
观点句中评价对象/属性的缺省项识别方法研究
2014-02-28 00:45刘慧慧王素格赵策力
中文信息学报 2014年6期
刘慧慧,王素格,2,赵策力
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006;3. 山西大学 数学科学学院,山西 太原 030006)
1 引言
微博以其短小精悍的语言特点从众多社交平台中脱颖而出,归因于它不仅是一个信息传播平台,而且是一个内容自创的平台,让人人都成为内容的制造者、见证者、传播者以及评论者。用户不仅可以发表文字内容,而且可以通过超链接、图片和视频分享资源,使得微博具有丰富的延伸性,给予用户简便的阅读体验和自由度,它要求用户发表的文字内容仅限在140个字数之内,因此,人们通常会使用言简意赅的语言表述对某一事物或者某一产品的看法和观点,但这导致了不规范的、口语化的文本数据日益剧增,如何从这类文本数据中挖掘所蕴含的有价值的观点,已经成为自然语言处理领域的一个热点研究课题[1]。
在语言表达中,人们通常省略某些语言成分,即句子存在缺省项,在相关文献中也称它为零指代[2]。它是句子中的一个缺口,指代前文中出现一个语言单位。相比于其他语言而言,汉语表达更加灵活,缺省使用也较频繁。据Kim[3]进行调查,发现在英文文本中显式主语的使用率高达96%,而在中文文本中显式主语的使用率只有64%,这就意味着在中文文本中零指代的现象较为普遍。在情感观点句中,人们在不影响表达的前提下,往往使用指示性代词代替前文中所出现的某个评价对象和评价属性,或者直接将评价对象和评价属性省略。我们称前者为评价要素指代,后者为评价要素缺省。在观点要素抽取时,如果不能正确地处理评价对象与评价属性的对应关系,将导致评价对象与评价属性之间张冠李戴。例如,“苹果过于封闭,更新速度相对较慢且价格昂贵,而三星等品牌系统开放,硬件技术日益完善,手机更新速度快,受众群涵盖上、中、下三层。”该句中评价属性“价格”、“硬件技术”对应的评价对象分别为“苹果”、“三星等品牌”。
对于评价要素指代,可以借鉴文献[4-6]中的指代消解技术。而对于评价要素缺省识别,评价对象和评价属性的缺省问题还鲜有研究。为了寻找评价对象与评价属性的关联对,需要准确识别观点句中评价对象和评价属性的对应关系,而确定缺省项的位置是其至关重要的环节。本文首先分析了观点句中评价对象和评价属性缺省项句法特点,构造候选缺省项识别规则集,在此基础上,利用句子的词性序列和候选缺省项识别规则集,获取观点句中待识别的缺省项侯选集。为了准确判定缺省项在句子中的位置,将其看作一个二分类问题。利用缺省项的上下文词性信息和依存句法信息构建分类特征集。在训练集上使用决策树C4.5算法,训练分类模型,对测试集进行缺省项识别,最终获得情感观点句中评价对象或评价属性缺省项所在的位置,为实现评价对象或评价属性缺省项的恢复奠定了基础。
2 相关工作
目前,零指代识别与消解的相关研究在国内外得到了广泛的关注[2],主要表现在以下两个方面。
基于规则方面,Kong等[7]提出了一种基于规则探测零指代词的方法,该方法通过对一个句子进行完全句法分析,获取覆盖当前预测节点的最小子树。在此基础上,构造规则,用于确定该句子是否含有零指代词。实验结果表明,在正确的句法分析树上,F值可达82.45%,但在自动句法分析树上,F值下降了近20%。Yeh和Chen[8]提出了一种基于词性标注的零指代消解方法,利用一个分割程序将句子划分为带词性标注的序列,在此基础上,使用短语级解析树将其分割为更小的成分,例如名词短语和动词短语。每一个短语作为词序列,被转化为一个完整的三元组T=[S,P,O]。利用零指代三元组,挖掘零指代候选集,通过约束规则最终确定零指代词。实验结果表明,仅使用三元组识别零指代的精确率达到65.2%,加上约束规则后,精确率可达到80.5%。
基于机器学习方面,大都沿用了Soon等[9]提出的框架,其基本思想是将零指代消解看成二元分类问题。Ng等[1]将零指代消解划分为零指代识别和零指代消解两个阶段,分别使用零指代词识别特征集和零指代词先行语确定特征集。在候选词选取时,他们采用了简单的启发式规则,获得大部分的零指代词,但同时也引入了太多噪音,导致前照应零指代词识别的精确率较低。Xue等[10]给出了一种基于机器学习的空语类识别方法。该方法在完全正确的句法树上,获得了很好的结果,但在自动标注的句法树上,性能有所下降,说明句法信息对空语类识别有一定的作用。Kong和Zhou[11]提出了一种基于树核方法的统一框架,用于解决零指代消解问题。在零指代识别阶段,他们使用有效的句法树片段代替以往的平面特征,虽然保留了必要的上下文信息,在一定程度上提高了识别的性能,但是若句子越长,解析树越可能出现错误,并且时间复杂度也将随之增高。
对于评价对象和评价属性识别,Santosh[12]等人针对属性词抽取提出了一种无监督和领域无关的方法,整个实验过程分为三个步骤,第一步从输入的文本中识别出相关的名词短语;第二步将描述同一个属性的名词短语聚成一类;第三步定义了属性得分函数,得分最高的侯选集即为属性词。通过在不同规模的数据集进行实验,证明了他们的算法具有较好的鲁棒性。Katharina[13]等人利用半监督学习技术抽取属性值-评价词关系对,首先自动地从未标注的数据中抽取一个初始化种子列表,将其作为半监督分类算法的训练集,最后使用依存信息和co-location得分建立了属性词和评价词之间的关系。
本文的研究目标是对情感观点句中缺省的评价对象和属性进行识别,通过挖掘缺省项识别规则集,选取缺省项侯选集,最后通过机器学习方法对缺省项进行识别。
3 缺省项类型
根据文献[14],一个中文句子一般包括一个或者几个分句。依据中心理论,一个句子中,主语最可能被指代,其次是宾语,最后是其它名词。在以往的零指代研究中,侧重于处理前照应零指代,即零指代词出现在先行语之后,并且零指代词在句子中作主要的句法成分。与零指代识别研究不同,在多对象评论文本中,一个观点句可能涉及多个对象/方面。如图1所示。
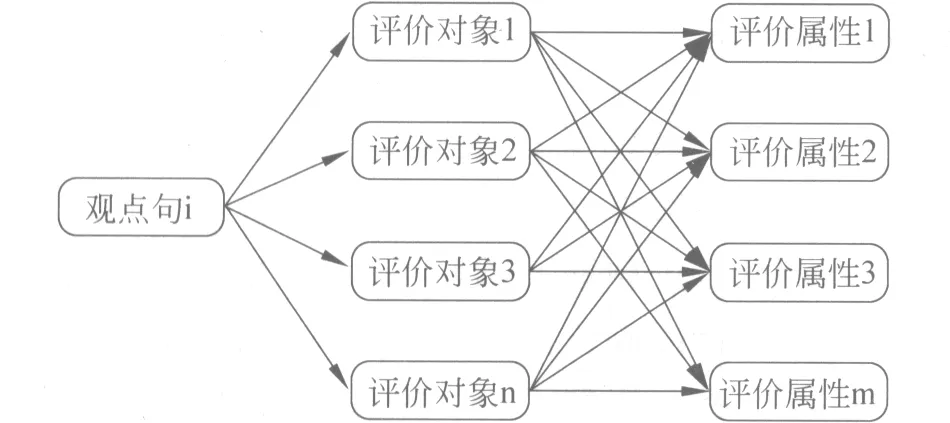
图1 观点句—评价对象—评价属性关系对应图
图1中,观点句i可能涉及n个评价对象,每个评价对象可能涉及m个属性。
通过对大量情感观点句考察,将评价要素缺省项分为以下两种情况。
(1) 缺省项作为句子的主要成分
例1三星太她妈难用了,还是iphone好,任何手机都比不上。
在例1中,第3个子句缺省了评价对象“iphone”,它作为句子的宾语。
例2三星手机质量太差,一进水就不好用,而且不禁摔。怀念诺基亚。
在例2中,第2和第3个子句中缺省了评价对象“三星手机”,它作为句子的主语。
(2) 缺省项不作为句子的主要成分
例3新机nexus 4入手,外观比我想像中还要大气。手机的速度不是我吹水,真的比三星的9300快多了。
在例3中,第2个子句缺省了评价属性“外观”的评价对象“新机nexus 4”。在第4个子句中缺省了评价对象“三星的9300”的评价属性“手机的速度”。
4 缺省项识别框架
根据第3节介绍的缺省项类型,本文提出一种缺省项识别方法,框架如图2所示。
根据图2,首先,初始文本经过分词和词性标注预处理,利用情感词典识别情感观点句。在此基础上,构造缺省项识别规则集获取待识别的缺省项侯选集。在训练阶段和测试阶段分别提取特征,使用决策树C4.5算法训练分类器模型,将其用于测试集,最后得到观点句的缺省项识别结果。
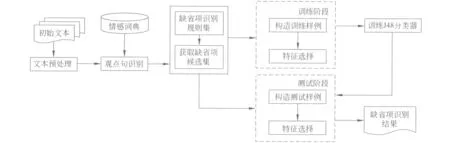
图2 缺省项识别框架
5 缺省项识别规则挖掘算法
为了获取缺省项候选集,人们通常依据语言现象总结启发式规则,但在开放的网络平台和文本大数据中,仅仅依靠人工无法将所有的情况包括其中。为了减少人为因素,我们使用缺省规则挖掘算法以期获取一个全面、科学的规则集。
定义1: 根据文献[14],设A是一个由规则构成的集合,则称A为项集。若A中包含k个规则,则称其为k项集。
定义2: 设S={s1,s2,…,st}为所有句子的集合,项集A在句子集S中出现的次数占S中总句子数的百分比称为项集A的支持度(support)。
定义3: 如果项集的支持度超过用户给定的最小支持度阈值(Min-support),则称该项集为频繁项集(或大项集)。
形如规则X→Y,X是规则的前件,Y是结果。只有当X→Y的支持度和置信度分别大于最小支持度和最小置信度时,X与Y之间存在关联关系。X→Y支持度和置信度计算公式如式(1)~(2)所示:
为了获得选取缺省项侯选集的规则集,本文利用缺省项识别规则挖掘算法获取规则集,算法流程图如图3所示。
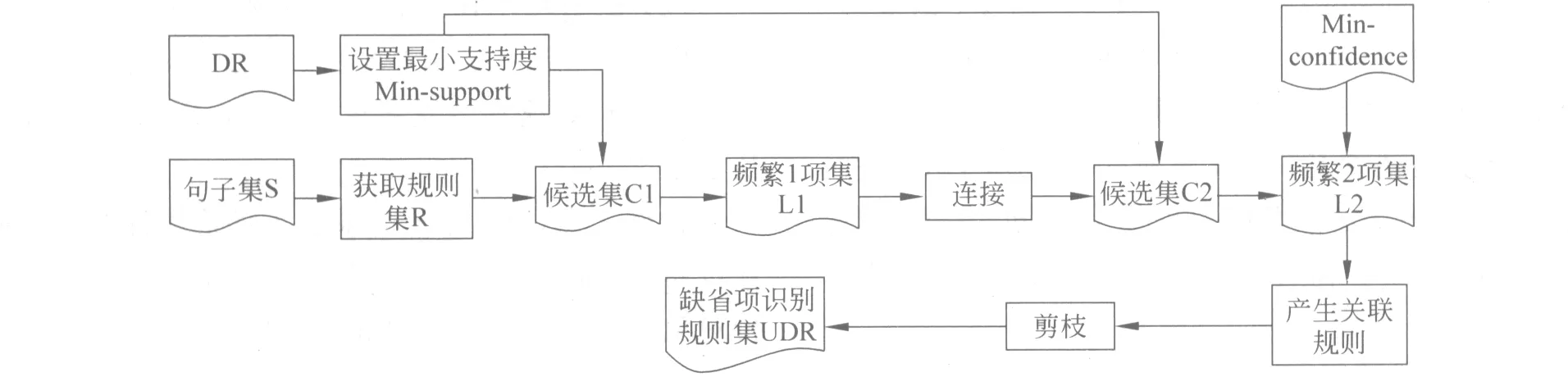
图3 缺省项识别规则挖掘算法流程图
根据图3的算法流程图,缺省项识别规则挖掘算法描述如下:
算法说明:Li、Ci分别为频繁i项集和i项集侯选集(i=1,2,…,m);DR为启发式缺省项识别规则集,它是通过对观点句缺省位置的考察,利用该位置的上下文信息,总结得到的规则集;DF为DR中规则的频度集;DAR、UDAR分别为确定性关联规则集和非确定性关联规则集。frequence(x)为x出现的次数,本文最小置信度Min-confidence设置为0.6-1.0,窗口大小Window_size=i+1,i=1,2,3。
输入: 序列化之后的句子集S={s1,s2,…,st},DR,Min-confidence,DAR=∅,UDAR=∅,C1=∅,C2=∅,L1=∅,L2=∅。
输出: 缺省项识别规则集UDR。
Step1: 设置最小支持度Min-support
设DR={r1k}(k=1,2,3,…,n),DF={f(r1k)},Min-support=min{x∈DF}。
Step2: 获取规则集R
从句子si中截取Window_size长度的规则集,记为Ri+1(i=1,2,3)。
Step3: 选取候选规则集C1
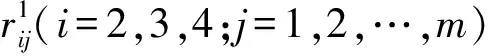
Step4: 产生频繁1项集L1//频度大于最小支持度阈值的规则组成的集合。
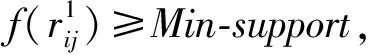
Step5: 连接,即L1与自身连接
将L1的非空真子集与自身连接,产生候选2项集的集合,记为C2。
Step6: 产生频繁2项集L2
Step7: 由频繁项集产生关联规则
对于L2中每个非空真子集a,如果frequence(L2)/frequence(a)≥Min-confidence,则a→(L2-a)是一个关联规则,UDAR=UDAR∪{a→(L2-a)}。
Step8:DAR生成
遍历DR和L1,取DR中的元素dri,L1中的元素l1j,构造dri→{l1j},i=1,2,…,|DR|;j=1,2,…,|L1|的关联规则。如果frequence(dri∧{l1j})/frequence(dri)≥Min-confidence,则DAR=DAR∪{dri→{l1j}}。
Step9: 剪枝,将UDAR中无关的规则剔除。
遍历UDAR中每个元素x,如果x前件不包含在DAR中元素的后件组成的集合中,则将其从UDAR中剔除。
Step10: 生成缺省规则集UDR
UDAR中元素的前件和后件逐一加入UDR中。
Step11: 算法结束。
6 特征选择与分类器构造
6.1 特征选择
本文将缺省项识别的过程看作一个二元分类问题,通过引入词法特征和依存句法特征,建立一个缺省项识别分类器。
(1) 词法特征
缺省项位置上前后词语的词性决定了它在句子中的句法成分,而一个句子的句法成分是否完整,对缺省项识别非常关键,因此本文使用缺省项φ位置上前后词语的词性用于刻画缺省项的特征。
例4φ 真心/d 是/v 我/r 买/v 过/u 最/d 好/a 的/u 手机/n 。/w
从例4中可以看出,φ之后是副词,之前没有任
何词,那么这个位置存在缺省。由此可见,词法特征可以确定缺省项的位置。
根据语料中的语言现象,词法特征描述见表1所示。
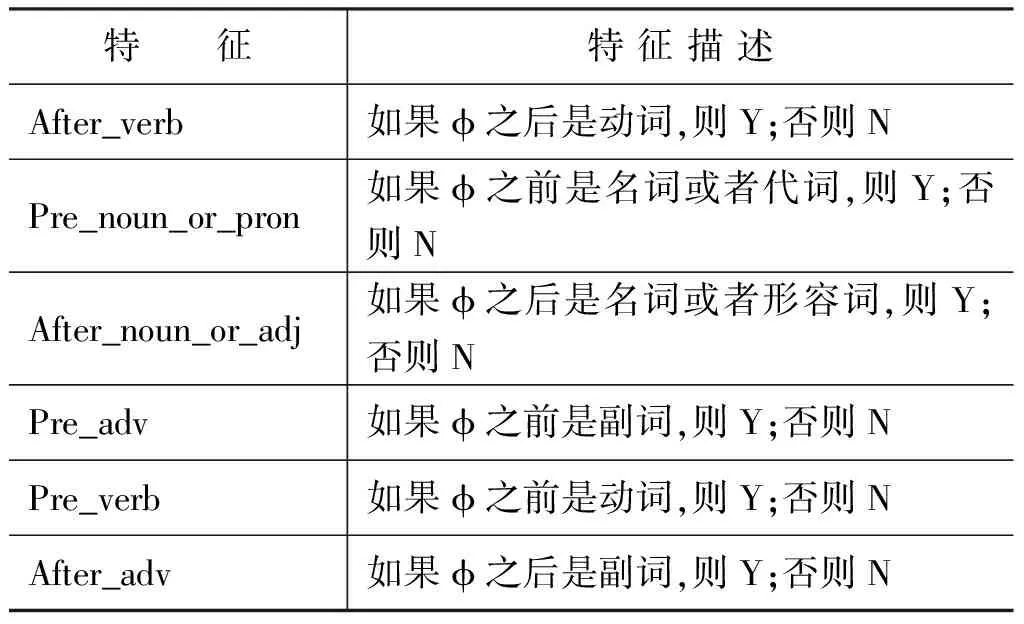
表1 词法特征集的描述
利用表1的描述,例4的词性特征即为After_adv,其值为Y。
(2) 依存句法特征
虽然词法特征在一定程度上反应了缺省项的特点,但是这种平面特征只考虑了缺省项前后词的词性,往往忽略了缺省项与上下文之间的关系。为了弥补这种缺陷,我们利用依存句法分析树建立句子中词语与词语之间的联系,以其刻画词语之间的关系。
本文直接利用哈工大的依存句法树自动获取依存信息,例4的依存句法分析结果,如图4所示。

图4 依存句法分析结果图
从图4中可以看出,缺省项φ与“是”之间形成了主谓关系(SBV),而且只作为从属词(箭尾),不做支配词(箭头)。
根据缺省项的上下文依存句法信息,本文构造了5个依存句法特征,特征集描述见表2所示。
依据表2的描述,例4的依存句法特征即为SBV。
6.2 决策树分类器
决策树学习是一种临近离散值目标函数的方法,它对错误有很好的健壮性,而且适用于属性值较
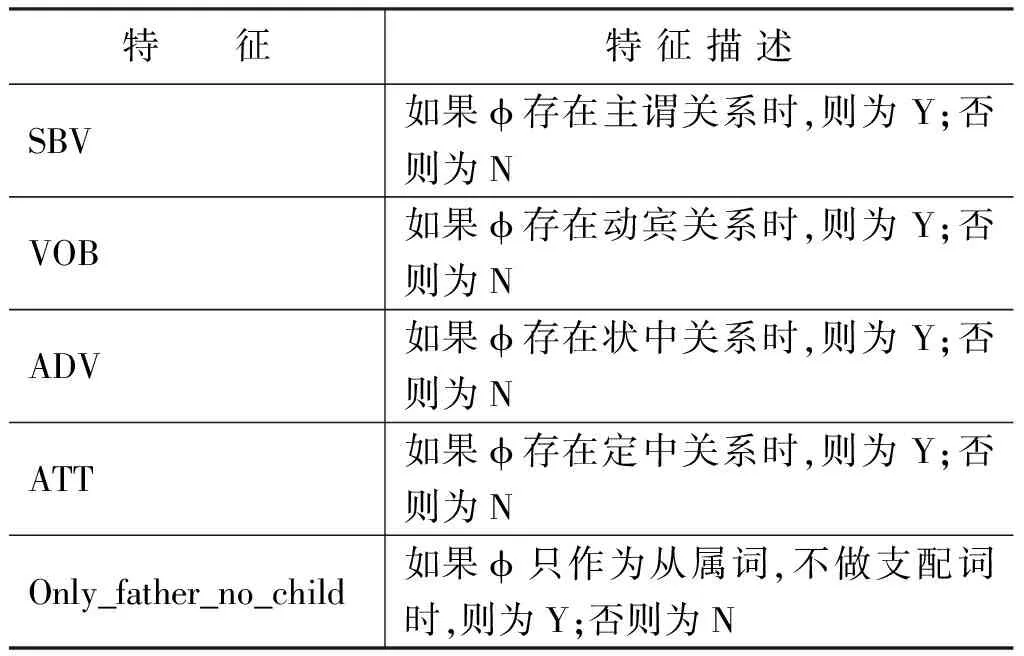
表2 依存句法特征集的描述
少的情况。本文采用决策树C4.5作为分类器。在训练阶段,将缺省项侯选集的每个实例通过上述表1和表2的特征集表示,对每个实例打上类标签,使用weka中的决策树J48训练分类器模型。在测试阶段,同样地,向量化每个实例,然后使用训练好的分类模型预测每个实例所属类别。
7 实验结果与分析
7.1 实验语料
本文选自2014年中文文本倾向性分析评测(COAE 2014)中手机领域的292篇微博作为实验数据,使用山西大学情感词典(共计17 445个情感词)识别观点句,将包含情感词的句子当作情感观点句,并在情感观点句(共计1 077个子句)上标注了缺省项的位置以及类型,如表3所示。该语料中共包含848个缺省项,其中,零指代缺省(φZ)占45.7%,非零指代缺省(φN)占24.3%,其他类型占30%。
为了进一步说明仅使用情感词典判断情感句对最终实验带来的影响,本文在所有的句子(共计1 337个子句)上标注缺省项,实验结果见表3。
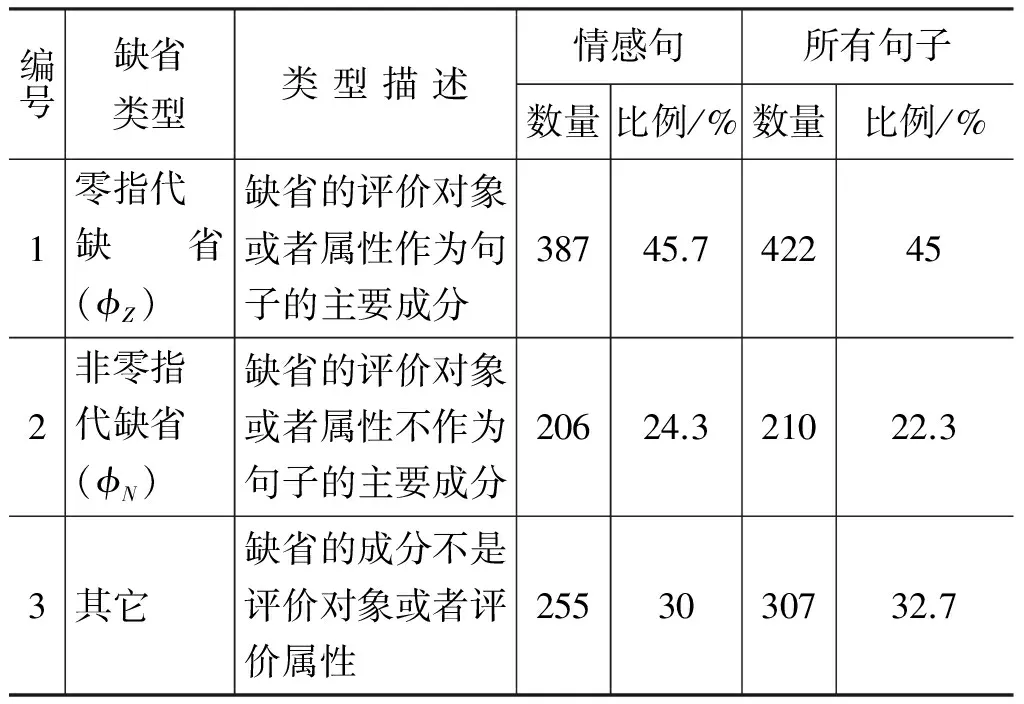
表3 缺省项类型统计结果
由表3可知,仅使用情感词典判断情感句,必然会造成部分φZ和φN缺失,但相比所有句子的φZ和φN,它们在情感句中的比例略高,而第三种类型的缺省却有所上升。本文只针对前两种缺省进行处理,而使用情感词典判断情感句可以有效地减少噪音(第三种类型缺省)数据的引入。
7.2 语料校对
在手机领域中,新功能、新型号以及新别称层出不穷,由于分词软件词库未能将全部的新词收录,从而造成错分、错标等问题。为了减少预处理阶段对本文方法产生不良影响,我们对自动分词与词性标注后的评价对象和评价属性进行了校对。
(1) 分词错误
例5三星/nz 这/r 款/q 手机/n 之所以/c 让/v 我/r 满意/v ,/w 是因为/c 自/a 拍/j 是/a 200万/m 像/d 素/a 的/b 。/w
例5中的“自/a 拍/j”、“像/d 素/a”是手机的属性,应进行合并,并标注词性为“n”。
(2) 词性标注错误
例6“9300/m 好/a 了/y ,/w 原来/d 是/v 颓废/a 的/u 包/n 的/u 问题/n ”
这里“9300/m”是三星手机的一个型号,经过校对标注为“nz”。
7.3 实验结果与分析
根据第4节缺省项识别框架和第7.2小节语料校对,设计如下实验。
(1) 语料校对对缺省项侯选集选取的影响
为了说明语料校对前后对实验结果的影响,我们针对缺省项侯选集DR方法设置了对比实验,实验结果见表4。
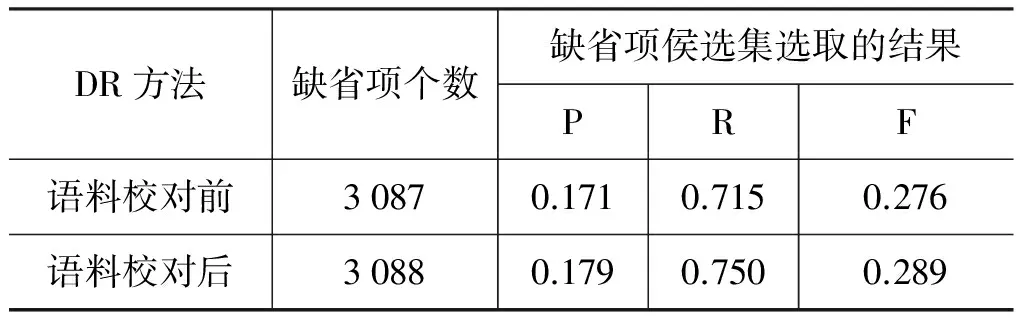
表4 语料校对前后对缺省项侯选集选取的影响
由表4可知: 使用相同的规则集DR,在语料校对前后得到的缺省项的个数几乎没有发生变化,但缺省项侯选集选取的召回率有明显地改变,说明语料经过校对后在一定程度上可寻找出更多的缺省项。
(2) 规则的置信度对缺省项侯选集的影响
由于规则集的大小受规则置信度高低的制约,为了识别尽可能多的缺省项,以建立较完备的缺省项侯选集,本实验选取置信度为0.6~1.0的规则,用于获取缺省项侯选集,实验结果见表5所示。
由表5可以看出:
① 规则挖掘算法中的置信度大小对扩充启发式缺省项识别规则集有一定的影响,规则置信度越低,扩充的规则集合就越大。
② 随着置信度增大,规则集的规模、缺省项个数
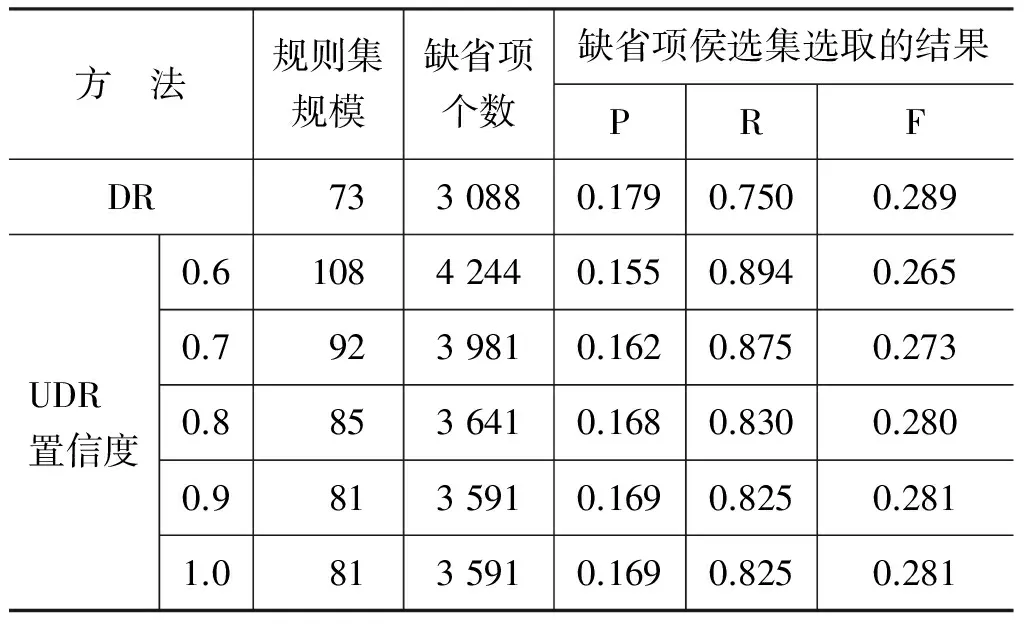
表5 规则的置信度对缺省项侯选集的影响
以及规则的召回率均减小,而缺省项识别的精确率和F值均有增长。
(3) 特征对缺省项识别的影响
为了验证本文构造各类特征集对缺省项识别的影响,分别考察了使用不同特征集的分类效果。与此同时,使用Zhao[2]提出的启发式规则作为本文的baseline。最终的实验结果采用五倍交叉验证,实验结果见表6。
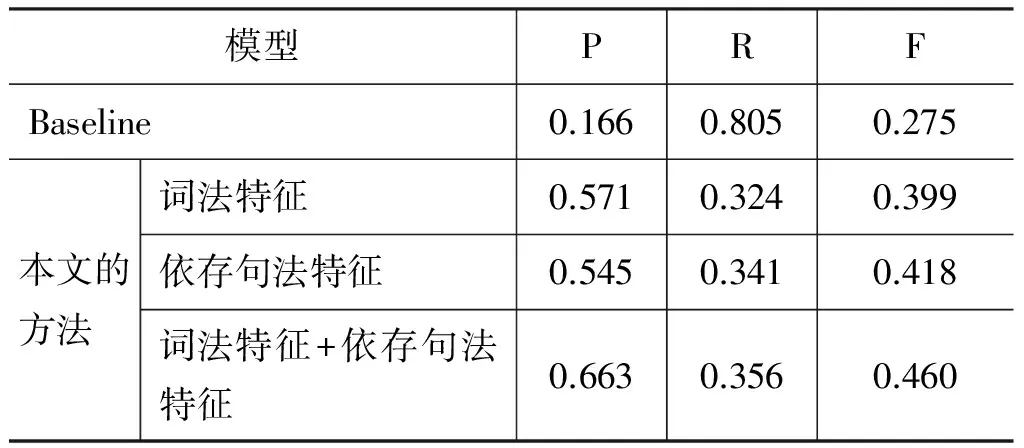
表6 缺省项识别结果
从表6可以得知:
① 当使用依存句法特征对缺省项识别时,召回率和F值均略高于词法特征,从而说明依存句法涵盖的缺省项上下文信息更为丰富。
② 将词法特征和依存句法特征融合之后,精确率要远远优于任一单类特征,而融合的特征集在召回率和F值也有较为明显的提高,说明词法特征和依存句法特征之间具有互补性。
(4) 错误分析
通过对情感观点句的评价对象和评价属性缺省项识别结果的分析,得出识别错误的主要原因有以下三个方面:
① 缺省项φ的词性错标: 由于在利用依存句法工具之前,人工已标记了句子的缺省项符号,导致依存句法工具对个别句子进行句法分析时,产生缺省项φ的词性错标。
例如,“φ1 感觉φ2 真不错”的依存句法图如图5所示:
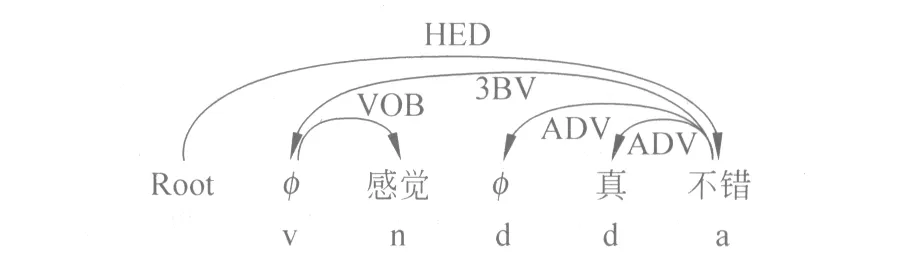
图5 依存句法分析图
其中,“感觉”是一个动词,却被误标成了名词,导致与缺省项φ1之间的关系发生错误,“φ2”的词性应该是名词,却被误标成副词,使形成的依存关系也出现错误。
② 词性标注错误: 微博中的表情符号有着重要的意义,但是在分词时,往往会被冠以某一种词性,例如,“屏幕/n 大/a 又/d 4核/n ~/n φ3 太/d 爽/a 了/v”,其中“~”被标注为名词,使用词法特征分类时,“φ3 ”被认为不是缺省项,又因为“φ3 ”之前是名词,之后是完整的谓语,故机器误认为这个句子不存在缺省。
③ 结构化信息过少: 本文主要针对两种类型的缺省项识别,一类是在句子中作主要成分的零指代缺省项,另一类是不作主要成分的非零指代缺省项。从实验结果中,可以看出句法特征SBV、VOB、ADV对于零指代缺省项的识别效果较好,但是对于非零指代缺省项的识别,效果不太理想,例如,“φ质量很差”,φ与“质量”之间形成ATT的关系,经常被错标成其他关系类型,导致非零指代的缺省项识别结果较差。
8 结束语
针对评价要素缺省项识别的问题,本文提出了一种有效的解决方法。首先使用山西大学情感词典,将包含情感词的句子作为情感句。在以往的零指代识别中,通常利用启发式规则获取侯选集,虽然简单,但也引入了过多的噪音数据,为了避免噪音数据带来的影响,本文在情感观点句上,采用缺省项识别规则挖掘算法得到规则集,用于获取缺省项侯选集。从实验结果中可以得知,使用规则挖掘算法得到的规则集优于简单启发式规则。最后,本文在缺省项候选集的基础上,构造了两类特征集用于缺省项识别的分类器,从实验结果可知,两类特征的融合要优于单类特征,从而也证明了本文方法的有效性。
本文方法的不足是整体召回率还偏低,说明构造的特征集还不够完善。未来工作中,将寻找更好的特征方法以利于缺省项识别,在此基础上,开展缺省项消解方面的研究工作。
致谢本文使用的依存句法工具来自哈尔滨工业大学信息检索研究中心的中文依存句法分析工具,在此我们特别诚挚地感谢哈尔滨工业大学提供的语言技术平台。
[1] C L Yeh, Y C Chen. Using zero anaphora resolution to improve text categorization[C]//Proceedings of the 17th Pacific Asia Conference, 2003: 423-430.
[2] S H Zhao, H T Ng. Identification and resolution of Chinese zero pronoun: a machine learning approach[C]//Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, 2007: 541-550.
[3] Young-Joo Kim. Subject/Object drop in the acquisition of Korean: A Cross-linguistic Comparison[J]. Journal of East Asian Linguistics, 2000: 325-351.
[4] R Mitkov. Robust pronoun resolution with limited knowledge[C]//Proceedings of the 18th International Conference on Computation Linguistics,1998: 869-875.
[5] S Converse. Pronominal anaphora resolution in Chinese[D]. Ph.D. Thesis, University of Pennsylvania. http://www.researchgate.net/Publication,2006.
[6] G D Zhou, F Kong, Q M Zhu. Context-sensitive convolution tree kernel for pronoun resolution[C]//IJCNLP’2008: 25-31.
[7] K W Qin, F Kong, P F Li, et al. Chinese zero anaphor detection: rule-based approach[J]. Advances in Intelligent and Soft Computing, 2011: 403-407.
[8] C L Yeh, Y C Chen. Zero anaphora resolution in Chinese with shallow parsing[J]. Journal of Chinese Language and Computing, 2007: 41-56.
[9] W Soon, H Ng, D Lim. A machine learning approach to coreference resolution of noun phrase[J]. Computational Linguistics, 2001: 521-544.
[10] Y Q Yang, N W Xue. Chasing the ghost recovering empty categories in the Chinese Tree -bank[C]//Proceedings of the Coling’10 Beijing, 2010: 1382-1390.
[11] F Kong, G D Zhou. A tree kernel-based unified framework for Chinese zero anaphora resolution[C]//Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, 2010: 882-891.
[12] R Santosh, P Prasad, V Vasudeva. An Unsupervised Approach to Product Attribute Extraction[C]//Proceedings of the 31st European Conference on IR Research. Toulouse, France:[s.n.], 2009: 796-800.
[13] P Katharina, G Rayid, K Marko, et al. Semi-supervised Learning of Attribute-value Pairs from Product Descriptions[C]//Proceedings of the 20th International Joint Conference on Artificial Intelligence.[S.I.]: IEEE Press, 2007: 2838-2843.
[14] Y Huang. Anaphora: A cross-linguistic study[M]. Oxford, England: Oxford University Press.
猜你喜欢
科学咨询(2022年19期)2022-11-24
大连民族大学学报(2021年2期)2021-07-16
航天工业管理(2020年9期)2020-12-28
考试与评价·八年级版(2020年1期)2020-10-26
中华诗词(2018年3期)2018-08-01
中华诗词(2018年11期)2018-03-26
现代语文(学术综合)(2017年9期)2017-10-19
自动化学报(2017年11期)2017-04-04
华人时刊·中旬刊(2015年4期)2015-10-21
当代修辞学(2014年3期)2014-01-21
