
基于Carrot2聚类的垂直搜索引擎的研究与实现
2012-01-06 02:31阳春辉陶秋红杨军伟
河北工业科技 2012年3期
高 凯,阳春辉,陶秋红,张 洋,杨军伟
(1.河北科技大学信息科学与工程学院,河北石家庄 050018;2.石家庄职工大学,河北石家庄050041;3.北京首都国际机场,北京 100621)
基于Carrot2聚类的垂直搜索引擎的研究与实现
高 凯1,阳春辉1,陶秋红2,张 洋3,杨军伟1
(1.河北科技大学信息科学与工程学院,河北石家庄 050018;2.石家庄职工大学,河北石家庄050041;3.北京首都国际机场,北京 100621)
给出了一个基于Nutch的垂直搜索引擎系统的实现,主要探讨了基于Lucene和Carrot2的信息检索与聚类的实现,并对分词、垂直信息采集等的实现进行了说明。
搜索引擎;Lucene;Nutch;分词;聚类
伴随着因特网的迅速普及和应用,网络已成为人们获取信息的重要渠道。为了帮助人们方便、高效地利用网络信息,搜索引擎应运而生。传统搜索引擎往往不能很好地满足一些特定用户的检索需求,因此研发面向特定领域的垂直搜索引擎非常有必要。由于校园网链接稀疏、特定关键字重复度高,因此把基于互联网搜索引擎的链接分析技术应用于校园网信息检索时效果并不理想[1]。相关工作中,文献[2]提到一种有效的相关概念反馈策略;文献[3]给出对中文语料抽取主题概念词的一种方法;文献[4]和文献[5]对信息采集过程中的采集策略等分别给出了相应的算法和实现,给出基于聚类的中文垂直搜索引擎系统的实现,并在校园采风搜索引擎系统中使用,效果良好。
垂直搜索引擎通过主题爬虫来抓取网页,再经过全文检索索引和提供给用户检索界面来实现。其中主题爬虫对互联网信息采集后会扔掉不相关的页面,实现的主题信息采集的爬虫往往用时短,速度快。垂直搜索引擎爬虫可以用有限的网络带宽和存储资源,在较短的时间内获得更多、更相关的关于某一主题的信息资源。
Nutch内部使用了Lucene的索引和检索技术并有自己的网络蜘蛛,是一个真正的搜索引擎[6]。Nutch为人们提供了运行自己的搜索引擎所需要的全部资源。Nutch遍历网站的资源,将这些资源抓取到本地,分析网站内每一个有效的URL,并提交HTTP请求,从而获得相应结果,生成本地文件及相应的日志信息等。LUCENE为Nutch提供了文本索引和搜索的API[7]。Nutch具有良好的可扩展性和灵活性。Carrot2是一个开源的基于搜索结果的聚类工具,可以把 Google,MSN Live,Yahoo!,Lucene Index等搜索结果组织成不同的主题[8]。
1 系统实现
在Nutch架构的基础上开发了一个专注于教育与校园网信息采集的搜索引擎,并基于Carrot2实现了对检索信息的聚类。实践表明,其具有较好的可用性。
1)完成系统配置过程 在服务器上安装FreeBsd1.0版本的Unix操作系统,开启SFTP服务,用Filezilla作为数据上传下载工具,用Putty作为远程控制工具。下载Unix版本的JDK及Tomcat6.0,在/etc/profile中写好相应的环境变量。把配置好的 Nutch-1.0拷贝到用户文件夹,写好Nutch运行、Tomcat启动和停止等脚本。
2)完成对搜索引擎的配置和设定工作 作为专门服务高校的专业化搜索引擎,需要构建各高校有关的资源库、限定索引范围。
①种子集设定 通过在主流搜索引擎中给定相关关键词和来源等(如:大学 招生 就业 网site:edu.cn)采集信息,设置每页显示结果数并进行相关处理获取大量分类网址。修改 ${nutch}\conf下的crawl-urlfilter.txt,通过正则表达式限定,抓取想要的网页。运行时,基于Nutch的爬虫可以实现只抓取特定范围的内容,获取后保存到索引中,同时刷新旧索引内容。
②异构文件处理 爬虫从互联网下载的文件格式有很多,为使 Nutch能处理pdf,doc,xls,ppt等文档,可下载相关插件并在配置文件中声明。文件类型识别方法很多,在此系统中截取索引URL字段后3位作为文件类型最简单,并将其添加在对应搜索结果前面。
③中文分词 搜索引擎最早是以英文为搜索关键字,英文单词间用空格分隔,切分容易实现。中文是以字为单位的,词汇之间没有分隔,这就增加了检索中文的难度。Lucene为中文用户提供了2个正向最大匹配的中文分词CJKAnalyzer和ChineseAnalyzer,但分词效果都不太理想。经过对CJKAnalyzer,JE,ICTCLAS几种分词方案的对比,笔者选择JE分词。
④聚类 系统采用Carrot2建立的基于文本的搜索结果聚类引擎[9]。Carrot2中使用比较多的2种聚类算法是Lingo(基于奇异值分解的聚类算法)和STC(后缀树聚类算法)。Lingo算法是先提取出聚类标签,然后给各个标签分配文档,以形成最终的聚类。STC算法使用的主要数据结构是一个为所有输入文档建立的广义后缀树(GST)。该算法遍历GST,以识别在输入文档中出现次数大于1的单词和短语。每一个这样的单词或短语产生一个基本聚类,最终合并基本聚类,形成聚类[10]。
⑤信息检索 系统可根据不同用户的检索习惯,完成部分个性化的处理工作。如对每页显示结果的处理,检索时可以根据需要自己定每页显示的结果数。
2 实验结果分析
2.1 分词效果分析
为了测试分词效果,笔者设计了相关的实验。测试环境为FreeBsd 1.0,CPU 2.9GHz,内存2.00 GB,JDK 6.0。由于 CJKAnalyzer和 ChineseAnalyzer分词效果不理想,在此仅对JE和ICTCLAS分词方案性能进行对比分析。索引源内容采用河北科技大学校内3万多个网页,索引字段数为13个。搜索结果见表1。
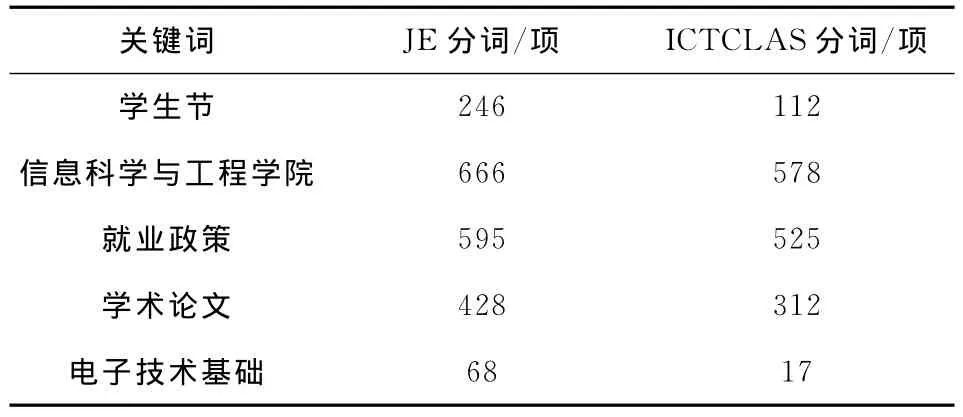
表1 JE,ICTCLAS搜索结果项对比表Tab.1 Comparison of JE,ICTCLAS search results
用ICTCLAS后得到的索引文件比用JE后得到的索引文件约小6.68%,这与JE生成的词项数比ICTCLAS多有关。JE索引耗时比ICTCLAS多,ICTCLAS分词速度优于JE。结合JE,ICTCLAS分词效果对比可知,如果对分词效果要求非常高,应选用ICTCLAS。考虑到ICTCLAS分词太精确会让查全率可能有所降低,为了在分词效果和搜索效果方面取得一个较优效果,本系统选用JE分词。
2.2 Lingo与STC聚类算法比较
由于Lingo和STC聚类算法不一样,因此二者有不同的聚类特点。在搜索界面输入关键词University Technology,2种聚类算法结果比较见表2。
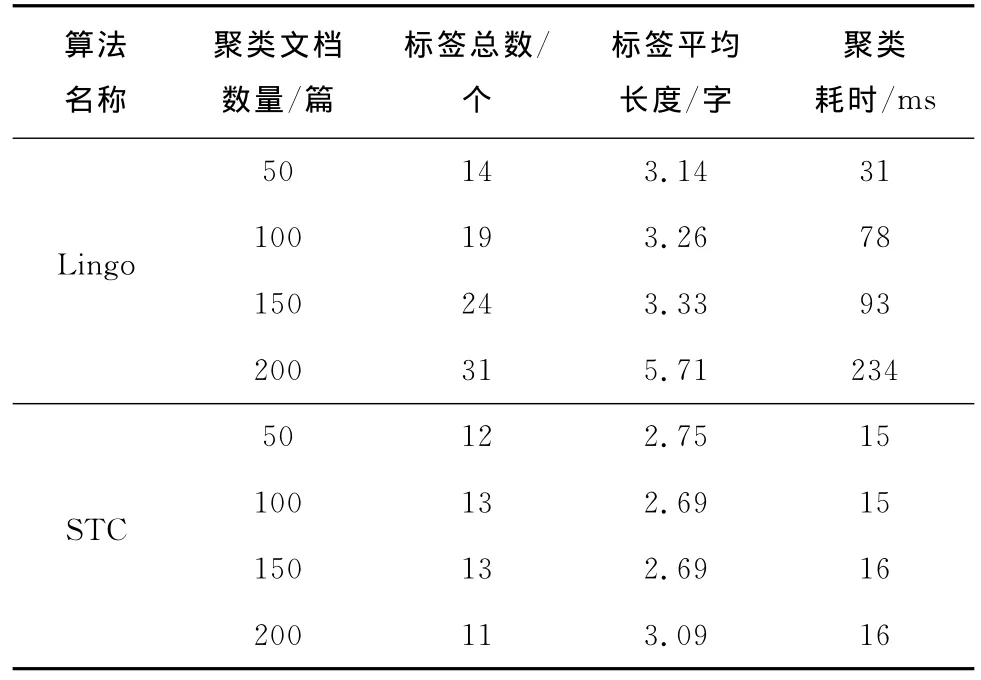
表2 Lingo和STC的聚类结果对比Tab.2 Comparison of Lingo and STC clustering results
由表2可见,在默认设置下,Lingo聚类标签很长,往往有很多的描述。聚类多样性高,会产生许多小的聚类,但其可扩展性低,对超过约1 000份文件进行聚类,将需要很长时间和很大的内存。STC聚类标签短,聚类多样性低,很少会产生小的聚类。此外,STC可扩展性比Lingo高。实际中应用哪种算法,视情况而定。在基于Carrot2实现的系统中,采用的是STC算法。
3 结 语
给出基于Nutch架构实现的垂直搜索引擎系统,结合Carrot2实现了信息聚类,并对分词性能和聚类算法进行了实验和分析。该系统目前已经上线,并面向校内用户使用,用户评价良好。
[1]宋光慧,聂 琰,郭建康.基于Nutch的校园网信息检索系统的研究与实现[J].中国教育信息化,2010(15):65-66.
[2]GAO Kai.Presenting implicit relevance feedback in educational search engine[J].Computer Applications in Engineering Education,2011,19(2):294-304.
[3]GAO Kai,LI Y J.Modelling on Chinese subject-term extracting algorithm[J].International Journal on Modelling,Identification and Control,2011,13(3):202-208.
[4]高 凯.搜索引擎中信息动态采集策略的研究[J].电子学报,2007,35(10):1 984-1 988.
[5]GAO Kai,ZONG B Q.Web information processing and extracting[A].Proceedings of the 9th International Conference on Machine Learning and Cybernetics[C].[s.l.]:[s.n.],2010.2 350-2 355.
[6]高 凯,许云峰,郭立炜.网络信息检索与搜索引擎技术[M].北京:科学出版社,2010.
[7]LUCENE.Nutch官网 Nutch技术介绍[EB/OL].http://wiki.apache.org/nutch/2012-04-06.
[8]王学松.Lucene+Nutch搜索引擎开发[M].北京:人民邮电出版社,2008.
[9]陈菊红.搜索引擎返回结果聚类技术的研究与实现[D].成都:西南交通大学,2009.
[10]贺 玲,吴玲达,蔡益朝.数据挖掘中的聚类算法综述[J].计算机应用研究,2007(1):10-13.
Research and implementation of vertical search engine based on Carrot2clustering
GAO Kai1,YANG Chun-hui1,TAO Qiu-hong2,ZHANG Yang3,YANG Jun-wei1
(1.College of Information Science and Engineering,Hebei University of Science and Technology,Shijiazhuang Hebei 050018,China;2.Shijiazhuang Staff and Workers University,Shijiazhuang Hebei 050041,China;3.Beijing Capital International Airport,Beijing 100621,China)
This paper presents the implementation of vertical search engine based on Nutch,mainly the implementation of the Lucene and the Carrot2for information retrieval and clustering.Moreover,the paper also introduces in some details the Chinese word segmentation and data collection.
search engine;Lucene;Nutch;Chinese word segmentation;clustering
TP311
A
1008-1534(2012)03-0155-03
2012-03-02
李 穆
河北省科技支撑计划项目(12213516D)
高 凯(1968-),男,山东章丘人,副教授,博士,主要从事自然语言处理、信息检索、数据挖掘、云计算等方面的研究。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
电子制作(2017年9期)2017-04-17
新闻传播(2016年18期)2016-07-19
现代计算机(2016年11期)2016-02-28
电子设计工程(2015年6期)2015-02-27
河南科技(2014年11期)2014-02-27
