
多数据源中局部模式挖掘研究
2013-09-28 04:57林耀进胡学钢
合肥工业大学学报(自然科学版) 2013年1期
林耀进, 胡学钢
(1.合肥工业大学 计算机与信息学院,安徽 合肥 230009;2.漳州师范学院 计算机科学与工程系,福建 漳州 363000)
0 引 言
随着网络通信技术与分布式数据库技术的不断发展与应用,连锁经营的大型企业所属的子公司数量不断增加,大型企业一般将数据库存放在相应的子公司,总公司在数据汇总分析时,需要数据挖掘系统能够对不同子公司数据库的情况采取相应策略,从而涉及多数据源挖掘问题。因此,有效地从多数据源中提取有用的信息为各种决策提供服务是数据挖掘领域的一个研究热点。
多数据源挖掘是一项艰巨的任务,主要面临以下困难:① 数据格式的异构性。现实中如云计算环境下的数据结构存在多样性,同时数据库中也可能存在噪声,因此,在挖掘前需要对数据进行预处理。② 数据库容量过大。多数据源挖掘不仅面临多个局部数据库,而且存在局部数据库容量过大的情况,利用并行技术进行挖掘需要对硬件和软件进行升级,耗资过大。③ 数据隐私性。局部数据库提供原始数据进行全局挖掘,有可能导致数据隐私的泄露。因此,设计一套合适有效的多数据源挖掘方法需要对实际应用进行分析。
多数据源挖掘存在于多个研究领域中,许多学者针对不同的实际需求,给出了相应的挖掘技术。为解决全局查询无法直接查询异构数据源问题,文献[1]提出将全局查询分解为针对异构数据源子查询的解决方案;文献[2]针对相同应用背景下多数据源模式的集成问题进行了研究,提出一种基于用户使用信息的多模式集成方法;文献[3]给出了 WoRLD(Worldwide Relational Learning Daemon)系统,该系统利用传播活动从网络中分布的多数据源进行归纳学习;文献[4]为了减少从多数据源中搜索信息的时间,根据相关应用对数据库进行了划分,使搜索信息更有针对性,且降低了搜索时间;为了从分布式数据库中挖掘定量关联知识,文献[5]提出了一种从分布式数据源中挖掘自适应的比例规则;文献[6]通过设定时间窗口,挖掘与事件序列发生时间有关的多领域序列模式;文献[7]提出了基于局部模式分析的多数据源挖掘方法,局部模式分析方法是指根据局部数据库提供的局部规则进行合成以产生全局规则,并不需要将局部数据库中的数据进行集成后统一挖掘,降低了挖掘时间、减轻了对硬件设备的依赖、保护了数据的隐私性,是一种有效的多数据源挖掘方法;文献[8]从多数据源划分、模式合成等方面对基于局部模式分析的多数据源挖掘方法进行了分析与改进。目前,对于多数据源模式挖掘,主要可归类为传统数据挖掘方法、并行技术挖掘方法与局部模式分析挖掘方法等3种方法。
传统的数据挖掘方法[7]是将所有局部数据库的数据集成到单一数据库,采用Apriori、FP-growth等传统算法进行挖掘。该方法虽能有效地提取有趣的全局模式,但存在以下缺点:① 局部数据库之间存在数据特征不一致性,如格式差异、数据冲突等;② 集成后的数据库容量太大,对计算机软硬件要求较高;③ 无法挖掘局部模式,不能为子公司制定决策;④ 数据隐私性,子公司可能不愿提供原始数据。
并行技术挖掘方法[9-10]利用并行技术将挖掘任务分布在大量相连的计算机上,能够很好地对分布于不同位置的数据库进行挖掘。但是,并行技术挖掘存在着对软硬件要求较高,面临隐私泄露、数据异构难以挖掘等问题。另外,传统的数据挖掘方法不能在并行技术环境中使用。
文献[11-13]根据大型连锁超市需要从所有子公司的交易数据库提取全局模式以制定全局决策的需求,设计了仅依靠局部数据库提供局部模式就可以获取全局模式的方法,称之为局部模式分析法。局部模式分析法解决了传统数据挖掘方法和并行技术方法所面临的问题,其具体流程如图1所示。该方法有效地保护了数据隐私性,降低了数据量,获得的模式可以为子公司和总部提供决策。
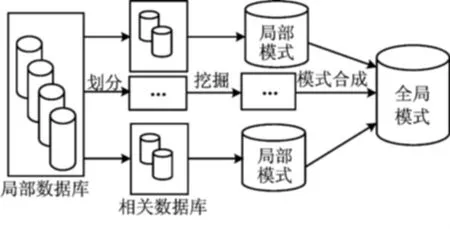
图1 局部模式分析多数据源挖掘流程
1 多数据源的划分
数据源之间由于存在着主题不一致、数据格式不同、数据的组织结构多样性等差异,所以对多数据源进行挖掘之前必须对数据进行预处理,其中,为了降低从大量数据源中搜索数据所需的时间以及减少对全局决策没有价值的数据,需要对多数据源进行划分,文献[14-15]讨论了与应用相关的多数据源划分方法,所提出的方法有效地缩减了大数据集的容量,但是在没有额外信息情况下,划分效果不佳;文献[16]针对数据共享环境多数据源选择问题,基于Pareto最优理论提出了多数据源选择方法,该方法有效地缩小了搜索空间;文献[17]针对事务数据库,提出了一种有效独立于应用的数据库划分方法,其主要思想为:如果2个事务数据库拥有大量相同的数据项,则2个数据库相似程度较高。
多数据源划分问题描述为:给定m个来自于不同子公司的数据源,即 D={D1,D2,…,Dm},根据数据源之间的相似性,设计搜索最优划分的有效算法对D中m个数据源进行划分。由此可以看出,有效的数据源之间相似性的度量方式能够对数据源更精确地划分。目前,存在以下几种度量数据源相似性的方法。
(1)根据数据源所包含相同数据项的度量方法[17],其公式为:
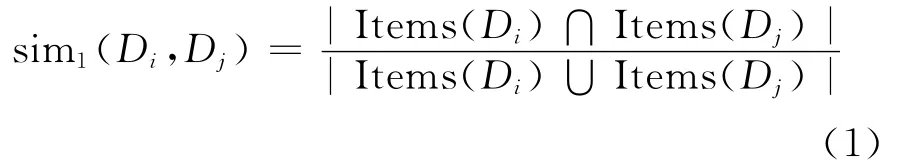
其中,Items(Di)为数据源Di拥有数据项的集合;|·|为集合的基数,下同。
(2)根据数据源得到模式所包含相同数据项的度量方法[17-19],有3种情形,其公式为:

其中,Si为数据源Di产生的模式;Items(Si)为Si模式集合中所有数据项的集合。
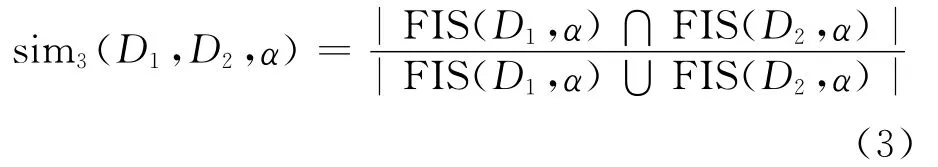
其中,sim3(Di,Dj,α)为满足支持度α下数据源Di与Dj的相似度度量方法;FIS(Di)表示从数据源Di提取满足支持度为α的频繁项集数量。
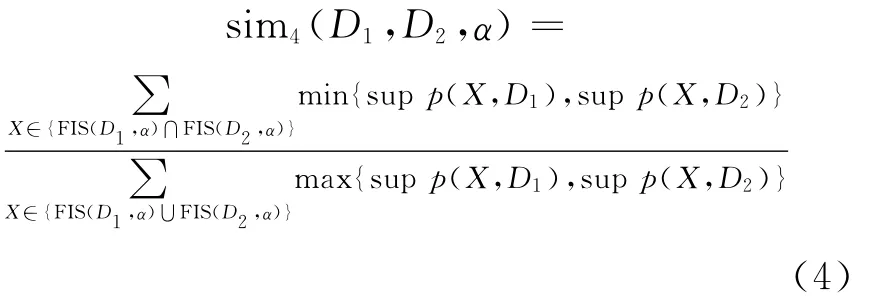
其中,sup p(X,Di)为频繁项集X在数据源Di中的支持度。
文献[18]对(1)式、(2)式进行详细分析,指出拥有大量相同数据项的数据源,其相似程度并不一定高,认为对多数据源进行知识提取时要考虑数据源的特性,该特性取决于其频繁项集,因为频繁项集反映了顾客的购买行为,即反映了数据源的特点,因此提出了(3)式和(4)式2种度量方法。由(4)式可看出,度量方法更加合理,因为每个频繁项集的支持度可以被认为其在数据源中的权重,(3)式度量方法认为频繁项集的权重都为1,而(4)式选取两数据源共有的频繁项集的最小支持度作为分子,最大支持度作为分母,更加合理地度量数据源之间的相似性。
在度量完数据源之间相似性后,设计一种对多数据源搜索最优划分的算法,其步骤为:
(1)给定阈值α,对数据源进行划分,即
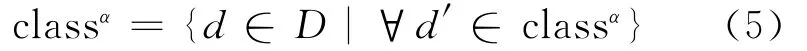
其中,d与d′满足α相关;D为所有数据源集合;classα为两两之间相似度大于α的数据源集合。
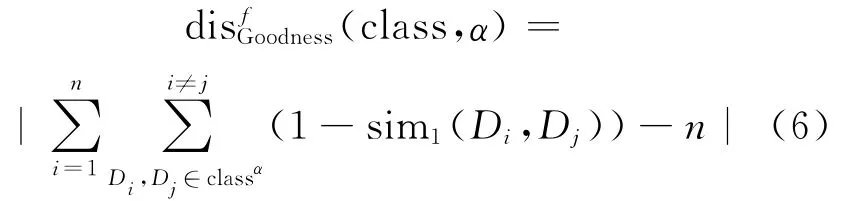
根据以上划分过程,文献[17]设计了相应的算法,其中GreedyClass算法对数据源进行划分,BestClassification算法从所有划分中寻找最优划分。虽然该方法能很好地划分数据源,但GreedyClass算法的时间复杂度为O(n2m2+m4),其中n为数据源中项的个数,m为数据源的数量。随着数据源数量的增加,该算法显得低效。为此,文献[19]设计一种新的数据划分算法completeclass,将时间复杂度降低至O(m3)。
2 有趣模式研究
相对于传统地将局部数据库汇总到统一数据库中进行挖掘的方法,基于局部模式分析的多数据源挖掘不仅挖掘单个数据源得到局部模式,而且综合局部模式得到全局模式,有效地为各级决策提供依据。另外,对局部私有数据的安全性、局部数据源的完整性和独立性也起到了保护作用。有趣模式发现问题描述如下。
给定m个来自于不同子公司的数据源,即D1,D2,…,Dm,LIi表示从局部数据源Di中获取的模式集,本问题在从所有局部模式(∪LIi)中发现有趣的模式。文献[7]将多数据源中的模式分为以下5种:
(1)局部模式,即子公司数据源中挖掘出来的模式。
(2)高选票模式,指大部分子公司数据源共有的模式与规律,总公司可依据该模式制定维护大多数子公司的共同利益的经营策略。
(3)例外模式,指在个别数据库中具有较高的支持度,而在其他数据库中具有零支持度(即不被其他数据库支持)的模式,总公司可因地制宜为少数公司制定相应的决策策略。
(4)推荐模式,该模式的选票率小于给定的最小选票率,但又很接近最小选票率,有时这类模式对决策很有用。
(5)全局模式,指将所有局部数据库合成一个全局数据库,再从全局数据库挖掘出的模式。
由于例外模式比其他4种模式在信用卡欺诈检测、公司经营决策等方面具有更重要的作用,为了从局部模式中寻找有趣的例外模式,文献[20]提出了2种例外模式兴趣度量方法,分别为:
(1)第1种兴趣度量,即
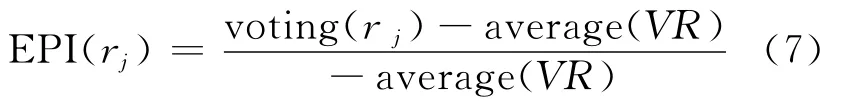
其中,voting(rj)为模式rj的选票率(包含模式rj数据库的数量与所有数据库数量之比);average(VR)为所有模式的平均选票率。该度量主要用来度量模式rj在所有数据库中的支持率。
(2)第2种兴趣度量,即
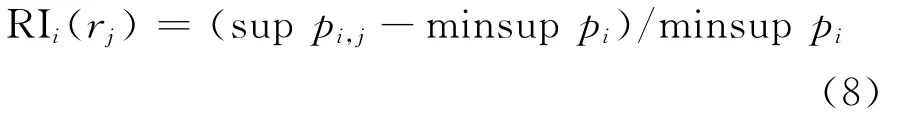
其中,sup pi,j为模式rj在数据库Di的支持度;minsup pi为所有模式在数据库Di中最低的支持度。该度量主要用来度量模式rj在数据库Di的支持度。
根据上述2种度量方法的定义可知,若一个模式同时满足 EPI(r)≥ min EP与 RIi(r)≥min EPsup,其中min EP、min EPsup 为 用户 自定义的2个阈值,则该模式称为例外模式。(7)式从投票率对模式进行度量,(8)式从支持度对模式进行度量,当面对多数据源容量大小不一致时,若模式在数据源容量低的支持率高,在数据源容量高的投票率低,从销售经营角度看,该模式为例外模式,但是并没有很大的经济价值,因此,在挖掘例外模式时,还需要考虑局部数据源的权重。
除了以上5种模式外,一些学者根据实际应用需要,从不同角度挖掘其他模式。在多数据源环境下,不同子公司拥有不同的商品捆绑销售策略,并且策略随时间不断改变,文献[21]提出了一种在多数据源环境中自动抽取关联模式,该关联模式包含商品销售的地点与时间。文献[22]根据不同时间段将数据库划分成多个时间相关数据库,并利用协方差统计支持度随时间基本稳定不变的数据项,在不同时间数据库中挖掘销售量密切相关的模式,为公司提供商品销售策略。
3 局部模式合成算法
根据局部数据库挖掘出的模式,对全局模式进行近似求解,一方面避免了将所有局部数据库合在一起存在数据库容量过大、隐私窃密等问题,另一方面,局部数据库中提取的模式对公司总部来说,有些模式是冗余的,有些模式是重要的,因此,下面研究各种局部模式合成方法(也称为对全局模式进行近似求解)。另外,局部模式合成得到的模式的支持度、置信度应与传统方法在全局数据库得到的模式近似。
局部模式合成方法问题的描述如下:存在m个主题相关的局部数据库为D1,D2,…,Dm,每个局部数据库拥有相应的满足一定条件的模式集LI1,LI2,…,LIm,称为局部模式,综合局部模式LI1,LI2,…,LIm进行全局分析是问题的关键。
针对来源于局部数据库的高频繁模式,文献[12]提出了一种基于权重的RuleSynthesizing算法,其时间复杂度为O(n4×max NosRules×totalRules2),其中n、max NosRules、totalRules分别表示数据库的个数、从不同局部数据库中所提取的最多模式数、不同数据库中所有模式总数。算法主要过程如下。
(1)计算相应模式的权重,公式为:

其中,WRi为模式Ri的权重;Num(Ri)为拥有模式Ri的数据库总数。
(2)依据每条模式的权重,计算局部数据库的权重,公式为:
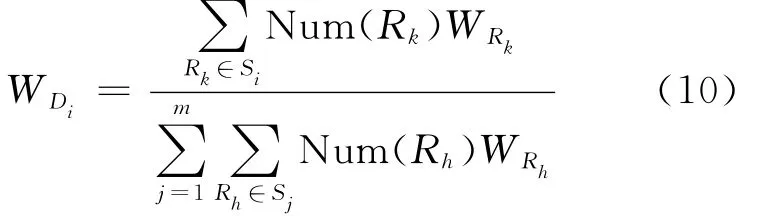
其中,WDi为数据库Di的权重;Si为数据库Di包含的所有模式集。
(3)计算合成模式的支持度与置信度,公式为:
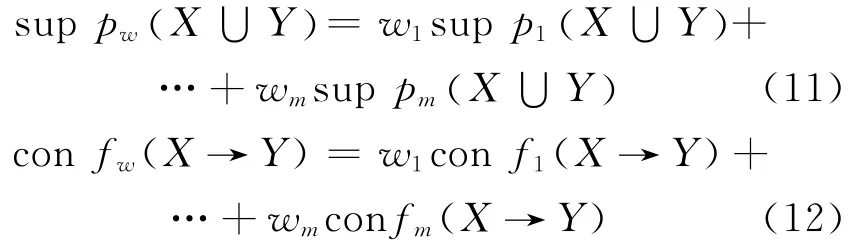
(4)对合成方法的效果进行度量,有2种度量方式。
最大误差法:
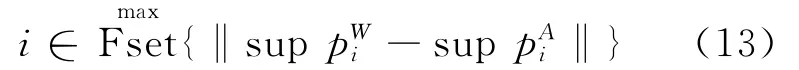
平均误差法:
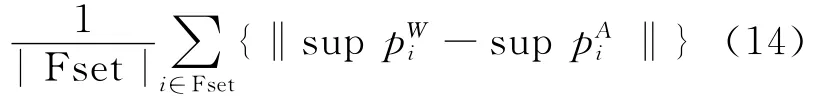
文献[23]认为,局部模式合成方法[12]是基于各局部数据库的容量大小基本一致的假设,然而现实中,数据库之间的大小有可能差异较大,所以提出了一种基于事务的数量的高频繁模式合成方法,其中,模式权重的计算公式为:
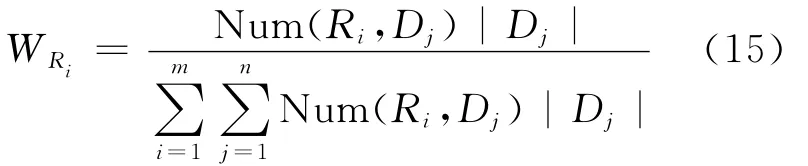
其中,|Dj|为数据库Dj包含的事务总数;Num(Ri,Dj)为拥有模式Ri的数据库总数。
文献[24]认为局部模式分析挖掘方法是挖掘多数据源的一种近似方法,在模式的合成过程中,更多的局部模式会提高合成模式的质量,据此,提出一种ACP Coding方法对局部模式进行压缩,降低支持度与置信度,以选择更多局部模式。文献[25]认为在一个数据库中所显示的顾客购买行为趋势也存在数据库中,并将这种数据库称为实时数据库,于是,提出了一种从不同实时数据库中合成 重 关 联 模 式 的 Association-Rule-Synthesis算法,主要采纳了更多的高频繁模式。与Rule-Synthesizing算法[12]相比,文献[25]的算法具有以下几个优点:① 时间复杂度低,max{O((M+N)×lg(M+N)),O(n×(M+N))},其中,N,M分别为从n个数据库中获取的模式总数、推荐模式总数;② 平均错误率较低;③ 该算法能识别重关联模式的类型。文献[26]将多数据源挖掘分为广义与狭义2种,广义多数据源挖掘是指采用局部模式分析方法识别有趣的局部模式,然后对局部模式进行合成;狭义多数据源挖掘是指针对如实时多数据源、选取与决策有关的数据项等特殊应用的挖掘。因此,文献[26]提出基于PFT(Pipelined Feedback Technique)技术的多数据源挖掘方法,结果表明该方法能对大容量局部数据库进行挖掘。
上述多数据源挖掘方法并未考虑局部数据源之间数据的关系,从而造成从局部数据源中合成的全局模式是不完备的,文献[27]提出了一种基于核估计的非线性方法处理不同数据源中数据的关系,该方法具有以下优点:① 发现的模式不仅是局部有趣的,而且是全局有趣;② 不同的数据库分配不同的权重;③ 利用属性对数据库进行划分,极大地减少了内存需求;④ 有效地保护了数据隐私。
以上研究均是围绕A→B的正关联规则形式进行的,现实中存在形如A→⇁B,⇁A→B,⇁A→⇁B的负关联规则,文献[28]提出了一种能够同时挖掘正关联规则和负关联规则的算法,以传统的Apriori算法挖掘频繁项集中的正关联规则和非频繁项集中的负关联规则。文献[29-30]探讨了在多数据中挖掘负关联规则的方法,提出了负关联规则合成方法,利用负规则的选票率解决正规则与负规则间的冲突,并讨论了多数据源中时态负关联规则的提取方法。
4 总结与展望
本文详细地讨论了多数据源研究背景,分析了该问题所涉及的研究内容,并对已有的研究成果进行了详细介绍。多数据源挖掘主要包括数据库聚类、提取有用的局部模式及对局部模式进行合成等3个方面,可以从这3个方面深入提高挖掘效率的方法。
本文所提到的数据库为事务数据库,而现实中,数据库是多样化的,存在结构化、半结构化、非结构化等不同结构的数据库,而且涉及如数据隐私、测试代价及时态等问题,本文认为未来的研究方向主要有以下几个方面:
(1)数据挖掘过程中保护数据隐私是个重要问题[31-32],如病人健康记录、用户行为记录等涉及个人隐秘的信息,简单地删除用户姓名、地址等字段并不能有效隐藏个人隐私。将来随着应用的需要,更多的隐私保护挖掘算法将会出现在隐私敏感多数据源中。
(2)生物信息学[33-34]的最新发展使人们可以获得不同的数据库,如用mRNA和miRNA概述内容、生物信号传导途径和基因注释等,多数据源的有效结合丰富了生物相关的样例与基因知识。
(3)序列模式挖掘能够发现模式之间的时态关系[35-37],在实际应用中,存在主题相同的多序列数据库,如在用信用卡支付衣服、书籍的购买及饮食消费等过程中,人们在购买时尚杂志后可能购买相关的服装,这就需要从多序列数据库寻找有关的序列模式。
[1]李柳青,冯志勇,刘 超.基于多源异构数据的查询分解算法[J].计算机工程,2010,36(23):56-58.
[2]丁国辉,王国仁,赵宇海.基于使用信息和聚类方法的多模式集成[J].计算机研究与发展,2010,47(5):824-831.
[3]Aronis J M,Kolluri V,Buchanan F J,et al.The WoRLD:Knowledge discovery from multiple distributed databases[C]//Proceedings of 10th International Florida AI Research Symposium,1997:337-341.
[4]Liu H,Lu H J,Yao J.Identifying relevant databases for multi database mining[C]//PAKDD,1998:210-221.
[5]Yan J,Liu N,Yang Q,et al.Mining adaptive ratio rules from distributed data sources[J].Data Mining and Knowledge Discovery,2006,12(2/3):249-273.
[6]Peng W C,Liao Z X.Mining sequential patterns across multiple sequence databases[J].Data & Knowledge Engineering,2009,68(10):1014-1033.
[7]Zhang S C,Zhang C Q,Wu X D.Knowledge discovery in multiple databases[M].New York:Springer,2004:110-120.
[8]Adhikari A,Rao R R,Pedrycz W.Developing multi-database mining applications[M].New York:Springer,2010:78-92.
[9]Agrawal R,Shafer J.Parallel mining of association rules[J].IEEE Transactions on Knowledge and Data Engineering,1996,8(6):962-969.
[10]Parthasarathy S,Zaki M J,Ogihara M,et al.Parallel data mining for association rules on shared-memory systems[J].Knowledge and Information Systems,2001,1(1):1-29.
[11]Zhang S C,Wu X D,Zhang C Q.Multi-database mining[J].IEEE Computational Intelligence Bulletin,2003,3(1):5-13.
[12]Wu X D,Zhang S C.Synthesizing high-frequency rules from different data sources[J].IEEE Transactions on Knowledge and Data Engineering,2003,15(2):353-367.
[13]Zhang C Q,Liu M L,Nie W L,et al.Identifying global exceptional patterns in multi-database mining[J].IEEE Computational Intelligence Bulletin,2003,3(1):19-24.
[14]Zhong N,Yan Y,Ohsuga S.Peculiarity oriented multi-database mining[C]//Proceedings of PKDD’99,1999:136-146.
[15]Liu H,Lu H J,Yao H.Toward multi database mining:identifying relevant databases[J].IEEE Transactions on Knowledge and Data Engineering,2001,13(4):541-553.
[16]汪晓庆,郑彦兴,史美林.一种有效的数据共享环境多数据源选择算法[J].软件学报,2008,19(2):314-322.
[17]Wu X D,Zhang S C,Zhang C Q.Database classification for multi-database mining[J].Information System,2005,30(1):71-88.
[18]Adhikari A,Rao P R.Efficient clustering of databases induced by local patterns[J].Decision Support Systems,2008,44(4):925-943.
[19]Li H,Hu X G,Zhang Y M.An improved database classification algorithm for multi-database mining[C]//FAW 2009,LNCS 5598,2009:346-357.
[20]Zhang S C,Zhang C Q,Yu J X.An efficient strategy for mining exceptions in multi-databases[J].Information Sciences,2004,165(1):1-20.
[21]Chen Y L,Tang K,Shen R J,et al.Market basket analysis in a multiple store environment[J].Decision Support System,2005,40(2):339-354.
[22]Adhikari J,Rao P R,Adhikari A.Clustering items in different data sources induced by stability[J].The International Arab Journal of Information Technology,2009,6(4):394-402.
[23]Ramkumar T,Srinivasan R.Modified algorithms for synthesizing high-frequency rules from different data sources[J].Knowledge and Information System,2008,17(2):313-334.
[24]Adhikari A,Rao P R.Enhancing quality of knowledge synthesized from multi-database mining[J].Pattern Recognition Letters,2007,28(16):2312-2324.
[25]Adhikari A,Rao P R.Synthesizing heavy association rules from different real data sources[J].Pattern Recognition Letters,2008,29(1):59-71.
[26]Adhikari A,Ramachandrarao R,Prasad B,et al.Mining multiple large data sources[J].The International Arab Journal of Information Technology,2010,7(3):241-249.
[27]Zhang S C,You X F,Jin Z,et al.Mining globally interesting patterns from multiple databases using kernel estimation[J].Expert Systems with Application,2009,36(8):10863-10869.
[28]Wu X D,Zhang C Q,Zhang S C.Efficient mining of both Positive and negative association rules[J].ACM Transactions on Information Systems,2004,22(3):381-405.
[29]Shang S J,Dong X J,Geng R N,et al.Mining negative association rules in multi-database[C]//Fifth International Conference on Fuzzy Systems and Knowledge Discovery,2008:596-599.
[30]尚世菊,懂祥军,赵 龙.多数据源中的负关联规则挖掘技术及发展趋势[J].计算机工程,2009,35(5):61-63.
[31]Bhaskar R,Laxman S,Smith A.Discovering frequent patterns in sensitive data[C]//KDD’2010,Washington,DC,2010:37-42.
[32]Wu X D,Kumar V,Quinlan J R,et al.Top 10algorithms in data mining[J].Knowledge and Information Systems,2008,14(1):1-37.
[33]Lu H C,Shi C C,Wu G W,et al.Integrated analysis of multiple data sources reveals modular structure of biological networks[J].Biochemical and Biophysical Research Communications,2006,345(2):302-309.
[34]Zhao Z,Wang J X,Liu H.Identifying biologically relevant genes via multiple heterogeneous data sources[C]//KDD’08,Las Vegas,Nevada,USA,2008:24-28.
[35]Kum H C,Chang J H,Wang W.Sequential pattern mining in multi-databases via multiple alignment[J].Data Mining and Knowledge Discovery,2006,12(2/3):151-180.
[36]Chen Y L,Wu S Y,Wang Y C.Discovering multi-label temporal patterns in sequence databases[J].Information Sciences,2011,181(2):398-418.
[37]张 晶,张 斌,胡学钢.基于领域知识的冗余关联规则消除算法[J].合肥工业大学学报:自然科学版,2011,34(2):246-250.
猜你喜欢
数学物理学报(2022年4期)2022-08-22
上海文化(文化研究)(2022年3期)2022-06-28
数学物理学报(2022年2期)2022-04-26
数学年刊A辑(中文版)(2022年4期)2022-02-16
数学年刊A辑(中文版)(2019年3期)2019-10-08
金桥(2018年4期)2018-09-26
计算机与生活(2018年3期)2018-03-12
中国科技期刊研究(2017年2期)2017-05-14
中国学术期刊文摘(2016年1期)2016-02-13
浙江大学学报(工学版)(2015年2期)2015-05-30
