
Modality, Vocabulary Size and Question Type asMediators of Listening Comprehension Skill
2013-12-04 07:42MURPHYJUNCSILLO
当代外语研究 2013年12期
. MURPHYJUN . . CSILLO
The University of Oxford, UKThe University of Hong Kong, China
Most studies that have investigated the relationship between lexical knowledge and listening performance have used vocabulary assessments administered in the visual modality (e.g., Mecartty, 2000). However, the outcomes of vocabulary tests might vary as a function of the modality in which they are carried out (e.g. Milton & Hopkins, 2005, 2007). Aural knowledge of words might be particularly important in listening, therefore using visually measured lexical knowledge as a predictor of listening performance could be problematic. To explore this issue, 51 English as a second language (L2) learners from a vocational training institute in Hong Kong aged between 18 and 19 were given two different versions of the X Lex vocabulary test: (1) the visual X Lex (Meara & Milton, 2003) and (2) the Aural Lex (Milton & Hopkins, 2005). The listening sub-test of the International English Language Testing System (IELTS) was also administered to measure participants’ listening performance. The results indicated that (1) participants scored higher in the X Lex than the Aural Lex; (2) the Aural Lex was a stronger predictor of listening performance than the X Lex; (3) participants’ proficiency in aural vocabulary influenced performance on the listening test. These results suggest that visual measurements of lexical knowledge may not as accurately reflect the learners’ aural knowledge of words and therefore, the modality in which (lexical) knowledge is assessed when estimating vocabulary as a predictor of other skills needs to be considered.
Keywords: modality, vocabulary, aural vocabulary, listening comprehension
Correspondence should be addressed to Dr. Victoria A. Murphy, Department of Education, The University of Oxford, 15 Norham Gardens, Oxford, OX26PY, United Kingdom. Email: victoria.murphy@education.ox.ac.uk
INTRODUCTION
The skill of listening can be considered either unidirectional or bidirectional. Unidirectional listening refers to a task in which listeners do not have the chance to interrupt the flow of speech in order to seek clarification from the speaker (Macaro, Graham, & Vanderplank 2007). Bidirectional listening, on the other hand, involves interaction between the listener and the speaker in which it is possible to negotiate for meaning and ask for clarifications when comprehension problems occur. The current study focuses specifically on unidirectional listening within the L2 paradigm. Although a number of researchers (e.g., Long, 1983a, b, 1985, 1996; Pica, Young, & Doughty, 1987) have argued that bidirectional listening is more beneficial to L2 acquisition since the learners can benefit from processes such as negotiation of meaning and recast, unidirectional listening is still perhaps the predominant type of listening that many L2 learners experience due to factors such as large class sizes which limit L2 learners’ opportunities to interact with more competent users (e.g., teachers) of the target language. Unidirectional listening also remains the dominant format in which L2 learners’ listening proficiency is measured. Therefore, this type of listening remains an area worth researching, especially within the L2 context.
Listening, like reading, is a route to access meaning and considered a receptive skill. Reading involves the interactive processing of visual, phonological and semantic information (Lupker, 2007). Listening is different from reading on numerous levels, one of which is that typically it does not involve the processing of orthographic information and hence visual information is not necessarily implicated in listening processes①. There are a number of features that are unique to listening that arise out of this modality difference, including the fact that: (ⅰ) aural text exists in time (not in space), and results in the comparatively fleeting nature of the information extracted from the listening process; (ⅱ) the listener typically has no control of the pace of the text; and (ⅲ) spoken texts usually include intonation, stress, accents, background noise and other variations of acoustic features which can affect the ways in which the listener both processes the text and the extent to which s/he can extract meaning from aural text (Lund, 1991; Macaroetal., 2007).
Both linguistic and non-linguistic knowledge are implicated in the comprehension of aural text, (Buck, 2001) and researchers have argued that different processing skills are invoked in the activation of these different knowledge sources. For example, in top-down processing, incoming aural input is related to and interpreted through the listener’s activated schema or pre-existing world knowledge. In other words, the listener’s schema is like a lens through which the listener infers meaning and makes sense of the text. As Field (2004) suggests, “in a top-down process, larger units exercise an influence over the way in which smaller ones are perceived” (p. 364), in which larger units refer to the listener’s schema while smaller units refer to the different linguistic elements (e.g., vocabulary items) in the aural input. This type of processing is seen as more listener-driven in nature as comprehension depends relatively less on effective decoding of linguistic data in the incoming aural input and comparatively more on the listener’s use of context and prior knowledge.
With bottom-up processes, on the other hand, comprehension of incoming aural data relies on successful decoding of the aural text’s various linguistic units (e.g., lexical, syntactical and phonological), which will then enable the sequential process of building up a linguistic representation of the text from which to extract meaning. In this sense, bottom-up processing is more text and linguistically driven than top-down processing.
Top-down processing could not assist comprehension without some degree of bottom-up processing being engaged first to process linguistic information (bottom-up processing) in the incoming aural input that in turn activates the learners’ schema (Field, 2004). For instance, without first identifying words such as “rainy”, or “windy” in the incoming aural input, it would be impossible for the listeners to activate their world knowledge and assume that the text may be about weather. Therefore, the main difference between top-down and bottom-up processing should be perceived in light of which type of knowledge is beingdominantlyapplied to make sense of the incoming aural information. In top-down processing, schema gains dominance while in bottom-up processing, the listeners’ linguistic knowledge is utilized more. Therefore, when a listener processes information in a top-down manner, it is not the case that bottom-up processing is irrelevant, but rather, top-down processes are being utilized to a greater extent to extract meaning from the text.
Given that listening tasks are “online” tasks and that listeners usually have less control over the pace in which a listening text is presented, it is to the advantage of listeners to have the ability to shift from one mode of processing to another in response to different situations. Therefore, ideally, top-down and bottom up processing should be used in an interactive and compensatory manner (Stanovich, 1980). For instance, when L2 listeners are presented with a linguistically challenging text, listeners may process the text in a more top-down dominated manner in order to compensate for their inadequate linguistic knowledge. On the other hand, when faced with a text with which they have little background knowledge, they may need to rely more on their bottom-up processing skills to make sense of the text. Moreover, apart from being compensatory, the interactive use of top-down and bottom-up processing could also have confirmatory value. Graham and Macaro (2008) argue that “the interaction of top-down and bottom-up processes is likely to be both compensatory and confirmatory” (p.749). In other words, the listener’s developing schema (top-down processing) must be constantly checked against textual evidence obtained through bottom-up processing to prevent wild guessing, especially when the schema activated by the initial input is contradicted by the subsequent ones.
A number of studies investigating listening comprehension were primarily interested in fleshing out how proficient and less-proficient listeners process aural texts, especially which type of processing, bottom-up or top-down, differentiates proficient ones from less-proficient ones. For example, O’Malleyetal. (1989) conducted a qualitative study of 11 high school students in America who were learning English as a second language. They were categorized as effective or less-effective listeners according to their performance on a standardized reading test of functional vocabulary and their teachers’ perception of their proficiency. Three aural texts were presented to the participants who were required to verbalize (think-aloud) what they had been thinking while listening to a tape of oral discourse. O’Malleyetal. (1989) found that proficient listeners “tended to relate new information to prior knowledge” (p. 432) while less-proficient ones were inclined to process the aural text in a bottom-up fashion as they were “embedded in determining the meanings of individual words” (p. 434). They concluded, therefore, that effective top-down processing is a hallmark of proficient listeners. However, apart from the small number of participants involved, participants were categorized into effective and less effective listeners based on their scores in a reading test. Therefore, whether the participants categorized as effective listeners in this study were truly effective listeners is debatable.
With a significantly larger number of participants and using a different method, a quantitative study conducted by Tsui and Fullilove (1998) yielded quite different results from O’Malleyetal. (1989). Tsui and Fullilove (1998) examined the performance of approximately 20,000 students in a public listening examination in Hong Kong. The listening items were categorized according to schema and question type. Non-matching schema type items and global questions are those that require effective (rapid and accurate) bottom-up processing skills since the schema activated by the initial linguistic input may be refuted by the subsequent input in these types of items and questions. Therefore, listeners “need to be able to pick up the incoming linguistic cues to constantly check against their developing schema to see whether the schema is confirmed or refuted” (Tsui & Fullilove, 1998, p. 438). Matching schema type items and local questions, on the other hand, do not have conflicting linguistic cues and only require listeners to pick up specific information. Therefore, “candidates could rely on top-down processing to get the correct answer” (p. 432), even if their bottom-up processing skills were underdeveloped. In contrast to O’Malleyetal.’s (1989) findings, Tsui and Fullilove (1998) found that participants who obtained high scores in the test (more proficient listeners) were those who consistently performed well in non-matching schema type listening items, suggesting that they possessed effective bottom-up processing skills. Performance of less-proficient listeners on non-matching schema type items was consistently and clearly inferior to that of proficient listeners. As for matching schema type items, there was no significant difference in performance between the proficient and less-proficient listeners, suggesting that the less-proficient listeners were, surprisingly, able to utilize top-down processing skills to tackle such questions. These findings suggest that effective bottom-up processing was clearly the stronger discriminator of listening performance that differentiates more proficient from the less proficient listeners. In light of this, the role that top-down processing plays in successful listening should not be overestimated and overemphasized, nor should the ability to process information in a top-down fashion be considered as the absolute defining attribute of proficient listeners, as O’Malleyetal. (1989) appear to suggest.
Although the issue of linguistic knowledge was not directly addressed in the Tsui and Fullilove (1998) study, their findings nevertheless points to the possibility that L2 listeners’ linguistic knowledge could be a more important factor than being able to use world knowledge in determining listening success, since bottom-up processing involves the application of the listeners’ linguistic knowledge to make sense of the aural input (Rost, 2002). Indeed research by Mecartty (2000) and Vandergrift (2007) confirms this suggestion. Andringa, Olsthoorn, van Beuningen, Schoonen and Hulstijn (2012) also indicate that effective L2 listening is determined by both the extent of a learners’ L2 linguistic knowledge together with their skills in applying this knowledge. Their study took an individual differences approach in an attempt to explain the componential structure of listening skills in native (NS) and non-native speakers (NNS) of Dutch. These speakers participated in a range of different tasks including discourse comprehension, vocabulary, semantic and grammatical processing, segmentation, word monitoring and self-paced listening tasks. Andringaetal. also included a working memory measure and a measure of nonverbal IQ. The purpose of these tasks was to identify the strength of different predictor variables in determining listening performance. Perhaps not surprisingly they found differences between the NS and NNS speakers in terms of which variables were significant predictors of listening comprehension. However, for both groups “knowledge of language” was the most powerful predictor confirming previous research. Processing speed was also a very significant variable in predicting variance on the discourse comprehension tasks. Therefore, knowledge of linguistic information, together with speed of processing that knowledge are two highly significant variables in determining success in listening comprehension. Most interestingly, the working memory task used in Andringaetal. (2012) did not emerge as a significant predictor variable of discourse comprehension, a finding which contradicts some previous research. Andringaetal. argue this is due to the fact that working memory is experience-based and inextricably associated with linguistic knowledge and processing speed. If the NNSs’ working memory is not a reflection of their experience of the Dutch language, then it would not emerge as an important predictor in listening. Andringaetal. is a methodologically rigorous study that clearly demonstrates the importance of linguistic knowledge (more “bottom up”) in listening comprehension.
InvestigatingtheRelationshipbetweenLinguistic
KnowledgeandListeningPerformance
Lexical and grammatical knowledge have been recognized as important for listening comprehension (Call, 1985; Rost, 1990; Mecartty, 2000; Andringaetal., 2012). In Mecartty’s (2000) study, word-association and word-antonym tasks were administered to measure lexical knowledge in college-level learners of Spanish. Their grammatical knowledge was measured by a multiple-choice sentence-completion task and a grammaticality judgment task. While there was no difference between the listening and reading groups in terms of lexical and grammatical knowledge, lexical knowledge explained a larger proportion of variance in reading (25%) than listening (17%). In addition, while lexical knowledge was a significant predictor of both reading and listening performance (albeit to a lesser degree in listening), grammatical knowledge was not a predictor of either reading or listening performance. Andringaetal. (2012) explain the different results in their study relative to Mecarrty’s (2000) as being due to the significant methodological differences across the two studies, including the different ways in which both studies measured grammatical knowledge. In Mecarrty’s study, grammatical knowledge was measured through visually presented production tasks (sentence completion and grammaticality judgment). Andringaetal.’s (2012) measurements of grammatical knowledge are likely to be more relevant to listening tasks since participantsheardthe beginning sentence fragments of Dutch sentences and the participants’ task was to judge whether these fragments were legitimate or not. The predictive power of grammatical knowledge to listening skill was weak in Mecarrty and strong in Andringaetal. If this contrast is indeed attributable to methodological differences as suggested in Andrigaetal., then this constitutes further evidence that the modality in which different constructs are assessed can have a pronounced impact on the results.
Other researchers have focused on the effect of lexical knowledge on listening comprehension. For example, Staehr (2008, 2009) conducted research that attempted to clarify the relationship between vocabulary size and performance in listening, reading and writing. In Staehr (2008), 88 adolescent Danish learners of English were given the Vocabulary Levels Test (VLT), together with tests of reading comprehension, listening and writing. Vocabulary size correlated significantly with the participants’ performance in the reading, writing and listening tests, and while lexical knowledge accounted for 72% of the variance in reading and 52% in writing, such knowledge could only explain 39% of the variance in listening. In Staehr (2009), measures of both breadth (VLT) and depth (word associates test) of vocabulary were examined as predictors of listening performance. Both measures combined explained 51% of the variance in listening scores, the VLT scores (argued to be a measure of breadth) by itself explained 49% of the variance in listening scores, however the word associates measure only contributed an additional 2% of the variance suggesting so-called depth of vocabulary (as measured by the word associates task) does not contribute as much as breadth to performance in listening tasks.
Lexical knowledge emerges as a strong predictor of performance in reading and writing but the extent to which vocabulary predicts listening performance has been less consistently observed in the literature. As Mecartty (2000) concludes in her study, “lexical knowledge appears to be more crucial for reading than it is for listening comprehension” (p. 338). This inconsistency in the literature begs the question as to why lexical knowledge would be a stronger predictor of reading compared to listening performance. There are a number of possibilities, including the fact that knowledge of words includes orthographic information. One cannot read if one cannot decode the grapheme-phoneme correspondences, hence orthographic knowledge is a critical dimension in reading but arguably less relevant in listening (particularly listening tasks which are not supported by any accompanying text). Another more methodological possibility is that the significant majority of studies investigating these relationships measure knowledge of words through the visual modality. Therefore, the role of lexical knowledge in listening comprehension might have been underestimated.
PhonologicalKnowledgeofWords
A number of studies suggest thatinadequateorinaccuratephonological knowledge of words may hinder L2 learners’ listening performance. Goh (2000) conducted a study that explored the listening difficulties encountered by Chinese students of English in Singapore. A number of methods were used such as group interviews, immediate retrospective verbalization procedures and asking the participants to keep a journal record of their listening difficulties. One of the most frequently reported difficulties encountered by the participants wasnotrecognizingwordstheyknow, reported by 22 out of 40 participants. Many of the participants reported that they were able to recognize the words in their written form but not when they were presented aurally. Goh (2000) attributed this problem to theunderdevelopedlisteningvocabularyof the participants and suggested that their knowledge of the phonological representation of words was inadequate or inaccurate. This finding was clearly illustrated by the comment made by a participant in a group interview in which she remarked that “Ah, last time when someone mentioned ‘benign’ in the class, I didn’t react to it very quickly because I always pronounce it as ‘bening’ for many years” (Goh, 2000, p. 62).
Another study that points to the importance of knowing the phonological representations of words in listening was conducted by Chang (2007). This study investigated the impact of vocabulary preparation on listening comprehension. Taiwanese college students were compared across three different conditions. Group 1 were given one week to study a vocabulary list which contained 25 items. They were informed that these items would appear in the listening test that they would need to take later. Although given the same vocabulary list, group 2 was only given one day to study the words. Participants in group 3 received the least amount of preparation time, receiving the vocabulary list only 30 minutes prior to the study. Somewhat counter-intuitively, there was no significant difference between the three groups in terms of their listening comprehension scores (Group 1: 59%, Group 2: 56%, Group 3: 54%), despite the fact that the preparation time given to them varied considerably. Chang (2007) attributed this surprising result to the fact that students in group 1 and 2, while given more preparation time, spent most of their time remembering the written form of the words given to them, as revealed by the post-test questionnaire, in which over 70% of the participants in both groups expressed that they had problems matching the visual form of the words in the list with their aural form in the aural text. In comparison, only 39% of the participants in group 3 reported having such problems. During the 30-minute preparation time, learners in group 3 formed groups to study the words and tried to seek help from one another about the words’ pronunciation. Chang (2007) speculated that this might be the reason why group 3, despite having the least preparation time, did not perform significantly worse than the two other groups.
The notion that modality effects might impact on listening comprehension is supported by Sydorenko (2010) and Winke, Gass and Sydorenko (2010), studies which have both demonstrated modality effects in comprehension. In both of these studies, NNSs were asked to watch videos with and without captioning. In both studies NNSs had higher comprehension and (aural) vocabulary scores when watching videos with captioning, argued to be due to the fact that the captioning caught the students’ attention. Thus, unlike the participants in groups 1 and 2 of Chang’s (2007) study, the participants in Sydorennko (2010) and Winkeetal. (2010) did not need to spend time trying to match aural representations of words on to visual ones since the captioning provided this information for the learners and yielded higher scores on comprehension and vocabulary.
These studies suggest that there may be a gap between an L2 learner’s visual and aural knowledge of words. Therefore, using data about lexis obtained from the visual modality to predict learners’ performance in listening (aural modality) could be inaccurate, or at least, less accurate, and could potentially obfuscate findings (c.f. the difference between Mecarrty [2000] and Andringaetal. [2012] could be due in part to modality differences). This modality measurement problem is relevant to all the current studies available that have looked into the relationship between lexical knowledge and listening performance. We know that modality can have an impact on how participants’ respond on a range of different linguistic tasks. Murphy (1997) showed that modality impacted on L2 learners’ ability to judge the grammaticality of sentences with violations of subjacency (believed to be a principle of Universal Grammar) in wh-questions. Participants in both the aural and visual groups were exposed to the same stimuli for the same amount of time, which controlled for the time spent processing the sentences in each task. The participants were significantly less accurate at judging the ungrammatical items in the aural than in the visual modality. Moreover, modality had a significant effect on the participants’ response time as the participants in the aural group also responded significantly slower than those in the visual condition. Therefore, it is possible that employing a visual measure of vocabulary size to predict L2 listening performance could offer a less accurate depiction of how lexical knowledge affects listening.
This possibility is confirmed in the study by Milton and Hopkins (2007), who compared vocabulary knowledge in Greek and Arabic learners of English in an aural and visual test. Milton and Hopkins used the X Lex measure, a computer-based program which estimates a learner’s vocabulary size visually by asking them to indicate whether they know a word presented to them on screen. Both real English words and pseudo-words designed to look and sound like English words are included in this test. In addition to using the X Lex, an aural measure of learners’ vocabulary was used. The Aural Lex, is designed to imitate the X Lex in every respect except that the words were presented aurally. In their study, the visually measured vocabulary size of the Greek learners was significantly higher than their aurally measured one. For the Arabic learners, there was no significant difference between their visually and aurally measured vocabulary sizes. Moreover, it was also revealed that there was a greater tendency in both groups (Greek and Arabic) to identify pseudo-words as real ones in the Aural Lex. This evidence, similar to Murphy’s (1997) study, demonstrates that differences in the modality of presentation has an effect on the participants’ performance in the task.
In light of the above discussion, the study reported below was designed to directly investigate aural vs. visually measured lexical knowledge and its relationship to a listening task.
METHODOLOGY
ResearchDesign
The explanatory variables in this study are the visually and aurally measured vocabulary size of the participants and the response variables are their performance in different types of IELTS listening items (direct and indirect questions). This study was designed to address the following research questions:
(1) Does visually measured vocabulary size (X Lex score) differ significantly from aurally measured vocabulary size (Aural Lex)?
(2) Which vocabulary size measure (visual or aural) is a stronger predictor of performance in the IELTS listening test?
(3) Is there a significant difference between the high aural vocabulary score (HAVS) group and the low aural vocabulary score (LAVS) group in terms of their overall IELTS listening score?
(4) Does question type (direct vs indirect questions) affect the participant’s accuracy rate?
(5) Is there a significant difference between the performance of the HAVS and LAVS group in Direct and Indirect IELTS questions?
Participants
51 students (41 females and 10 males) from a vocational institute in Hong Kong took part in this study. All the participants were over 18 years of age and were learning English as a second language. They were all higher diploma students majoring in a number of subjects such as Fashion Design, Fashion Retailing and Computing where the medium of instruction was mainly Chinese (Cantonese). However, they were also required to take a number of compulsory vocational English courses aimed to develop students’ ability to use English in the workplace and consequently focus on areas such as business writing, making business presentations and conducting meetings. All participants received 2 hours of instruction in English each week.
The participants’ English proficiency varied. Some (N=21) passed the Hong Kong Advance Level (HKAL) Use of English examination, a public examination intended for form 7 students (grade 13), which, according to the Hong Kong Examinations and Assessment Authority (HKEAA), reflects an English proficiency between band 5 and 6 in the IELTS banding system. In contrast, a number of participants (N=6) had failed in the Hong Kong Certificate of Education (HKCEE) English Language examination intended for form 5 students (grade 11), suggesting their English standard is likely to be well below band 4 in the IELTS banding system.
ResearchInstruments
VisualMeasureofVocabularySize:TheXLex
Developed by Meara and Milton (2003), the X Lex estimates a learners’ knowledge of the most frequently occurring 5000 words in English and derives its lemmatized word list from Hindmarsh (1980) and Xue and Nation (1984). It is a computer-based test that requires the participants to indicate whether they know a particular word that is shown on the computer screen by pressing the corresponding on-screen buttons provided. Learners are presented with 20 randomly selected words from each 1000 word frequency band of the 5000 most frequently occurring words in English, resulting in 100 words being shown. The number of words that a learner indicates as known words is then multiplied by 50, generating the raw score (the highest raw score is 5000). In addition to the 100 words, 20 pseudo words, designed to look and sound like words in English, are also presented to the learners. These items are included to counter the effect of guesswork. The number of pseudo words that a participant claims to know is multiplied by 250 and subsequently deducted from the raw score, resulting in the final adjusted score.
AuralMeasureofVocabularySize:TheAuralLex
The Aural Lex, developed by Milton and Hopkins (2005), was designed to be identical to the X Lex in every possible respect (e.g. the same number of words, the same testing and scoring principles), except that the words are not shown on the computer screen but presented aurally. Learners press an on-screen button to hear the words through earphones. Each word can be heard as many times as required by the listener before they decide whether they know the words. Therefore, the major difference between the X Lex and the Aural Lex is the modality of the presentation of the vocabulary items—visual or aural.
MeasureofListeningPerformance:TheIELTSListeningTest
The IELTS (International English Language Testing System) listening test was chosen to measure the participants’ listening skills. The IELTS assesses the English language ability of learners in four areas: listening, reading, speaking and writing. It is taken by a large number of candidates all over the world each year and the qualification obtained is widely recognized by tertiary institutions in a substantial number of countries as an index of English language ability.
An IELTS listening test consists of 40 items divided into 4 sections. The entire test lasts for approximately 30 minutes. Since the test is administered all over the world, there are inevitably different parallel versions of the listening test in existence at any one point. Nevertheless, since the tests are verified, there should be a degree of consistency in difficulty among the different versions. As a result, Listening Test 1 in the sixth collection of practice tests for IELTS published by the Cambridge University Press was used. In this study, the 40 listening items in the chosen version of the test were further categorized into INDIRECT items (N=27) and DIRECT items (N=13).
Indirect Items
Some of the scripts in the IELTS listening test include distractors to ensure that listeners process and evaluate all the surrounding linguistic cues in the speech stream in order to deduce the correct answers. Indirect items are operationalized here as those in which the correct answers are more indirectly presented in the aural text or where the correct answer is one of a possible set of choices the listener could make. The following figure is an example of an indirect item.
Example1
Question: What is the starting time of the play?
Tapescript: We are experimenting a bit with the time the curtain goes up. We used to start all our performances at 7:30 but that made it difficult for people to go home by public transport, so instead, we are beginning at 7:00 because at 9:45, when it finishes, there are still buses running.
Answer: 7 pm
In the above example, the correct answer, 7:00, and while this is clearly stated, a number of possible options (distractors) were also mentioned: 7:30 and 9:45. Listeners identify the correct answer by processing all the other surrounding cues such as ‘used to’, which indicates that starting at 7:30 was an old practice and ‘finishes’ which indicates that 9:45 is also not the correct answer. For this type of question, simply looking out for any mention of time is inadequate to arrive at the correct answer since three different times were mentioned in the tape script.
Figure1 Sample of an Indirect Item
Direct Items
Direct items are operationalized here as those questions where it is not crucial for the listeners to process all the surrounding linguistic cues in order to deduce the correct answer and distinguish it from possible distractors (as there are none). Direct items are those in which the correct answers are presented directly and explicitly in the aural text. The following is an example of a direct item in the IELTS listening test.
Example2
Question: What is the cost of classes for silver membership scheme
Tapescript:
Enquirer: What’s the next type of membership?
Receptionist: Well, that’s silver. It’s the same as gold, except you have to pay a small fee of 1poundper lesson and you can only use the centre at certain times.
Answer: 1 pound
The answer is given directly and explicitly in the second sentence. There is no other distracting information presented. The extent to which learners are able to process the other pieces of information is less important in arriving at the correct answer.
Figure2 Sample of a Direct Item
INDIRECT questions are arguably more demanding than DIRECT questions since the former requires the processing of a larger amount of aural information in order to deduce the correct answers. For the purposes of our study, the IELTS listening items were divided into DIRECT and INDIRECT items (as described above) to evaluate the effect of different aural vocabulary sizes (High Aural Vocabulary Size (HAVS) versus Low Aural Vocabulary Size (LAVS)) on different types of listening items.
Procedure
Permission to carry out the study was sought and granted at the targeted school at which the second author had personal connections, hence this school was recruited through a convenience sampling procedure. 4 classes were identified to take part in the study on the grounds that the students in these classes were sufficiently motivated and that participating in the research would not interfere with their studies. The data collection was conducted over one school week (four data collection sessions in total).
All materials were pilot tested on a similar group of students who did not form part of the final sample to ensure that the assessments were appropriate for these students. The tests were conducted in a language laboratory equipped with computers and headsets, necessary for the X Lex and the Aural Lex to be administered. Each data collection session lasted for 1 hour (including the X Lex, Aural Lex and the IELTS listening test). For the purpose of counterbalancing, the classes completed the tests in the sequences shown in Table 1.

Table 1 Sequences in Which the Participants Took the Tests
Participants were provided with information about the tests (e.g. which buttons to press to indicate knowledge of a word, how to fill in their scores on the test cover sheet) and given opportunities to ask questions. When completing the X Lex and Aural Lex, no time limit was imposed but it was observed that almost all the participants are able to finish each test within 15 minutes. For the IELTS test, all the instructions and examples were given through the tape script. The whole test took approximately 30 minutes.
RESULTS
The scores for both the X Lex and Aural Lex, and the IELTS tests were checked for normality through the application of the Kolmogorov-Smirnov test. The test of normality did not reach significance (p<.05) for either of the 3 dependent measures and therefore, they could all be considered as normally distributed. In light of this, parametric tests were carried out.
The means and standard deviations obtained from the X Lex, Aural Lex and the IELTS listening test are presented in Table 2.

Table 2 Means and Standard Deviations of the Scores on the X Lex, Aural Lex and the IELTS Listening Test
A related samples t-test was carried out to determine whether the participants’ visually vs. aurally measured vocabulary scores differed, revealing that the visually measured vocabulary score (X Lex) was significantly higher than their aurally measured vocabulary score (Aural Lex) where t(50)=14.126, p<.001.
A Pearson’s correlation coefficient analysis determined that the X Lex and Aural Lex scores were associated with the IELTS listening test, as shown in Table 3.

Table 3 Correlations between the X Lex, Aural Lex and IELTS Tests
**=p<.001
Table 3 shows that both X Lex and Aural Lex scores were significantly and positively correlated to performance in IELTS listening (p<.001).
Next a regression analysis was carried out to determine whether the vocabulary size measures (X Lex and Aural Lex) predict performance on the IELTS. Table 4 summarizes the results obtained from this analysis.

Table 4 Regression Analysis between Vocabulary Size (Predictors) and IELTS Listening Test Score (Predicted)
Note R2=.54 for Step 1; change in R2=.02 for Step 2. *p<.05
Table 4 illustrates that only aurally measured vocabulary scores (Aural Lex) reliably explain variance in the IELTS listening test (p<.05). Therefore, the prediction, that aurally measured vocabulary size is a stronger predictor of listening performance in the IELTS than visually measured vocabulary, is confirmed.
Research question 3 aimed at finding out if there is a difference between the overall IELTS scores of participants who obtained higher scores in the Aural Lex and those who obtained relatively lower scores. To that end, the top 25% of participants (N=13) achieving the highest scores in the Aural Lex were operationalised as the HAVS (High Aural Vocabulary Score) group while the bottom 25% (N=13) were operationalized as the LAVS (Low Aural Vocabulary Score) group. As this determination was somewhat arbitrary, the mean Aural Lex score in the HAVS vs. LAVS group were compared and found to be statistically different (independent samples t-test), confirming the categorization into high and low aural vocabulary groups [Mean of the LAVS=1453.85, SE=64.91; Mean of the HAVS=3265.39, SE=100.54, p<.001]. Having confirmed that the two groups were indeed significantly different in their Aural Lex scores another independent t-test was conducted to see if the overall IELTS scores of the two groups (HAVS and LAVS) differed. The HAVS group obtained higher scores (M=25.00, SE=3.60) on the IELTS listening test than the LAVS group (M=14.08, SE=1.00) where t(24)=-7.39, p<.001.
Research question 4 asked whether question type (direct and indirect questions) in the IELTS had an impact on the participant’s accuracy rate. Similarly, research question 5 asked whether performance on direct and indirect questions would be different depending on whether the participant had a high or low Aural Lex score. To address these questions, a mixed ANOVA was conducted with one between-group factor: Group (HAVS/LAVS) and one within-groups factor: Question (Direct/Indirect). There was a reliable main effect of question type (F(1, 24)=33.674; p<.001), where the participants are more accurate in direct (M=60.65, SE=3.05) than indirect questions (M=43.73, SE=1.83). There was also a reliable main effect of group (F(1, 24)=50.142; p<.001). In addition, these two variables interacted where F(1, 24)=7.99; p<0.009. This interaction is illustrated in Figure 3.
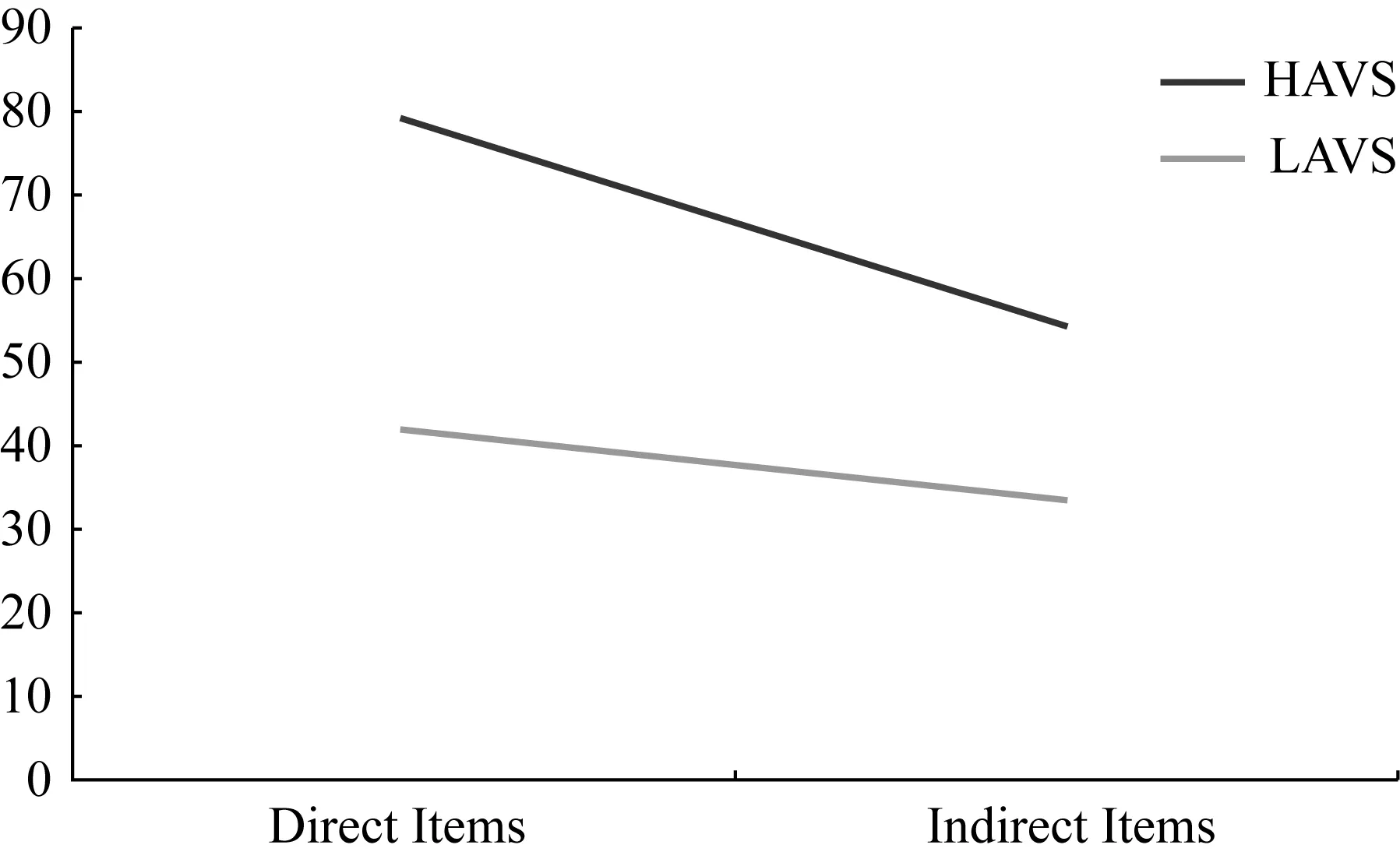
Figure 3 Interaction between Question Type and Group
Figure 3 illustrates that the HAVS group significantly outperformed the LAVS in both Direct (t(24)=-6.11, p>.001) and Indirect (t(24)=-5.67, p>.001) questions. The source of the interaction comes from the fact that the size of the effect is smaller at the level of Indirect Question than Direct items.
In light of the above analyses, the prediction that the HAVS group would outperform the LAVS group in Indirect questions was confirmed. The prediction that there would be no significant difference between the two groups in Direct Questions, however, was rejected.
In summary, participants in this study did manifest different visual vs. aural vocabulary size as measured by the X Lex and Aural Lex respectively. Participants’ vocabulary size scores did correlate with the IELTS listening test score, but only the Aural Lex measure significantly predicted variability on the IELTS Listening Test. When participants were categorized into high vs. low aural vocabulary size groupings, the participants with the higher aural vocabulary size had correspondingly higher scores on both direct and indirect question types on the IELTS listening test.
DISCUSSION
In this study the participants’ visually measured vocabulary size yields a higher score than when their vocabulary size is measured aurally. This finding corroborates Milton and Hopkins (2007) and provides further evidence that an L2 learner’s vocabulary size estimates will differ depending upon the modality in which the measure is carried out (as in Murphy, 1997 in measures of syntax). The correlation and multiple regression analyses revealed that aurally measured lexical knowledge (Aural Lex) is a stronger predictor of listening performance than visually measured ones (X Lex). This finding lends support to the argument that cross-modal relationships between vocabulary size (visual) and listening (aural) tests may not be the best index of the relationship between vocabulary knowledge and listening performance and could result in the importance of lexical knowledge in listening being underestimated in some studies.
It was somewhat surprising that the X Lex did not significantly predict performance on the IELTS test since previous work has suggested that even visually measured vocabulary size estimates do predict listening comprehension performance to some degree (e.g., Staehr, 2009). It is difficult to be able to explain this result based on the current findings but this discrepancy with previous research might be attributable to differences in the measures used. For example, Staehr’s (2009) study, which showed a clear relationship between visually measured vocabulary knowledge and listening skill, unlike ours, used different measures of vocabulary knowledge (VLT and word associates test) as well as a different measures of listening performance. However, if results vary so considerably as a function of different measurements there is a problem; either the measures are at fault or the hypothesized constructs argued to underlie the tasks are incorrect. In this case, it is most likely to be a measurement problem—similar to the measurement differences that resulted in different findings in Mecarrty (2000) and Andringaetal. (2012).
Another reason for the lack of relationship between the X Lex and listening in this study might be found in looking at the context of L2 learning for the particular sample recruited in this study. The medium of instruction (MOI) of the school from which these participants were recruited is predominantly Chinese (Cantonese), in which all but one of their subjects related to the students’ majors were taught in their L1. However, while classroom interactions are mainly in Chinese, lecture notes, which the students rely on heavily for revision and completion of assignments, are primarily in English. Therefore, there is a mismatch between the language of the aural input (Cantonese) and the language of the visual input (English) that the learners receive in this context. This dissonance could have an effect on the development of the learners’ phonological knowledge of the words in L2 as there is little reinforcement between the aural and visual input they receive. In fact, such a practice is not uncommon in Hong Kong. Hoare (2008) conducted a series of class observations among Hong Kong secondary schools to observe the teachers’ use of English in lessons. He found that it is common for many teachers to conduct their lessons completely in Cantonese while giving their students notes that are primarily in English.
In addition, the primary ways the students’ learning outcomes are assessed could also possibly help explain the participants’ smaller aural vocabulary size in this study. Learners in the participating school are mainly assessed through written English, in which they are usually required to submit group reports, individual essays and sit for written examinations in English while other assessment formats such as presentations, which will inevitably require more attention to the aural form of words, are used comparatively less frequently. In other words, the participants are primarily required to express their learning outcomes visually (in writing) in their L2 and such a practice may lead to more attention being given to consolidating their knowledge of the visual features of words as they are more relevant to their success in assessments. Thus thelearningcontext(e.g. teaching and learning practice) is likely to be influential in shaping the type of lexical knowledge that L2 learners develop, leading to one type of lexical knowledge (e.g. visual knowledge) being more developed than another (e.g. aural knowledge). Therefore, perhaps for these particular learners where there was a large discrepancy between information presented visually vs. aurally, only those words that had strong enough phonological representations in the mental lexicon (i.e., had been learned aurally as well as visually) were shown to be in a positive relationship with listening skill. Of course, this explanation is purely speculative at present, but it is worth investigating more closely the relationship between the nature of the L2 input/tasks and outcomes such as these.
Participants were significantly more accurate on direct than indirect items. This finding confirms the prediction that indirect questions, which require participants to process and evaluate all the surrounding linguistic information in order to deduce the correct answers from the distractors, would be more challenging than direct questions. This result is also consistent with Tsui and Fullilove (1998) in which listening items that required effective bottom-up processing skills (global and non-matching schema type items) were found to be generally more challenging than those items which could be answered in a top-down manner (local and matching schema type items).
Participants with higher aural vocabulary size scores in turn had higher scores on both direct and indirect question types than those with lower aural vocabulary scores. We thought this was somewhat surprising as we had expected that direct questions would be accessible to all learners, even those with lower aural vocabularies. However, we also note that there might have been some aspects that were overlooked in our initial categorization of question types. IELTS listening items were categorized as direct when the answers were presented in the aural text without the presence of distractors and which therefore did not require the participants to process all the surrounding linguistic information. However, in light of the HAVS vs LAVS group differences on the direct question types all the direct listening items were reanalyzed. Although they all fit the previous criteria set for being categorized as direct questions (e.g. no distractor, answers presented directly), some of the direct items were also found to contain low frequency vocabulary items that might have affected the listeners’ performance. An example of this is item 23, which required the participants to write down the type of facility that a college provides to its students.
Brian:Whataboutfacilitiesforyoungchildren?I’dliketobringmydaughterherewhileI’mstudying.Tutor:Howoldisshe?Brian:Three.Tutor:Thensheiseligibletojointhenursery,whichissupervisedbyaqualifiednurserynurse.Thewaitinglistisquitelongsoyououghttoapplynow.
Among 51 participants involved in this study, only 20% (N=11) managed to get the correct answer. The answer to the above item isnursery, which was presented directly without any other distractors. The poor performance on this item could be due to the fact that the wordnurseryis likely to be an uncommon word for the participants in our sample since in Hong Kong, the provision of nursery is not a common practice and the relatively younger age of the participants in this study might mean that they were not particularly aware of such a service. In addition, a closer look at the data reveals that among those who answered item 23 correctly (N=11), none belongs to the LAVS group (bottom 13 in terms of Aural Lex scores) while 5 belong to the HAVS group (top-13 in terms of Aural Lex scores) and 4 belong to the top 20. Therefore, it is possible that the presence of low frequency words such asnurserycould affect the difficulty of some of the items that were initially categorized as direct ones in this study, making them biased towards participants with higher aural lexical knowledge. Table 5 shows the accuracy rate of HAVS and LAVS group in the direct items (N=13).
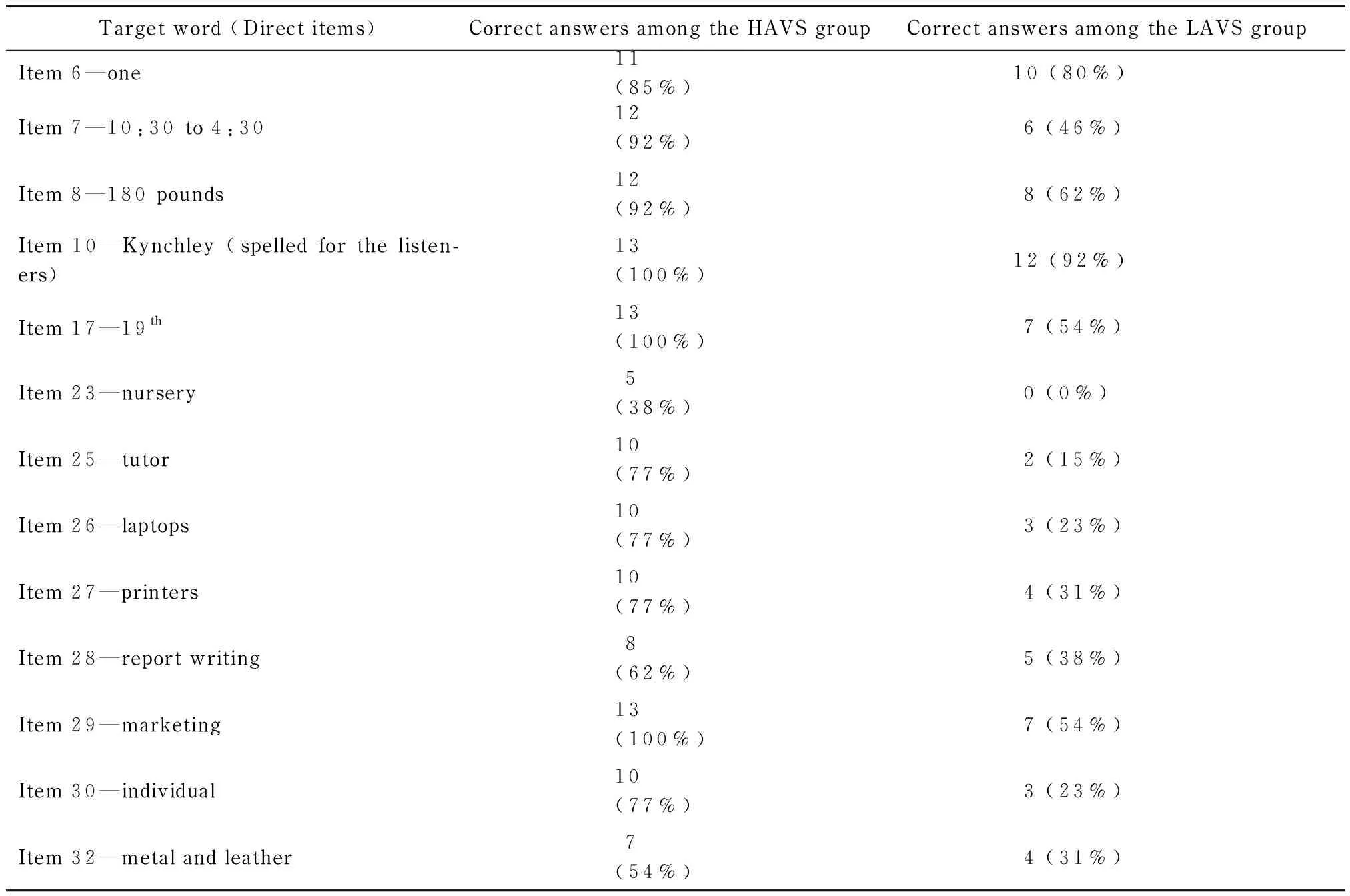
Table 5 Accuracy Rate of the HAVS and LAVS Groups in Direct Items
From Table 5, it is clear that the gap between HAVS and LAVS group is more pronounced in some items (e.g. item 25, 26, 27, 30) than others (e.g. item 6, 8, 10, 32). It is possible that the frequency of the target words may have had an effect on the accuracy rate of the LAVS group even for direct items. The HAVS group, because of their higher aural lexical knowledge, are probably more resistant to differences in word frequency in the aural input while the LAVS group would be more sensitive to such a change. Therefore, in light of the above, an implication that could be derived is that for the LAVS group to be able to perform on par with the HAVS group in direct questions, a certain threshold in aural vocabulary knowledge might have to be reached. The significantly lower Aural Lex scores of the LAVS group points to the possibility that such a hypothesized threshold has not yet been reached.
The results of our study also found that as predicted the HAVS group outperformed the LAVS group in the more challenging indirect items, suggesting that aural knowledge of words may affect L2 listeners’ performance in listening items that contain distracting information.
These results taken together suggest then that there are distinct observable differences between aurally and visually measured vocabulary knowledge that seems to have different degrees of association with listening skill. Why might this be so? If, as is widely accepted, entries in the mental lexicon include visual, phonological, orthographic and semantic features of words, then why would we see such observable differences in how well visual vs. aural vocabulary predicts listening skill? The answer may lie in the discussion above concerning the nature of the participants’ experience with aural L2 input. The aural dimensions of the L2 words used in this study are likely to be less well developed or elaborated in the mental lexicon of our sample. Given the lack of practice that our sample had with working aurally and/or orally with English, since it was really only their written work that was carried out in English, it is very likely that they had less well-elaborated aural knowledge of L2 words. Therefore, the retrieval practice for aural L2 vocabulary would have been comparatively weak relative to visual features of words. As a result, one finds that (a) visual measures are higher than aural and (b) aural has stronger relationships with listening, since these are the critical features that are activated in carrying out listening tasks. Kang, Gollan and Pashler (2013) argue that retrieval practice produces better comprehension of L2 words, and better L2 pronunciation as well. In their study, two groups of undergraduate students studying at an American University were asked to learn 40 Hebrew nouns, a foreign language for all of their participants. These words were learned in one of two conditions: (ⅰ) a retrieval practice condition where the participants were first shown a picture and then asked to try and name it in Hebrew and (ⅱ) the imitation condition where participants were shown the pictures simultaneously with hearing the Hebrew word and participants were asked to imitate what they heard. The results of Kangetal.’s (2013) study indicated that participants in the retrieval practice condition had consistently higher scores than the imitation condition on both comprehension and production. Kangetal. argue that the benefits of the retrieval practice condition stem from the fact that the same sort of mental operations are used in retrieval practice as are relevant in L2 comprehension and production tasks and are in line with well known research indicating that cognition is context dependent—higher performance will result when the test conditions are closely aligned with the learning conditions (c.f. the “transfer-appropriate processing framework” from Morris, Bransford, & Franks, 1977). In our study, the participants would have had very few opportunities to practice their retrieval of words through the aural modality, hence they had smaller vocabulary sizes when tested aurally than visually. In that sense, participating in listening tasks is not as relevant for them as this is not the way in which they tend to learn L2 words. However, words they do know aurally (as measured by the Aural Lex) are strongly associated with their skills in English L2 listening comprehension.
Visually measured lexical knowledge has been shown to be a reliable predictor of performance in reading and writing (e.g., Koda, 1989; Laufer, 1992; Mecartty, 2000; Staehr, 2008). However, when it comes to predicting listening performance, findings from the current study indicate that aurally measured lexical knowledge is likely to be a stronger predictor than visually measured ones. As previously shown in Murphy (1997), the modality through which test items are presented impacts on test takers’ performance and therefore performance indicators obtained through a single modality might not be an accurate reflection of the relationship between different variables (vocabulary and listening in the context of our study).
One of the ways to heighten students’ awareness of the aural form of words is to introduce assessment formats in which paying attention to and processing the aural form of words is necessary. For instance, taking the participating school as an example, in addition to submitting written reports in their L2 (English), students could also be asked to deliver oral presentations of their reports to encourage them to find out the pronunciation of unfamiliar words and enhance their aural knowledge of words. In addition, helping students to come to terms with the principles behind sound production in English, such as providing them with training in phonics or phonetics would probably help learners acquire the aural forms of words more easily and would also have positive effects on their English L2 decoding (Woore, 2010). It is important to remember that the relationship between listening skill and vocabulary development is reciprocal. That is, learners can develop their knowledge of L2 vocabulary through listening activities and there are particular approaches to listening that might help learners’ access the content of aurally presented texts or discourse, which in turn will help their aural vocabulary knowledge. Field (2003), for example, argues that it is worth drawing learners’ attention to some of the challenges associated with parsing speech and advocates the use of a number of approaches aimed at helping learners perceive lexical items within aurally presented material—through lexical segmentation exercises which draw learners’ attention to the stress patterns of the language, enabling them to better identify lexical items within speech. These ideas are further supported in a more recent study by Karimi (2013) who illustrated that an intervention aimed at increasing L2 learners’ morphological awareness had a facilitative effect on their listening transcription skills. In his study, 40 Iranian pre-university students were given an English transcription task to establish a matched baseline level of transcription ability. Half of these students subsequently participated in five one-hour sessions aimed at improving English morphological awareness focusing on a range of inflectional and derivational morphemes including the plurals, -ing, -ness, -tion, and the possessives. Following from this morphological awareness intervention both groups took a second English transcription task. The group who participated in the English morphological awareness training had higher scores on the listening transcription task (i.e., made fewer errors when transcribing English text). Karimi (2013) interprets his results as establishing a relationship between morphological awareness and listening ability. These findings demonstrate that listening performance can be improved, which in turn can help bolster learners’ aural vocabulary knowledge.
While there are clear limitations to the study described here including a narrow and small sample, categorization of the IELTS questions into direct and indirect (i.e., lacking appropriate controls for word frequency), these results clearly demonstrate the need to consider the issues of measuring vocabulary size more widely, within the context of modality, in an attempt to obtain the most accurate and comprehensive measure of a learners’ vocabulary knowledge. We empirically demonstrated that vocabulary size estimates are lower when measured aurally than visually, and that aural vocabulary size measures have stronger relationships to listening performance scores than visual ones. These effects are likely to be directly attributable to the nature of the L2 input to which the learners are exposed and highlights the need for repeated opportunities for retrieval practice in developing well-elaborated lexical representations in the L2.
ACKNOWLEDGEMENTS
We would like to thank staff at the institute in which this data was collected and all the students who participated in the study and the comments of one anonymous reviewer for helpful feedback.
NOTE
1 Note, however, that listening tasks can sometimes include visual information (e.g., listening to a lecture with slides including text) and therefore in these contexts visual processes are also implicated in listening and can support listening tasks.
REFERENCES
Andringa, S., Olsthoorn, N., van Beuningen, C., Schoonen, R., & Hulstijn, J. (2012). Determinants of success in native and non-native listening comprehension: An individual differences approach.LanguageLearning, 62, 49-78.
Buck, G. (2001).Assessinglistening. Cambridge: Cambridge University Press.
Call, M. E. (1985). Auditory short-term memory, listening comprehension, and the input hypothesis.TESOLQuarterly, 19, 765-781.
Chang, A. C. S. (2007). The impact of vocabulary preparation on L2 listening comprehension, confidence and strategy use.System, 35, 534-550.
Field, J. (2003). Promoting perception: Lexical segmentation in L2 listening.ELTJournal, 57, 325-334.
Field, J. (2004). An insight into listeners’ problems: Too much bottom-up or too much top-down?System, 32, 363-377.
Goh, C.C.M. (2000). A cognitive perspective on language learners’ listening comprehension problems.System, 28, 55-75.
Graham, S. & Macaro, E. (2008). Strategy instruction in listening for lower-intermediate learners of French.LanguageLearning, 58, 747-783.
Hindmarsh, R. (1980).CambridgeEnglishlexicon. Cambridge: Cambridge University Press.
Hoare, P. & Kong, S. (2008). Late immersion in Hong Kong: Still stressed or making progress? In T. W. Fortune & D. J. Tedick (Eds.).Pathwaystomultilingualism:Evolvingperspectivesonimmersioneducation(pp. 242-263). Clevedon: Maltilingual Matters.
Kang, S. H. K., Gollan, T. H., & Pashler, H. (2013). Don’t just repeat after me: Retrieval practice is better than imitation for foreign vocabulary learning.PsychonomicBulletin&Review. Published online, 17 May, 2013. DOI 10.3758/s13423-013-0450-z
Karimi, M. N. (2013). Enhancing L2 students’ listening transcription ability through a focus on morphological awareness.JournalofPsycholinguisticResearch, 42, 451-459.
Koda, K. (1989). The effects of transferred vocabulary knowledge on the development of L2 reading proficiency.ForeignLanguageAnnals, 22, 529-540.
Laufer, B. (1992). How much lexis is necessary for reading comprehension.VocabularyandAppliedLinguistics, 3, 16-323.
Long, M. H. (1983a). Linguistic and conversational adjustments to nonnative speakers.StudiesinSecondLanguageAcquisition, 5, 177-194.
Long, M. H. (1983b). Native speaker/non-native speaker conversation and the negotiation of meaning.AppliedLinguistics, 4, 126-141.
Long, M. (1985). Input and second language acquisition theory. In S. Gass & C. Madden (Eds.),InputandSecondLanguageAcquisition(pp. 377-444). Rowley: Newbury House.
Long, M. (1996). The role of linguistic environment in second language acquisition. In W. C. Ritchie & T. Bhatia (Eds.),Handbookoflanguageacquisition:Vol. 2.SecondLanguageAcquisition(pp. 413-468). New York: Academic Press.
Lund, R. J. (1991). A comparison of second language listening and reading comprehension.ModernLanguageJournal, 75, 196-204.
Lupker, S.J. (2007). Visual word recognition: Theories and Findings. In M. Snowling & C. Hulme (Eds.),Thescienceofreading:Ahandbook. Oxford: Blackwell.
Macaro, E., Graham, S., & Vanderplank, R. (2007). A Review of Listening Strategies: Focus on sources of knowledge and success. In A.D. Cohen & E. Macaro (Eds.),Languagelearnerstrategies: 30yearsofresearchandpractice. Oxford: Oxford University Press.
Meara, P. & Milton, J. (2003).X_Lex:Swanseavocabularylevelstest(version 2.02). Wales, UK: Swansea University.
Mecartty, F. H. (2000). Lexical and grammatical knowledge in reading and listening comprehension by foreign language learners of Spanish.AppliedLanguageLearning, 11, 323-348.
Milton, J. & Hopkins, N. (2005).AuralLex. Wales: Swansea University.
Milton, J. & Hopkins, N. (2007). Comparing phonological and orthographic vocabulary size.CanadianModernLanguageReview, 63, 127-147.
Morris, C.D., Bransford, J.D., & Franks, J.J. (1977). Levels of processing versus transfer appropriate processing.JournalofVerbalLearningandVerbalBehavior, 16, 519-533.
Murphy, V. A. (1997). The effect of modality on a grammaticality judgment task.SecondLanguageResearch, 13, 34-65.
O’Malley, J. M., Chamot, A. U., & Kupper, L. (1989). Listening comprehension strategies in second language acquisition.AppliedLinguistics, 10, 418-437.
Pica, T., Young, R., & Doughty, C. (1987). The impact of interaction on comprehension.TESOLQuarterly, 21, 737-758.
Rost, M. (1990).Listeninginlanguagelearning. London & New York: Longman.
Rost, M. (2005). L2 listening. In E. Henkel (Ed),Handbookofresearchinsecondlanguageteachingandlearning. Mahwah: Erlbaum.
Stanovich, K. E. (1980). Toward an interactive-compensatory model of individual differences in the development of reading fluency.ReadingResearchQuarterly, 16, 32-71.
Sydorenko, T. (2010). Modality of input and vocabulary acquisition.LanguageLearning&Technology, 14, 50-73.
Tang, C. (1994). Assessment and student learning: Effects of modes of assessment on students’ preparation strategies. In G. Gibbs (Ed.),Improvingstudentlearning:Theoryandpractice. (pp. 151-170). Oxford: Oxford Brookes University, The Oxford Centre for Staff Development.
Tsui, A. B. M. & Fullilove, J. (1998). Bottom-up or top-down processing as a discriminator of L2 listening performance.AppliedLinguistics, 19, 432-451.
Vandergrift, L. (2007). Recent developments in second and foreign language listening comprehension research.LanguageTeaching, 40, 191-210.
Winke, P., Gass, S., & Sydorenko, T. (2010). The effects of captioning videos used for foreign language listening activities.LanguageLearning&Technology, 14, 65-86.
Woore, R. (2010). Thinking aloud about L2 decoding: An exploration into the strategies used by beginner learners when pronouncing unfamiliar French words.LanguageLearningJournal, 38, 3-17.
Xue, G. & Nation, I. (1984). A university word list.LanguageLearningandCommunication, 3, 215-229.

- 当代外语研究的其它文章
- Learning Mandarin in Later Life: Can Old Dogs Learn New Tricks?①
- Toward a Theoretical Framework for Researching Second Language Production
- Making a Commitment to Strategic-Reader Training
- Codeswitching in East Asian University EFL Classrooms:Reflecting Teachers’ Voices①
- Metacognition Theory and Research in Second Language Listening and Reading: A Comparative Critical Review
- Thinking Metacognitively about Metacognition in Second and Foreign Language Learning, Teaching, and Research:Toward a Dynamic Metacognitive Systems Perspective