
基于支持向量机的汉语声调识别
2013-12-10 14:07中北大学信息与通信工程学院沈泉波韩慧莲
电子世界 2013年4期
中北大学信息与通信工程学院 沈泉波 韩慧莲
1.引言
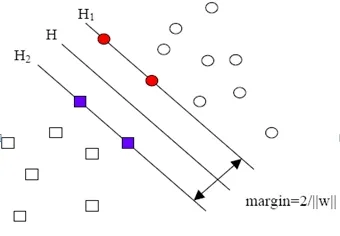
图1 线性可分情况下的最优分类线
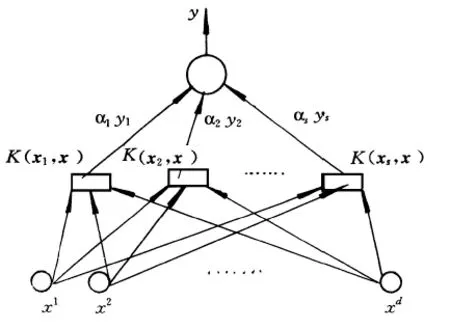
图2 支持矢量机结构示意图

图3 识别结果
汉语中每个汉字的最小发音单位是音节,每个音节由声母、韵母和声调组成,声调有4种,加上轻声有五种。声调是汉语的重要特征之一,携带了重要的语义信息,不同的声调和音节的组合代表了不同的含义。声调信息对汉语语音识别和汉语语音合成有很重要的影响,加入了声调信息,可以大大提高语音识别的精度和速度。因此,声调识别研究是一项很重要也很有意义的工作。
声调识别的方法有很多,包括有基于规则的方法、模糊识别方法、神经网络识别方法和基于隐马尔科夫模型的识别方法等,隐马尔科夫模型是语音是语音识别的主流技术,它是根据语音的统计特征来进行的识别的,能有效地提取时序特征,但是非线性分类能力和提取时间相关性能力不足。本文采用支持向量机这一优秀的模式分类器,它能较好地解决小样本、非线性、高维数和局部极小点等实际问题。本文在提取出各音节的基频和能量特征后,首先采用基于勒让德多项式的曲线拟合法对特征参数进行拟合,然后建立了6个二类支持向量机对测试音节进行识别。
2.特征参数计算
基音频率是公认的声调识别的特征参数,此外,基频差分、能量和能量差分也是声调识别的重要参数。本文选择了基频、基频差分、能量和能量差分作为特征参数,基频的计算采用加权自相关法,基频特征参数,基频差分,能量,能量差分,以帧为单位的特征向量由4个参数组成,其中1iN-1,以音节为单位的特征参数可以用下面的特征矩阵表示:
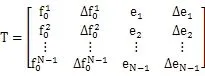
支持向量机只能处理相同维数的模式分类问题,所以要对提取到的不同维数的特征矩阵进行归一化处理,本文选用基于勒让德多项式系数的曲线拟合法,对不同维数的特征矩阵进行归一化,将曲线拟合的系数组合成特征参数。
3.支持向量机设计
支持向量机(Support Vector Machine,SVM)是建立在统计学习理论基础上的一种新型的模式分类器。目前SVM已在很多领域发挥了作用,包括模式识别(人脸识别、语音识别等)、数据挖掘、信号处理等。
SVM是从线性可分情况下的最优分类面发展而来的,基本思想可用图1的两维情况说明。
图1中,方形点和圆形点代表两类样本,H为分类线,H1,H2分别为过各类中离分类线最近的样本且平行于分类线的直线,它们之间的距离叫做分类间隔(margin)。所谓最优分类线就是要求分类线不但能将两类正确分开(训练错误率为0),而且使分类间隔最大.推广到高维空间,最优分类线就变为最优分类面。
对非线性问题,可以通过非线性变换转化为某个高维空间中的线性问题,在变换空间求最优分类面,分类函数为:,图2是结构示意图。其中K()表示内积函数,不同的内积函数会形成不同的算法,常用的内积函数有:线性核函数、多项式核函数、径向基函数和Sigmoid核函数,文中选用径向基核函数。
声调共有四种,所以本文属于多类模式的分类问题,目前常用的SVM多值分类器构造方法主要有“一对一”、“一对多”和SVM决策树方法。因为“一对一”方法精度高、容错性好,而四类声调属于较少的情况,所以选用“一对一”的分类方法。“一对一”方法的原理是首先为已知的K类训练样本训练个支持矢量机,然后用这些二类支持矢量机对测试样本进行分类。测试时,常用投票法,得票最多的类为测试样本所属的类。本文就是采取投票法。
4.MATLAB仿真
本文的训练集共有400个音节,每个声调有100个音节,测试集有20个音节,分别有a1,bei1,ben1,ao2,bie2,bo2,can2,bi2,b ao3,bie3,biao3,bai3,an4,ban4,bang4,ba o4,bei4,ben4,bian4,bo4,数字代表声调,通过Matlab的GUI工具搭建仿真界面,系统由四部分组成,包括预处理,提取特征参数,SVM训练,测试识别。首先语音信号要进行预处理,包括滤波,分帧,加窗,清浊音区分,其次要进行特征提取,对基频和能量进行差分,差分计算的代码为:
y1(i,:)=-2*y(i-2,:)-y(i-1,:)+y(i+1,:)+2*y(i+2,:),然后把f0,f0,engy,engy组成特征参数,利用曲线拟合法对不同维数的特征参数进行曲线拟合,拟合代码为:
fun=inline('f(1)*a+f(2)*0.5*(3*a.^2-1)+f(3)*0.5*(5*a.^3-3*a)+f(4)*0.125*(35*a.^4-30*a.^2+3)','f','a')
[ff(:,t),res]=lsqcurvefit(fun,[0.5,0.5,0.5,0.5],j,g),拟合系数组成特征矩阵。下一步开始SVM训练,训练的时候把两两分类时的分类器结构信息进行保存,SVMStruct{ii}{jj}=svmtrain(X,Y,'Kernel_Function','rbf');
测试识别时,首先读入两两分类时的分类器结构信息,然后利用投票策略进行分类识别,投票数最多的类就是识别结果。代码为:Voting(:,iIndex)=Voting(:,iIndex)+(classes==1);
Voting(:,jIndex)=Voting(:,jIndex)+(classes==0);
识别结果如图3所示。
从仿真结果可以看出20个测试音节都能被准确的识别出声调来,说明SVM能有效的对四种声调进行识别。
5.结束语
本文主要讨论了支持向量机在声调识别中的应用,以基频、基频差分、能量和能量差分组成的特征参数,然后设计了6个二分类支持向量机对声调进行识别。从识别结果可以看出SVM对汉语声调能有效的进行识别,具有很强的分类识别能力。
[1]钟金宏,杨善林,蒋俊杰.汉语连续语音中声调识别的特殊性研究[J].小型微型计算机系统,2002,23(4):470-473.
[2]肖汉光,蔡从中.基于SVM的非特定人声调识别的研究[J].计算机工程与应用,2009,45(9):74-176.
[3]顾明亮,夏玉果,杨亦鸣.支持矢量机的汉语声调识别[J].声学技术,2007,26(6):1186-1190.
[4]傅德胜,李仕强,王水平.支持向量机的汉语连续语音声调识别方法[J].计算机科学,2010,37(5):228-230.
[5]顾明亮,夏玉果,王劲松.噪声环境下的汉语声调识别[J].计算机技术与发展,2007,17(6):70-72.
[6]章文义,朱杰,徐向华.利用声调提高中文连续数字串语音识别系统性能[J].上海交通大学学报,2004,38(2):185-188.
[7]赵瑞珍,宋国乡,屈汉章.基于小波变换的汉语声调识别新方法[J].信号处理,2000,16(4):357-361.
[8]赵春霞,徐近霈.一种汉语单音节基音提取与声调识别方法[J].应用声学,1989,9(3):31-37.
[9]魏瑞莹,梁维谦.基于三音子模型连续语音声调识别方法[J].电声技术,2011,35(8):34-37.
[10]赵力,邹采荣,吴镇扬.基于连续分布型HMM的汉语连续语音的声调识别方法[J].信号处理,2000,16(1):21-23.
[11]张瑞丰.精通MATLAB6.5[M].北京:中国水利水电出版社,2004.
[12][英]克里斯特安尼.支持向量机导论[M].李国正,王猛,曾华军译.北京:电子工业出版社,2004.
[13]董婷.支持向量机分类算法在MATLAB环境下的实现[J].榆林学院学报,2008,18(4):94-96.
[14]郭小荟,马小平.基于MATLAB的支持向量机工具箱[J].计算机应用与软件,2007,24(12):57-59.
猜你喜欢
中国人民公安大学学报(自然科学版)(2022年1期)2022-07-20
新疆大学学报(自然科学版)(中英文)(2022年2期)2022-03-27
空间科学学报(2020年1期)2021-01-14
小天使·一年级语数英综合(2020年9期)2020-12-16
小天使·一年级语数英综合(2020年9期)2020-12-16
山东交通科技(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年9期)2019-09-25
作文周刊·小学一年级版(2019年28期)2019-09-07
制造技术与机床(2017年11期)2017-12-18
中国交通信息化(2017年8期)2017-06-06
