
改进的粗糙模糊和模糊粗糙K-均值聚类算法
2014-07-08 08:32田大增吴静
计算机工程与应用 2014年17期
田大增,吴静
1.河北大学物理科学与技术学院,河北保定 071002
2.河北大学数学与计算机学院,河北保定 071002
改进的粗糙模糊和模糊粗糙K-均值聚类算法
田大增1,吴静2
1.河北大学物理科学与技术学院,河北保定 071002
2.河北大学数学与计算机学院,河北保定 071002
在分析归纳原有聚类方法不足的基础上,结合粗糙理论和模糊理论,给出了改进的粗糙模糊K-均值聚类算法;设计了新的模糊粗糙K-均值聚类算法,并验证了该聚类算法的有效性;进而将这两种聚类算法应用到支持向量机中,对训练样本做预处理,以减少样本数目,提高了其训练速度和分类精度。
粗糙模糊K-均值聚类;模糊粗糙K-均值聚类;支持向量机
1 引言
随着信息技术的迅猛发展和人们搜集数据能力的日益增强,大量的数据库被用于商业管理、政府办公、科学研究和工程开发等领域。因此数据挖掘(Data mining)和知识发现技术应运而生,并得以蓬勃发展,越来越显示出其强大的生命力。数据挖掘已经引起了人们的广泛关注,成为国内外数据库和信息决策领域的最前沿研究方向[1-3]。
聚类[4]是数据挖掘领域最为常用的技术之一。随着计算机的发展和实际问题的需要,基于目标函数的聚类方法已成为聚类分析的主流。一方面是由于可以将聚类问题表述成优化问题,易与非线性规划领域联系起来,可用现代数学方法来求解;另一方面是由于计算机可以比较容易地实现算法的求解过程。各种聚类算法已经在许多领域得到了广泛的应用,在图像处理中被应用于图像分割[5]、图像增强、图像压缩等;在模式识别[6]中,被用于语音识别、雷达目标识别;此外还可以用于模糊推理规则的建立、医学诊断[7]等。目前,对聚类算法的研究也不断深入,利用其已有算法的优势,改进其不足,提出了改进的粗糙模糊K-均值聚类算法和粗糙模糊K-均值聚类算法,使聚类算法更能反映客观世界。
支持向量机(Support Vector Machine,SVM)[8-9]是数据挖掘中的一项技术,是借助于最优化方法解决机器学习问题的工具。它是Vapnik在统计学习理论基础上提出的一类机器学习算法。正因为支持向量机的提出,才促进了统计学习理论的应用得到了发展。支持向量机与传统机器学习方法相比,在解决小样本、高维度以及非线性问题上具有明显的优势。但是,支持向量机作为一种技术,目前仍存在许多局限。SVM的研究主要有两类问题亟待解决[10],一方面由于训练样本多导致训练时间可能很长,从而影响到其应用;另一方面,尽管支持向量机方法具有较好的推广能力,但是由于在构造最优分类面时所有训练样本被认为对最优超平面具有相同的作用,所以当训练样本中含有噪声与野值样本时,由于这些含有异常信息的样本在特征空间中常常位于分类面附近,因此导致获得的分类面不是真正的最优超平面。
针对以上问题,如果能够使用某种方法对支持向量机样本进行预处理,既减少训练样本个数,又可以保留样本的属性特征,使得在提高支持向量机的训练速度的同时又能保证支持向量机的分类精度。本文提出的聚类算法,对支持向量机的训练样本进行预处理,能够减少样本数目,提高训练速度;与此同时,又通过定义的一种基于样本紧密度的新的模糊隶属函数,能够减少样本中噪声点、孤立点对分类的影响,从而提高分类精度。
2 粗糙模糊K-均值(RFKM)聚类算法的改进算法
RFKM算法是基于粗糙集的上、下近似的概念改进了FKM的目标函数,从而改变了隶属度函数的分布,使得隶属度函数的分布更加合理,同时RFKM的时间复杂性比FKM更低。

其中Ai称为上近似限,上近似限刻画了所有可能属于第i类的对象的边界,若某个对象不属于上近似限所界定的范围,则它属于这个类的负域,即完全不属于这个类。
定义2[11]粗糙模糊K-均值算法的目标函数为:
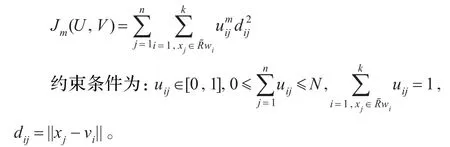
同样可以得到粗糙模糊K-均值算法的迭代公式:
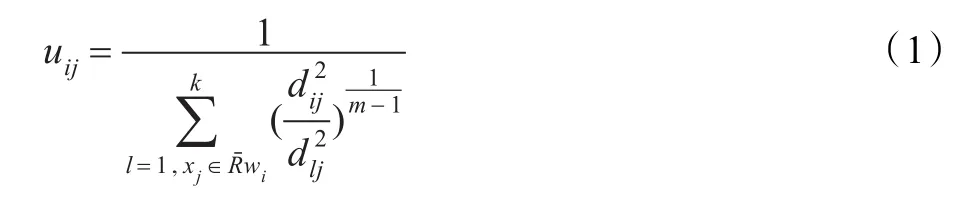
质心计算公式不变:

从RFKM算法很容易得到以下两个性质:
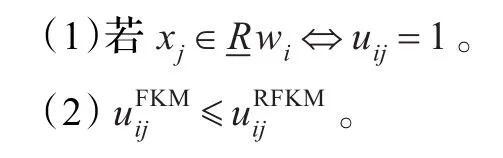
下面具体给出RFKM算法的步骤[11]:
(1)确定类数k(2≤k≤n)、参数m、初始矩阵、类的上近似边界Ai和一个适当小数ε>0,s=0。
(3)若xj∉wi,则uij=0,否则按式(11)更新。
(4)若||U(s)-U(s+1)||<ε,则停止,否则,s=s+1,转步骤(2)。
RFKM算法的主要思想是把属于某个类的对象分成了肯定的、可能的和否定的三个集合,以所有可能的对象的最小类内平方误差和为聚类准则进行聚类。RFKM算法和FKM算法最大的不同在于,它认为xj属于wi的隶属度uij的计算只与上近似中包含xj的类有关,若某个类wk的上近似中不包含xj,则这个类对xj的隶属度是没有任何贡献的。
对于上述粗糙模糊K-均值聚类的算法,由于引进了归一化条件,则在样本不理想的情况下会导致不好的效果。比如,如果某个样本远离欧氏距离的类中心,本来它隶属各类的隶属度都很小,但由于归一化的要求,将会使它对各类都有较大的隶属度,最终将影响迭代的结果。本文对聚类中隶属函数进行了改进,从而有效地改进了这些问题。
考虑放松对隶属度归一化的要求,改变隶属度函数的约束条件,将会对噪声数据有较好的处理能力。则要求算法中各个数据点的隶属度只需满足大于零的条件,并且更新了目标函数。通过这种方法产生的各个聚类中心之间相互独立,即某一点中心的改变不会影响到其他的类中心,因此,改进后的隶属度可以解释为数据点属于某一类的绝对程度。
改进算法的目标函数为:
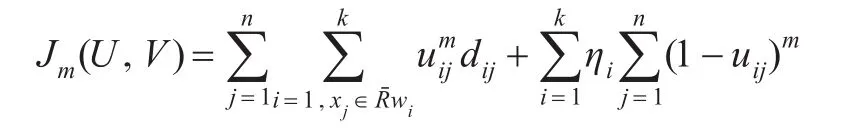
其中uij∈[0,1],ηi(i=1,2,…,k)是一个合适的正整数。
利用Lagrange乘数法,可以得到使目标函数取得最小值的条件如下:
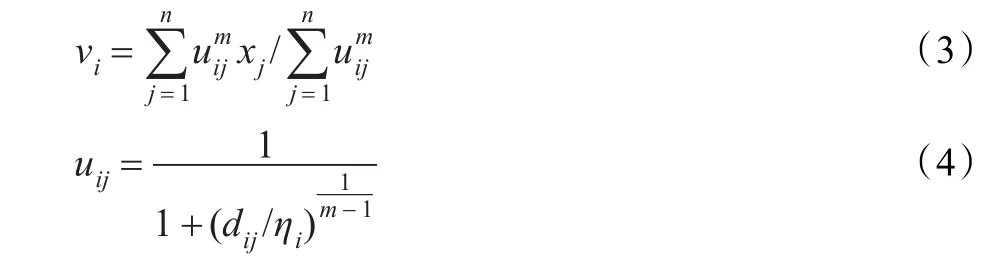
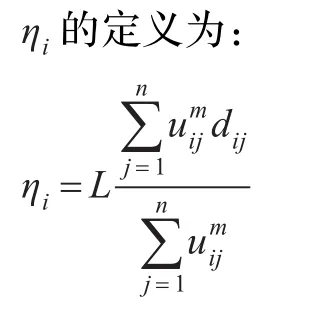
一般L取值为1,ηi值控制各个聚类原型之间的距离,其中xj∈wi。
下面具体给出改进后的RFKM算法的步骤:
(1)确定类数k(2≤k≤n)、参数m、初始矩阵、类的上近似边界Ai和一个适当小数ε>0,s=0。
(3)若xj∉wi,则uij=0,否则按式(4)更新。
(4)如果‖Us-Us+1‖≤ε,迭代终止,否则令s=s+1,返回步骤(2)。
但是在应用中应该注意到,当上近似限取得足够大时,RFKM算法退化为FKM算法或改进的FKM算法,不同数据集的分布不同,得到Ai理论上的计算公式是困难的一件事情,只能采取一些经验的方法来确定其上近似限。上近似限取值宜大不宜过小,上近似限取得过小,会使得聚类错误率过高。同时不同类之间的上近似限应该尽量地有差别,上近似限不同才能使得不同的类分开的可能性增大。这样做可以减小对初始隶属度矩阵的依赖。
3 模糊粗糙K-均值(FRKM)聚类算法及聚类有效性
3.1 模糊粗糙K-均值聚类算法
该算法是对粗糙K-均值聚类算法的一个改进,为每一个样本点定义一个模糊隶属函数,使每个样本点对聚类中心的调节作用因隶属度的不同而有差别,提高聚类精度。
设数据集合X={x1,x2,…,xn},聚类中心M={m1,m2,…,mk}(本文中用(mi),(mi)表示mi对应聚类簇的上,下近似集),用d(xi,mj)表示第i个对象到第j个聚类中心的距离。令表示对象xi到最近的簇中心ml的距离。相应的聚类中心作如下修改,公式如下:

其中wl,wp分别表示第k个簇的下近似集和边界集在求簇中心时的权重,且wl+wp=1,且由于下近似集对簇中心的影响大,要尽量减少边界集中的对象对聚类中心的影响,一般wl>wp,则在基于粗糙K-均值聚类的基础上,基于粗糙模糊K-均值聚类的聚类算法可描述为:
(1)初始化指数因子m,权重wl,wp,阈值ε(ε∈[0,1]),停止误差δ(δ∈[0,1]),聚类数k,整数s=0。
(2)令数据集合X={x1,x2,…,xn},随机选取k个初始聚类中心M(s)。
(3)设xi为待聚类的向量,如果对于任意的d(xi,mj),0≤j≤k,有d(xi,mj)-dil≤ε,则xi属于(ml),xi属于(mj);否则d(xi,mj)-dil>ε,有xi属于(ml)。其中l≠j,0≤l,j≤k。
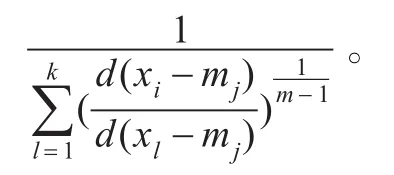
(5)按照公式(5)调节聚类中心,得到新的聚类中心M(s+1)。
该算法利用粗糙K-均值算法的优势,并在此基础上引进模糊隶属函数,使每个样本在属于每个粗糙集时具有不同的程度,提高了聚类的精度,并减小了孤立点对聚类的影响。
3.2 聚类的有效性
初始化阈值是对数据进行初始化聚类划分的依据,K均值算法采用随机法选取初始聚类中心,选取点的不同,聚类结果可能就不同,这样的依赖性就导致聚类结果的不稳定性,且容易陷入局部最优而非全局最优聚类结果。而文中提出的改进FRKM聚类算法是在RKM基础上改进的,引入了模糊的思想,通过引入聚类簇的隶属度的概念,改进了划分阈值的敏感性和对于数据比例变换缺乏鲁棒性的缺陷,克服了硬划分算法的缺陷。
从以上模糊粗糙K-均值聚类算法中可以看出,聚类的结果受分类数k和参数m及初始聚类中心的影响,使其在选择不同参数时正确率存在差异。所以有必要判断聚类的有效性。以保证聚类的正确率,从而保证将聚类中心作为训练样本的有效性。最有效的聚类应在类内紧凑度与类间分离度之间找到一个平衡点,以获得最好的聚类。本文采用Xie和Beni提出的基于紧密度和分离度的有效性函数[12]作为判断模糊粗糙K-均值聚类算法有效性的指标。有效性函数为:
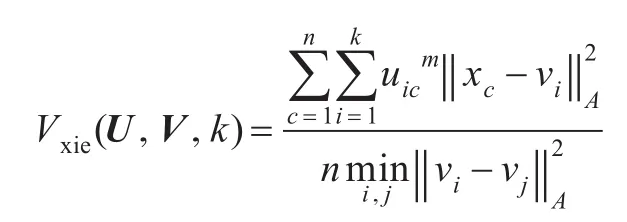
其中U是隶属度矩阵,V是聚类中心矩阵,k是聚类中心数,uic表示U中元素,vi表示V中第i行。分子表示聚类的紧密度,分母表示聚类的分离度。在类内紧凑度和类间分离度之间找一个平衡点,使其达到最小,从而获得最好的聚类效果。而Vxie越小,表示所有聚类紧密且相互独立,即为最优聚类。
4 两种聚类算法的比较
文中引入了RFKM聚类和FRKM聚类这两种算法,下面简要说明和比较两种算法:
(1)RFKM聚类算法在FKM基础上利用粗糙集的上、下近似的概念,改进了模糊隶属度矩阵的分布,使该分布更加合理,同时RFKM的时间复杂性比FKM更低。
(2)RFKM聚类算法中引入了上近似界这个参数。而在该算法中,这个参数的选取与调节至关重要。而在现有研究基础上,只能用经验来确定。这一点需要在将来进一步研究,来完善该算法的性能。而FRKM聚类算法中把模糊隶属度作为了聚类中心调节的权重,意在使用模糊隶属度来表示数据对于中心的调节各自的贡献不同,从而提高聚类的有效性,但聚类中心的调节公式还有待于进一步完善。
两种算法在一些数据处理方面各有利弊,则要求在以后的学习、研究中继承其优势,改进其缺陷,进一步完善聚类算法。
5 实验结果与分析
为了更好地实现FRKM聚类算法,在Matlab环境下用frkm_classify,frkm_calcU,frkm_center这三个主要函数来体现这个聚类的过程。函数frkm_classify是实现了FRKM聚类过程中的归类过程,从而构成了聚类中心数对应的上,下近似集。函数frkm_calcU是更新隶属度矩阵的过程。在聚类算法中,把模糊隶属度引进到聚类中心调整中,使各个样本对聚类中心的作用各不相同。函数frkm_center在训练阶段,要对两类样本分别进行聚类的预处理,作用是计算,从而更新聚类中心。本文使用FRKM聚类算法。输出每一类的聚类中心,然后用输出的聚类中心做为SVM的新的训练数据进行训练。SVM训练核函数选用线性核函数K(x,xi)= exp(-g‖x-xi‖2),分类阈值ε=0.1,g=0.5。分别对以下两组经典数据进行测试:
选定数据集cancer为从经典数据集的Cancer数据集中随机选取的,取150个作为训练样本,50个作为检验样本,其中训练样本中1类数据为84个,-1类数据为66个。分别对1类和-1类数据进行聚类,得到聚类中心。经聚类有效性判断知:当l类数据参数分别为c=10,m=2,ε=0.1,-1类参数分别为c=10,m=2,ε=0.1时,为最优聚类。
选定数据集spambase是从经典数据集的Spambase数据集中随机选取的,此数据集共有训练样本个数1 187个,测试样本个数40个,维数均为24维。其中训练样本中-1类数据568个,1类数据619个。分别对1类和-1类数据进行聚类,得到聚类中心。经聚类有效性判断知:当l类数据参数分别为c=100,m=2,ε=0.1,-1类参数分别为c=100,m=2,ε=0.1时,为最优聚类。实验结果见表1。
从实验结果可以看到,采用原训练数据的有效聚类中心作为新的训练数据,从而大大减少了训练样本个数,加快了样本的训练速度。同时,RFKM和FRKM聚类算法的有效性和聚类中心的代表性避免了噪声样本成为训练样本的可能性,从而提高了训练精度,而且FRKM+SVM要比RFKM+SVM精度更高一点。并且,随着训练数据的增加,FRKM+SVM算法的优势愈加明显。
6 结论
通过分析聚类算法和SVM算法的优缺点,本文在模糊K-均值聚类和粗糙K-均值聚类的基础上提出了粗

表1 RFKM+SVM算法、FRKM+SVM算法与SVM算法计算结果
糙模糊K-均值聚类(RFKM)的改进和模糊粗糙K-均值聚类(FRKM)算法,用RFKM和FRKM聚类算法对数据进行预处理,从而减少了样本个数,提高了支持向量机训练精度和速度。
[1]刘小华,胡学钢.数据挖掘的应用综述[J].信息技术,2009,21(9):149-152.
[2]化柏林.数据挖掘与知识发现关系探析[J].情报理论与实践,2008,31(4):507-510.
[3]黄艳玲.数据挖掘在医学领域中的文献发展评价[J].现代医院,2007,7(1):145-147.
[4]Andrew S T.Computer networks[M].Beijing:Tsinghua University Press,2003.
[5]朱嵬鹏,王世同.基于空间模式聚类的彩色图像分割[J].计算机工程与应用,2009,45(34):161-163.
[6]吕佳.核聚类算法及其在模式识别中的应用[J].重庆师范大学学报:自然科学版,2006,23(1):22-24.
[7]刘木清,周德成,徐新元.聚类算法用于中药材的近红外光谱分析[J].光谱学与光谱分析,2007,27(10):1985-1988.
[8]Vapnik V N.Statistical learning theory[M].New York:Wiley-Interscience Publication,1998.
[9]Vapnik V N,Chervonenkis A Y.The necessary and sufficient conditions for consistency of the method of empirical risk minimization[J].Yearbook of the Academ y of Sciences of the USSR on Recognition,Classification and Forecasting,Nauka,Moscow,1998,2:207-249.
[10]黄啸.支持向量机核函数的研究[D].江苏苏州:苏州大学,2008.
[11]王丹,吴孟达.粗糙模糊C-均值算法及其在图像聚类中的应用[J].国防科技大学学报,2007,29(2):76-80.
[12]Xie X L,Beni G.A validity measure for fuzzy clustering[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1991,13(8):841-847.
TIAN Dazeng1,WU Jing2
1.Faculty of Physics Science and Technology,Hebei University,Baoding,Hebei 071002,China
2.Faculty of Mathematics and Computer Science,Hebei University,Baoding,Hebei 071002,China
The shortcomings of the original clustering methods are analyzed. Moreover, the rough theory and fuzzy theory are combined together. The improvement of rough fuzzy K-means clustering algorithm is given. A fuzzy rough K-means clustering algorithm is designed, and the validity of fuzzy rough K-means clustering algorithm is verified. The proposed clustering algorithms are applied to support vector machine. In the above applications, the training samples are pre-processed to reduce the number of samples and improve the training speed and the classification accuracy.
rough fuzzy K-mean clustering;fuzzy rough K-mean clustering;support vector machine
TIAN Dazeng, WU Jing. Improvement of rough fuzzy and fuzzy rough clustering algorithm. Computer Engineering and Applications, 2014, 50(17):142-145.
A
TP311.13
10.3778/j.issn.1002-8331.1210-0203
国家自然科学基金(No.61073121);河北省自然科学基金(No.A 2012201033,No.F2012402037);河北省教育厅自然科学青年基金(No.Q2012046)。
田大增(1965—),男,博士,教授,硕士生导师,主要从事不确定统计学习理论和支持向量机等方面的研究;吴静(1984—),女,硕士,主要从事支持向量机等方面的研究。E-mail:tdz19651204@hbu.cn
2012-10-19
2012-11-26
1002-8331(2014)17-0142-04
CNKI网络优先出版:2013-01-11,http://www.cnki.net/kcm s/detail/11.2127.TP.20130111.0953.019.htm l
猜你喜欢
科技创新与应用(2020年6期)2020-02-29
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
电子设计工程(2015年6期)2015-02-27
数学年刊A辑(中文版)(2014年4期)2014-10-30
