错误在本研究中主要指文章中出现的大小写转换及标点符号错误,因这类错误多数是粗心或笔误所致,受汉语影响较少故不予以统计。本研究调查的重点为后三类错误(详情见表2)。
本研究将定量与定性分析相结合,采取语料库研究方法,运用了绍兴文理学院自行研发的检索软件进行错误标码的统计,文本分析软件AntConc帮助进行语料的处理和分析,并运用了社会科学统计软件SPSS帮助进行数理统计。具体步骤如下:
1.批改作文,并对错误进行系统标码(半机动)。
2.运行自研检索软件,检索错误标码,统计作文错误类型和分布频率。
3.运用AntConc对比检索词频以发现中国学习者的汉式写作特点。
4.分析汉式写作特点的原因及探讨教学对策。
(三)研究结果及分析
1.差错类型和分布频率
本研究从WECCL中随机抽取了5万字左右的非英语专业书面语料,对其进行半自动错误标注及统计分析。以下两表对学生作文中的主要错误进行了归类,并详细统计了各类错误的数量。从表1中可以看出,学生作文中出现的主要错误有2670处(大小写转换及标点符号使用错误未计算在内)。其中,词汇错误高达1280处,占错误总数的50%,位于错误之首;其次为语法错误,错误数为1050,占总数的38%;语篇错误数为340,占错误总数的12%。
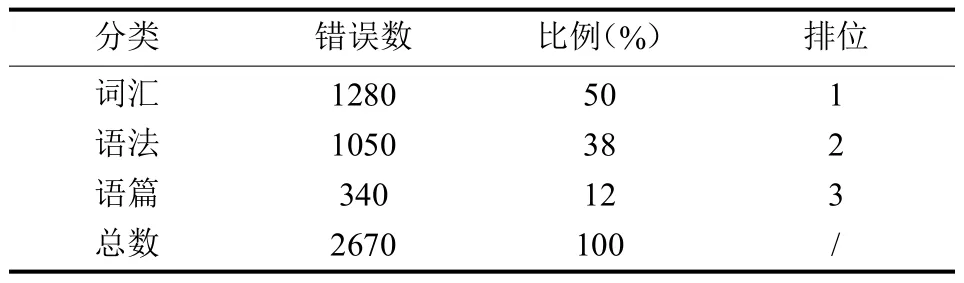
表1 写作错误的总体分布
表2统计了中国大学生写作错误的具体分布:在各子类错误中,语法类的句法错误最为频繁,达到872次,占到错误总数的33%;其次为选词错误,出现频率为538次,所占比例为20%;词汇拼写和搭配中所犯错误分列其后。
调查结果不难发现大学生作文中的语言错误之普遍以及错误之严重,许多简单的、低级的错误层出不穷。理论上,被调查学生,至少都经过七年的英语学习,应该说对语法词汇、文章的组织结构、语篇衔接等语言应用知识有着较好的基础,但统计结果无疑进一步验证了笔者多年教学观察所发现的语法、词汇、语篇衔接等语言知识运用能力低,这一当今大学生普遍存在的写作问题。究其原因,主要是中国大学生英语写作过程中,仍然遵循汉语思维表达习惯,而忽略或很少意识到英汉两种语言的差异,使得作文中充满了汉语式的句子结构、词语搭配及语篇衔接等汉式英语。鉴于篇幅所限,本研究将重点分析词汇搭配错误的汉式特点及其原因。
2.高频词汇错误的汉式特点及原因分析
从表1和表2的统计结果来看,词汇错误在大学生写作中最为普遍。其中,选词和搭配错误非常频繁,错误次数各为538和332(见表2)。鉴于拼写只涉及词汇的表面形式,受汉语影响少,在此不予分析。
首先,词汇的低覆盖率。通过检索发现,和本族语语料库FLOB相比,中国学习者的英语语料库的词汇覆盖面要低很多,他们所掌握的5000词的覆盖面为97.58%,而本族语者这一词汇量只能覆盖文本中86.73%的内容,要达到97%以上的覆盖率,词汇量需达到15000左右。这一数据对比结果表明中国学习者掌握的词汇量极为有限,大大低于本族语者,导致写作时只能频繁使用大量常用词,来弥补自身词汇量的不足,从而容易引起搭配和选词的不当。
其次,词汇的任意搭配。Firth认为“理解一个词要看它的结伴关系”,某些词经常和某些词共现,它们这种“词语间的相互期待”形成了搭配关系[12]。据统计,英语的词汇量至少有50万,而汉语的词汇量最多10万左右,而常用字只有3500左右,覆盖率为99.48%。因此,汉字利用程度高,组合能力强,能以少量字词表达大量事物,表现出用词的经济性。相反,英语倾向于用一个不同的词来表达类似的概念和事物,表现出用词的奢侈性。这样,汉语中搭配合理、耳熟能详的词组对等译成英语却让人大为不解。如汉语可以说:开锁、开山、开学、开车、开枪,而英语中的搭配却是:open the lock、cultivate a mountain、begin school、drivea car、open fire。再如汉语中“大”可以和任何事物搭配,而英语中相应的搭配受到选择性限制,必须分别用big、large、great等。根据FlOB语料库,big所搭配的词语主要是描述具体物体大小的物理属性,因此有 big rocks/man/car/hand/house/school/country搭配,和抽象名词搭配只有demand、meeting、success。great大多和抽象名词搭配,如great deal/meal/importance/variety/majority/interest/pleasure/hospital/detail/help/influence/care/danger/value/change等。而large在Flob语料库中一般和数量词搭配较多,按频率这些词分别为:large scale/number/quantities/sums/majority/audience/proportion/amount/supply/buildings/school/country,其中只有audience和后四个词不是数量词。由于不了解这种搭配上的不对应现象,WECCL语料库中频繁出现将汉英词汇简单对应,按照汉语思维来遣词造句而发生的错误,包括动宾搭配不当,动介、形名搭配不当,同义反复等多种情况[13]。这一点也体现在中国大学生对许多常用动词存在过度频繁使用的倾向上。

表2 写作错误的具体分布/次数
以英语的高频动词“get”为例,通过Antconc检索其在WECCL中出现的频率,得到有关get的索引行有4030条,有效索引行3731条,词频标准化后,最终得到get在WECCL中的标准频数为33.9。以同样的方法检索FLOB后,得到有关get的索引行1449条,得出其标准频数为14.5。卡方检验表明两者存在显著性差异(P<.05)。进一步分析,发现本族语者在使用get时可表示“获得”、“生(病)”、“使迷惑”等17种含义,而中国学生主要用该词来表达“获得”、“变成”和“达到”3个常用义项。可见,由于受汉式思维的影响,中国学生对该词的使用始终停留在最基本的语义层上,对它的掌握非常片面。调查还显示,与本族语者相比,中国学生在选择能和get搭配的词语时,知识极为有限,如表示“得到”义项时,学生过度使用了 knowledge、education、graduation、realization等搭配词,如:
We can't get enough knowledge...
Let their children get higher education...
He didn't get his graduation even...
Tradition helps to get the realization of modernization...
这种过度搭配现象产生的原因除了认知方式和语言结构的影响外,主要是受到母语的干扰,试图按照汉语的搭配,到英语中去找可以对应的词。此外,还有词汇量不够,只能用笼统的常用近义词、上义词去搭配,结果产生中国式英语的“汉式英语”。
通过以上分析,我们可以看出中国大学生由于不了解英汉两种思维模式和表达方式的差别,无意识中倾向于在英语写作中套用汉语的语言规则,而忽视英语的表达习惯,结果错误频出,造出很多不知所云或英语味道不浓的汉式英语。因此,要提高学生英语写作水平,写出地道的英语,教师除了要引导学生关注中西文化及思维差异外,更需要将英汉对比写作教学融入课堂,通过适当的英汉对比分析,尤其是对两种语言的词语搭配和句子结构进行对比分析,来帮助学生深入理解和掌握两种语言的规律,有效克服母语思维习惯在英语写作中的负面影响,真正提高英语表达能力。
[1] 王初明,等.以写促学——一项英语写作教学改革的试验[J].外语教学与研究,2000(3):207-212.
[2] 桂诗春.英语词汇学习面面观[J].外语界,2006(1).
[3] 邓鹂鸣,等.过程写作法在大学英语写作实验教学中的运用[J].外语教学,2004(6):69-72.
[4] 刘红,邓郦鸣.英汉思维模式差异对大学英语写作的影响[J].西安外国语学院学报,2005(1):78-80.
[5] 蔡基刚.英汉写作对比研究[M].上海:复旦大学出版社,2000.
[6] Corder,S.P.The Significance of Learner's Errors[J].International Review of Applied Linguistics,1967(5):161-170.
[7] Selinker,L.Interlanguage[J].International Review of Applied Linguistics,1972(10).
[8] Habbard,P.J.Training Course for TEFL[M].Oxford:Oxford University Press,1981.
[9] Lado,R.Linguistics Across Culture[M].Michigan:The University of Michigan Press,1957.
[10] Ellis,R.The Study of Second Language Acquisition[M].上海外语教育出版社,1994.
[11] James,C.Errors in Language Learning and Use:Exploring Error Analysis[M].Beijing:Foreign Language Teaching and Research Press,2001.
[12] 蔡基刚.英汉词汇对比研究[M].上海:复旦大学出版社,2008:196.
[13] 朱湘华.大学英语写作错误中的汉式英语实证研究[J].绍兴文理学院学报,2010(11):73-77.
A Corpus-based Study of the Characteristics of“Chinglish”in Chinese College Students'English Writing
ZHU Xiang-hua
Through the study method of error analysis,this article extracts the writing corpus in part of non-English majors'writings from WECCL,then counts and classifies the writing errors to show the current students'ubiquitous writing problems in terms of grammar,vocabulary and discourse cohesion,all of which display the students'lower application ability of language knowledge.Furthermore,with the help of AntConc and SPSS,it also counts and analyses the extracted corpus by using FLOB as reference.It has found that the high frequency errors of college students'English writing have “Chinglish” characteristics,comparing with the native speakers.
English writing; error analysis; mother-tongue transfer; Chinglish
H315
A
朱湘华(1978-),女,硕士,讲师,研究方向为语言学及语言教学。
猜你喜欢
小天使·一年级语数英综合(2022年2期)2022-03-30
中华胰腺病杂志(2021年1期)2021-02-26
山东医药(2020年34期)2020-12-09
天津外国语大学学报(2020年1期)2020-03-25
中华胰腺病杂志(2019年4期)2019-08-29
湖南工业职业技术学院学报(2016年6期)2016-04-17
语言与翻译(2015年4期)2015-07-18
人生十六七(2015年29期)2015-02-28
短篇小说(2014年11期)2014-02-27
中华胰腺病杂志(2012年3期)2012-11-07
