
基于最大相似类别和位置熵的三维模型融合检索方法
2013-03-16 07:06陈俊英孟月波王羡慧刘四妹西安建筑科技大学信息与控制工程学院陕西西安70055
图学学报 2013年5期
陈俊英, 孟月波, 王羡慧, 刘四妹(. 西安建筑科技大学信息与控制工程学院,陕西 西安 70055;
2. 新疆大学信息科学与工程学院,新疆 乌鲁木齐 830046;
3. 中国联通网络通信公司西安分公司,陕西 西安710043)
基于最大相似类别和位置熵的三维模型融合检索方法
陈俊英1, 孟月波1, 王羡慧2, 刘四妹3(1. 西安建筑科技大学信息与控制工程学院,陕西 西安 710055;
2. 新疆大学信息科学与工程学院,新疆 乌鲁木齐 830046;
3. 中国联通网络通信公司西安分公司,陕西 西安710043)
为了有效利用各特征集对三维模型内容的描述信息,对各种特征集上分别检索的结果进行综合分析,统计各类模型的分布概率得到查询模型的最大相似类别,然后在各个检索结果中统计该类别模型的位置熵,基于最大相似类别模型数目和位置熵计算融合权值。在普林斯顿标准3D模型集上进行实验,并和其他几种动态融合方法和静态方法进行比较,结果说明所提出的方法在有弱特征集存在的情况下是有效的。
3D模型检索;多特征;动态融合
随着3D模型的普及应用,从现有模型资源中进行检索是势在必行的事情,基于内容的 3D模型检索已得到产业界与学术界越来越多的重视。在基于内容的3D模型检索过程中,首先需要寻找合适的特征描述算法。迄今为止,已有几十种特征描述算法被相继提出,但没有一种通用的特征描述方法能针对任意的模型都能取得最佳的检索效果。并且文献[1]的研究结果表明:特征提取方法在描述能力方面存在极限,这一极限不能通过提高形状特征的细致程度加以突破。
为提高检索性能,研究人员一方面在继续寻找高效的特征提取方法,如矩描述[2]方法等;另一方面在现有的特征提取方法基础上借助于机器学习领域的方法进行进一步处理,包括特征选择、多种特征融合、对特征进行分类和聚类分析等,寻找有效的多特征融合方法是目前研究的热点问题之一[3]。文献[4]应用静态权值的方法进行融合,这种方法需先给定权值等级(如0,1,2,3)。在检索时,针对任何查询模型都使用同一参数组合。文献[5]中分别计算各个特征集上的熵不纯度(entropy impurity),然后基于熵不纯度计算融合权值。文献[6]中分别统计各个特征集上检索列表的前 k(k是设定的参数)项同类模型最多的数目,得到各个特征集对应的纯度(purity),然后利用纯度计算融合权值。Leng等人[7]提出基于先验知识的检索方法,对一个特定的特征集,先统计检索列表前k项中同类模型最多的类别,然后计算该类别模型在列表中的累加增益,通过累加增益得到该特征集的融合权值。这3个算法中熵杂度、纯度和先验知识的获得主要依赖于各个检索列表中排序前几位的模型类别和各类别模型的数目,没有利用各个特征集上的综合检索结果指导权值计算,这对在单特征集上检索性能都较好的情况下是有效的,如果融合中存在弱特征集,排序前几位的模型类别和同类模型数目可能给出误导信息,导致计算出的融合权值不适合,从而导致检索性能变差。
针对融合中有弱特征集存在的问题,提出基于最大相似类别和位置熵的多特征动态融合检索方法,该方法从各特征集的综合检索结果出发,避免了从各个特征集自身出发计算相应参数的片面性。下面首先介绍多特征动态融合的检索方法,然后通过实验验证了该方法的有效性。
1 多特征动态融合算法
对一个查询模型,先把各个特征集上检索列表的前k项综合考虑,统计同类模型数,将具有最多模型数目的类别作为查询模型的最大相似类别,然后在各个检索列表中统计该类别模型的数目和位置熵,两者的乘积作为融合权值。最后基于融合权值计算模型之间的相似度,从而实现3D模型的检索。
1.1 判断查询模型的最大相似类别
用Σ表示3D模型集合,其中已分类模型用C表示,未分类模型用U每个类的模型集合用表示,则有
应用l种特征提取方法,3D模型库转化为相对应的 l个特征空间上的特征集,表示为。给定一个查询模型、一个常数k,在第j个特征集 Fj上计算C内模型与查询模型之间的相似度,生成一个相似度由大到小的结果排序列表,记为,记为中前k个模型组成的集合。
综合各个特征集上检索列表的前k项,得到模型集合 Rqk, Rqk计算式如下:

Rqk 中第 i类模型集合记为 Sqki,计算式如下:

模型 q的最大相似类别定义为 Rqk中模型数最多的类别,判定用公式如下:

1.2 计算最大相似类别模型的位置熵
在确定查询模型q的类别 Class( q, k)后,统计各个特征集对应的检索列表前 k项中类别为Class( q, k)的模型在列表中的位置,第j个特征集对应的检索列表前k项中类别为 Class( q, k)的模型序号表示为。表示对应于序号的模型,表示这一模型的类别。则在第j个特征集上最大相似类别模型的位置熵可以表示为下式:
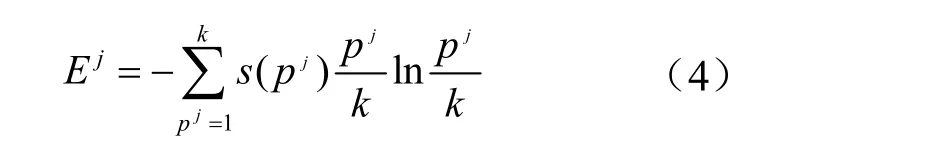
其中:

1.3 计算融合权值
统计各个特征集对应的检索列表前k项中类别为 Class( q, k)的模型的个数,将第j个特征检索列表中类别为 Class( q, k)的模型的个数表示为。针对查询模型q,常数k,第j个特征集上的融合权值记为,考虑到 Class( q, k)模型数越大对应的权值应该越大,而位置熵越小对应的权值应该越大,计算式如下:

模型个数减1是为了除去检索结果中与检索模型相同的那个模型。如遇到(nj-1)都为0时,假定各特征集对融合所起的作用一样,各融合权值都设为1。
1.4 计算模型之间的相似度令 dj表示应用特征集时的距离函数,表示应用时查询模型q和模型库中模型的最大距离,则融合后查询模型q和模型库中的模型o之间的相似性距离定义式如下:

2 特征提取算法
实验中用体素化球面调和函数方法、基于形状分布的方法[8]和基于二维视图的方法提取三维模型的特征。下面简单介绍一下这3种特征提取方法的实现。
基于体素化球面调和函数(voxelization Spherical harmonics,简称为 VSH)的特征提取方法首先计算出以三维模型重心为球心的最小包围球,假设半径为,按照该球半径的1 N为单位,将这个模型投射到2 N× 2 N× 2N个网格中,该网格重心放置和三维模型的重心重合。每个格子的数值非0即1,如果任何一个格子内部存在着三维模型表面上的点,那么该格子的数值设为 1,反之,该格子的数值设为 0。之后将网格限制在一系列半径为的球壳上,每个球壳对应一个二值化的球坐标方程。将每个方程展开形成球面调和函数的和,组合系数就形成一组具有旋转不变性质的特征向量。
基于形状分布(Shape Distribution,简称SD)的特征提取算法,其基本思想是统计模型表面上点分布的统计特征。多次随机采样三维模型表面上的点对,计算两点间的距离,而后根据距离等分成多个区间,统计位于各个距离区间的两点间距离的个数,得到统计直方图,经过归一化等变换得到特征描述向量。
基于二维视图(简称 SIL)的特征提取方法[9]通过 CPCA方法计算三维模型的正交坐标系;沿着3个正交坐标轴方向得到三维模型的3个二维投影视图;对二维投影图像采用傅里叶变换方法提取特征,然后组合3个特征向量形成三维模型的特征描述。
3 实验与分析
3.1 实验数据
实验采用研究人员使用最为广泛的普林斯顿形状基准数据库PSB[9]。该数据库共包含1814个模型,分训练集TR和测试集TS,各包括907个模型,训练集用来计算融合权值。在实验中,使用VSH方法提取的256维特征集、SD方法提取的64维特征集和SIL方法提取的300维特征集。
3.2 性能评价准则
实验结果用查准率-查全率曲线、平均查准率、前 50%查全率上的平均查准率、BEP、R-Precision、和最近邻检索精度来评价检索性能[10]。其中查准率-查全率曲线比较全面地描述了检索性能,是较重要的一种性能评价标准。其他每种指标各有侧重点,一种指标评价算法某一方面的优劣,如最近邻检索精度表示当返回检索结果数为1时的正确率;R-Precision表示返回模型数为( ni表示与查询模型相关的模型数)时的查准率;BEP表示返回模型数为时的查全率;平均查准率是各种返回模型数上的查准率的平均值,计算时取查全率为0.1,0.2,…,1时的查准率的平均值;前50%查全率上的平均查准率表示前 50%中各个返回模型数上的查准率的平均值,即取查全率为0.1,0.2,…0.5时的查准率的平均值。因为目前还没有一种通用的评价指标能完全表明检索性能的好坏,本文使用多种指标是为了全面地评价检索性能。
3.3 实验结果
3.3.1 k参数的取值
首先对不同k值对检索性能的影响进行了实验,图1给出了不同k值对应的平均查准率。如图1所示,k从1取到5过程中,平均查准率逐渐递增,k=5时取得了最好的平均查准率,随后k值在[6-15]之间平均查准率变化不大,这说明了该算法对k参数变化具有较强的鲁棒性。在后续的实验中选取k=5。

图1 不同k值下的平均查准率
3.3.2 融合实验
为了和其他融合方法进行比较,我们还实现了基于纯度的方法[6]、基于熵不纯度的方法[5]、基于先验知识的方法[7]和静态权值方法[4]。基于静态权值的方法中,设定权值等级为0,1,2,3等4个等级,在训练集上找到最优的权值参数组合为(3,1,0),给出的性能是在这一参数组合下PSB中所有模型的平均检索性能。图2给出了各种融合方法在 SIL[300]+VSH[256]+SD[64]组合上的检索结果和各单特征集对应的检索结果。图注中按顺序给出的值分别为:前 50%平均查准率,平均查准率,BEP,R-Precision指标和最近邻检索精度。
如图2所示,SD特征集检索性能较差,为弱特征集,VSH特征集比SD特征集检索性能好一些。融合方法的查准率-查全率曲线和5个性能评价指标都远远好于SD特征集和VSH特征集上的相应指标值,所以本文方法避免了在检索过程中选择最差特征集进行检索导致的风险问题。

图2 各种融合方法在SIL[300]+VSH[256]+SD[64]组合上的检索结果和各单特征集对应的检索结果
本文方法在查全率小于 0.6时的查准率-查全率曲线在SIL方法的曲线上方,仅在查全率大于0.6时,SIL方法的查准率-查全率曲线略位于上方。和最好单特征集相比,本文提出的方法将前 50%的平均查准率提高 6.7%,平均查准率提高3.3%,BEP提高0.7%,R-Precision指标值提高4.6%,最近邻检索精度提高9.5%。考虑到用户重点关注的是位于检索列表前面的模型,也就是说在查全率大到一定程度后的查准率对用户来说已经没有太大意义了。综合起来考虑,本文方法优于SIL方法。
基于纯度、基于熵不纯度和基于先验知识的3种方法仅在最近邻检索精度上略优于最好特征集SIL,在其他4个指标上都差一些。这是因为这几种方法都是基于单个特征集检索结果计算相应的融合权值,而在多特征集中SD特征集检索性能较差,单依靠特征集本身可能会使得计算出来的融合权值给出错误的信息,从而导致检索性能下降。本文方法的查准率-查全率曲线位于基于纯度的、基于熵不纯度的和基于先验知识3种方法对应的查准率-查全率曲线上方,并且在题注中给出的5种性能评价指标上也略优一些。说明本文方法在有弱特征集存在的情况下优于其他3种动态融合方法。
基于静态权值的方法的查准率-查全率曲线在查全率大于0.6以后的查准率-查全率曲线在本文方法的曲线上方,但在查全率小于0.6时,本文方法的查准率-查全率曲线位于上方。从5个性能评价指标上看本文方法好于基于静态权值的方法。
静态权值方法在前 4个性能指标上优于其他3种动态融合方法,在最近邻检索精度这个指标上比基于纯度方法和基于先验知识的方法略差一些。静态权值方法之所以取得和动态融合检索相似甚至更好的检索性能,是因为基于静态权值的方法通过对弱特征集SD的权值赋值0,较弱的特征集 VSH的权值赋值 1,最好的特征集SIL的权值赋值3,既保持了SIL特征集在检索过程中的主导地位,又利用VSH特征集对其进行了补充,从而取得了在5个性能指标上比最好单特征集SIL都要好的结果。
本文提出的多特征融合检索方法从各个特征集上检索结果的综合情况考虑查询模型的最大相似类别,避免了仅从单个特征集考虑造成的片面性。如果某一种特征集针对查询模型q的检索性能太差的话,则在计算权值时可能因为列表前k项中不含与q同类的模型,从而使得计算的权值为0,即回避掉弱特征集。如果某一种特征集针对查询模型q的检索列表前k项中包含与q同类的模型的数目较少或位置较靠后,都会使计算的权值较小,从而只起到对其他特征集的补充作用。某一种特征集针对查询模型q的检索列表前k项中包含与q同类的模型的数目越多、位置越靠前,对应的权值越大,对融合结果起的作用越大。本文方法就是通过这种针对查询模型动态计算融合权值的方法,取得了较好的检索效果。
4 结 论
本文提出的多特征动态融合检索算法能够针对查询模型自动计算融合权值,计算时利用最优单特征集对模型类别判断的主导作用,避免了单独依靠特征集自身进行模型类别判断的片面性。实验结果表明在有弱特征集存在的情况下,本文算法避免了检索过程中选择最差特征集进行检索导致的风险问题,并在一定程度上有效提高了检索效果。
[1] 吕天阳. 三维模型检索中基于聚类与基于语义方法的研究[D]. 长春: 吉林大学, 2007.
[2] 刘玉杰, 李宗民, 李 华. 三维 U系统矩与三维模型检索[J]. 计算机辅助设计与图形学学报, 2006, 18(8): 1111-1116.
[3] Shih J L, Chen H Y. A 3D model trtrieval approach using the interior and exterior 3D shape information [J]. Multimedia tools and Application, 2009, 43(1): 45-62.
[4] Akbar S, Josef Kung , Wagner R. Multi-feature integration on 3D model similarity retrieval [C]//2006 1st International Conference on Digital Information Management. Bangalore, 2006: 151-156.
[5] Bustos B, Keim D, Saupe D, et al. Using entropy impurity for improved 3D object similarity search [C]// IEEE International Conference on Multimedia and Expo (ICME'04), 2004: 1303-1306.
[6] Bustos B, Keim D, Saupe D, et al. Automatic selection and combination of descriptors for effective 3D similarity search [C]//Proceedings of the IEEE Sixth International Symposium on Multimedia Software Engineering (ISMSE'04), 2004: 514-521.
[7] Leng Biao, Zheng Qin. Automatic combination of feature descriptors for Effective 3D shape retrieval[C]//ProceedingsinComputerVision/Compu-te r Graphics Collaboration Techniques. Rocquencourt, France, 2007.
[8] Robert Osada, Tom Funkhouser, Bernard Chazelle, et al. Matching 3D models with shape distributions [C]// International Conference on Shape Modeling and Applications, 2001.
[9] Philip Shilane, Patrick Min, Michael Kazhdan, et al. The princeton shape benchmark [C]//Shape Modeling International. Genova, Italy, 2004.
[10] Vranic D V. 3D model retrieval [D]. University of Leipzig. Germany, 2004.
3D Model Retrieval Based on Maximum Similar Category and Location Entropy
Chen Junying1, Meng Yuebo1, Wang Xianhui2, Liu Simei3
( 1. School of Information and Control Engineering, Xi'an University of Architecture and Technology, Xi'an shaanxi 710055, China; 2. School of Information Science and Engineering, Xinjiang University, Urumqi Xinjiang 830046, China; 3. China Unicom Xi'an Branch, Xi'an shaanxi 710043, China )
For using descriptive information of individual feature of 3D models effectively, the maximum similar category of the query model is determined by comprehensively analyzing the distribution of models in retrieved results based on various features. Then the location entropy of the same class models of individual feature is calculated respectively. Finally, combination weights are computed dynamically based on the number of models of the maximum similar category and location entropy. Compared with other dynamic and static combination methods on Princeton 3D benchmark models, the results show the proposed method is effective in the case of weak features included.
3D model retrieval; multi-features; dynamic combination
TP 391.3
A
2095-302X (2013)05-0051-05
2012-10-18;定稿日期:2012-12-14
陕西省自然科学基础研究计划资助项目(2012JQ8039)陕西省教育厅科研计划资助项目(11JK1036)西安建筑科技大学青年基金资助项目(DA05037)
陈俊英(1980-),女,内蒙古丰镇人,讲师,博士,主要研究方向为模式识别、三维模型检索等。E-mail:vcjy@163.com
猜你喜欢
四川大学学报(自然科学版)(2021年6期)2021-12-27
唐山师范学院学报(2018年6期)2018-12-25
现代电子技术(2018年20期)2018-10-24
现代电子技术(2018年16期)2018-08-21
现代情报(2018年11期)2018-01-07
现代电子技术(2017年23期)2017-12-20
计算机应用(2016年10期)2017-05-12
文苑(2015年9期)2015-09-10
新课程学习·中(2013年3期)2013-06-14
中国管理信息化(2009年10期)2009-06-19
