
Turbo乘积码译码器的并行实现方法*
2014-02-09 09:02陆连伟冯占斌
通信技术 2014年12期
陆连伟,冯占斌
(广州海格通信集团股份有限公司,广东广州510663)
Turbo乘积码译码器的并行实现方法*
陆连伟,冯占斌
(广州海格通信集团股份有限公司,广东广州510663)
本文介绍了Turbo乘积码(TPC)的串行和并行译码器结构,提供了一种TPC译码器的并行实现方法,该方法对译码器乘积码的P(P≥8)行或列进行并行译码,在性能不下降的情况下,显著提高了译码器的吞吐量。与此同时,文中对传统的分量译码器算法——CHASE算法进行了改进,改进后的译码器缩短了译码周期,从而进一步提高了吞吐量。本文设计的译码器结构适用于多子码的TPC译码器,可实现不同码字的兼容。
Turbo乘积码 迭代译码 并行译码 CHASE算法
0 引 言
Turbo码具有接近香农极限的优越性能[1],它的出现是信道编码研究中的一项重大突破,被称为二十一世纪的纠错编码。Turbo乘积码(TPC)作为Turbo码在译码算法上的延伸,且译码复杂度较低,也受到了世界范围内信息和编码理论界的关注,并成为该领域近几年来研究的热点。
TPC为块状码,一般由两个或两个以上的分组码经编码后成为二维、三维或多维的编码块。这里的分组码在乘积码中常称为子码,这些子码可以相同也可以不同,可以是BCH码、奇偶校验码、扩展汉明码等,并可对乘积码的编码块进行截短,从而构成满足通信系统要求的码率。目前无线通信系统中,以扩展汉明码作为子码的居多[2]。
TPC译码算法通常采用软判决迭代译码算法[3-4],该算法对码字的行和列进行重复迭代译码以此获得很高的纠错能力。由于按照串行的方式实现对行和列的译码严重影响了译码器的吞吐量,因此并行译码器的研究成为重点。
文中,我们提供了一种更高效的并行译码方法,并对子码为扩展汉明码的TPC分量译码器进行了改进,经过改进后的译码器可以成倍提高吞吐量,而同时又不提高存储需求。
本文结构如下,第1节介绍TPC串行译码结构及本文使用的并行译码结构,并对并行译码结构中存储单元这一关键模块做了说明,第2节介绍改进的分量译码器算法[5],最后对本文所做工作进行总结。
1 TPC译码器结构
TPC译码通常采用迭代译码的方式,其译码过程为:计算接收符号的可信度,将可信度排列成矩阵,进行行译码和列译码,将译码得到的信息在行译码和列译码之间传递。
图1为TPC译码器串行迭代一次的框图[6],图中行译码器需要进行M次译码然后再进行列译码,列译码器需要进行N次译码然后再进行下一次迭代的行译码,其中M和N分别为TPC乘积码排列成矩阵之后的行数和列数。

图1 常规串行TPC译码器(1次迭代)Fig.1 Serial TPC decoder(one iteration)
该结构译码器的吞吐量受困于TPC码字的行数M和列数N,当采用较大的M和N时,译码器吞吐量很低,下面介绍一种并行结构的译码器。
图2为本文使用的并行译码结构框图[7],该结构在分量译码器中同时进行P行或Q列的译码,因此在一次迭代过程中,只需要进行N/P次行译码和M/Q次列译码,大大降低了一次迭代需要的时钟,因此可以大幅度提高吞吐量。实际应用中,TPC的行码和列码一般选用同种类型的码字,这样做可以共用分量译码器,降低资源需求,此时可以选择P=Q,且取P为M和N的最大公约数。
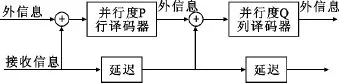
图2 并行TPC译码器(1次迭代)Fig.2 Parallel TPC decoder(one iteration)
本文选用4种扩展汉明码作为二维TPC的子码,扩展汉明码参数分别为:(8,4)、(16,11)、(32, 26)、(64,57),因此支持16种不同的TPC码。此时分量译码器并行数可选P=8。
这种并行结构译码器较传统结构译码器需要更多资源,并且为了实现并行处理,需要将TPC码字存储在不同的存储器中,以实现并行读写。
文献[7](对应文献《PARALLEL DECODING of TURBO PRODUCT CODES for HIGH DATA RATE COMMUNICATION》)中给出了一种存储器存储数据的结构,但该结构中行存储器与处理器之间的对应关系与列存储器与处理器之间的对应关系不同,在译码器设计时需使用额外的电路来选择对应关系。本文设计的存储器存储数据的方法如图3所示,其中方格中的数字表示存储器的编号,pi(i=0,…,7)表示并行处理器,分别对应所处理的行子码或列子码的位置,由图可以看出,存储器与处理器一一对应。存储器中每个方格存储TPC码字对应位置的一部分数据,该部分数据为(M/P,N/P)的矩阵,所有在这个方格中的信息都存储到对应的存储器中。在接收数据阶段,P个存储器按图中所示以列的方式存储接收到的信道信息。下面简单介绍一下分量译码器工作过程中对存储器的读取控制。
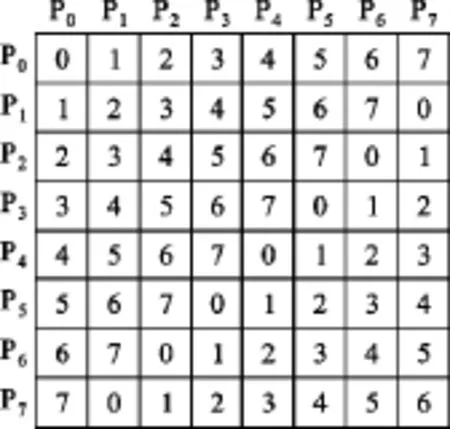
图3 信息存储器结构Fig.3 Messagememory construction
在分量译码器并行工作过程中,首先从按顺序从左到右排列的P个存储器中读取P个待处理数据,然后根据上图中的对应关系,将读取的P个数据进行循环移位送入相应的处理器中。以列码为(8,4)扩展汉明码的TPC码的列译码为例,每个存储单元存储列码码字的一个数据。读取时,第1个时钟读取第0行数据送入编号相同的处理器中;第2个时钟读取第1行数据,然后向左循环移动1个数送给处理器;第3个时钟读取第2行数据,然后向左循环移动2个数送给处理器;以此类推,第8个时钟读取第7行数据,然后向左循环移动7个数送给处理器,从而完成所有数据的读取工作。
由上面分析可知,每个存储器存储的数据个数相同,并且在行译码或列译码过程中,每次读取的P个数据都是来自不同的存储器,因此可以实现并行处理。
2 改进的分量译码器算法
此处分量译码器采用软输出译码算法——CHASE译码算法[8],其性能接近于最大似然译码。该算法的基本原理是利用硬判决译码器,根据不同的试探序列产生几个候选码字,然后把他们与接收序列进行比较,挑选一个与接收序列有最小软距离的候选码字作为译码器的输出码字。
对于(n+1,k)扩展汉明码来说(其中n为扩展汉明码的码长,k为信息位长度),传统的CHASE
算法的译码过程如下:
2)构造2p个试探错误图样,这些图样取遍了p个最不可靠位置上的所有排列。每个图样的长度都为n。注意:只有这p个最不可靠位置可以取值{0, 1},其它位置都取0。
3)确定2p个码字试探序列,j=1,2,…,2p。
b)将伴随子转化为错误位置pj。如果,那么错误位置pj=l,否则pj=-1表示没有错误。这里是H的第l列。
c)纠错得到有效码字。如果pj≥0,则⊕1。
5)计算有效码字集的模拟权重ωj=-,j=1,2,…,2p。
这里使用的是有效码字与接收码字的最大相关值(或者相关值相反数的最小值)作为衡量标准,在下面的改进算法中我们将使用最小错误权重作为衡量标准,即:所有错误位置上置信度之和,可以证明两种度量是等价的。
6)在有效码字集里寻找最似然码字d。,这里。
7)对接收的信号计算额外信息

这里ωc,ωd分别是似然码字d和c的模拟权重。c是码字d的竞争码字,且ci≠di。如果似然码字d有不止一个竞争码字,ωc等于具有最小模拟权重的码字。如果不存在竞争码字,可靠值修正因子β用来计算额外信息。注意,β随着迭代次数的变化而变化。
从上面的过程我们可以看出,在传统CHASE算法过程中,第2)、3)、4)、5)、7)步实际上需要进行循环计算,这在FPGA实现中会占用很多时间资源,对于实现高速的译码器来说是不可忍受的。为此,对传统的CHASE算法做了改进,定义相邻的两个试探错误图样只有一个不同的比特,则改进后的算法如下:
2)初始化试探错误图样、模拟权重、伴随子、扩展比特以及当前最似然码字的每个比特是否存在竞争码字、竞争码字的权重大小等。
=0(除扩展校验位以外的试探序列的错误图样权重),
ω0=0(当前候选码字的错误图样权重),
=max,这里max为实现时采用的一个最大值,保证计算出来的所有权重都比它小(当前最似然码字的错误图样权重),
ωmax=0(错误图样权重的最大值),
s=(y1,y2,…,yn)HT(伴随子),
be=()mod2(扩展比特),
flag(i)=0,i=1,…,n+1(第i个比特的竞争码字是否存在的标志),
ccw(i)=max,i=1,…,n+1(第i个比特的竞争码字存在时,竞争码字的权重),
pj∈[1,n](j=1,…,2p-1)是与不同的比特所在的位置(注意:这里使用到了相邻的两个测试序列只有一个位置不同的性质)。
3)执行2p次迭代,得到每个比特是否存在竞争码字,及竞争码字的权重大小。
对于第j次迭代(j=1,…,2p),
a)对当前的试探序列,根据伴随子s计算纠错以后的错误图样(候选码字对应的错误图样),并计算对应的权重。
如果s=0,表明汉明码没有错误(或无法检测到错误),则tj(i)=(i)(对i∈[1,n]),tj(n+1)=be;ωj=+be*rabs(n+1)。
否则,汉明码有错误,进行纠正。设s≠0时对应的错误位置为ls,则tj(i)=(i)(对i∈[1,n],且i≠ls),tj(ls)=(ls)⊕1,tj(n+1)=be⊕1;ωj=+
b)计算当前的最似然码字的试探错误图样,试探错误图样的最大值,并判断每个比特是否存在竞争码字,及竞争码字的权重大小。

如果ωmax<ωj,则ωmax=ωj。
如果j>1,则判断每个比特是否存在竞争码字,并存储竞争码字对应的权重。如果≥ωj,flag(i)=1,ccw(i)=,其中i∈[1,n+1]且(i)≠tj(i);否则,flag(i)=1,ccw(i)=ωj,其中i∈[1,n+ 1],(i)≠tj(i)且ccw(i)>ωj。
c)产生下一次迭代的试探错误图样,并更新伴随子,扩展比特和权重。
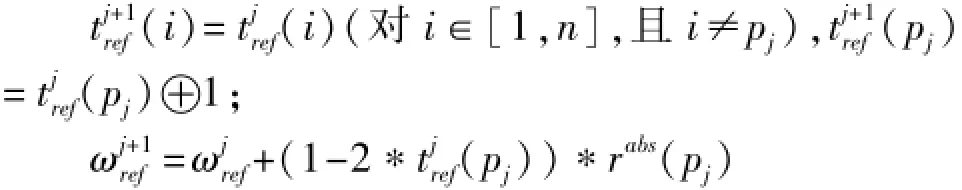
s=s⊕Hpi,Hpi是校验矩阵H的第pj列对应的值;
be=be⊕1
4)计算最似然码字:d=y⊕。
5)计算外信息。
对于i∈[1,n+1],如果flag(i)=1,则g(i)= (2*d(i)-1)*(ccw(i)-)-ri,
否则,g(i)=(2*d(i)-1)*(wmax-)/p。
从上面的步骤可以看出,改进后的CHASE算法较传统的CHASE算法主要有如下几个优点:
1)充分利用相邻两个试探错误图样具有很强相关性的特性,大大简化了伴随子及错误图样权重的计算,在FPGA实现时,使用的时钟个数由M个(列译码时)或N个(行译码器时)减少为一个时钟就可以完成,减少分量译码器时间,从而提高整个译码器数据吞吐量;
2)不需要存储每次计算出来的候选码字的错误图样和权重,输出外信息时,也不需要对每个比特在所有的候选码字中进行搜索寻找与最似然码字比特不同的码字的最小权重,只需要根据得到的是否有竞争码字的标志及对应的竞争码字权重计算即可,因此节省了搜索的时间,使用FPGA实现时可以极大地提高吞吐量;
3)不再使用β对没有竞争码字的比特进行修正,因此对每次迭代,计算外信息的方法不会因为迭代次数的变化而变化,便于实现。
3 结 语
本文对传统的分量译码器算法进行改进,充分利用了错误图案之间的相关性,降低了伴随子和错误图样权重的计算复杂度以及计算时间,从而在相同译码器结构的条件下,提高了译码的吞吐量;处理过程无需存储译码的中间结果,且每次迭代无需调整外信息的修正量,因而减少了存储器的使用,降低了实现复杂度。
实际系统中,TPC译码器通常会使用多种子码的TPC码,本文将不同的TPC码参数提前进行存储,再根据码字的不同选取相应的参数,实现多种码字共用一个译码器,提高了译码器的通用性。采用本文介绍的并行译码器结构,以及改进后的分量译码器算法,我们实现了兼容16种码字的TPC码译码器,在译码器输入时钟为96 MHz时,实现了50 Mbps吞吐量。
[1] 王宁,陈名松,杜晓萍.Turbo码的研究及仿真[J].通信技术,2012,45(03):22-27.
WANG Ning,CHEN Ming-song,DU Xiao-ping.Study and Simulation of Turbo Code.Communications Technology:2012,45(03):22-27.
[2] HE Yejun,ZHUGuangxi,LIU Yingzhuang.Turbo Product Codes and Their Application in the 4th Generation Mobile Communication System[J].Proceedings of SPIE, 2003(5284):221-228.
[3] PYNDIANRameshMahendra.Near-Optimum Decoding of Products Codes:Block Turbo Codes[J].IEEE Trans, 1998,46(08):lO03-1010.
[4] WEIXue-fei,Akansu N A.On Parallel Iterative Decoding of ProductCode[J].Proceedings of IEEE VTC,2001 (04):2483-2486.
[5] HIRSTSimon A.,HONARY Bahram,MARKARIAN Garik.Fast Chase A lgorithm withan Application in Turbo Decoding[J].IEEE Transaction on Communications, 2001,49(10):1693-1699.
[6] ARGON Cenk,MCLAUGHLIN Steven W..A Parallel Decoder for Low Latency Decoding of Turbo Product Codes [J].IEEECommunications letters,2002,6(02):70-72.
[7] ZHANG Xiu-jun,ZHAOMing,ZHOU Shi-dong,etc.Parallel Decoding of Turbo Product Codes for High Data Rate Communication[J].The 57th IEEE Semiannual:Vehicular Technology Conference,2003(04):2372-2375.
[8] CHASED.A Class of Algorithms for Decoding Block Codes with Channel Measurement Information[J].IEEE Trans.Inform.Theory,1972(IT-1 8):170-182.

陆连伟(1983—),男,硕士,工程师,主要研究方向为卫星无线通信;
LU Lian-wei(1983-),male,M.Sci.,engineer,majoring in satcom wireless communication.
冯占斌(1980—),男,硕士,工程师,主要研究方向为卫星无线通信。
FENG Zhan-bin(1980-),male,M.Sci., engineer,majoring in satcom wireless communication.
A Parallel Im p lem entation of TPC Decoder
LU Lian-wei,FENG Zhan-bin
(Guangzhou HAIGE Communications Group Incorporated Company,Guangzhou Guangdong 510063,China)
This paper describes the serial and parallel structures of turbo product codes(TPC),proposes a parallel implementation of TPC to realize simultaneous decoding of P(P≥8)row-wise or column-wise code vectors of a product code,thus the decoding throughput is obviously raised without any performance degradation.Furthermore,the traditional decoder algorithm——CHASE algorithm,is modified,and this modified algorithm could reduce the decoding cycle and thus further increse the throughput.The proposed decoder architecture is applied to TPC decoder ofmulti-subcode and could achieve compatibility of among different codons.
Turbo product code;iterative decoding;parallel decoding;CHASE algorithm
TN914.31
A
1002-0802(2014)12-1371-04
10.3969/j.issn.1002-0802.2014.12.005
2014-08-26;
2014-10-15 Received date:2014-08-26;Revised date:2014-10-15
猜你喜欢
ViVi美眉(2020年2期)2020-08-04
扬子江诗刊(2018年1期)2018-11-13
舰船电子对抗(2018年3期)2018-08-28
扬子江(2018年1期)2018-01-26
科技视界(2018年27期)2018-01-16
时代英语·高一(2017年5期)2017-11-14
科教导刊·电子版(2016年36期)2017-04-22
智能制造(2016年6期)2016-08-03
中国传媒大学学报(自然科学版)(2013年2期)2013-11-03
宠物世界·猫迷(2013年2期)2013-04-27
