
基于邻域密度的异常检测方法
2014-07-08 08:31赵华秦克云
计算机工程与应用 2014年17期
赵华,秦克云
西南交通大学数学学院,成都 610031
基于邻域密度的异常检测方法
赵华,秦克云
西南交通大学数学学院,成都 610031
提出了一个基于邻域密度的异常检测方法,它能处理混合数据的异常值。在该方法中,样本的异常指标被定义为该样本的邻域大小和该样本的平均邻域密度的加权和。为了验证提出的方法,进行了一系列实验。实验结果表明新提出的方法适用于混合数据,并且比其他检测方法更有效。
异常检测;邻域密度;混合数据
1 引言
异常检测是数据挖掘领域的一个重要的研究热点。异常检测的主要目的是发现数据集中明显区别于其他大部分数据的小部分异常数据(也称为异常值)。异常检测已经成功地应用于医疗告警[1]、环境监测[2]、欺诈检测[3]、入侵检测[4],也涉及到软件评价[5]、地理[6]、交通[7]、金融[8]等领域。异常值有两个主要特点,一是异常值的数量是很小的,二是异常值明显区别于其他的数据。
随着异常检测技术的不断发展,人们提出了大量的异常检测方法。异常检测方法通常分为四种:基于密度的方法[9-11]、基于距离的方法[12]、基于深度的方法和基于聚类[13-14]的方法。Yang[15]提出了一个基于核模糊c-means聚类的模糊SVM算法解决异常检测问题。Chen[16]将邻域粗糙集和异常检测相结合,提出了一个基于距离的异常检测方法。Guo[17]提出了一个基于支持向量域描述(SVDD)的后处理方法,这个方法可以有效地解决异常检测问题。从局部分布的角度出发,Zhang[18]引入了局部密度、局部对称度等概念并提出了两个异常检测算法LDBOD和LDBOD+。Cassisi[13]提出了基于密度的聚类算法去处理异常检测。这个算法应用空间分层的思想有效地确定数据集中不同密度的聚类簇,并且引入了相反最近邻域的概念。该方法可以检测不同密度数据集的异常值。
本文提出了一种基于邻域密度的异常检测方法(NDOIA)。在这个方法中,样本的邻域异常指标是该样本的邻域大小和该样本的平均邻域密度的加权和。样本的邻域大小是指某样本的邻域中包含的其他样本的个数,而样本的平均邻域密度则反映了该样本的邻域中其他样本的密度大小。一个样本的基于邻域密度的异常指标能更有效地度量这个样本与其他样本的相异程度。此外,通过引用邻域的概念,新的算法能够处理混合数据集。在这里,混合数据是指混合了数值型属性和名词型属性的数据。为了验证本文提出算法的有效性,进行了一系列的实验,实验结果表明NDOIA能有效地处理混合数据的异常检测问题。
2 基于邻域密度的异常检测方法
通常情况下,一个数据集可以表示成一个信息系统IS=U,A,其中U为对象的非空有限集合,称为论域,A是属性集。对于任意x∈U,定义其邻域为[19]:
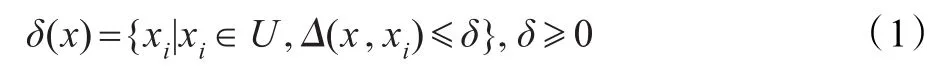
其中Δ是距离函数,对于∀x1,x2,x3∈U,Δ满足下面的条件:
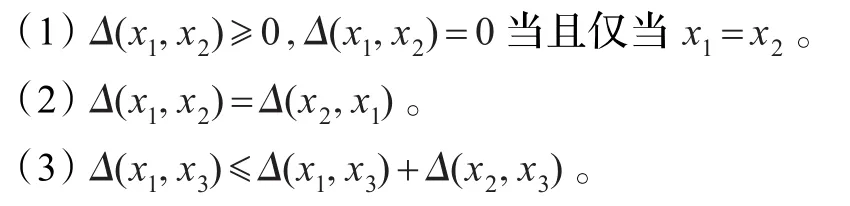
设B1⊆A,B2⊆A,其中B1是数值型属性集,B2是名词型属性集,样本x关于属性集B1,B2和B1∪B2的邻域分别定义为:

基于密度的异常检测方法受到了学术界广泛关注。经典的方法是使用k-nearest-neighbor技术,求所有样本与它们k-nearest-neighbor样本的平均距离,那些平均距离大的样本被认为在属性空间中更偏离大部分样本(或者说与大部分样本有极大差异),因此被认为是异常值。本章提出一种基于邻域密度的异常检测方法。在该方法中,一个样本的异常程度由两个因素决定,一是这个样本的邻域大小,即邻域中样本的个数;二是这个样本的平均邻域密度。因为一个样本的邻域大小不足以说明这个样本在整个属性空间中与周围样本之间的差异,所以引入了下面的定义。
定义1给定一个信息系统IS=U,A,对于任意的xi∈U,x的邻域距离定义为:

定义2给定一个信息系统IS=U,A,对于任意的xi∈U,x的平均邻域密度定义为:
一个样本的平均邻域密度越大,在属性空间中这个样本越有可能位于分布密度大的区域,成为异常值的可能性越小。
定义3给定一个信息系统IS=U,A,对于任意x∈U,基于邻域密度的x的异常度指标定义如下:
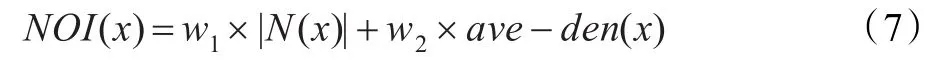
基于邻域密度异常度指标,提出下面的算法。
算法1基于邻域密度的异常检测方法(NDOIA)
输入数据集D
输出异常值集合O

3 实验
为了验证NDOIA,进行下面的实验。从UCI机器学习数据库中选择了9个数据集。这些数据集的具体信息如表1所示,其中有4个混合属性的数据集,3个名词型属性的数据集和2个数值型属性的数据集。接下来,设计两个实验,一个针对分布不均匀的数据集,一个针对分布均匀的数据集。在这两个实验中,对于NDOIA,所有数据集的数值属性都归一化到[0,1]之间,数值属性的邻域阈值被设定为0.2,名词型属性的邻域阈值为0。此外,在NDOIA中,w1为0.4,w2为0.6。
3.1 实验1
Aggarw al[20]提出了一种验证异常检测算法的方法。接下来,通过Aggarwal的验证方法,将本文提出的算法与CBLOF算法[14]和SEQ算法[21]进行对比分析。Aggarwal验证方法简单描述如下:用一个异常检测算法在一个给定的数据集上进行异常值检测,然后计算检测到的异常值属于少数类数据的百分比。在这里,少数类数据是指在数据集中数量少于5%的数据类别,而属于少数类的样本被认为是异常值。例如,数据集Car1包括1 728个样本,这些样本被分为4类“unacc”(70.023%),“acc”(22.222%),“good”(3.993%),“v-good”(3.762%)。很明显,第3类和第4类(“good”和“v-good”)被认为是少数类样本。类似地,另外几个数据集的类分布如表2所示,其中少数类样本用粗体标注。
表3到表8是3种不同的异常检测算法在6个数据集上的计算结果,其中CBLOF表示基于聚类的异常检测算法,SEQ表示基于粗糙集的异常检测算法。另外,“最高比率”表示那些异常度较高的数据个数与其他数据个数的比率;“包含在少数类中的异常值个数”是检测到的异常值属于少数类样本的个数,“覆盖率”是“包含在少数类中的异常值个数”与少数类总样本数的百分比。
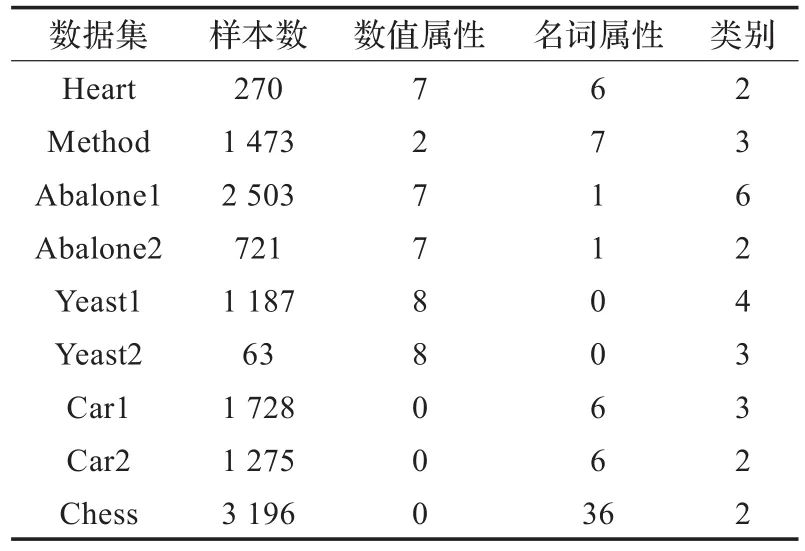
表1 UCI数据集

表2 6个数据集的数据分布
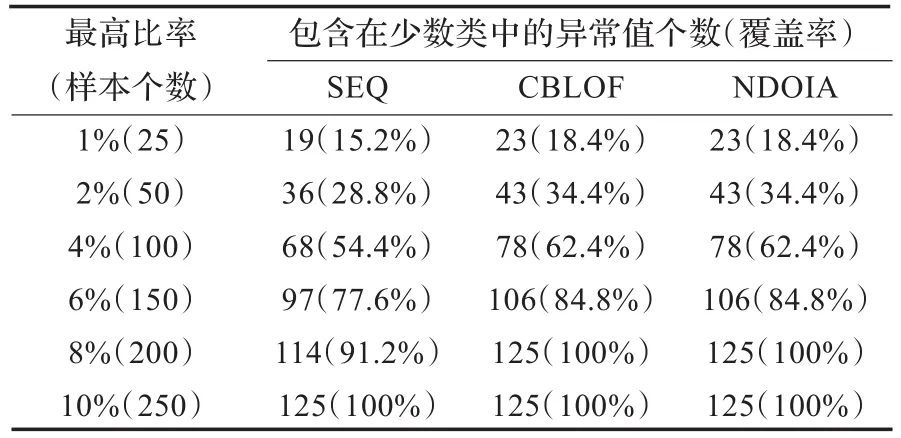
表3 3个算法在Abalone1上的对比结果

表4 3个算法在Abalone2上的对比结果

表5 3个算法在Yeast1上的对比结果
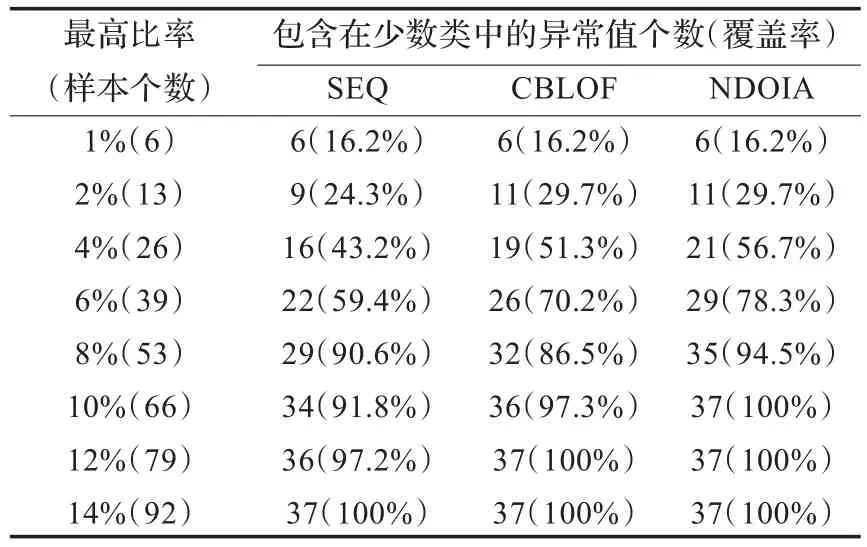
表6 3个算法在Yeast2上的对比结果
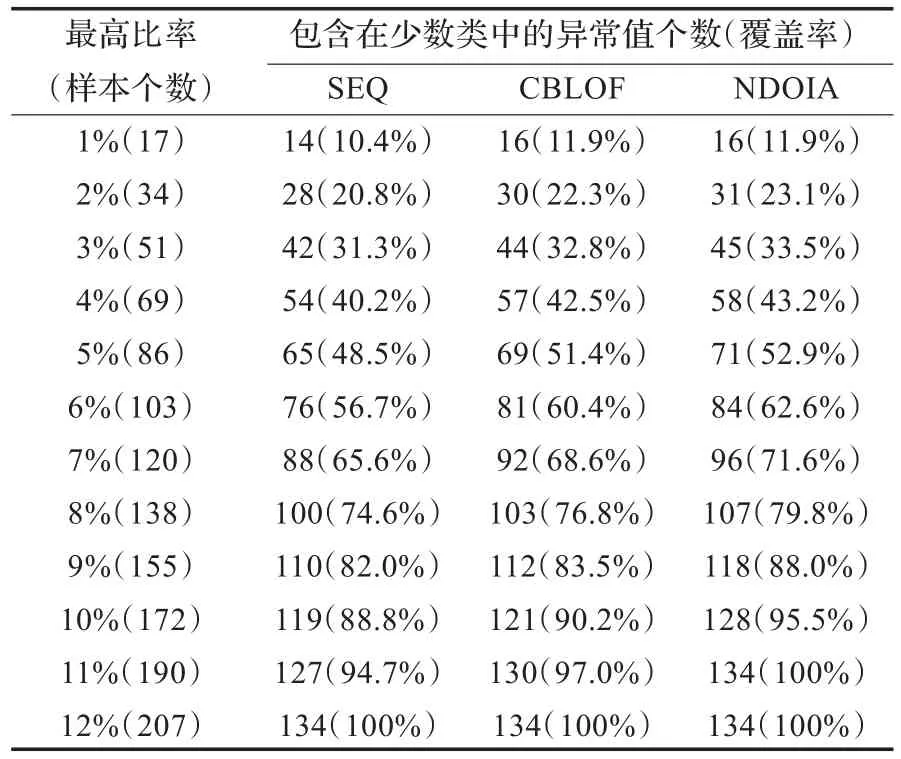
表7 3个算法在Car1上的对比结果

表8 3个算法在Car2上的对比结果
从表3到表8中,可以观察到3个算法都有一个共同的特点,即“覆盖率”的增加程度随着“最高比率”的增加而减小。在表3中,很容易发现,NDOIA和CBLOF的“覆盖率”明显高于SEQ。在表4中,为了检测到所有的32个异常值,NDOIA需要选择43个样本,CBLOF需要选择72个样本,而SEQ则需要选择86个样本。通过观察很容易发现,在表3到表8中,NDOIA算法的比其他两个算法更能有效地检测出异常值。
3.2 实验2
为了进一步验证提出的算法,将NDOIA与其他3个能处理混合属性数据的检测算法进行比较。这3个算法分别是KNN检测算法[22]、PODM算法[23]和NED算法[16]。这里用到的数据集是Heart,Method和Chess。这3个数据集的类分布分别为150∶120,629∶511∶333,和1 669∶1 527。容易发现这些都是分布比较均匀的数据集。因此,用一个类似于文献[23]中提到的方法生成异常值。该方法的具体步骤为:对于一个数据集,随机地从最小分布的那类数据中选择一些样本(小于总样本量的5%)作为一个新的类别,而其他的数据成为一类。Heart,Method和Chess的新数据集分布见表9。Heart1和Heart2是对于Heart选择了不同数量的样本作为少数类,Method1和Method2,以及Chess1和Chess2有相似的表示。特别地,少数类分布由粗体标识。另外,这些数据集的数值型属性值都被归一化到[0,1]。名词型属性的阈值被设定为0,数值型属性的阈值被设定为0.2。这里设定的邻域的阈值同样适用于NED算法。另外,对于KNN异常检测算法,最邻近的大小设定为5(即k=5)。
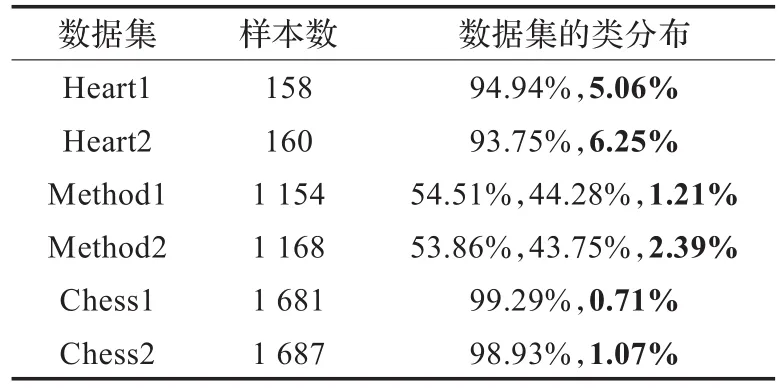
表9 6个数据集的类分布
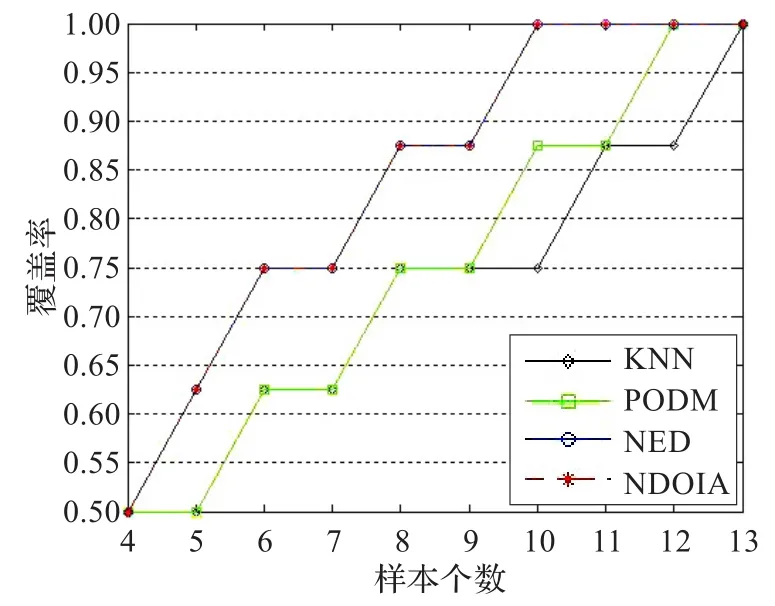
图1 Heart1的覆盖率曲线
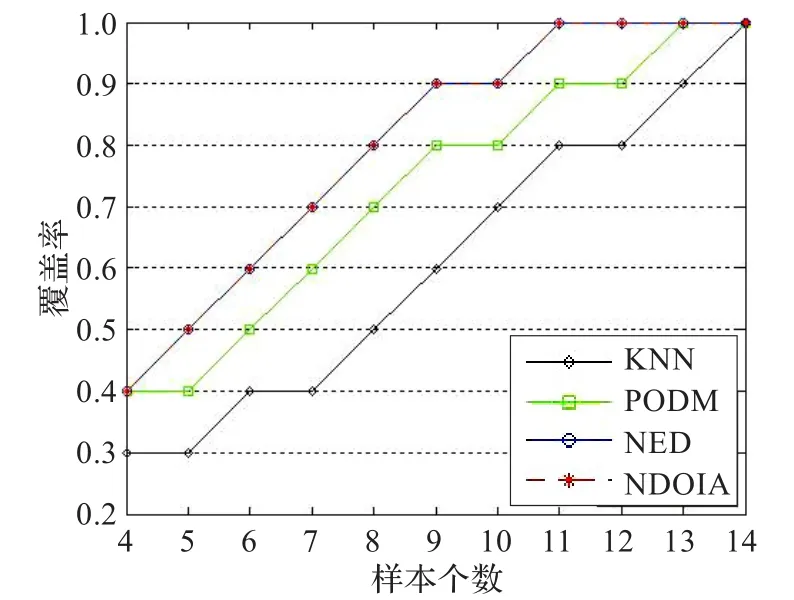
图2 Heart2的覆盖率曲线
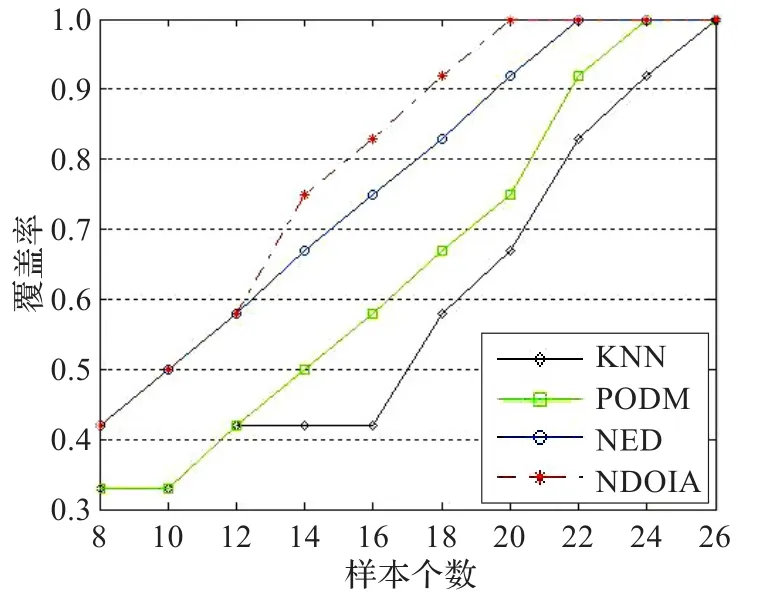
图3 Chess1的覆盖率曲线

图4 Chess2的覆盖率曲线
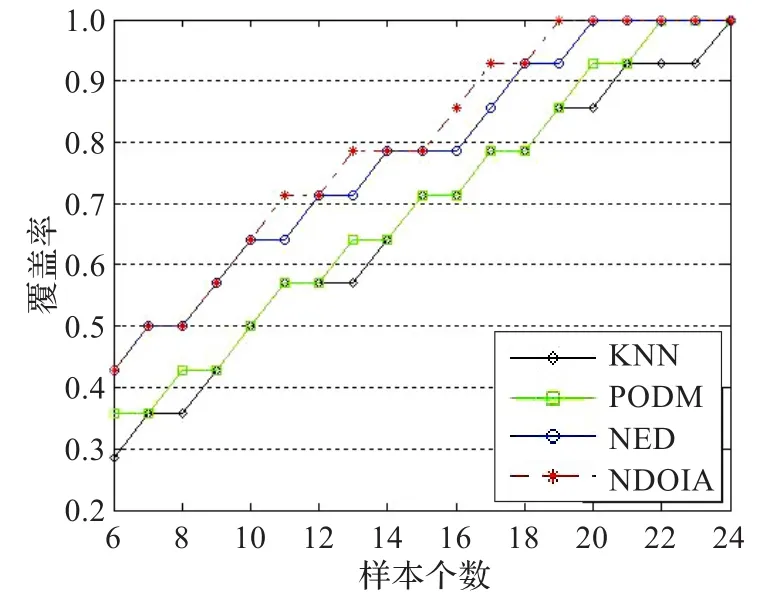
图5 Method1的覆盖率曲线

图6 Method2的覆盖率曲线
为了更直观地比较这4种算法,用上节中提到的Aggarwal方法中的“覆盖率”和“样本个数”的概念,画出了6个数据集的“覆盖率”随着“样本个数”的增加曲线图,具体如图1~6所示。在这里,把图1~6中的曲线称为覆盖率曲线。一个算法的覆盖率曲线下的面积越大,则表示这个算法的检测精度越高。图1和图2是Heart1和Heart2的覆盖率曲线图。发现曲线随着异常值的增加而增加。由表9,知道Heart1和Heart2的异常值分别为8和10个。从图1和图2看到当覆盖率达到1的时候,NDOIA和NED所选择的样本个数分别为10和11,明显低于KNN和PODM。在图1~6中,NDOIA算法的覆盖率曲线下的面积都大于其他算法。总的来说,NODIA适用于混合数据并能有效地检测出异常值。
4 结束语
本文提出了一个基于邻域密度的异常检测方法。这个方法能处理混合属性数据的异常值。在这个方法中,样本的邻域异常指标是该样本的邻域大小和该样本的平均邻域密度的加权和。样本的邻域大小是指某样本的邻域中包含的其他样本的个数。样本的平均邻域密度反映了该样本的邻域中其他样本的密度大小。为了验证新提出算法有效性,把它和其他代表性的算法进行了比较。实验结果表明,提出的方法适用于混合数据,并具有更高的效率。
[1]Hauskrecht M,Batal I,Valko M,et al.Outlier detection for patient monitoring and alerting[J].Journal of Biomedical Information,2013,46(1):47-55.
[2]Garces H,Sbarbaro D.Outliers detection in environmental monitoring databases[J].Engineering Applications of Artificial Intelligence,2011,24(2):341-349.
[3]Richard J B,David J H.Statistical fraud detection:a review(with discussion)[J].Statistical Science,2002,17(3):235-255.
[4]Leckie T,Yasinsac A,Member S.Metadata for anomalybased security protocol attack deduction[J].IEEE Transactions on Knowledge and Data Engineering,2004,16(9):1157-1168.
[5]Alan O,Catal C.Thresholds based outlier detection approach for mining class outliers:an empirical case study on software measurement datasets[J].Expert Systems with Applications,2011,38(4):3440-3445.
[6]Maervoet J,Vens C,Berghe G V,et al.Outlier detection in relational data:a case study in geographical information systems[J].Expert Systems with Applications,2012,39(5):4718-4728.
[7]Chen S Y,Wang W,Zuylen H D.A comparison of outlier detection algorithms for ITS data[J].Expert Systems with Applications,2010,37(2):1169-1178.
[8]Aurea G,Veiga H.Wavelet-based detection of outliers in financial time series[J].Computational Statistics and Data Analysis,2010,54(11):2580-2593.
[9]Breunig M M,Kriegel H P,Raymond T N,et al.LOF:identifying density-based local outliers[C]//Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data,Dallas,USA,2000:93-104.
[10]Kim S,Cho N W,Kang B,et al.Fast outlier detection for very large log data[J].Expert Systems with Applications,2011,38(8):9587-9596.
[11]Pokrajac D,Lazarevic A,Latecki L J.Incremental local outlier detection for data streams[C]//IEEE Symposium on Computational Intelligence and Data Mining(CIDM),Honolulu,Hawaii,2007:504-515.
[12]Knorr E M,Raymond T N,Tucakov V.Distance-based outliers:algorithms and applications[J].VLDB Journal:Very Large Databases,2000,8:237-253.
[13]Cassisi C,Ferro A,Giugno R,et al.Enhancing densitybased clustering:parameter reduction and outlier detection[J].Information Systems,2013,38(3):317-330.
[14]He Z Y,Xu X F,Deng S C.Discovering cluster-based local outliers[J].Pattern Recognition Letters,2003,24(9/10):1641-1650.
[15]Yang X W,Zhang G Q,Lu J,et al.A kernel fuzzy c-means clustering-based fuzzy support vector machine algorithm for classification problems with outliers or noises[J].IEEE Transactions on Fuzzy Systems,2011,19(1):105-115.
[16]Chen Y M,Miao D Q,Zhang H Y.Neighborhood outlier detection[J].Expert Systems with Applications,2010,37(12):8745-8749.
[17]Guo S M,Chena L C,Tsaib J S H.A boundary method for outlier detection based on support vector domain description[J].Pattern Recognition,2009,42(1):77-83.
[18]Zhang Y,Yang S,Wang Y Y.LDBOD:a novel local distribution based outlier detector[J].Pattern Recognition Letters,2008,29(7):967-976.
[19]Hu Q H,Yu D R,Liu J F,et al.Neighborhood rough set based heterogeneous feature subset selection[J].Information Sciences,2008,178(18):3577-3594.
[20]Aggarwal C C,Yu P S.Outlier detection for high dimensional data[C]//Proceedings of the 2001 ACM SIGMOD International Conference on Management of Data,California, 2001:37-46.
[21]Jiang F,Sui Y F,Cao C G.Some issues about outlier detection in rough set theory[J].Expert Systems with Applications,2009,36(1):4680-4687.
[22]Ramaswamy S,Rastogi R,Shim K.Efficient algorithms for mining outliers from large data sets[C]//Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data,Dollas,2000:427-438.
[23]Ye M,Li X,Orlowska M E.Projected outlier detection in high-dimensional mixed-attributes data set[J].Expert Systems with Applications,2009,36(3):7104-7113.
ZHAO Hua,QIN Keyun
School of Mathematics,Southwest Jiaotong University,Chengdu 610031,China
This paper proposes a neighborhood density based outlier detection method, which is applicable to the data with mixed numerical and categorical features. In this method, the outlierness indicator of a sample is defined as the weighted sum of neighborhood cardinality and average neighborhood density of this sample. To validate the effectiveness of this algorithm, it performs a series of experiments. Experimental results show that the proposal is applicable and effective to mixed data.
outlier detection; neighborhood density; mixed data
ZHAO Hua, QIN Keyun. Outlier detection method based on neighborhood density. Computer Engineering and Applications, 2014, 50(17):24-28.
A
TP393
10.3778/j.issn.1002-8331.1401-0320
国家自然科学基金(No.61175044,No.61175055);中央高校基础研究基金(No.SW JTU11ZT29)。
赵华(1980—),女,博士生,主要研究方向为智能信息处理、数据挖掘;秦克云(1962—),男,教授,主要研究方向为智能信息处理、模糊集、粗糙集。E-mail:zzh8008@gmail.com
2014-01-20
2014-03-07
1002-8331(2014)17-0024-05
CNKI网络优先出版:2014-03-19,http://www.cnki.net/kcms/doi/10.3778/j.issn.1002-8331.1401-0320.htm l
猜你喜欢
今日农业(2022年15期)2022-09-20
今日农业(2021年21期)2021-11-26
小学生学习指导(低年级)(2021年9期)2021-10-14
吉林大学学报(理学版)(2020年3期)2020-05-29
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
小学生学习指导(低年级)(2018年9期)2018-09-26
自动化学报(2018年7期)2018-08-20
周口师范学院学报(2016年5期)2016-10-17
西南交通大学学报(2016年6期)2016-05-04
