
基于HEVC屏幕图像编码的哈希表的优化算法
2014-07-08 08:32金小娟张培君林涛
计算机工程与应用 2014年17期
金小娟,张培君,林涛
同济大学超大规模集成电路研究所,上海 200092
◎图形图像处理◎
基于HEVC屏幕图像编码的哈希表的优化算法
金小娟,张培君,林涛
同济大学超大规模集成电路研究所,上海 200092
仿2维匹配算法对屏幕图像中的非连续色调区域有很好的压缩性能,但该算法中哈希表的空间开销较大,不利于硬件实现。为了减小哈希表的空间,通过对原算法优化提出了一种3字节计算哈希值方法,将源数据看作是一个由以YUV三元组为元素组成的数据集合,然后以YUV三元组为单位计算哈希值,这样不但减少了哈希值的计算量,而且使哈希表的存储空间得到很大的节省。实验结果表明,3字节计算哈希值方法使哈希表的存储空间减少为原算法的1/3,所测试屏幕图像的BD-rate性能也有所提高。
高效率视频编码(HEVC);仿2维匹配算法;屏幕图像;哈希表
1 引言
随着移动互联网的快速发展,“云计算”中的大量多媒体不仅引起了IT界的广泛关注,同时也引起了公众的广泛关注。众所周知,传输数据的带宽有限,通信系统不可能同时满足众多用户高速访问高分辨率的视频资源。因此,屏幕图像编码(Screen Content Coding)在通讯和网络领域中成为学者们讨论的热点话题。
2010年,ISO-IEC/MPEG和ITU-T/VCEG成立了JCT-VC(Joint Collaborative Team on Video Coding)合作开发下一代视频编码标准,即HEVC(High Efficiency Video Coding),HEVC设计目标是在相同图像质量的条件下,比特率比H.264/AVC减少50%。为了使视频达到高清晰度、高帧率和高压缩率,HEVC进行了大量的技术创新,比如基于四叉树的编码结构、自适应样点补偿SAO(Sample Adaptive Offset),宏块的大小由H.264/AVC中的16×16扩展到了64×64,以提高对高清、超高清视频的编码效率。HEVC采用基于四叉树的编码结构来提高编码效率,包括编码单元CU(CodingUnit)、预测单元PU(Prediction Unit)和变换单元TU(Transform Unit),其中,分割的最大编码单元被称为LCU(Largest Coding Unit)。SAO位于编解码环路内,它将重建后的图像进行归类,然后对每一类图像的像素值加减一个偏移,尽量减少失真[1-5]。
屏幕图像包括由摄像机捕捉得到的连续色调内容和由计算机产生的非连续色调内容,详见文献[6-8]。针对屏幕图像各向异性的特点,仿2维匹配算法很好地解决了比特率、编码质量和编码复杂性三者之间的矛盾。在编码YUV 444过程中,仿2维匹配算法通过建立哈希表寻找最佳匹配字符串,哈希表通过查表和链表搜索快速查找首个3字节匹配样本,然后逐字节搜索找到匹配最长的字符串,文献[9-14]的实验数据证明了仿2维匹配算法在对非连续色调内容编码时比HEVC编码器具有更高的编码效率,但是仿2维匹配算法为达到快速而高效地匹配所建立的哈希表占用了很大的存储空间,不利于硬件实现。
基于上述因素,再充分利用数据存储格式的特点,本文对原算法进行了优化,提出一种3字节计算哈希值方法,实验结果表明在不影响主观质量的前提下,3字节计算哈希值方法使得哈希表的存储空间减少为原来的1/3。
2 仿2维匹配算法
实际信源若不经过信源编码,会存在大量的冗余信息。仿2维匹配算法的目的是尽可能地减少冗余信息,该算法是从已编码的历史数据中寻找和当前待编码数据相匹配的字符串,如果匹配成功,就将(匹配距离,匹配长度)作为一个数据对代替当前待编码字符串,实现了用最少的信息比特来表示信源,减少信源冗余度,其中已编码历史数据的集合称为字典,将2维的图像数据以宏块为单位转换成1维序列,然后在1维序列上应用上述匹配算法,因此称为仿2维匹配算法。仿2维匹配算法和HEVC有机融合后组成的双编码器系统,有效改善了HEVC对屏幕图像的编码性能[15-19]。随着编码过程的不断进行,历史数据越来越多,这给匹配搜索造成了很大的困难,为了能实时高效地寻找到与当前字节匹配的字符串,将已编码的数据每三个字节计算一个哈希值HashValue,并将哈希值作为历史数据的索引存储在哈希表中,因此通过哈希表可以快速定位与当前三字节开头的字符串可能发生匹配的字符串位置,其中哈希值的计算是逐字节进行的,文献[6]中采用这种计算哈希值的方法,本文中称为逐字节计算哈希值方法。哈希表分为两部分:Base表和Son表,其中Base表用来存放哈希链表的首节点,Son表用来存放哈希值相同的历史节点,最新的哈希值存放在链表首部,在匹配过程中通过哈希表来访问哈希值相同的所有历史数据,从而快速定位可能与当前字节可能存在匹配的历史数据位置。仿2维匹配算法原理如图1所示。
逐字节计算哈希值方法具体步骤如下:
(1)读入YUV 444格式数据,把图像分割成不重叠的宏块/LCU,然后将数据以宏块/LCU为单位重排成Packed格式。
(2)计算当前三元组的哈希值,并将其对应数据节点位置存入Base表。
(3)在哈希表中找到和当前哈希值相同的上一个历史数据位置,开始逐字节匹配搜索,同时,把当前节点位置存入哈希表。
(4)在匹配搜索的过程中,根据匹配距离对当前节点和历史节点逐字节进行匹配搜索,寻找最优匹配,即字符串的匹配长度最大化,如果搜索进程没有到达该哈希值所在链表的末尾,转步骤(3)。
(5)如果最佳匹配长度小于2个字节,则认为没有找到匹配,输出当前字节;反之,记录并存储最优的(匹配距离,匹配长度)。
(6)指针向后移动一个字节,转步骤(2)。
字典有4个等级,用字典等级(level)表示,字典等级决定字典的大小,字典越大,匹配过程中可参考的历史数据越多,字符串的匹配效果越好,仿2维匹配算法性能就越好。但是当字典越大时,匹配搜索的时间和空间开销越大,使得移动或嵌入式设备的硬件实现越难,因此根据字典的大小将字典分为4个等级,分别对应不同大小的字典和哈希表,字典等级作为编码参数进行设置,以此满足不同的应用设求。定义Hs为哈希表大小,HSs为Son表大小,HBs为Base表大小,哈希表、Base表、Son表的大小与字典等级level之间的函数关系见公式(1)~(4):

图1 仿2维匹配算法原理图
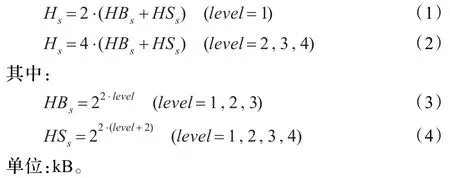
当level=1时,字典的大小为64 kB,Son表中需要64 kB个单元和字典中的位置一一对应,2个字节能表示的最大值是64 kB,所以哈希表的每个单元分配2个字节即可,用公式(1)计算哈希表的大小;当level>1时,字典大小超过了64 kB,必须为哈希表的每个单元分配4个字节,用公式(2)计算哈希表的大小。Base表和Son表的大小均由字典等级(level)决定,字典的大小等于Son表的大小。不同的字典等级对应不同大小的Base表和Son表,Base表和Son表的大小与字典等级之间的函数关系分别由公式(3)(4)表示。当level=4时,为了节省内存空间,设定Base表大小和level=3时Base表大小一样。逐字节计算哈希值方法中字典等级与字典、哈希表三者之间的大小关系如表1所示。

表1 逐字节计算哈希值方法中哈希表大小
由表1可以看出,在逐字节计算哈希值方法中,随着字典等级的增大,哈希表的存储空间明显增大,当字典等级等于4时,哈希表的存储空间达到了16 644 kB。
3 3字节计算哈希值方法
YUV数据的存储格式有两种:Planar格式和Packed格式。Planar格式将YUV三个分量分开保存,而Packed格式将相邻YUV三个分量打包形成一个三元组进行保存,因此在Packed格式中信源数据可被看作是一个以YUV三元组组成的数据集合。YUV的两种存储格式如图2所示。
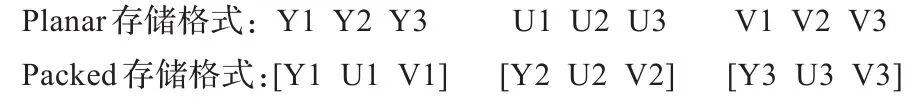
图2 YUV的两种存储格式
为了进一步提高字符串匹配效率,仿2维匹配算法在匹配搜索前,首先将当前宏块的数据重排列成Packed格式,使YUV分量转变为三元组形式存放,YUV 444数据重排列成packed格式,将其对应位置Pos标示出来,如图3所示。

图3 YUV 444数据和其对应位置Pos的关系图
在逐字节计算哈希值方法中,计算每个Pos处相邻3个字节的哈希值,并将其全部放入哈希表中,若在搜索匹配过程中找到哈希值与当前哈希值相同的Pos时,开始逐字节匹配,逐字节计算哈希值方法不仅使匹配效率很慢,而且哈希表占用的存储空间很大。对15幅屏幕图像进行编码统计,得到Len-C图,其中Len为字符串匹配长度,其最大长度为273,C为字符串匹配长度为Len的个数,为了观察方便,图4中Len的取值范围是0~99。

图4 Len-C关系图
从图4中,可以发现当Len等于3的倍数时,C具有局部极大值,而当Len等于其他值时,C相对较小,即大部分最佳匹配长度都是3的倍数。如果哈希表中的Son表只存储3的倍数处的Pos,这样不仅可以保证仿2维匹配算法良好的匹配性能,而且可以使Son表的存储空间减少为原来的1/3,匹配搜索时间也会减少。所以对逐字节计算哈希值方法的第(6)步进行改进,指针向后移动3个字节而不是一个字节,直接计算下一个YUV三元组的哈希值,再进行匹配搜索,这样在匹配搜索过程中不再是逐字节搜索,而是以3个字节进行匹配搜索,此方法称为3字节计算哈希值方法。3字节计算哈希值方法不仅提高了仿2维匹配算法的速度,而且减少了哈希表的存储空间。
3字节计算哈希值方法中,哈希Son表大小的计算公式需要修正,公式(4)修正后得到公式(5):
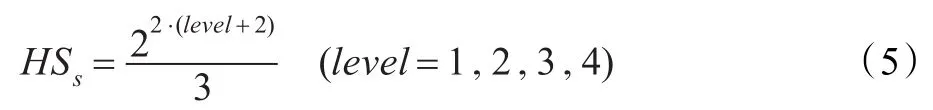
根据公式(1)、(2)、(3)和(5)可计算得到3字节计算哈希值方法中字典等级和字典、哈希表三个变量之间的大小关系,如表2所示。
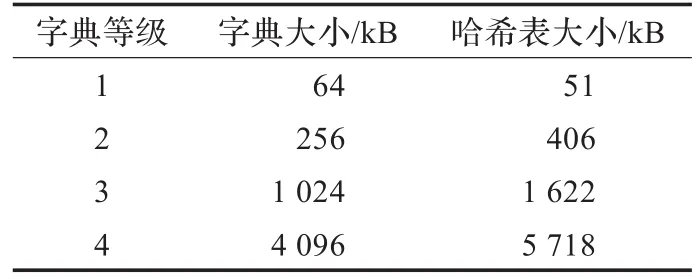
表2 3字节计算哈希值方法中哈希表大小
比较表1和表2可以发现,3字节计算哈希值方法中哈希表大小明显有所减少,尤其当字典等级等于4时,哈希表的存储空间仅为5 718 kB,减少为原方法中16 644 kB的1/3,而且实验测试结果表明屏幕图像的BD-rate性能还有所提高。
图3所示的YUV数据每3个字节看作一个像素值,则3字节计算哈希值方法相当于每个像素计算一个哈希值存入哈希表,相对于逐字节算法的每相邻3个字节计算1个哈希值,3字节计算哈希值方法中Son表的存储空间减少为原算法的1/3,因此也可将3字节计算哈希值方法称为1/3算法,那么就可以将这种方法扩展为1/n算法,即



式(8)表示1/8算法是在1/3算法的基础上跳过了1/6和1/24像素点计算,哈希表空间减少为逐字节算法的1/8。
4 实验结果
为了验证仿2维匹配算法的3字节计算哈希值方法优于逐字节计算哈希值方法,本文提出的算法是在参考软件HM 8.0的基础上实现的,测试环境如表3所示。
本文选用了图5所示的4组测试序列都是JCT-VC会议上用于测试HEVC在SCC方面性能的屏幕图像。图5(a)是波形图,图5(b)是PCB板设计图,图5(a)、(b)两幅图像都以黑色和线条为主,包含少量颜色的文字,属于非连续色调居多的屏幕图像,用来测试本文提出的3字节计算哈希值方法对于非连续色调内容的适应性。图5(c)是一类网页屏幕图像,图5(d)是一类办公场景的屏幕图像,图5(c)、(d)两幅图像不仅包含大量的文字,而且包含很多自然图像,这一类图像具有较多的纹理细节,可以认为属于连续色调居多的屏幕图像。分别用仿2维匹配算法的逐字节计算哈希值方法和3字节计算哈希值方法对屏幕图像编码后在不同字典等级(level)下进行编解码实验,4幅屏幕图像的BD-rate性能比较结果如表4所示,根据HEVC统一的评价准则,若BD-rate为正,表示逐字节计算哈希值方法的性能较好;若BD-rate为负,表示3字节计算哈希值方法的性能较好。

表3 测试环境

图5 屏幕图像
从表4中的BD-rate性能比较结果可以得到以下结论:
(1)和逐字节计算哈希值方法相比,本文提出的3字节计算哈希值方法将哈希Son表的大小减小为原方法的1/3,虽然哈希Son表只记录了1/3的历史数据位置,但实际上保留了可能存在最优匹配的所有位置,摒弃了大部分低效率的位置记录。因此,3字节计算哈希值不仅提高了算法的时间空间效率,而且提高了算法的匹配性能。
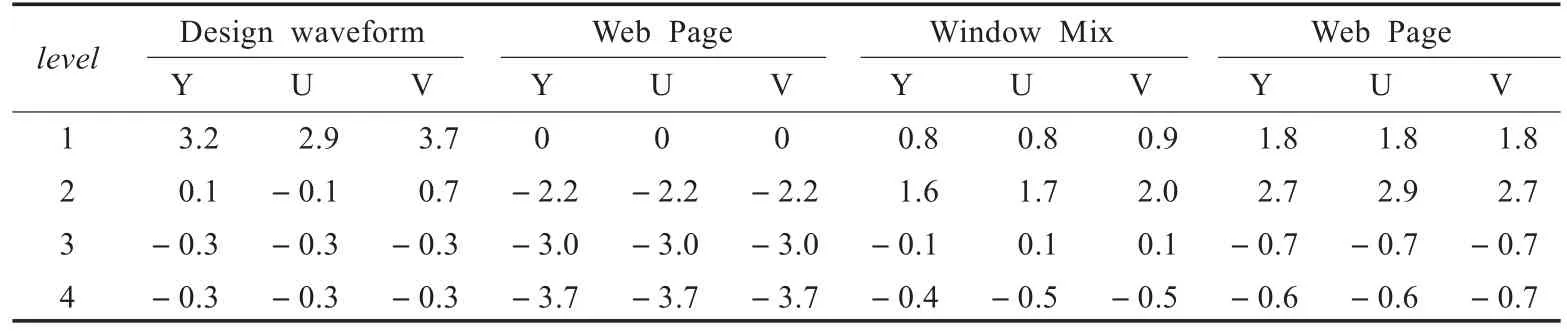
表4 BD-rate性能比较(%)
(2)对于图5(a)和(b)这一类像素边缘很明显的非连续色调的屏幕图像,当level=1时,和逐字节计算哈希值方法相比,本文提出的3字节计算哈希值方法对图像编码后得到的BD-rate性能稍有所降低,但是对于图像主观质量基本没有影响,因为低的字典等级决定了字典容量较小,字典中可存放的已编码历史数据较少,所以在寻找和当前待编码数据相匹配的字符串时可以参考的历史数据也较少,导致字符串的匹配效果较差。当level>1时,和逐字节计算哈希值方法相比,本文提出的3字节计算哈希值方法对图像编码后得到的BD-rate性能基本有所提高,而且随着字典等级越高,BD-rate性能提高也更多,可以得到比较好的匹配效果,说明仿2维匹配算法的3字节计算哈希值方法对非连续色调的屏幕图像有很好的匹配效果。
(3)对于图5(c)和(d)这一类包含大量自然图像的连续色调的屏幕图像,当level=1和level=2时,和逐字节计算哈希值方法相比,本文提出的3字节计算哈希值方法对图像编码后得到的BD-rate性能稍有所降低,但是BD-rate性能减小都在3%以内,对图像的主观质量基本没有影响。当level=3和level=4时,和逐字节计算哈希值方法相比,本文提出的3字节计算哈希值方法对图像编码后得到的BD-rate性能基本有所提高,说明仿2维匹配算法的3字节计算哈希值方法对包含有自然图像的连续色调的屏幕图像也有较好的匹配性能。
(4)从表4可以看出,字典等级越高,使得字典和哈希表占用的内存空间就越大,此时本文提出的3字节计算哈希值方法对屏幕图像编码后得到的BD-rate性能提升效果也越好。
(5)比较表1和表2,再根据表4中的实验结果,仿2维匹配算法的3字节计算哈希值方法充分利用了YUV数据存储格式的特点,不仅有效降低了屏幕图像编码所需哈希表的大小,而且降低了编码硬件所需的存储空间和计算复杂度。因此,仿2维匹配算法的3字节计算哈希值方法比逐字节计算哈希值方法具有更大的优势。
5 结束语
本文通过对15幅屏幕图像进行编码统计实验,得到了搜索匹配过程中字符串匹配长度Len和Len的个数C之间的统计概率,发现大部分最佳匹配长度都是3的倍数,说明在文献[6]中逐字节地进行字符串的匹配操作并不是最优的,于是本文提出了一种3字节计算哈希值方法,使得字符串在匹配搜索的过程中不再逐字节地搜索,而是以YUV三元组的形式直接开始搜索匹配。该方法充分利用了YUV数据存储格式的特点,使得为了快速高效寻找到与当前字符串匹配的哈希表占用的内存空间减少到原方法的1/3,不仅降低了编码硬件所需的存储空间,而且降低了计算复杂度,当字典等级比较高时屏幕图像的BD-rate性能还有所提升。接下来的研究方向可进一步分析1/n算法,使得哈希表自适应地根据字典的大小而变化,从而达到既能减小哈希表的大小,又能使屏幕图像的BD-rate性能均有所提升的目的,最终实现时间空间效率和匹配性能的最优化。
[1]Cai Xiaoxia,Cui Yansong,Deng Zhongliang,et al.Model of next-generation video standard and relative key technologies[J].TV Technology,2012,36(2):80-84.
[2]Ugur K,Andersson K,Fuldseth A,et al.High performance,low complexity video coding and the emerging HEVC standard[J].IEEE Transactions on Circuits and Systems for Video Technology,2010,20(12):1688-1697.
[3]Lainema J,Bossen F,Han W J.Intra coding of the HEVC standard[J].IEEE Transactions on Circuits and Systems for Video Technology,2010,22(12):1792-1801.
[4]Sole J,Joshi R,Nguyen N,et al.Transform coefficient coding in HEVC[J].IEEE Transactions on Circuits and Systems for Video Technology,2010,22(12):1765-1777.
[5]Ding Wenpeng,Lu Yan,Wu Feng.Enable efficient compound image compression in H.264/AVC intra coding[C]// IEEE International Conference on Image Processing,San Antonio,2007:337-340.
[6]Lin Tao,Zhang Peijun,Wang Shuhui,et al.mixed chroma sampling-rate high efficiency video coding for full-chroma screen content[J].IEEE Transactions on Circuits and Systems for Video Technology,2013,23(1):173-185.
[7]Lan Cuiling,Shi Guangm ing,Wu Feng.Compress compound images in H.264/MPEG-4 AVC by exploiting spatial correlation[J].IEEE Transactions on Image Processing,2010,19(4):946-957.
[8]Lin T,Hao Pengwei.Compound image compression for real-time computer generated compound images[J].IEEE Transactions on Image Processing,2005,14(8):993-1005.
[9]Lee B,Kim M.Modeling rates and distortions based on a mixture of Laplacian distributions for inter-predicted residues in quadtree coding of HEVC[J].IEEE Signal Processing Letters,2011,18(10):571-574.
[10]Zhang Peijun,Lin Tao,Wang Shuhui,et al.P2M and P2M+SAP as lossless coding tools for screen content coding[C]//JCTVC-Meeting,Geneva,2013.
[11]Lin Tao,Zhang Peijun,Wang Shuhui,et al.Full-chroma(YUV 444)dictionary+hybrid dual-coder extension of HEVC[C]//JCTVC-Meeting,Shanghai,2012.
[12]Wang Shuhui,Lin Tao,Zhou Kailun.Update on full-chroma(YUV 444)screen content test sequences of JCTVCH0294[C]//JCTVC-Meeting,Shanghai,2012.
[13]Lin Tao,Zhang Peijun,Wang Shuhui,et al.Syntax and semantics of Dual-coder mixed Chroma-sampling-rate(DMC)coding for 4∶4∶4 screen content[C]//JCTVCM eeting,Stockholm,2012.
[14]Lin Tao,Zhang Peijun,Wang Shuhui,et al.AHG7:HM software implementation and source code for JCTVCK 0133[C]//JCTVC-M eeting,Shanghai,2012.
[15]张培君,王淑慧,周开伦,等.融合全色度LZMA与色度子采样HEVC的屏幕图像编码[J].电子与信息学报,2013,35(1):196-202.
[16]Lin Tao,Zhang Peijun,Wang Shuhui,et al.4∶4∶4 screen content coding using Dual-coder mixed Chroma-samplingrate(DMC)techniques[C]//JCTVC-Meeting,Geneva,2012.
[17]Zhang Peijun,Lin Tao,Wang Shuhui,et al.Subjective quality comparison between DMC coding and chromasubsampled 420 coding using YUV 444 screen content test sequences[C]//JCTVC-M eeting,Geneva,2012.
[18]Lin Tao,Wang Shuhui.mixed chroma samp ling-rate coding:combining the merits of 4∶4∶4 and 4∶2∶0 and increasing the value of past 4∶2∶0 investment[C]// JCTVC-Meeting,San Jose,2012.
[19]Wang Shuhui,Lin Tao.4∶4∶4 screen content coding using macroblock-adaptive mixed chroma-sam pling-rate[C]// JCTVC-M eeting,San Jose,2012.
JIN Xiaojuan,ZHANG Peijun,LIN Tao
Institute of Very Large Scale Intergration,Tongji University,Shanghai 200092,China
The preudo 2-D matching algorithm has good compression performance for the discontinuous-tone content of screen content. However, the large space overhead of the hash table is not conductive to realize the hardware in this algorithm.This paper proposes a 3-byte hash value method to reduce the space of the hash table for optimizing the original method. The source data is treated as the data set composed of elements for YUV triples. Then the hash value of YUV triple is calculated as a unit. It not only can reduce the amount of computation of the hash values, but also can minimize the space overhead of the hash table. The experimental results show that the 3-byte hash value method makes the storage space of the hash table reduce to one-third of the original. And the BD-rate performance of some test screen images is alsoimproved.
High Efficiency Video Coding(HEVC); preudo 2-dimension matching algorithm; screen content; hash table
JIN Xiaojuan,ZHANG Peijun,LIN Tao.Op tim ization algorithm on hash tab le based on HEVC screen content coding.Computer Engineering and Applications,2014,50(17):155-159.
A
TP393
10.3778/j.issn.1002-8331.1303-0425
国家自然科学基金(No.61201226,No.61271096);上海市自然科学基金(No.12ZR1433800);中央高校基本科研业务费专项资金(No.2810219002,No.2810219003)。
金小娟(1989—),女,硕士,研究方向为多媒体算法和SoC设计;张培君(1977—),男,博士,讲师,研究方向为多媒体算法和SoC设计;林涛(1958—),男,博士,教授,研究方向为多媒体算法和SoC设计。E-mail:jinxiaojuan08@gmail.com
2013-03-27
2013-06-17
1002-8331(2014)17-0155-05
猜你喜欢
销售与市场(营销版)(2021年10期)2021-11-21
无线互联科技(2020年11期)2020-12-01
电脑爱好者(2020年20期)2020-10-22
销售与市场(营销版)(2019年6期)2019-06-21
网络安全技术与应用(2017年9期)2017-09-20
工业设计(2016年8期)2016-04-16
燕山大学学报(2014年1期)2014-03-11
电子设计工程(2014年12期)2014-02-27
测绘科学与工程(2013年6期)2013-03-11
网络安全与数据管理(2011年17期)2011-07-25
