
基于CUDA的运动估计算法研究
2012-09-20 03:29赵海国
湖南理工学院学报(自然科学版) 2012年2期
赵海国
(湖南理工学院 数学学院, 湖南 岳阳 414006)
基于CUDA的运动估计算法研究
赵海国
(湖南理工学院 数学学院, 湖南 岳阳 414006)
运动估计是H.264视频编码器中复杂度最高、耗时最长的模块. 本文介绍了运动估计的基本原理以及全搜索算法FS(Full Search)和钻石搜索法DS (Diamond Search )等经典的运动估计算法, 并引入了基于CUDA的运动估计算法: 全域消除GEA算法和基于CUDA 的并行 FS算法, 有效地提高了H.264视频编解码速度.
运动估计; 统一计算设备架构; 全搜索算法; 钻石搜索法; 全域消除算法
H.264是目前最新的视频压缩标准, 也是视频压缩领域中编码效率较高且图像质量较好的编解码标准,在实际中有着广泛的应用. 比如摄像头采集的原始图像, 相邻帧的差别往往比较小, 特别在视频监控领域相邻两帧图像甚至可能完全相同. 这样的图像帧之间包含着大量的重复信息, 视频编码就是在不影响图像质量的情况下去除这些冗余信息, 从而达到压缩视频数据、节约存储资源的目的.
分析H.264视频编码器的典型运行周期, 在H.264编码过程中, 复杂度最高、耗时最长的是运动估计/补偿部分, 占80%以上(见表1). 为了提高整体的编码速度, 高效、快速地实现运动估计模块是编码系统设计的关键.

表1 H.264编码器中各模块分析表
1 运动估计的基本原理
运动估计是H.264编码器帧间预测的核心技术. H.264视频编解码器在帧间预测的过程中, 充分考虑活动图像相邻帧之间的相关性, 将活动图像分成若干块或宏块, 并设法搜索出每个块或宏块在邻近参考帧图像中的位置, 并得出两者之间的空间位置的相对偏移量, 该相对偏移量就是通常所指的运动矢量(MV), 得到运动矢量的过程被称为运动估计[1]. 由此可见, 运动估计就是从图像序列中对图像帧内运动的图像区域使用某种算法来提取它的运动矢量, 并且存储的过程中也只存储其运动矢量, 这样就能实现使用最小的比特数开销来表示宏块的运动, 达到视频压缩的目的.
为了获取最优的匹配块位移的运动矢量, H.264中通常采用基于块匹配的运动估计搜索算法. 在编码器进行运动估计的过程中, 首先采用16×16、8×16、16×8、8×8、4×8、8×4、4×4共7 种块分割模式将图像帧分成多个大小相同的宏块, 并假定宏块内各像素具有相同的运动矢量, 然后搜索参考帧中与当前宏块最匹配的宏块, 计算出两者之间在空间上的相对偏移量即为运动矢量, 这就是基于块匹配的运动估计搜索过程.
2 运动估计的经典算法
H.264采用的基于块匹配的运动估计搜索算法中较经典的有全搜索算法FS(Full Search)和钻石搜索法DS (Diamond Search )等.
全搜索算法(简称FS算法)也被称为穷尽搜索算法, 是最简单可靠的运动估计算法[2]. 该算法对搜索窗口范围内所有可能的匹配位置都进行检测, 对所有可能的候选位置都计算 SAD (sum of absolute difference) 值, 从中找出最小的SAD, 其对应原点的偏移即为最佳运动矢量. 该算法的搜索路径有两种:采用光栅扫描顺序从左到右或者从上到下进行搜索, 或以坐标原点为中心进行螺旋型搜索[2]. 由于FS算法是对整个搜索窗口的每一个位置进行块匹配计算, 所以该算法得到的匹配位置是理论上的最优位置,但计算量太大, 特别是在实时压缩场合应用受限.
菱形搜索法(简称DS算法)也称钻石搜索法, 该算法主要是通过降低搜索点数的方法来加快搜索的速度[2]. 大部分的钻石搜索法是以搜索模板为基础的, 当使用不同大小和不同形状的搜索模板时相应的搜索速度和算法性能也会各不相同. 在搜索模板中如果选择了过大的搜索半径, 则非常容易产生错误的搜索方向; 但如果选择了过小的搜索半径, 又容易产生局部最优解. 为了使菱形搜索法既能保证搜索的准确度, 同时又能提高搜索的效率, 该搜索法选择两种不同大小的菱形搜索模板配合使用, 包括有9个搜索点的大菱形模板LDSP ( Large Diamond Search Pattern)以及只有5 个搜索点的小菱形模板SDSP (Small Diamond Search Pattern). 首先使用含有9个搜索点的大菱形搜索模板进行搜索, 该模板的搜索半径相对比较大, 能够避免产生局部的最优解; 然后再使用含有5 个搜索点的小菱形搜索模板来搜索, 该模板的搜索半径相对比较小, 能够保证搜索的精度更高, 这样大小搜索模板配合使用能够使菱形搜索法的搜索结果比较稳定[2].
3 基于CUDA的运动估计算法
CUDA(Compute Unified Device Architecture)是由NVIDIA推出的通用并行计算架构[3], 是一种将GPU作为数据并行计算设备的软硬件体系. 与以住GPU相比,该架构既能使用GPU并行计算来解决复杂的计算问题, 又引入了片内共享存储空间实现线程间通信, 同时还可以减小片外访存延迟, 这些改进使GPU更适合通用计算[2]. 在CUDA架构下, 程序被分为两个部分: Host端和Device端(如图1所示), 即源程序由运行于 host(CPU)上的控制程序和运行于device(GPU)上的计算核心 kernel两部分组成. 每一个kernel 由一组相同大小的线程块thread block来并行执行 ,同一线程块内的线程通过共享存储空间来协作完成计算.
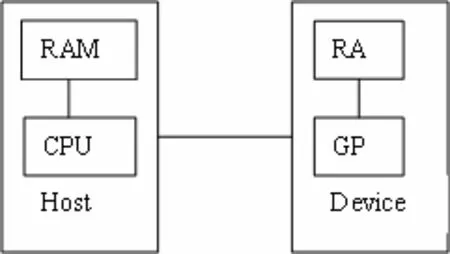
图1 CUDA的Host-Device模式
将H.264/AVC中计算量较大的运动估计运算移植到CUDA中来处理, 可以充分发挥GPU的并行计算能力, 达到提升编码效率的目的. 全搜索算法基本都是采用固定窗口, 采用穷举的方式对窗口内所有的位置进行遍历, 计算每个位置的SAD值, 得到最优化预测编码的图像质量. 该算法简单、有规则性, 非常适合GPU并行化处理. 目前为止研究利用CUDA降低H.264视频编码的计算时间取得了一定的成果. 陈佐, 陈汉, 季加良提出了快速全搜索算法—全域消除算法(GEA)[4]. GEA算法将大小为的块分割成个大小为的子块. 当前块记为C, 搜索块记为S, 当前块的单个子块内全体像素和记为CS, 候选块的单个子块内全体像素之和记为SS. 在全搜索块匹配算法(FSBM)中, 匹配准则是块中所有像素的绝对差之和, 亚采样SAD(SSAD)是CS和SS之间的绝对差之和[4]. 该算法先计算所有SSAD, 找到最可能的M个运动向量, 这些向量具有最小的M个SSAD值, 再将所有候选块中第M小的SSAD值记为SSADM, 最后计算M个搜索位置对应的SAD, 以找出最优的运动向量[4]. 为了测试算法的性能, 分别在CPU与GPU环境下按照各自算法具体实现GEA搜索算法, 对不同分辨率测试序列中各取100帧进行测试, 实验结果表明(如表2所示): 采用CUDA在GPU环境下实现的GEA搜索算法性能比CPU中有显著提高, 可获得近9倍的加速比.
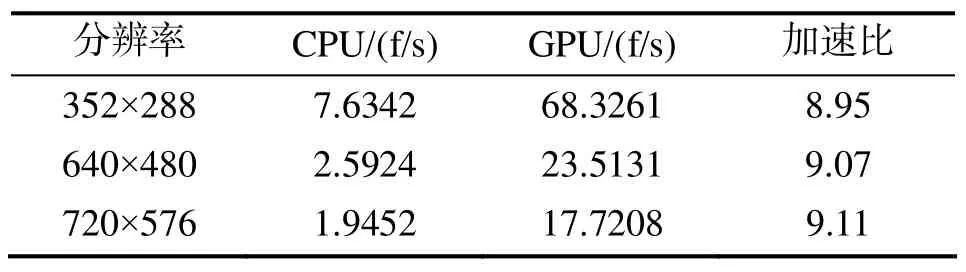
表2 算法运行在CPU与GPU环境下的性能对比
为了充分利用CUDA构架下GPU并行运算的特性,让运动估计中的全搜索算法在GPU上得到更好的优化,甘新标, 沈立, 王志英提出了一种基于CUDA的并行全搜索运动估计算法[3]. 针对H.264的树状结构运动估计有16×16、8×16、16×8、8×8、4×8、8×4、4×4共7种宏块分割模式的特点, 基于CUDA 的并行FS算法中, CUDA源程序中运行于device(GPU)上的计算核心kernel可启动7个SAD计算实体来并行计算各种分割方式下最小的SAD, 分别记为SAD1, SAD2, SAD3, SAD4, SAD5, SAD6和SAD7, FS算法取最小的SAD为帧间预测模式, 即为最小SAD对应的分割方式:在SAD的并行计算和比较模型中, 该算法使用了共享存储空间, 让同一个线程块里面的线程可以通过共享存储空间进行通信, 减少了数据的存取时间, 提高了算法的效率. 同时考虑到运动矢量不仅在空间域上存在相关性, 物体运动的连续性使得运动矢量在时间域存在一定相关性, 可采用MVP机制对基于空间域的运动矢量进行中值预测,预测当前块的运动矢量为其相邻宏块(左边块,上边块和右上方块)的运动矢量的中值, 避免对每个块的运动矢量进行编码, 提高了算法的效率. 实验分别在CPU上实现FS算法, 基于CUDA构架下使用GPU并行运算实现FS算法, 对不同分辨率测试序列进行测试. 实验结果表明(如表3所示):基于CUDA的并行FS算法相比在CPU上获得了近70倍的加速比, 且图像分辨率越大, 加速的效果越好.

表3 并行FS算法运行在CPU与GPU环境下的性能对比
4 总结
为了高效、快速地实现H.264编码过程中复杂度最高、耗时最长的运动估计模块, 提高H.264视频编解码速度. 本文介绍了运动估计的基本原理以及全搜索算法FS(Full Search)和钻石搜索法DS(Diamond Search )等经典的运动估计算法, 并引入了基于CUDA的运动估计算法降低H.264视频编码计算时间, 其中快速全搜索算法—全域消除GEA算法, 获得近9倍的加速比; 基于CUDA的并行FS算法, 获得近70倍的加速比, 且图像分辨率越大, 加速的效果越好.
[1] 郑兆青. 用于H.264视频编码的运动估计VLSI结构研究[D]. 武汉: 华中科技大学博士学位论文, 2007, 2
[2] 万 双.H.264中运动估计的并行计算实现[D]. 武汉: 中南民族大学硕士学位论文, 2009, 6
[3] 甘新标, 沈 立, 王志英. 基于CUDA的并行全搜索运动估计算法[J]. 计算机辅助设计与图形学学报, 2010, 22
[4] 陈 佐, 陈 汉, 季加良. 运动估计搜索算法的CUDA优化与实现[J]. 计算机工程与应用, 2010, 46(32)
Research on Motion Estimation Algorithm Based on CUDA
ZHAO Hai-guo
(College of Mathematics, Hunan Institute of Science and Technology, Yueyang 414006, China)
Motion estimation is the most time complexity part of Video Compression Standard H.264. This paper introduces the principle of motion estimation and classical motion estimation algorithms such as Full Search algorithm and Diamond Search algorithm, and this paper proposes motion estimation algorithm using CUDA, for example, Global Elimination Algorithm and parallelizing Full Search Algorithm for motion estimation using CUDA, which can accelerate the encoding and decoding process of H.264 significantly.
motion estimation; Compute Unified Device Architecture(CUDA); Full Search Algorithm(FS); Diamond Search Algorithm(DS); Global Elimination Algorithm(GEA)
TP317.4
A
1672-5298(2012)02-0034-03
2012-02-12
赵海国(1980- ), 女, 湖南邵阳人, 湖南理工学院数学学院讲师. 主要研究方向: 计算机软件开发
猜你喜欢
成都信息工程大学学报(2021年3期)2021-11-22
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
电子设计工程(2015年24期)2015-08-26
电测与仪表(2015年15期)2015-04-12
河北科技大学学报(2015年5期)2015-03-11
中央民族大学学报(自然科学版)(2014年1期)2014-06-11
郑州大学学报(理学版)(2013年3期)2013-03-11
杭州电子科技大学学报(自然科学版)(2011年5期)2011-09-04
电视技术(2011年11期)2011-03-15
意林(2008年12期)2008-05-14
