
河网数据渐进式传输的自适应可视化研究
2013-04-07 07:46石传奎闫浩文程耀东
测绘通报 2013年1期
杨 军,石传奎,闫浩文,程耀东
(1.兰州交通大学研究生学院,甘肃兰州 730070;2.江苏省镇江市规划局规划科技信息中心,江苏镇江 212004;3.兰州交通大学数理与软件工程学院,甘肃兰州 730070)
一、引 言
渐进式传输可以有效地解决当前有限的网络带宽和无限增长的空间数据之间的突出矛盾,同时还可以满足用户自适应的空间信息阅读和应用需求。河系是重要的地理要素之一,必然成为渐进式传输中不可回避的要素。河网渐进式传输中自适应可视化是指在小比例尺下显示较少重要的河流,大比例尺下显示较多河流,用户可以通过调节比例尺来控制河流的显示数量,从而满足其不同的需求。同时,河流的显示过程是由少到多、由主流到支流的渐变过程,这样不仅缩短了客户端用户的等待时间,也符合人们由整体到局部的空间认知规律。
目前基于河网的渐进式传输的研究还很少,但基于河网综合方面的研究成果却很丰富。Rosso等人研究了河网的自相似性与分形特征,并推导出了适合地图综合层次化分析需要的河网分维估值公式[1];Richardson等人提出了基于Horton码和长度的河流结构选取的方法[2];何宗宜总结了用于确定河流选取指标的一元回归模型、多元回归模型、开方根规律模型[3],这些模型常被用于河流资格(河长)或定额(数量)的选取;武芳等人研究了河网自动综合中空间知识、属性知识及综合规则的策略和形式化表达方法,通过河网知识和综合中各条规则的优先级和权重实现了河流选取[4],该方法在保持河网整体结构特征方面有较好的效果,但在保持河网密度差异和图形相似性方面还不是很理想;艾廷华等人运用Delaunay三角网模型建立了各级河流分支汇水区域的层次化剖分模型,并基于该层次剖分模型计算了河流分布密度、相邻河流间距、汇水范围及层次关系,进而推算出河网中每一条河流的重要性系数,实现了不同尺度下河流的综合选取[5],该方法较好地保持了河网的主体形态结构,兼顾考虑了选取河流的级别、长度、河流间距,但由于缺乏河网区域总体特征的考虑,使得河流分布疏密的对比没有得到保持;张青年等人在构建河系树的基础上,结合上下文环境,提出了基于层次分解和各个层次上不同子流域之间选取数量比例分配的河系简化方法[6],简便而有效地保持了河网的密度差异。渐进式传输是制图综合的逆过程,关于河网综合的研究为河网渐进式传输奠定了理论基础。
从已有的研究成果可以看出,河系结构化组织有利于河流实体的整体选取与操作。因此,本文在构建河系树的基础上,运用河流层次、等级、数量密度和长度等因子对河系进行了详细的描述,遵循保持河网自适应可视化前后河流密度差异与结构特征的规则,提出了将某一尺度下河流选取数量按河流数量密度逐级分摊到河系与河系内部各级子流域的方法;然后把所有选取的河流按其层次逐层输出显示,从而实现了渐进式传输中河网的自适应可视化;最后对该方法进行了试验分析,验证了该方法的有效性。
二、树状河系描述
在空间数据库中,河流通常是以河段为单元存储的,被表示为一个相互邻接的河段序列,只有在河段的基础上构建河流实体,才有利于河流选取。在河系树的自动构建过程中,可以获得河流的层次结构、等级、长度、左右支流等重要信息。本文将利用河流主支流结构、等级、河流数量密度和长度等来对河系进行描述。
树状河系结构是由一条主流和若干级支流组成的,即主流有一批支流,而各级支流又可能拥有一批次级支流。主流在河系中的重要性最大,在地图综合中被优先选取。事实上,在手工地图综合中,河系简化也是在选取主流的基础上逐级增加各级支流实现的。本文基于这种主流优先选取的原则,对河系中的各级河流进行了层次划分,定义主流的层次为1,由主流到支流再到次级支流的层次值逐级增1。标记后的河系层次如图1所示。
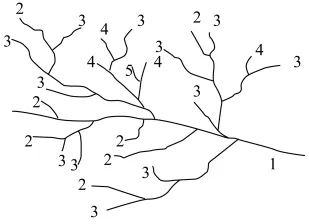
图1 河流层次描述
另外,河流的各级支流数量越多,河流的重要性就越高,因此,河流各级支流数量具有反映河流等级差别的意义。文献[7]定义了如下河流等级规则:河流等级=该河流的各级支流的数量+1,即该河流自身和各级支流数量的总和,各级支流数量不仅仅局限于该河流的下一级支流。基于该等级规则得到的河流等级如图2所示。
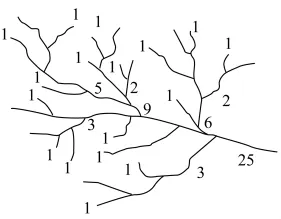
图2 河流等级描述
流域内河流数量在一定程度上反映了该流域内河网密度情况。在主流长度一定的情况下,子流域的河流总数越大,则河网密度越大,反之则密度较小。因此,在渐进式传输过程中,通过保持各个河系中河流数量与河流总量的对比关系,就能保持不同河系之间的河流密度差异;类似地,保持同一河系内各个子流域河流数量与该河系河流总量的对比关系,就能保持该河系内部子流域的河流密度差异。本文将以上对比关系定义为河流数量密度,其计算公式为

在计算河网中各个河系的河流数量密度时,式中,m为某一河系的主流等级(即该河系的河流数量);M为河网中河流总数量;D为该河系的河流数量密度值,该值被赋在该河系的主流(即层次为1的河流)上。在计算某一河系子流域的河流数量密度时,式中,m为该子流域的主流等级(即该子流域的河流数量);M为该子流域上一级流域的主流等级(即该子流域上一级流域的河流总数量);D为该子流域的河流数量密度值,该值被赋在该子流域的主流上。依此方法计算图 2的河流数量密度,结果如图3所示。

图3 河流数量密度描述
河流长度也是河流选取时需要考虑的一个重要指标,以河流长度为分界尺度选取河流是河网综合的基本方法。如大于指定长度的河流被选取,低于这一指标的则被舍弃。河系树上相同层次的河流,长度大的应该被优先选取。然而,河流长度不能全面衡量河流的重要性,长度相似的两条河流在不同的地理环境中,其重要性可能相差甚远。
三、渐进式传输中河网自适应可视化
要实现空间数据渐进式传输的自适应可视化,关键是建立不同分辨率下空间数据与尺度之间的映射关系[8-10]。实现河网的自适应可视化需要解决以下3个问题:一是在某一尺度下,应该从河网地图数据中选取多少条河流进行显示;二是应该选取哪些河流显示才能准确反映该尺度下河流的分布情况;三是如何控制河网渐进式传输中的传输顺序。
1.河流选取数量计算
开方根模型是通过建立方根数学模型来计算确定新比例尺地图上的河流条数的。方根模型的公式为

式中,S1为原始地图比例尺的分母;n1为原始地图比例尺下显示的河流数量;S2为新编地图比例尺的分母;n2为新编地图比例尺下显示的河流数量,其随着S2的变化而取不同的值;x为经验系数,通过地图综合样图的统计分析可以得到n1和n2,从而确定x。利用开方根模型对河流进行选取,基本可以反映出河网的类型特点及河网各部分的密度对比。
2.逐层分摊指标法
通过开方根模型,可以得到某一尺度下新编河网地图上应该选取显示的河流数量。本文分以下两个步骤把这些数量逐级分摊到河系的各个层次上:首先将选取数量分摊到各个河系中;其次将各个河系分摊的数量再分摊到各个子流域,并依次在子流域内部递归分摊选取数量。两个过程中兼顾分摊出去的数量等于选取数量。
(1)选取数量分摊到各个河系
将用户请求尺度下新编河网地图上河流选取总数量分摊到各个河系的计算公式如下

式中,n2为开方根模型计算出的用户请求尺度下河网地图上河流选取总数量;D1为某河系的河流数量密度;W1为该河系分摊到的河流数量,该值按四舍五入法处理为整数。
当W1=0时,用户请求尺度下,该河系的所有河流不具备显示资格;当W1=1时,该河系只有第1层的主流具有显示资格,此时停止继续向子流域分摊;当W1﹥1时,除主流外,子流域上的河流也有显示资格,此时应减去主流的数量,将剩余的选取数量再分摊到子流域。
按以上方法计算,支流少的小河系的分摊数量可能为0,如果存在大量这种情况,实际分摊的河流数量之和将小于应选取的河流数量;相反,实际分摊的河流数量之和也可能大于应选取的河流数量。此时,需要比较两者的大小,如果∑W1=n2,则不作处理;如果∑W1<n2,将W1=0的小河系按河系主流长度排序,把前n2-∑W1个小河系的分摊指标W1值标记为1;如果∑W1>n2,对分摊到指标的河系按指标大小排序,从大到小依次减1,直到∑W1=n2为止,并更改各河系的W1值。
(2)河系内部再分摊
河系内部子流域上的数量再分摊和河系间的分摊略有不同,需减1之后再分摊,公式如下
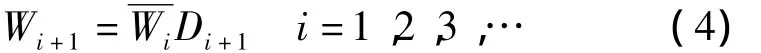
同样,当Wi+1=0时,该子流域内所有河流不具备显示资格;当Wi+1=1时,该子流域内只有其主流具有显示资格,此时停止继续向下分摊;当Wi+1>1时,除该子流域主流外,下一级子流域上的河流也有显示资格,此时应减去该子流域主流数量(值为1)后,再将剩余的选取数量递归分摊到下一级子流域。
前文中,笔者把河系和各级子流域的河流数量密度D赋给了其各自的主流,而河系和各级子流域的分摊数量W是根据河流数量密度D计算得到的,因此,河系和各级子流域分摊数量W就和每一条河流都建立了联系。又因为当河系或各级子流域分摊数量W值大于或等于1时,其主流是必选的。由此分析,分摊数量大于或等于1所对应的河流就是用户请求尺度下需要输出显示的河流。
3.河网渐进可视化顺序控制
渐进式传输中数据按照重要性次序输出,决定数据重要性的因素包括语义特征和空间尺度。发育很小的河系因为其特定的地理位置,重要性突出,与类似大小却没有语义特征上独特性的河流相比,将其归为重要的河流而被优先输出。另外,重要的、几何特征显著的信息才能在小比例尺地图上得以表达,因此,表达尺度也是地理目标重要与否的衡量标准。本文主要考虑河流尺度特征,按所选取河流的层次进行输出显示,即传输时逐级输出层次为1、层次为2、层次为3的河流等。河网中层次为1的河流数量较少,首先传输可在客户端快速地显示,给用户一个初步印象。同时,这种由主流到支流再到次级支流的显示过程符合人们由整体到局部、由简单到复杂的空间认知规律。
四、试验与分析
本文在Visual Studio.NET 2005环境下进行了试验。在河系树构建和描述的基础上,当客户端用户向服务器提出某一尺度的地图请求时,首先,服务器根据用户请求比例尺信息利用开方根模型计算出该尺度下应该输出显示的河流数量;然后,利用逐层分摊指标法将这些数量分摊到河网的各个层次上;最后,检索与分摊指标大于或等于1的河流,并按河流层次依次输出显示。部分试验结果如图4所示。

图4 河网渐进式传输过程中的自适应可视化
图4(1)是甘肃省南部1∶20万水系图的局部,共有56条河流;图4(2)是比例尺为1∶50万时河系的自适应可视化过程,式(2)中的指数x取2,共选取了22条河流。暂且不讨论河系间的密度差异,单从河系内部看,原图上河系子流域a、b、c的河流数量分别是14、9、6,在新编图上,此3个子流域显示的河流数量分别为5、3、2。可见,本文的方法较好地保持了可视化前后河流数量的对比关系。而河流数量对比关系又反映了河系内部河流的密度差异。从图4(2)河流自适应可视化的过程来看,第1步首先显示1条主流,第2步增加了10条支流,第3步增加了11条次级支流,数据传输渐变粒度划分均匀,层次显示顺序合理,较好地展现了河系的结构特征。
五、结束语
某一尺度下的河流选取是渐进式传输中河网自适应可视化的关键,需要兼顾河网可视化前后的密度差异与结构特征。本文在构建河系树的基础上,结合河流层次、等级、数量密度和长度等河流描述因子,提出了将河流选取数量按河流数量密度逐级分摊到河系与河系内部各级子流域的方法,并把选取的河流按其层次逐层输出可视化。该方法在试验中取得了较好的效果,但笔者也发现位于河系树底层的部分河流的选取难以控制,河系局部树状结构不明显的地方选取不尽合理,如图4(1)中标记部分,局部密度大却选取了较少的河流显示,这说明依据河流长度补选河流存在不足之处,需要进一步考虑其他因子对其加以控制。此外,河网渐进式传输的自适应可视化效率还有待进一步提高。这些问题都是河网渐进式传输可视化需要继续研究的内容。
[1] ROSSO R,BACCHI B,LA BARBERA P.Fractal Relation of Mainstream Length to Catchment Area in River Networks[J].Water Resources Research,1991,27(3):381-387.
[2] RICHARDSON D E.Automatic Spatial and Thematic Generalization Using a Context Transformation Model[D].Holland:Wageningen Agricultural University,1993.
[3] 何宗宜.地图数据处理模型的原理与方法[M].武汉:武汉大学出版社,2004.
[4] 武芳,谭笑,翟仁健,等.基于知识表达和推理的河网自动选取[J].辽宁工程技术大学学报:自然科学版,2007,26(2):183-186.
[5] 艾廷华,刘耀林,黄亚锋.河网汇水区域的层次化剖分与地图综合[J].测绘学报,2007,36(2):231-236,243.
[6] 张青年.逐层分解选取指标的河系简化方法[J].地理研究,2007,26(2):222-228.
[7] 张青年.顾及密度差异的河系简化[J].测绘学报,2006,35(2):191-196.
[8] 杨必胜,李必军.空间数据网络渐进传输的概念、关键技术与研究进展[J].中国图象图形学报,2009,14(6):1018-1023.
[9] 艾廷华,成建国.对空间数据多尺度表达有关问题的思考[J].武汉大学学报:信息科学版,2005,30(5):377-382.
[10] 艾廷华.网络地图渐进式传输中的粒度控制与顺序控制[J].中国图象图形学报,2009,14(6):999-1006.
猜你喜欢
中国房地产业(2022年33期)2022-02-14
黑龙江水利科技(2020年8期)2021-01-21
——以莲花县为例
江西水利科技(2020年2期)2020-05-22
创造(2020年12期)2020-03-17
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
光学精密工程(2016年6期)2016-11-07
通信电源技术(2016年4期)2016-04-04
Coco薇(2016年1期)2016-01-11
浙江理工大学学报(自然科学版)(2015年2期)2015-03-01
卫生职业教育(2014年24期)2014-05-20
