
林业专题动态信息的搜索与集成
2013-12-27 13:17张丽莎龙朝夕
中南林业科技大学学报 2013年5期
张丽莎 ,张 贵,龙朝夕,张 盛
(中南林业科技大学 林学院,湖南 长沙 410004)
林业专题动态信息的搜索与集成
张丽莎 ,张 贵,龙朝夕,张 盛
(中南林业科技大学 林学院,湖南 长沙 410004)
针对普通的搜索引擎进行林业专题动态信息搜索时,返回的信息显得杂乱无章且主题相关性不足,结合用户需求,对林业专题动态信息进行分类,采用最佳优先搜索策略和向量空间模型算法,以及主题爬虫的搜索策略、结构及运行原理,提出了一套林业专题动态信息搜索与集成的设计方案。实验表明,该设计方案的主题爬虫在抓取林业专题动态信息时的精确率、全面率和成功率明显优于普通爬虫。
林业;专题动态信息;搜索;集成;主题爬虫
我国林业是国民经济的基础产业,担负着生态环境建设和促进社会可持续发展的重大使命,人类是林业产业建设中的主要受益群体,当林业产业结构形成时,人们就在其中发挥其各自不同的作用。近年来,林业信息化的推进,促进了林业信息资源的共享,为公众提供了便利,促进了林业产业的发展[1]。但是,如何更好地利用林业信息资源,为我国林业科学领域广大科研人员、教学工作者以及林农服务,就迫切需要对林业信息实施快速搜索与集成。
随着网络的快速发展,互联网成为信息的主要载体。如何从浩瀚的信息空间中快速查找个人所需要的林业专题信息,已经成为林业信息化的根本问题之一[2-3]。传统的搜索引擎如Google、Yahoo以及百度等,作为人们检索信息的工具已经成为人们访问互联网的入口和指南。但是,随着使用的深入,这些普通搜索引擎越显不足,信息召回率和精确率都比较低,不能满足用户针对特定林业专题信息领域的查询,因此公众急需要一个分类精确、数据全面、更新及时的林业专题搜索引擎。
1 林业专题动态信息的主体需求及分类
在当今的网络环境下,由于信息技术已经得到了一定程度的发展,人们逐步开始寻求以人为本的技术设计思想,更加注重用户的利益需求。本研究所诉的林业专题动态信息即就是为用户服务的林业网站信息,这些信息主要涉及的类别(指林业信息属性方面)有:林业科技信息类、林业生产资料类、林产品市场供求信息类、花卉信息类、林业政策法规类、林业劳务信息类、气象与环境信息类[4]。而这些信息类别所面向的主体对象为:林业管理人员、林业科研人员、林业教育人员、林业技术推广人员、林民及其它林业工作者。
根据调查统计研究得出:所有被调查对象对林业科技信息(88%)都非常关注,绝大多数被调查者对林产品市场供求信息(79.60%)、林业政策法规(75.30%)、花卉信息(70%)非常关注,大部分人对林业生产资料(61.7%)、林业劳务信息(69.72%)、气象与灾害预警(63.60%)也比较关注(见图1)。
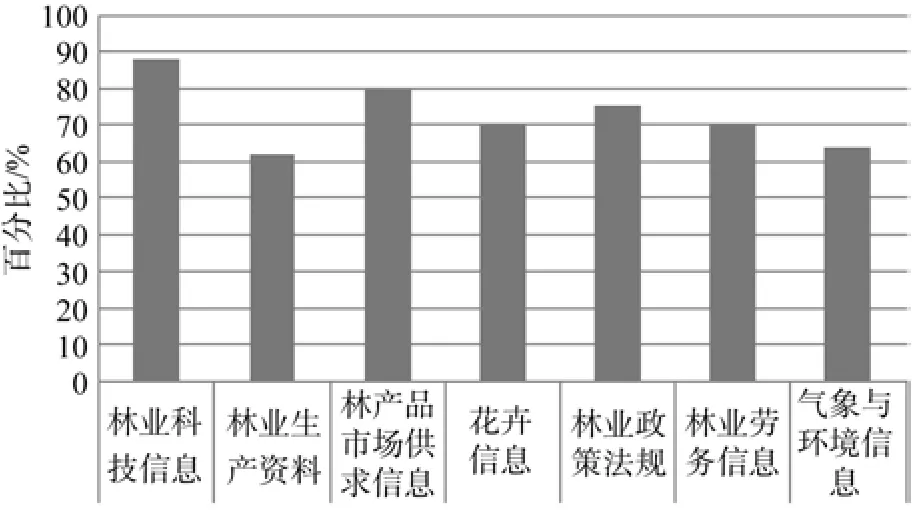
图1 林业动态信息主要类别需求调查Fig.1 Demand survey on main categories of dynamic forestry information
由图1可知,被调查人员对各种林业信息的需求各有不同。由此,为了进一步明确用户的需求,将各个类别具体化:
(1)林业科技信息类主要包括林业科技成果信息、林业实用技术信息、林业专利信息、林业在研科技项目信息以及林业百科。
(2)林业生产资料主要包括林业机械类和农资类。
(3)林产品市场供求信息主要包括木材生产、林木加工产品、林果类产品、木本中药材和竹藤产业。
(4)花卉信息主要包括花卉供应信息、花卉需求信息、种子/种球/种苗供应、种子/种球/种苗需求和苗圃基地。
(5)林业政策法规主要包括林业政策和林业法律法规。
(6)林业劳务信息主要包括高级管理类、行政/人事类、文职/后勤类、财务类、市场公关/策划类、销售/客户类、工程项目类、设计师、工程师、生产/养护、古建施工、林业技术工、教育/科研/公务员、信息/咨询/网络和林业普通工这些类别。
(7)气象与环境信息主要包括基础设施信息和自然资源与环境信息。
为了给用户提供更好的林业信息渠道,从检索用户的需求及利益出发,对林业专题动态信息进行合理分类,在用户定位方面是一种既合理又成功的方式。它是直接面向最终用户设计的,类别的划分以尽可能满足用户的需求为宗旨,并不只强求体系的科学性和结构的完整性。林业信息类别的编制必须符合这一趋势,改变以往传统的分类做法,而把面向终端用户作为自己的首要指导思想。
2 林业专题动态信息源的搜集与分类
为了能够采集到权威、准确、专业的林业专题动态信息,需要通过已经分出的林业动态信息类别来搜集林业相关类型的网站,把权威的林业主题网站采集回来,通过对这些网站的分类汇总,实现对林业网站的管理。在对林业网站进行采集时,需要采集数据所提供的网站域名,并采集域名后的内容,同时辨别所采集的网站类别。林业专题动态信息来源网站分类见表1。
3 林业专题动态信息主题爬虫搜索器
3.1 林业专题动态信息主题爬虫爬行策略
网络爬虫搜索策略通常定义为网络爬虫查询到一个网页之后怎样搜索下一个网页,普通爬虫的策略有深度优先策略、广度优先策略和将两者结合在一起的方式[5]。按深度和广度优先搜索策略爬行时,在很多情况下会导致爬虫的陷入问题,在这两种策略下的爬虫都只按其各自方式来爬行网页,对网页的内容没有认真的分析,虽然搜索到的各方面的信息较为全面,但搜索效率非常低并且搜索的信息显得杂乱无章。
为了提高爬虫的搜索效率与结果的内容相关性,因此提出了最佳的优先搜索策略[5,13], 这种搜索策略是按照特定的网页分析算法(URL算法),预先估算出待爬行的URL与目标网页的相似程度,或者是指与林业主题之间的相关性,之后通过选取最具相关性的一个或者几个URL来进行信息的提取。网络爬虫只访问通过URL算法预算为最佳的网页。在研究中,林业主题爬虫就是采用最佳优先策略进行搜索,与传统的普通爬虫相比,该设计的工作量大大减少,工作效率大大提高。
3.2 林业专题动态信息主题爬虫的设计
主题爬虫的主要运行方式是首先通过预先已经给出的林业主题,逐个分析网页中的各个超链接以及已经下载过的网页信息,来预估下一个即将爬行的网页,以尽可能地保证多下载与林业主题相关程度高的网页,同时尽可能少下载与林业主题无关的网页,使有限的资源得到最大限度的利用,通过这种方法来改善主题爬虫的爬行效率和准确率。

表1 林业动态信息来源网站分类Table 1 Classification of forestry dynamic information source website
林业主题爬虫[6]的设计是在通用爬虫的基础上对其爬行模块进行改进,主要增加三方面的功能:确定林业主题、林业网页分类、网页排序。
(1)确定林业主题
确定林业主题是林业专题动态信息主题爬虫的基础工作,主要采用主题词集来确定主题,其中每个主题词指定不同的权值,权值的设置有两种方法:特征提取和手工设置。特征提取[3]就是指假设给定一个跟林业专题动态信息主题相关的网页集合,而这些网页集合必须在林业动态信息方面具有权威性和代表性的网站,并建立一个包含与林业动态信息相关的网站URL和IP列表的专业数据库,由程序将网页里面共同的特征进行提取,并根据频率确定权值。这样不仅可以减少计算量,而且还可以提高分类的效果。手工设置是指通过手工的方法设置一组关于林业专题动态信息的关键词并分配权值[7]。
(2)林业网页分类
林业网页分类的目的是为了使搜索到的有关林业动态信息的网页尽可能地靠拢主题,对网页进行过滤,剔除那些与林业主题相关度低的网页。页面的复杂结构特点和林业主题页面的分布可以从各个方面捕捉与林业主题相关的信息,将这些内容运用到基于内容分析的林业主题爬虫搜索策略当中,能很好地提高林业主题爬虫的性能。主要从以下几方面考虑:
①URL的地址信息
在网页制造初期,研发者往往会在URL地址中加入一些与页面相关的一些主题信息,即在URL地址中加入与该主题相关的一些字符串,使之与另外的主题页面相区别。例如:林业,forestry、linye;种子,seed、zhongzi;木业,wood、muye等等。所以,在URL地址当中就有可能包含与林业主题页面相关的信息。比如: www.chinaforestry.com.cn(中国林业网)、www.wood365.cn(中国木业网)就是表示这个链接与林业相关。
②锚文本信息
当访问者点击锚文本时浏览器会将访问者带到其相应的URL指向的页面,在HTML文档中相当于向导的角色。锚文本是对URL主题相关度实行判断的一个重要的指标。例如,页面中有超链接:<a href=gqlist2.asp?sname=苗木<ypeid=0 class="sousuo" target=_blank >苗木</a>,其中“苗木”就是这个超链接的锚文本,这个子网页往往就包含与“苗木”相关的内容。
上述URL的地址信息和锚文本信息是基于内容分析所产生的结果,对于锚文本以及相关主题内容可以建立VSM向量空间模型[8-9],其中关于锚文本信息与林业主题的相关度sim(Di,Dj)可以运用如下公式:
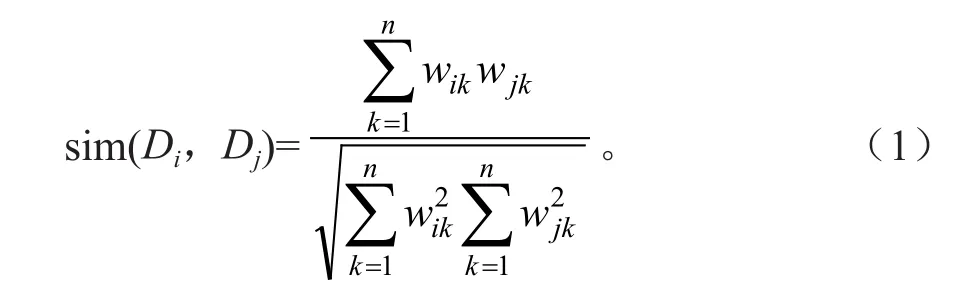
式中:Di为待分类文本特征向量;Dj为第j类的中心向量;n为特征向量的维数;wik、wjk分别为向量的第k维在文本Di、Dj中对应的权值。
③网页选择
网页选择的目的是通过计算网页的重要程度来决定网页的访问顺序,让价值高的URL优先访问,从而尽快爬行到尽可能多的与林业主题相关的网页。在实际应用中,判断URL重要性的算法很多,本文应用基于链接结构分析算法来判断URL的重要性[10],就是通过对web页面之间相互引用关系的分析来确定链接的重要性,进而确定链接的访问顺序。其中极具代表性的方法是Page-Rank算法。
Page-Rank超链接分析算法属于Google搜索引擎核心技术的一部分,这种算法主要是对搜索到的林业网站进行排序,运用Page-Rank算法对网页Page-Rank值进行计算,来判定网页出现在结果集中的位置,在结果集中出现的越靠前的页面说明Page-Rank值越高,就是说Page-Rank值是评价某个网页重要性的一个很重要的数值。
Page-Rank算法的中心思想是基于以下假设产生的:某一个林业网页被另外的网页链接的频率越高,即有可能这个林业网页就越重要;另外,若某个林业网页既使链接的频率不高,但是它被某些重要的网页链接引用了,则也有可能是重要网页。某一个林业网页的重要性是平均传递到它所链接的各个网页的。基于以上思想,得出网页P的Page-Rank值PR(p)的迭代公式:

式中:PR(p)代表网页P的Page-Rank值;PR(Ti)代表网页Ti的Page-Rank值,网页Ti指向网页P;d为阻尼系数;C(Ti)为链入网页P的网页数量。
3.3 林业专题动态信息主题爬虫URL队列的维护
为了更高效地实现对林业专题动态信息的爬取,使林业主题爬虫方便对网页链接的处理和进行林业主题相关度的计算,林业主题爬虫主要设计了4个URL队列:等待爬行队列、正在爬行队列、爬行完成队列以及错误或异常队列。
当林业主题爬虫运行后,所有的URL都加入到等待爬行队列,当处理一个URL时,如果该URL为错误或者异常类型则放入错误或异常队列,否则处理完成后放到爬行完成队列中。每当处理一个新的URL时,都需将其与错误或异常队列和爬行完成队列中URL进行比较,如果该URL已经在这两队列中则放弃爬行,再取新的URL,依次循环。
4 实验结果及分析
目前在对林业主题爬虫的性能评价的研究中,主要是通过查准率和查全率[11-12]作为评价标准的传统意义上的信息检索方法。查全率Rj为爬行到的林业相关页面数与全部林业相关页面数的比值。查准率Pj为爬行到的林业相关页面数与爬行到的全部页面数的比值。
页面与页面之间的关系如图2所示。
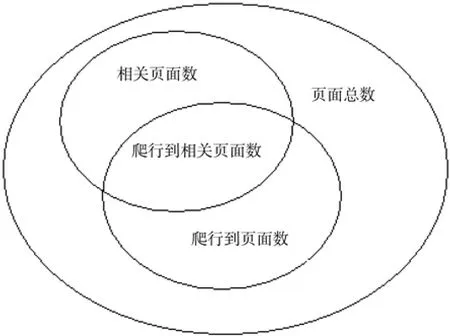
图2 页面与页面之间的关系Fig.2 Relations among website pages
为了更好地表示林业动态信息主题爬虫的性能[14],对林业主题爬虫的爬准率、爬全率和普通爬虫进行了测试,得出的最终比较结果如图3所示。
由图3、4不难看出,在抓取网页的时候,有关林业动态信息的林业主题爬虫的成功率、准确度、全面率都要明显高于普通爬虫。
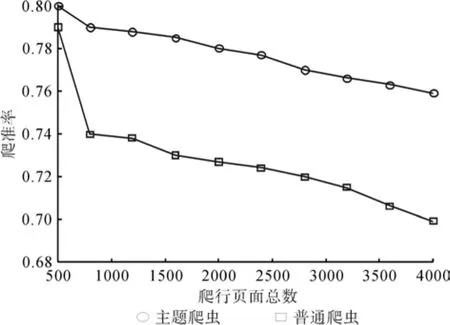
图3 爬准率曲线Fig.3 Crawler accuracy curves of web pages crawled
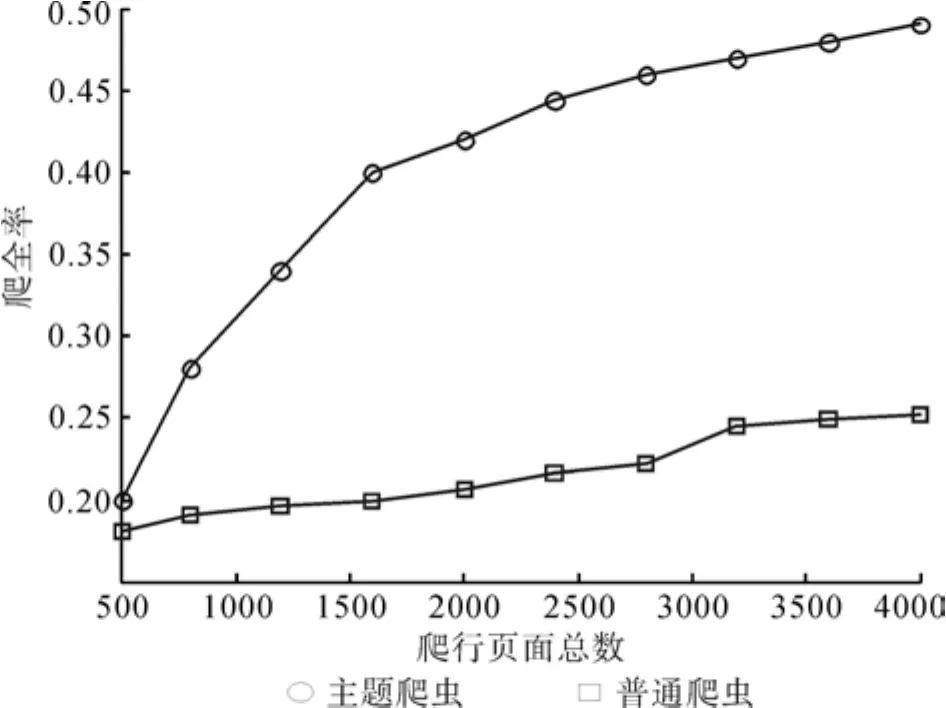
图4 爬全率曲线Fig.4 Full rate curves of web pages crawled
5 结 语
(1)基于用户需求对林业专题动态信息进行分类,使其与传统分类方式有明显区别,前者是面向检索专业人员,而后者主要是广大的普通用户。各个类别的设置以满足用户的需求为宗旨,分类体系具有较强的实用性和直接性,并且能满足用户从各种角度进行查找的需要。
(2)根据已构建的林业动态信息类别体系,搜集与之相关的林业专业网站,明确信息采集的网站来源。采集所需要的数据所提供的网站域名,并采集域名后的内容,同时辨别所采集的网站类别,实现对林业动态信息源的搜集及分类。
(3)通过与通用爬虫的对比,本研究设计的林业专题动态信息的主题爬虫,在实现对抓取网页内容抓取时的性能相对较好,保持了相对较高的爬全率和爬行准确率。爬行过程中性能相对稳定,有效过滤掉与林业主题不相关的网页,为主题搜索引擎的推广应用奠定了基础。
(4)通过本研究,体现了该林业主题爬虫在关于林业专题信息查找中的优越性,以此为基础而实现的林业主题搜索引擎,结合到以林业动态信息为主题的具体应用中,林业主题爬虫可在受限制的领域内进行面向林业主题的信息采集,为用户提供更加专业而精确的信息。
(5)作为一个检索信息的主题搜索工具,其搜索策略、爬行效率和性能等方面还存在着需要优化的部分,在以后的探索中还需要不断改进和创新。
[1] 吴志文.论林业信息化对传统林业的改造[J].林业经济问题,2003,23(1):59-61.
[2] 谢朝柱.林业是推动绿色发展的万世之基[J].中南林业科技大学学报,2012,32(6):89-93.
[3] 瞿茂生,陈 明,吴雯雯.刍议林业科技信息与林业支柱产业[J].湖南林业科技,1998,25(4):1-2.
[4] 朱颖芳,肖云华,张 贵,等.基于博弈论的林业科技成果转化主体行为分析[J].中南林业科技大学学报,2010,30(12):98-101.
[5] 欧阳柳波,李学勇,李国徽,等.专业搜索引擎搜索策略综述[J].计算机工程,2010,30(12):98-101.
[6] Chakrabarti S, van den Berg M,Dom B. Focused crawling:A new approach to topic-specific Web resource discovery [J]. In Proceedings of 8th International World Wide Web Conference(WWW8), 1999,30(13):78-82.
[7] 龙宇魏,王永成,许庆欢.主题搜索引擎Robot的设计与算法[J].计算机仿真,2004,21(4):69-72.
[8] 张 彰,樊孝忠.一种改进的基于VSM的文本分类算法[J].计算机工程与设计,2006,11(4):89-93.
[9] 易 斌,姜 飞. 支持向量机在人岗匹配度测算中的应用[J].中南林业科技大学学报,2011,31(6):92-94.
[10] CBAKRA BARTIS, DOM B E, GIBSON D, et al. Mining the Web's link structure computer[J]. IEEE,1999,32(8):60-67.
[11] MENCZER E, PANT G, RUIZM, et al. Evaluating topic-driven web crawler[C]. NY: Proc ACM SIGIR,2001:241-249.
[12] Menczer F, Pant G. Evaluating Topic-Driven Web Crawlers[J].SIGIR,2001:9-12.
[13] 周立柱,林 玲.聚焦爬虫技术研究综述[J].计算机应用,2005, 25(9):1965-1969.
[14] Aggarwal C, AI Garawi F, Yu S P. Intelligent crawling on the World Wide Web with arbitraryPredecates[C].In:Proc of the 10th International World Wide Web Conference,2001:145-165.
Search and integration of thematic dynamic information on forestry
ZHANG Li-sha, ZHANG Gui, LONG Zhao-xi, ZHANG Sheng
(School of Forestry, Central South University of Forestry and Technology, Changsha 410004, Hunan, China)
When the users inquire the web dynamic information in forestry fi eld, traditional search engines’ returned information was disordered and lack of theme correlation. The thematic dynamic information in forestry were classif i ed by combining the users’ demand,and by taking the best first search strategy, algorithm of vector space model and the topic crawler’s search strategy, structure and operation principle, A set of design scheme about search and integration of forestry thematic and dynamic information was put forward.The results show that this scheme’s crawler accuracy, comprehensive rate and success rate were obviously superior to that of the ordinary crawler in grasping thematic dynamic forestry information.
forestry; thematic dynamic information; search; integration; topic crawler
S718.54+1
A
1673-923X(2013)05-0047-05
2012-11-15
湖南省科技计划重点项目(2010nk2004,2010CK2009)
张丽莎(1987-),女,湖南益阳人,硕士研究生,主要从事林业信息工程的研究;E-mail:zhanglisha99@gmail.com
张 贵(1964-),男,湖南桃江人,教授,博士,主要从事林业生态工程、林业信息工程方面的研究
[本文编校:谢荣秀]
猜你喜欢
房地产导刊(2022年10期)2022-10-18
保健医苑(2022年1期)2022-08-30
动漫界·幼教365(中班)(2021年4期)2021-05-23
现代信息科技(2021年21期)2021-05-07
成都信息工程大学学报(2021年6期)2021-02-12
电脑爱好者(2020年17期)2020-09-14
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2018年2期)2018-04-18
电子制作(2017年2期)2017-05-17
