
维吾尔语音情感声学特征提取与建模研究*
2013-09-17 12:31阿依提拉米吉提艾斯卡尔肉孜艾斯卡尔艾木都拉
通信技术 2013年11期
阿依提拉·米吉提,艾斯卡尔·肉孜,艾斯卡尔·艾木都拉
(1.新疆大学信息科学与工程学院,新疆乌鲁木齐830046;2.新疆大学数学与系统科学学院,新疆乌鲁木齐830046)
0 引言
语音是最理想的人机交互方式之一,而语音合成技术则是实现语音人机交互的基础。情感语音合成作为一个新的研究方向正受到众多研究者的越来越的关注。从语音信号中提取情感特征,判断说话人的喜怒哀乐,是一个新兴的研究领域[1]。研究情感语音合成的目的是要使合成语音听起来更自然,更有表现力和人情味[2]。
语音的情感信息研究因为不同语种之间的各种差别,研究进展也不尽相同。英语,日语,德语等语种的语音情感处理都有了较丰富的研究。在美国,80年代初就有M1T的Cahn写出了一个用来描述发音的计算机程序来合成有50%的识别率的六种语音情感。在欧洲,启动了 PHYSTA(Principled Hybrid Systems and Their Application)项目,用于开发一个能从面部和语音来识别情感的系统。在日本,ATR实验室对人类语音交流中的情感等非音段信息进行深入分析,并录制和标注了大量的语音数据。最近几年来,国内对汉语语音的情感处理也进行了一些研究。清华大学和中科院心理所合作,将人机交互技术与心理、认知科学相结合,在情感语音计算和处理领域迈出了新的探索的步伐。中国科学院自动化研究所,东南大学,微软亚洲研究院分别有了成果,中国台湾的许多大学和研究所也对其进行了研究[3-4]。
而维吾尔语的情感分析和处理还处于初级阶段,要进一步地研究。目前,在维吾尔语情感语音合成系统中主要实现了将书面语言转换成口语输出,达到了语音词汇传达的准确性,而忽略了包含在语音信号中的情感因素。语音合成的可懂度,清晰度已经基本解决了,只不过缺乏丰富的语气,语速变化,所以听起来单调之味,很大程度上阻碍了维吾尔语语音合成的广泛应用[5]。研究维吾尔语情感语音合成涉及到维吾尔语情感语音数据库建设,情感韵律特征分析及建模,情感转换等研究领域[6]。
1 情感韵律特征库建设
1.1 维吾尔语情感语音数据库的建立
建立情感语音数据库是情感建模,情感语音合成的基础。文中首先选择了维吾尔语中的情感类别,主要是选了高兴,生气,中性三种情感,总共收集了600个句子。
目前维吾尔语情感语音库的建立工作包括如图1所示的4个步骤。
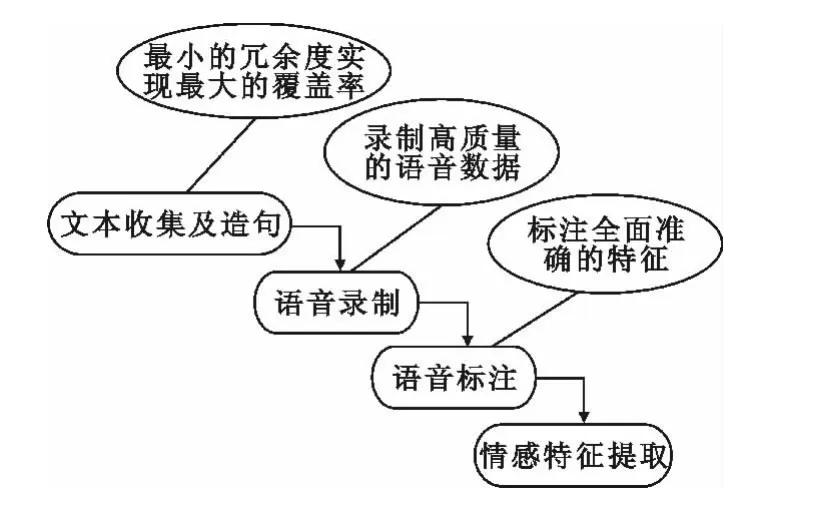
图1 情感语音库建设流程Fig.1 Construction process of emotional speech database
第一步:首先要收集有助于发音人的朗读和情感表达的、丰富的文本语料。结合韵律环境的音节、音素和情感类别覆盖率为目标,从中选取具有代表性的句子文本。然后针对不同的情感类别对选取的句字文本进行了字面上的修改。修改时要求修改后的文本能够更好的从文本上体现目标情感。
第二步:对收集好的文本句子进行语音录制,10个发音人员(5男,5女)对语料进行情感语音录制,语音采样率为16 kHz,采样精度为16 bit。
第三步:维吾尔语韵律结果一般分为语句,语调短语,韵律短语,韵律词,单词,音节,音素总共7层,对语料进行7层自动标注,然后进行手工修改(如图2所示)。
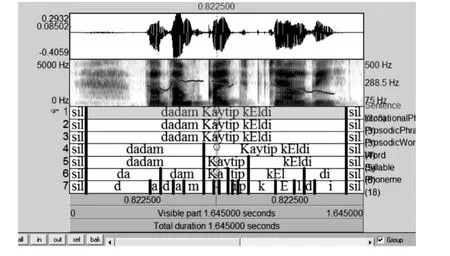
图2 维吾尔语的韵律结构Fig.2 Uyghur prosodic structure
第四步:从以上的语音标注数据中提取每一个音节的6个韵律特征参数和19个语境信息。
1.2 情感特征参数的提取
文中利用STRAIGHT参数合成算法进行中性语音和情感语音特征参数的提取,分析和建模。STRAIGHT是一种针对语音信号的高性能的算法[7],它通过对语音短时谱进行时频域的自适应内插平滑来提去除基频影响的语音信号精确地谱包络,并能在恢复语音的过程中进行时长,基频及谱参数的调整。
从以上的语音标注数据中提取与情感表达关系最为密切的短时平均能量(E)、音段时长(T)、基频最大值(fp,max)、基频最小值(fp,min)、基频均值(favg)与基频范围(frange)这6个韵律特征作为分析与建模的对象。
文中利用每个句子的wav文件和textgrid文件来进行提取参数,用STRAIGHT来提取了每一个句子中的各个音节的语音参数,还有提取了每一个音节的19个特征(语境信息)。然后c#里面写程序合并了6个参数和19个特征。
2 情感韵律特征建模
利用STRAIGHT来提取的每个音节的19个语境信息和6个参数来进行情感建模,实验中利用分类回归树(CART)算法[8],建立中性和情感特征参数之间的映射关系。输入要合成语音的语言层信息和中性语音的参数,能生成不同种类的情感语音的韵律特征参数。基于CART的情感语音韵律生成模型如图3所示。

图3 基于CART的情感语音韵律生成模型Fig.3 CART-based generation model of emotional speech prosody
提取参数完后,在Linux环境下用wagon建模步骤是:先在Linux下安装Speech toll语音工具,安装过程中生成了wagon和wagon_test可执行文件,然后选取要训练的数据,比如:选取十个句子的特征和参数,用wagon进行建模,生成决策树,得到每种参数的tree文件。下一步要选取测试的数据(训练数据和测试数据的格式一定要一致)然后用wagontest来预测测试数据的语音参数。
2.1 决策树聚类
对6个情感韵律特征在音节层上分别进行了决策树建模,所用到的语境信息如下:
音节的19个特征:
1)音节拼音。
2)音节类型。
3)元音个数。
4)辅音个数。
5)前一个音节。
6)后一个音节。
7)当前音节到句首的音节数。
8)当前音节到句尾的音节数。
9)当前音节到句首的韵律短语数。
10)当前音节到句尾的韵律短语数。
11)当前音节到韵律短语首的音节数。
12)当前音节到韵律短语尾的音节数。
13)当前音节在语法词中的绝对位置。
14)当前音节所在的语法词到句首的单词数。
15)当前音节所在的语法词到句尾的单词数。
16)当前单词所在语法词的音节数。
17)当前单词所在语法词的前缀音节数。
18)当前单词所在语法词的词干音节数。
19)当前单词所在语法词的词缀音节数。
3 实验结果与分析
3.1 单个情感特征的独立建模实验
为了验证所提取情感韵律特征的完整性,文中首先对每个情感类别单独进行了韵律特征建模与模型性能的测试实验。测试中,采用了开放测试和封闭测试方法。
开放测试中,每种情感语音数据的80%用于建模训练,其余的20%用于为模型测试。表1给出了开放测试的结果。
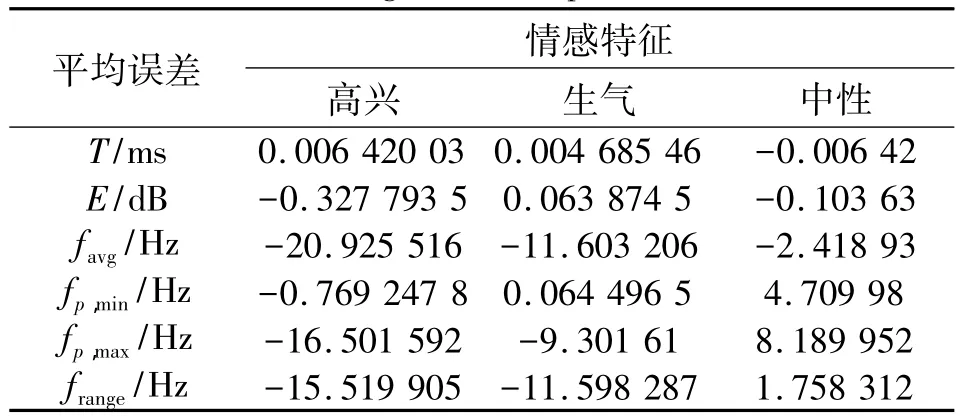
表1 开放测试结果的平均误差值Table 1 Average error in open test results
从表1可以看出,高兴和生气情感具有相同的趋势,其中基频最小值的预测误差最小,其次是基频范围,基频均值,最大值的误差还比较大。中性情感的基频均值,最大值和最小值的误差比较大。
封闭测试中,对收集的全部数据进行训练,然后对一部分数据进行测试。表2给出了封闭测试结果。
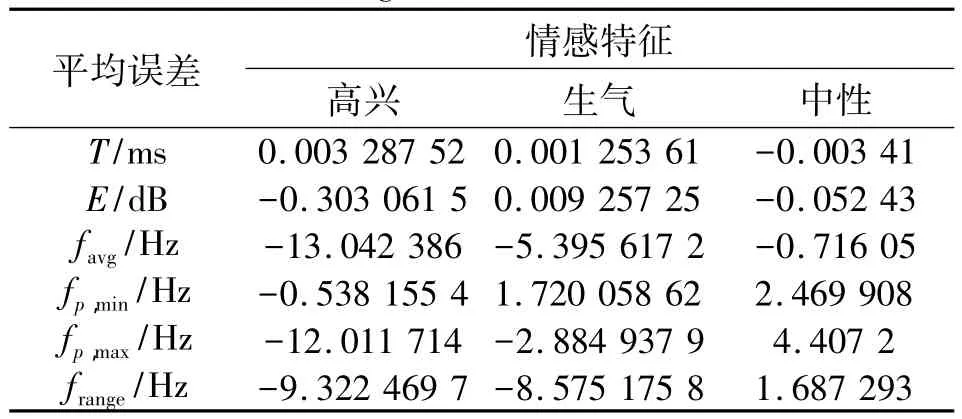
表2 封闭测试结果的平均误差值Table 2 Average error in closed test result
从表2可以看出,高兴,生气,中性三种情感中高兴情感的误差比较大。其中基频范围,最大值,基频均值的误差变化最明显。中性情感和生气情感的预测误差比较小。
总体来看,模型测试2的效果比较好,预测误差最小,预测出来的参数值很接近原来的参数值。对三种情感,其中中性情感的预测误差最小。
3.2 中性向其它情感的转换特征建模实验
为了验证所提取情感韵律特征的完整性,文中再按照语句和音节级别来分别对中性向其它两种情感的转化特征进行了建模。
首先,以语句作为单位,由中性转为两种情感时的变化情况如表3所示。
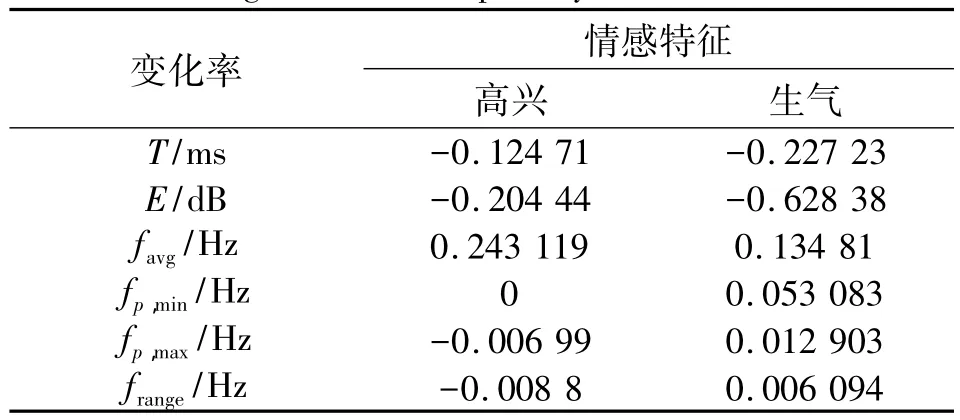
表3 情感韵律特征在语句级别的变化情况Table 3 Changes of affective prosody at the statement level
从表3可以看出,在语句级别,高兴情感的韵律特征变化主要体现在基频均值的提高上,相应的时长,能量,基频最大值,最小值有所减少,其中最为显著。生气情感的时长和能量有所减少,最明显的是能量急剧下降。其他的基频均值,最大最小值有所提高。
其次,以音节为单位,由中性转为两种情感特征的变化情况如表4所示。
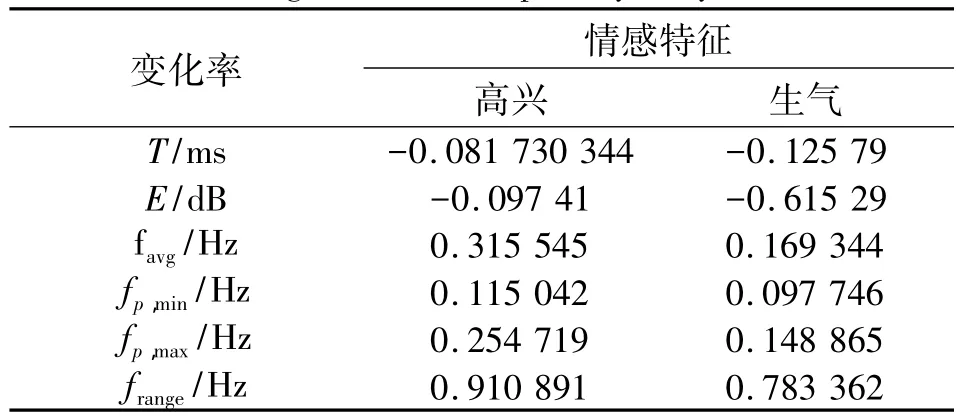
表4 情感韵律特征在音节级别的变化情况Table 4 Changes of affective prosody at syllable level
从表4可以看出,生气和高兴的变化趋势一样,时长和能量有所减少,基频均值,最大最小值,范围都是有所提高。
4 结语
文中对高兴,生气,中性3种情感在语句和音节级别上进行分析,利用STRAIGHT算法提取了每个音节的韵律参数,通过分类回归(CART)算法来建立了韵律预测模型。从实验结果看出中性情感的预测误差最小,因为中性情感的数据(句子数)多,所以进行测试时效果也好。高兴情感与生气情感的误差比较大,是因为收集的数据少。下一步扩大语料库,增加数据,按照所提取的情感特征能更准确地区分各个情感类型。
[1] 徐俊,蔡连红.面向情感转换的层次化韵律分析与建模[J].清华大学学报:自然科学版,2009,49(SI):1274-1277.XU Jun,CAI Lian-hong.Emotion-oriented Hierarchical Prosody Conversion Analysis and Modeling[J].Journal of Tsinghua University(Science and Technology),2009,49(SI):1274-1277.
[2] 吴义坚.基于隐马尔科夫模型的语音合成技术研究[D].合肥:中国科学技术大学,2006.WU Yi-jian.Hidden Markov Model-base Speech Synthesis Technology Research[D].Hefei:Chinese Academy of Sciences,University of Science and Technology,2006.
[3] 王宁.采用Pitch Target模型与韵律参数调整的语音情感转换[D].苏州:苏州大学,2012,WANG Ning.Using Pitch Target Model and Emotional Speech Prosody Conversion Parameter Adjustment[D].Suzhou:Suzhou University Master's Degree Thesis,2012.
[4] 周浩.基于高斯混合模型的情感语音转换[C]//2011年度中国西部声学学术交流会论文集.宁夏,银川:出版者不详,2011.ZHOU Hao.Gaussian Mixture Model based on Emotional Speech Conversion[C]//2011 China Western Acoustics Symposium.Yinchuan,Ningxia,2011.
[5] 姑丽加玛丽·麦麦提艾力、艾斯卡尔·艾木都拉.面向提高自然度的维吾尔语音合成关键技术研究[D].乌鲁木齐:新疆大学,2012.Guljamal Mamaitili,ASKAR Hamdulla.Key Technology Research for Improving Speech Synthesis Naturalness of Uyghur.[D].Urumqi:Xinjiang University PhD thesis,2012.
[6] 艾斯卡尔·肉孜、艾斯卡尔·艾木都拉.基于HMM的维吾尔语音合成系统的研究与实现[D].乌鲁木齐:新疆大学,2008.ASKAR Rozi,ASKAR Hamdulla.Research and Implementation of HMM-based Uyghur speech synthesis system[D].Urumqi:Xinjiang University Master's Degree Thesis,2008.
[7] KAWAHARA H.STRAIGHT-TEMPO:A Universal Tool to Manipulate Linguistic and Para-Linguistic Speech Information[C]//IEEE International Conference on Systems,Man,and Cybernetics.[s.l.]:IEEE,1997.
[8] TAO Jianhua,KANG Yongguo,LI Aijun.Prosody Conversion from Neutral Speech to Emotional Speech[J].IEEE Transactions on Audio,Speech& Language Processing,2006,14(04):1145-1154.
猜你喜欢
中国人民公安大学学报(自然科学版)(2022年1期)2022-07-20
新疆大学学报(自然科学版)(中英文)(2022年2期)2022-03-27
山东交通科技(2020年2期)2020-08-13
中国民族博览(2019年10期)2019-11-29
中华诗词(2019年1期)2019-08-23
福建基础教育研究(2019年11期)2019-05-28
乡村地理(2018年4期)2018-03-23
周末·校园文学(2017年35期)2018-02-06
自动化学报(2017年4期)2017-06-15
电子制作(2017年20期)2017-04-26
