
基于视觉内容与语义相关的图像标注模型
2012-12-27 06:00宋海玉李雄飞包翠竹岳青宇
大连民族大学学报 2012年1期
宋海玉,李雄飞,包翠竹,金 鑫,岳青宇
(1.大连民族学院计算机科学与工程学院,辽宁大连116605;2
.吉林大学计算机科学与技术学院,吉林长春 130012)
基于视觉内容与语义相关的图像标注模型
宋海玉1,2,李雄飞2,包翠竹1,金 鑫1,岳青宇1
(1.大连民族学院计算机科学与工程学院,辽宁大连116605;2
.吉林大学计算机科学与技术学院,吉林长春 130012)
针对当前标注系统的不足,设计了一种高效的标注模型,其标注步骤包括标注和标注改善,标注算法采用加权的正反例标志向量法,标注改善采用NGD方法。实验表明,标注效率远优于经典的标注模型,标注质量优于大多数标注模型。
图像标注;标注改善;归一化Google距离
近年来,随着计算机技术、数码技术、存储技术的迅速发展,以及计算机网络的普及,每天大量的图像由数码产品制作,并在网络上存储、传播。如何有效地访问和管理这些数据成为一项亟需解决的课题。近年来涌现出了很多经典的基于内容的图像检索系统(CBIR),例如 IBM QBIC,MIT PhotoBook等。它们都是通过计算图像的底层视觉信息(如颜色、纹理)确定相似图像。尽管CBIR系统取得了很大进展,但其检索效果和方式依然不能令人满意。其主要原因是计算机所使用的低层视觉特征与人所理解的高层语义之间存在着巨大的语义鸿沟[1]。人们更习惯于提交待检索目标对象的名称或者相关的语义描述作为检索线索,而不是提交一幅完整图像。此外,CBIR仅仅解决了图像检索问题,而作为无结构化的图像数据,其存储、管理等依然是一个有待于解决的问题。自动图像标注是上述问题的可行解决方案。通过对图像标注文本词汇,很容易采用传统的关系数据库方式组织和管理图像数据。自1999年提出图像标注以来,自动图像标注已经逐渐成为图像检索、计算机视觉、机器学习等领域非常活跃的研究热点。
1 相关工作
1.1 标注算法分析
当前主流的图像标注方法主要有两种:概率模型方法、分类方法。
第一种方法是学习图像与关键词之间相关的概率模型,使用概率模型方法完成图像标注。概率模型的最早的方法是Mori于1999年提出的共生模型[2],此后,Duygulu 和Kobus于ECCV2002上提出翻译模型[3],Jeon于 ACM SIGIR2003提出著名的跨媒体相关模型(Cross-Media Relevance Model,CMRM)[4]。CMRM 是概率模型的代表性模型,它对后续的标注模型产生了很大的影响。诸如著名的Continuous Relevance Model(CRM)和Multiple Bernoulli Relevance Model(MBRM)等都可以认为是 CMRM 的后续模型[5-6]。
第二种方法把图像标注问题视为图像分类问题,每个概念或文本标注词可视为分类系统中的类标签。对每一个类,在训练阶段通过从有类别标签的训练图像集中学习并获得相应模型后,在测试阶段就可以为新图像(测试图像)生成类别标签,即完成测试图像的标注。代表性作品有Bayes,SVM,2D -HMM 等用于图像标注中[7]。
共生模型、翻译模型的标注效果较差(F1分别为2%和4%),CMRM以较低的代价取得了较好的效果(F1为9.47%)。CMRM的后续算法CRM、MBRM性能有了极大的提升(F1分别为17%,23%),但他们系统开销极大,很难用于大规模数据处理。分类方法最大的优点在于可以应用现有的成熟的机器学习模型,但其缺点是训练代价大,而且,由于分类数非常有限,很难用于几百、几千个概念的多类分类。
1.2 标注改善算法分析
Jin于2005年率先提出了标注改善方法[8],他提出了利用语义网(WordNet)来计算标注词之间的语义关系,以去除噪音标注词的标注改善算法。在图像标注改善中,包括Jin在内的几乎所有的基于语义网的标注改善方法,在计算概念的语义相似度时候,都简化了语义知识。并且,以WordNet为代表的语义网,仅仅给出概念之间是否相关的定性评判,不能给出概念的语义相似度的定量测量。围绕如何定量表示语义相似度,研究人员给出了很多尝试,但没有一种完美的方法,而且往往容易与人的理解相矛盾。另外,WordNet还存在词汇不可扩展性,若WordNet中不包含候选标注词的话,则无法使用。
由于基于语义网的标注改善算法关注的词汇之间的语义相近程度,而不是词汇相关性,标注改善没有取得预期效果。很多学者提出了利用训练集中图像标注词的共存性计算词汇相关性,标注改善性能有一定提升。但受到训练集中图像数量的限制,很多词汇之间的关联性无法通过训练集体现出来。
2 系统设计
2.1 系统架构
本文所提出的模型如图1,该系统由两部分组成。第一部分完成模型训练,即为图像集中所有关键词构造标志性特征向量。训练集中所有图像均实现标注词的人工标注。训练集中所有图像栅格化为固定大小的图块(patch),根据特征选择和表示算法提取每个图块的视觉特征。通过聚类算法使得相似的图块聚成一类,每一聚类称为一个可视词汇(visual word),并由该可视词汇代表该聚类内的所有图块的视觉特征。这样就实现了图块特征从连续向量到离散向量的转变。借鉴文本检索模型中的bag-of-model,每幅图像就可以视为一组可视词汇的集合。统计图像中可视词汇的分布,并使用直方图方式表示,每幅图像可以表示为可视词汇的直方图(Histogram of Word,HOW)向量。由图像的HOW向量可以构造出每个标注关键词的HOW向量,即标志向量。
第二部分标注工作。对于一副无标注词汇的测试图像,首先,生成其可视词汇直方图向量,方法同训练阶段。然后,通过计算HOW向量得出测试图像与关键词的相似度。取相似度最大的前若干个词汇,即为该测试图像的标注词汇。
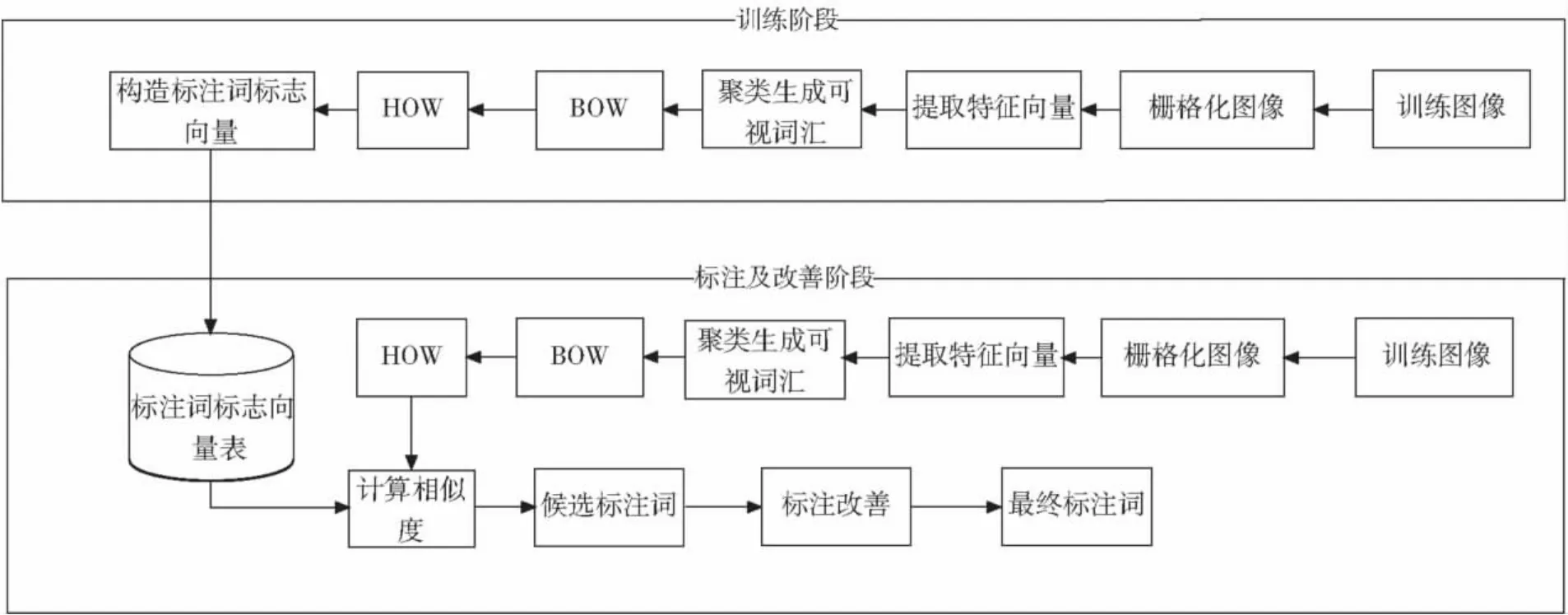
图1 系统体系结构
2.2 特征提取
由于基于区域的特征表示质量过于依赖于图像分割质量,而即使当前最优秀的图像分割算法也无法取得令人满意的分割效果[9]。基于栅格化的性能往往优于基于区域的方法。而且,考虑到图像分割的时间开销较大,本文采用栅格化方法。提取栅格化图块的视觉特征,包括12维的颜色信息(RGB和Lab共6个通道的均值和方差)和128维的SIFT纹理信息,使用K-means算法分别对颜色和纹理聚类成500和1000类。每幅图像最终可以表示为1500维的HOW向量。
2.3 加权正反例标志向量法
针对传统相关模型等存在的不足,我们提出了一种非常简单的标注模型,它无需复杂的训练过程和参数学习。该方法根据每个概念(标注词)所对应的正例图像与反例图像,为每个概念构造视觉特征向量,通过图像向量与概念向量的相似度来确定该概念U与图像的相关性或隶属度,称为正反例标志向量法[10],其基本思想是通过正例与反例图像特征向量的差异来构造代表该词汇的视觉向量,即表示词汇w的正例向量均值表示词汇w的反例向量均值,该算法详细步骤见参考文献[10]。在该算法基础之上,本文提出了加权的正反例标志向量法,其词汇视觉向量为
2.4 基于NGD的标注词改善
鉴于WordNet等方法标注改善存在的不足,我们采用归一化Google距离(NGD)方法作为词汇相关性的定量度量。NGD把任何两个词汇的相关性问题转化两个词汇在Web页面中共存的概率关系[11]。NGD计算方法为

其中,w1和w2分别代表两个文本词汇。f(w1)和f(w2)分别代表Google搜索引擎分别检索出包含查询词w1和w2词汇的网页个数,而f(w1,w2)代表检索出同时包含w1和w2两个词汇的网页个数。M是Google搜索引擎所涵盖的网页的总个数。仅从NGD的定义可知,它侧重的是词汇在上下文的相关性,而基于WordNet的方法关注的是概念的语义。另外,标注改善关注的应该是词汇之间的相容性,而不是同义词。因此,NGD是一种更适合于标注改善的词汇相关性度量方法。通过调用Google提供的接口,可以计算出包含任何词汇的网页个数。
由于每个词汇对应网页数量在一段时期内相对稳定,词汇对应网页的数量及NGD(w1,w2)可以事先保存起来,此后,周期性更新即可。在后续的标注改善过程中,可以直接访问NGD(w1,w2)信息,而无需在每次标注图像时调用Google接口。
3 实验与结果
3.1 实验设计
为了评价所提出的模型,我们与主流的标注算法进行对比。性能指标包括查准率、查全率、N+,以及算法复杂度和时间开销等,为公平起见,所有模型实验都在相同的图像数据集上完成。
Corel5K数据集已经成为图像检索和标注领域最常用的标准数据集,该数据集包括5000幅图像、371个标注词汇,平均每幅图像包含词汇个数为3.5个。与原始CMRM/CRM/MBRM算法数据划分一样,我们取4500幅图像作训练集,500图像作测试集,其中训练集与测试集中相交词汇260个。在CMRM/CRM等基于区域方法中,采用N-cut图像分割算法,且每幅图像分割为1-10个区域。栅格化方法中,每幅图像被等分为16*16像素的栅格。
3.2 实验评价指标
采用查准率(Precison)、查全率(Recall)、F1和N+作为标注质量评价指标。N+为查全率不为0的词汇个数。其他指标定义为


其中,r代表算法正确标注的词汇个数,n代表人工标注的实际个数,w代表算法错误标注出的词汇个数。
3.3 实验结果与分析
实验平台为HP笔记本,硬件配置为2.2GHz的Intel Duo CPU,3.0G内存,操作系统为Windows XP,软件环境为Matlab7.1以及NGD API包。与CMRM、MBRM等算法一样,标注算法为每幅图像生成5个标注词汇。本文所实现系统的标注效果与真实(手工)标注结果的对比见表1。本文方法与经典的标注模型性能对比见表2。

表1 标注结果对比

表2 算法性能对比表
表2中,视觉特征列中,C代表颜色,T代表纹理,S代表形状。算法复杂度列中,|W|代表数据集中词汇的个数,|D|代表训练图像个数,N代表图像分割后区域的个数,M是图像区域特征向量的维数。系统中数据集大时候,|D|会非常大,因此CRM和MBRM的时间开销会非常大;而即便系统的图像数据集再大,词汇个数|W|也非常有限;只要特征选择方法确定后,特征向量维数M是常量,与数据集大小无关。因此,越是训练集大的系统,本文方法优势越明显。本文所采用的加权正反例方法最优参数α、β分别是0.98和0.79。
通过调用Google接口获取网页数量的时间开销很大程度上取决于网络状况,且无需每次都调用Google接口,因此,表2中算法复杂度和平均耗时没有包括NGD的时间开销。
4 结语
针对当前图像标注模型存在的不足,本文设计了一种非常高效的标注模型,通过NGD方法对图像候选标注词进行标注改善,有效地保证了标注系统的总体质量。该系统既可以作为一个独立标注系统运行,也可以作为复杂系统的相关模块。
[1] RITENDRA DATTA,DHIRAJ JOSHI,JIA LI ,et al.Image Retrieval:Ideas,Influences,and Trends of the New Age[J].ACM Computing Surveys,2008,40,(2):1-60.
[2]MORI Y,TAKAHASHI H,OKA R.Image-to-word transformation based on dividing and vector quantizing images with words[C]∥ In MISRM'99 First International Workshop on Multimedia Intelligent Storage and Retrieval Management,1999.
[3]DUYGULU P,BARNARD K,DE FREITAS N,et al.Object recognition as machine translation:Learning a lexicon for a fixed image vocabulary[J].Proc.of Seventh European Conference on Computer Vision,2002:97 -112.
[4]JEON J,LAVRENKO V,MANMATHA R.Automatic Image Annotation and Retrieval using Cross-Media Relevance Models,Proc.of the 26th annual international ACM SIGIR conference on Research and development in information retrieval,2003:119 -126.
[5]LAVRENKO V ,MANMATHA R,JEON J.‘A model for learning the semantics of pictures’[C]∥Advances in Neural Information Processing Systems,2003.
[6]FENG S L,MANMATHA R,LAVRENKO V.‘Multiple Bernoulli Relevance Models for Image and Video Annotation’[C]∥IEEE Conf.Computer Vision and Pattern Recognition,2004.
[7]CHIH -FONG TSAI1,CHIHLI HUNG.Automatically Annotating Images with Keywords:A Review of Image Annotation Systems,Recent Patents on Computer Science,2008,1(1):55 -68.
[8]JIN Y,KHAN L,WANG L,et al.Image annotations by combining multiple evidence & wordNet[J].In Proceedings of ACM Multimedia,706-715,2005
[9]SHI J,MALIK J.Normalized cuts and image segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence,22(8):888–905,2000.
[10]SONG Haiyu,LI Xiongfei,BAO Cuizhu,et al.An Efficient and Effective Automatic Image Annotation using Positive and Negative Example Images,ICIC -EL,2011,5(8):2927-2932.
[11]CILIBRASI R,VITANYI P.The Google similarity distance.IEEE Transactions on Knowledge and Data Engineering 19(3),370–383,2007.
An Image Annotation and Refinement Model Based on Visual Content and Semantic Correlation
SONG Hai- yu1,2,LI Xiong - fei2,BAO Cui- zhu1,JIN Xin1,YUE Qing - yu1
(1.College of Computer Science and Engineering,Dalian Nationalities University,Dalian Liaoning 116605,China;
2.College of Computer and Technology,Jilin University,Changchun Jilin 130012,China)
The efficiency and qulaity of image annotation system determine the ability to manage images in the fields of computer vision and image retrieval.To overcome the drawback of current annotation system,an efficient annotation system is designed,including annotation and refinement stages by weighted positive and negative symbol vector method and NGD method respectively.The experiments demonstrate our proposed system perfomance,whose efficiency outperforms classicial image annotation models and qulity outperforms most current image annotation models.
image annotation;annotation refinement;normalized Google distance
TP391
A
1009-315X(2012)01-0067-05
2011-11-07;最后
2011-11-23
中央高校基本科研业务费专项资金项目(DC10040111);辽宁省教育科学“十二五”规划立项课题“应用型院校中本科生研究性学习模式的研究与实践”(JG11DB062)。
宋海玉(1971-),男,河南安阳人,副教授,主要从事图像分析与理解、计算机视觉、信息检索研究。
(责任编辑 刘敏)
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小学生学习指导(低年级)(2021年9期)2021-10-14
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
开放教育研究(2020年2期)2020-03-31
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
小学生学习指导(低年级)(2018年9期)2018-09-26
现代语文(2016年21期)2016-05-25
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
