
KMV模型对中国上市公司信用风险识别能力的实证研究
2011-11-03 05:07航徐林锋
当代经济 2011年11期
○沈 航徐林锋
(1、南开大学国际经济研究所 天津 300457 2、浙江大学经济学院 浙江 杭州 310007)
KMV模型对中国上市公司信用风险识别能力的实证研究
○沈 航1徐林锋2
(1、南开大学国际经济研究所 天津 300457 2、浙江大学经济学院 浙江 杭州 310007)
KMV模型作为一种结构化信用风险度量和预测工具,在国外成熟市场已被广泛采用。本文选取了66家中国的上市企业作为样本,通过比较其违约距离,检验了KMV模型的信用风险识别能力;同时选取了25家ST企业三年的数据作为样本,通过纵向比较其违约距离,检验了KMV模型的信用风险预警能力。
KMV模型 信用风险管理 违约距离
一、引言
银行是一国金融体系的核心,在国家经济和金融发展中占有十分重要的地位,对于银行来说,信用风险的管理一直是其面临的重要问题。近年来,随着金融危机席卷全球金融业之后,信用风险再次受到整个金融业的极大关注。从我国商业银行的收入结构来看,贷款收入仍然是其收入的主要来源,占到了80%以上。因此,如何有效管理商业银行的信用风险,降低不良贷款率,成为我国商业银行不得不面对的一个严峻问题。我们必须加强在信用风险模型方面的研究,并结合我国的实际情况,开发适合我国国情的信用风险度量和管理技术,促进商业银行信用风险度量和管理水平的提高。
在信用风险的度量中,最重要也是最困难的,一是度量方法的选择,二是信用状况数据的获取。我国目前对于信用风险的度量,主要还是采用一些传统的度量方法。然而这些方法已经无法满足人们的需求。最近十多年来,国外对于信用风险的度量已经向定量化模型发展,许多定价模型、分析技术都在商业中得到应用。其中,KMV公司开发的一种基于股票价格的信用风险计量模型(KMV模型),在全球50多个国家得到广泛应用。该模型认为,由于上市公司的所有行为都会体现在股价的波动上,因此上市公司股票价格变动的信息往往预示着该公司信用状况的变化。该模型通过对资本市场数据的处理和计算,得到反映公司财务状况和信用状况的数据。由于信用数据的缺乏一直是中国金融市场面对的重大难题,因此直接利用资本市场数据来进行信用风险度量的KMV模型在我国有着广泛的应用前景。
二、理论模型
1、模型的核心思想
KMV模型是由美国KMV公司以经典的默顿模型为理论基础开发的。Merton提出的风险债务估值理论认为银行债权人贷出一笔款项所得到的报酬与卖出一份借款企业的看跌期权是同构的,当贷款到期时,借款公司在利息贴现基础上向银行偿还数额为X的风险贷款,此时借款公司的资产市场价值为VA,在风险贷款到期日,如果VA>X,则借款公司有动力偿还贷款X,此时银行会得到一个固定的贷款收益,利息和本金都能够得到全部偿还;如果VA<X,借款公司由于丧失偿还贷款的能力,迫于无奈会选择违约,此时银行将遭受损失,损失的大小取决于贷款价值与公司剩余价值之间的差额。
KMV模型修正了其看法,认为一个公司的市场价值低于其总负债时违约就会发生的假设是不准确的,它假设当公司资产价值低于某个水平时,违约才会发生,并将这个水平上的公司资产价值定义为违约点(Default Point,DP),而违约风险则被定义为企业资产价值小于此违约点的概率。
2、模型的实现过程
KMV模型主要是利用预期违约概率EDF的值来判断一个公司在未来一定时期发生违约的概率。模型共分三个步骤来确定一个公司的EDF。
(1)估计资产价值及其波动性。KMV模型认为对于一家上市公司而言,我们无法直接观测到其资产的市场价值和资产的市场价值的波动率,但是可以直接观测到其股票的价格和股价的波动率。因此,可以通过期权定价公式来反向求出前者,即:

其中:VE表示公司的权益价值,VA表示公司的资产价值,σE表示公司资产的波动率,r表示无风险利率,B表示负债的账面价值,t表示时间范围,σE表示权益价值的波动率。套用B-S公式后可得:
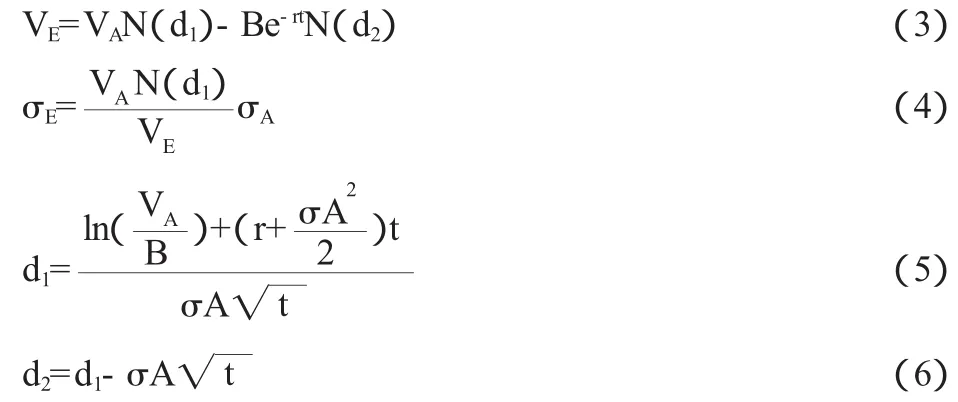
(2)计算违约距离DD。企业的资产价值及其波动性计算出来后,为了计算违约距离,还需要先确定企业的违约点。在现实中,多数企业在其资产价值相当于所有债务的账面价值时并没有违约,当然也有许多企业此时发生违约,这是因为一些长期债务为该企业提供了喘息机会。KMV公司通过对大量违约企业的数据进行分析后得出结论,企业的违约触发点通常位于流动负债与总债务金额之间。在实证研究中,违约实施点一般等于流动负债加50%的长期负债,即:其中,STD为短期负债,LTD为长期负债。

违约距离DD的定义是一年后资产的未来预期价值E(V)和违约点DP之间的距离相对于未来资产收益的标准差,即:

违约距离测度是一个标准化的度量方法,可用于不同公司之间的比较,反应公司信用状况的好坏。该值越大,说明公司到期能偿还债务的可能性越大,发生违约的可能性越小,则该公司的信用状况越好;该值越小,说明公司到期偿还债务的可能性越小,则该公司信用状况越差。因此,“违约距离”可以作为评判公司信用状况的一个指标。
(3)估计预期违约率EDF。KMV模型根据具有不同违约距离值的公司历史违约数据,确定了违约距离与违约率之间的映射关系。具体来讲,就是基于一个包含大量违约公司样本的历史数据库,计算公司的违约距离及由历史数据观察到的违约率,把这些数据拟合成一条平滑的DD-EDF曲线来表示违约距离函数,以此来估计预期违约率EDF的大小。由于我国关于企业违约事件的统计资料不完全,并未建立完整的企业违约资料库,所以目前还无法根据KMV公司的经验EDF公式来计算预期违约率。
三、实证分析
1、ST与非ST企业
(1)数据采集与假设条件设置。本文选取了66家制造业的上市公司,其中33家为2010年被ST处理的公司,另外33家为正常的公司。由于ST公司通常预示着企业财务的失败,因此从理论上来说违约风险要大于正常的公司。在选取样本时,本文遵循以下的配对原则:配对的两家企业属于同一行业,配对的两家企业资产规模相近。
为了便于实证分析,现作如下假定:第一,公司违约实施点的设定按照KMV公司的处理方法,即违约点(DP)=流动负债(STD)+0.5*长期负债(LTD)。第二,时间T为1年,即计算1年期的违约距离和违约概率,计算的基准日为2009年12月31日。第三,无风险收益率采用的是金融机构一年期定期存款利率,为2.25%。第四,假定公司股票价格服从对数正态分布。
(2)实证过程。其一,计算股价波动率。本文采用历史波动率法来估计上市公司股权市场价值未来一年的波动率,即用上市公司前一年的股票价格波动率来估计其未来一年的价格波动率。此处采用2009年的股价波动率代替2010年的股价波动率。根据股票价格服从对数正分布的假定,股票的对数收益率为:

其中,Sn代表第n天的股票收盘价格。股票价格的日波动率为:
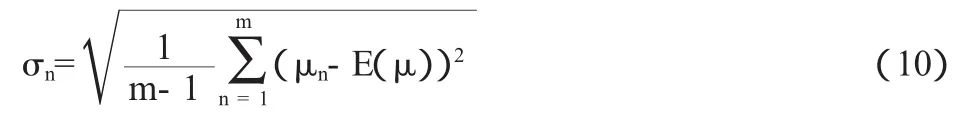
其中:

将股价数据代入上述公式,即可得到日收益波动率。根据日收益波动率,我们可以算出年收益波动率,公式如下:

其中,N表示一年的交易天数,本文取244天。
其二,计算股票的市值。我国存在着流通股和非流通股两大类股。流通股的价格可以直接从证券市场获得,而非流通股的市价无法直接采用证券市场的价格,因此本文对于非流通股的价格,采用每股净资产来代替,即:股权市值=流通股数*市价+非流通股股数*每股净资产。
其三,计算违约点。本文计算违约点时,采用KMV公司的经验公式,即:

其中,STD为短期负债,LTD为长期负债。根据以上公式,即可计算出各公司的违约点。
其四,计算公司资产价值与其波动率。本文在计算公司资产价值以及其波动率的时候,假定公司资产价值符合标准正态分布,且假设资产市场价值增长率0。将前三步的计算结果代入公司(3)—(6),利用matlab中的fsolve命令进行联立求解,就可以计算出公司的资产价值与波动率。
2、ST企业三年的违约距离
本文选取上述25家2010年被ST企业,对其三年的违约距离进行纵向比较,检验该模型对于上市公司信用风险状况变化的预测能力。计算步骤与上述过程相同。
3、实证研究结果
(1)违约距离横向比较结果。对33家ST企业与33家非ST企业的违约距离进行t检验和Wilcoxon检验,分别检验两组独立样本的均值和中值是否具有显著的差异。用Eviews对两组企业的违约距离DD进行均值与中值的t检验,检验结果如表1所示。

表1 违约距离t检验与Wilcoxon检验结果
从检验结果可以看出,在95%的置信水平下,原模型通过显著性检验,即ST企业与非ST企业的违约距离存在着显著的差异。可以看出,非ST企业违约距离的均值显著大于ST企业违约距离的均值。由于违约距离越大说明了信用风险越小,因此该结果表明了ST企业的信用风险要普遍大于非ST企业的信用风险,这与实际情况相符合,说明了KMV模型对于中国上市公司信用风险具有良好的识别能力。
(2)违约距离纵向比较结果。25家ST企业被ST前三年的违约距离变化如图1所示。
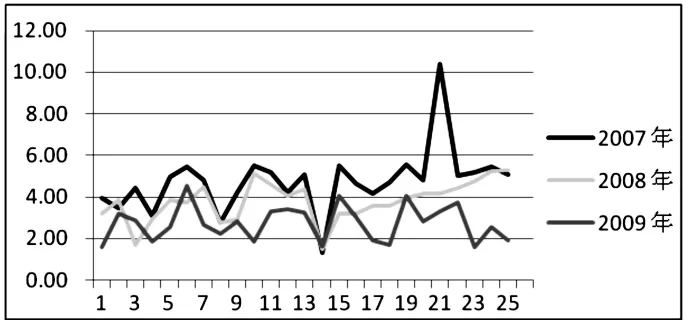
图1 ST企业2007-2009年违约距离变化
从图1可以清晰地看到,ST企业在被ST前三年,违约距离逐渐减少,这意味着其信用状况逐渐恶化,违约风险逐渐上升,与现实相符。此结果说明,KMV模型对于上市公司信用状况变化的预测能力也较为良好。
四、结论及启示
1、主要结论
本文通过实证分析,发现KMV模型在中国具有一定的适用性。对于不同信用状况的公司,KMV模型最终得出不同的违约距离,并且不同信用状况的公司之间,违约距离存在着显著差异,因此该模型具有良好的风险识别能力。同时,随着某公司信用状况的恶化,违约距离会随之减少,因此对于同一公司信用风险状况的变化,该模型也进行了较好的预测。综上所述,我国商业银行能够将KMV模型纳入其信用风险管理体系,用其来识别与预测某公司的信用风险。
另外,本文在研究中,发现具体在我国运用KMV模型时,如能考虑以下的因素,将会使得到的结果更为真实可信。
(1)考虑宏观经济状况对违约距离的影响。在进行纵向比较中,本文得出KMV模型具有良好预测能力隐含的前提是:违约距离的下降完全是由于公司本身信用状况的变化造成的。由违约距离的定义式可以看出,资产的波动率和违约距离存在着负相关,波动率的增加会直接导致违约距离的下降。
然而在中国的资本市场,不同年度整个股票市场的整体波动率存在着差异,而这种差异很多时候并不是由于上市公司的经营或财务状况出现异常所导致,而是由于一些宏观经济因素造成的。因此,在进行违约距离的纵向比较时,由于违约距离受股价波动率的影响较大,还应该结合不同年份股市的整体波动情况来分析。本文在进行纵向比较时,没有剔除年份整体波动率对违约距离造成的影响,因此在今后的研究中需要进一步修正。
(2)针对具体行业设置不同违约点。对于违约点的设置,本文参考的是KMV公司给出的经验公式。违约点的经济含义其实就是公司资不抵债的临界点,那么具体到不同行业,由于其业内企业资本结构和经营特点的差异,违约点应该也各不相同。因此,如何根据各行业分别得出其最实用的违约点,也是今后研究中一个需要关注的问题。
2、启示
为进一步提高KMV模型的运用效果,改善我国商业银行信用风险管理的现状,我国还需要完善如下工作。
在一个有效的股票市场中,股价中包含着市场对于企业未来发展与走势的预期,一个公司的股价如果大幅波动,则意味着市场对于该公司经营与发展的不确定性,经营的不确定性即意味着潜在的风险。因此根据股价波动大小来判别公司信用风险的高低有一定的可行性。所以KMV公司验证结果是否可信的一个重要前提就是资本市场的数据是否能客观反应相应企业的财务和经营状况。只有进一步提高资本市场的有效性,才能使KMV模型的检验与预测结果更加真实客观。
(2)尽快建立企业违约资料库。在KMV模型进行信用识别时,还要进行由违约距离到预期违约率的计算。但由于我国关于企业违约事件的统计资料不完全,并未建立完整的企业违约资料库,因此导致本文无法进行EDF的进一步计算。有不少学者在将KMV模型应用于中国时,得出违约距离后会按照风险中性的原理推到EDF,但笔者认为这一步意义不大,因为根据风险中性原理得出的EDF值并无参考价值,只有根据我国现实中违约统计信息建立起资料库,建立违约距离与EDF之间的映射关系,才能使EDF值具有运用价值。
[1]Zavgren C.:Assessing the vulnerability to failure of American industrial firms:a logistic analysis[J].Journal of Business,Finance and Accounting,1985(12).
[2]Madan,D and H.Unal.:Pricing the risks of default.Review of Derivatives Research,1998,2(2/3).
[3]Madan,D and H.Unal.:Pricing the risks of default[J].Review of Derivatives Research,1998,2(2/3).
[4]吴世农、卢贤义:我国上市公司财务困境的预测模型研究[J].经济研究,2001(6).
[5]周昭雄:基于我国上市公司的KMV模型研究[J].工业技术经济,2006(7).
[6]鲁炜、赵恒、刘冀云:KMV模型关系函数推测及其在中国股市的验证[J].运筹与管理,2003(6).
[7]沈沛龙:上市公司财务风险分析与信用评级[J].投资理财,2006(12).
[8]李秉祥:基于主成分分析法的我国上市公司信用风险评价模型[J].西安理工大学学报,2005,21(2).
[9]王琼、陈金贤:信用风险定价方法与模型研究[J].现代财经,2002(4).
(责任编辑:李文斐)
猜你喜欢
中国听力语言康复科学杂志(2021年6期)2021-12-21
中国外汇(2019年13期)2019-10-10
今日农业(2019年12期)2019-08-13
文学少年(原创儿童文学)(2019年1期)2019-05-23
中国化肥信息(2019年3期)2019-04-25
环境保护与循环经济(2017年2期)2017-09-26
辽宁经济(2017年6期)2017-07-12
中国法学教育状况(2017年0期)2017-05-29
当代经济(2016年26期)2016-06-15
新疆财经大学学报(2015年3期)2015-12-10
