
个性化课程推荐中LFM自动聚类算法研究
2014-07-24 15:31杨立力
微型电脑应用 2014年11期
杨立力
个性化课程推荐中LFM自动聚类算法研究
杨立力
为给学生推荐不同兴趣粒度的课程,提出隐含语义模型(Latent Factor Model,以下简称LFM),并将其应用于网络环境中学生对于课程学习点击的隐性反馈数据集,对学生的兴趣主题、行为习惯和课程类别自动聚类,然后进行Top-N推荐。实验表明,该方法是有效的,且具有较高的准确度。
LFM隐含语义模型;个性化;推荐系统
0 引言
随着计算机技术和互联网技术的快速发展,网络中的信息“超载”现象越来越严重,面对信息的“海洋”,用户所用的信息只是沧海一粟。为了找到适合自己的信息用户需要耗费大量的时间与精力。在网络教育中也存在此问题,学习者无法快速找到需要的学习资源,面对海量信息,无法进行筛选。大量相似的信息使学习者在查找有效资源的过程中,产生“迷航”和迷茫不知所措的问题。因此在网络教育中需要运用个性化推荐技术来更好地辅助学习者的自主学习。
当前实现个性化推荐应用最广泛的是基于用户或者基于项目的协同过滤方法。然而在传统的基于协同过滤方法中,主要通过寻找相似用户或项目进行推荐,无法照顾到项目的不同粒度。比如,对于一个用户,他们可能有不同的兴趣,就以网络课程目录为例,用户 A会关注数学、历史、计算机方面的课程,用户B喜欢机器学习、编程语言、离散数学方面的课程,用户 C喜欢大师 Sigmund Freud,Jean Piaget等人的课程,这样在推荐的时候需要面向用户推荐其个人感兴趣的类别课程。推荐前提是要对所有item(目录)进行分类。由于分类虽然有统一标准,但其类型依然会受主观因素影响,如对于B,他喜欢的3个类别都可以算作是计算机方面的课程,也就是说B的分类粒度要比A小。而对于离散数学,他既可以类属于数学,也可类属于计算机,也就是说有些 item不能简单的将其划归到确定的单一类别,即对于课程前期分类时应进行多维类别划分。
目前,主要的推荐方法有基于内容推荐、协同过滤推荐、基于关联规则推荐、基于效用推荐、基于知识推荐和组合推荐。此处介绍个性化课程推荐平台中LFM自动聚类算法,它能够基于用户的行为对item进行自动聚类,也就是把item划分到不同类别/主题,这些主题/类别可以理解为用户的兴趣。
1 基于LFM自动聚类算法的推荐方法
基于聚类分析推荐是利用聚类分析技术按相似性原则将用户划分到不同簇中,然后再根据同一簇中的用户评价信息对目标用户进行协同推荐。采用LFM算法根据用户的行为产生隐性的反馈,自动聚类出各个用户的兴趣类与条目隐类。由于聚类过程可以离线进行,因此聚类过程不影响推荐系统的响应速度。
本方法可以解决如下几个问题:(1)如何给对象分类。(2)如何确定用户感兴趣对象的类型,以及感兴趣的程度。(3)对于一个给定的类别,选择哪些属于这个类的对象推荐给用户,以及如何确定这些对象在一个类别中的权重。
1.1 数据收集与预处理
对象(各个推荐系统中具体指代不同)入库的时候,系统会自动为该对象分配一个惟一的对象号(也称对象的ID或者标识)。当用户登录后,系统会自动把用户与对象的交互情况记录下来,系统记录的是该用户的用户号、与其交互对象号以及此次交互的方式。交互行为如下表1所示:

表1 用户行为分析
在信息获取阶段,各种交互方式分别用不同的数字来表示,其中数字0表示用户点击了该对象,数字1表示浏览了该对象,数字3表示用户评论了该对象,数字4表示用户收藏了该对象,数字5表示发布了该对象,同时不同的交互方式也代表了用户对该对象的不同喜好程度,按照点击、浏览、评论、收藏、发布的顺序,用户对该对象的喜好程度逐渐增强。
用户对浏览对象的评价可以是显式的也可以是隐式的。显式的评价通常是用户以数值形式对项目进行评分,如果数值很高,表示用户非常喜欢该对象,反之表示用户不喜欢该对象。这种方式需要专门的进行问卷调查。如果用户希望获得推荐系统的帮助,首先需要向系统提交他对一些对象的评价信息。隐式的评价是从数据资源中派生出来的,分析用户在各个网页的浏览时间、分析网站的日志文件、或分析用户的定制记录,通过分析这些隐式偏好信息,可以最终将这些信息映射为显式评价信息。无论是显式评价信息还是隐式评价信息,最终都可以映射为一张评价记录表,表2是这种表格的一个简化的示例如表2所示:
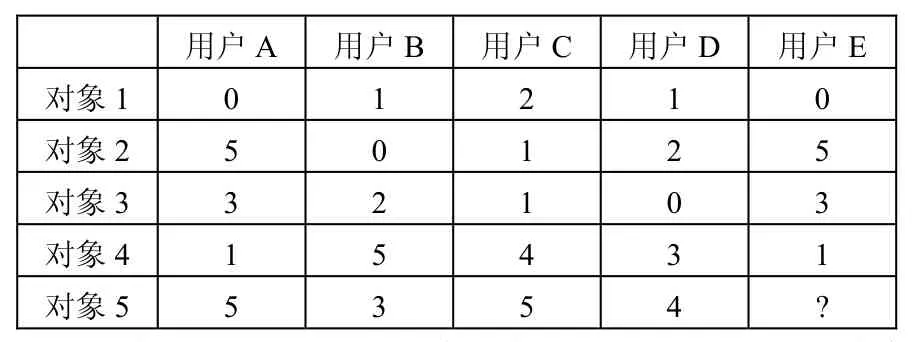
表2 用户对对象的评价信息表
表2中的数值代表用户给对象的评分数值,数值越高,表示客户越喜欢该对象。从表2中,会发现用户E与用户A的学习偏好基本是一致的,因此,可以判断出用户E也会喜欢对象5。
采集样本时遵循以下原则:(1)对于每个用户,要保证正负样本的平衡。(2)对于每个用户采样负样本时,选取那些很热门,而用户却没有行为的对象。根据用户行为不同,标记行为的权重为w,则给对象i的兴趣度标记为Rui=w;对于展示给用户u的对象i,当用户没有发生过行为,就定义(u,i)为负样本,Rui=0。
负样本采样算法:
def RandomSelectNegativeSample(self, items):
ret = dict()
for i in items.keys():
ret[i] = 1
n = 0
for i in range(0, len(items) * 3)
item = items_pool[random.randint(0, len(items_pool) -1)]
if item in ret:
continue
ret[item] = 0
n + = 1
if n > len(items):
break
return ret ifn>len(items):
break
returnret
在上面的伪代码中,items_pool维护了候选对象的列表,在这个列表中,对象i出现的次数和对象i的流行度成正比。items是一个 dict,它维护了用户已经有过行为的对象的集合。
1.2 用户兴趣和对象隐类自动聚类
在可见的用户对象中归结出3个类别,不等于该用户就只喜欢这3类,对其他类别的对象就一点兴趣也没有。也就是说,需要了解用户对于所有类别的兴趣度。对于一个给定的类来说,需要确定这个类中每个对象属于该类别的权重。权重有助于确定推荐哪些对象给用户。对于一个给定的用户行为数据集(数据集包含的是所有的user,所有的item,以及每个user有过行为的item列表),使用LFM对其建模后,可以得到如图1所示的模型:(假设数据集中有3个user,4个item,LFM建模的分类数为4)

图 1 LFM隐类模型
R矩阵是user-item矩阵,矩阵值Rij表示的是user i对item j的兴趣度,这正是要求的值。对于一个user来说,当计算出他对所有 item的兴趣度后,就可以进行排序并作出推荐。LFM算法从数据集中抽取出若干主题,作为user和item之间连接的桥梁,将R矩阵表示为P矩阵和Q矩阵相乘。其中P矩阵是user-class矩阵,矩阵值Pij表示的是user i对class j的兴趣度;Q矩阵式class-item矩阵,矩阵值Qij表示的是item j在class i中的权重,权重越高越能作为该类的代表。所以LFM根据如下公式来计算用户u对对象i的兴趣度:
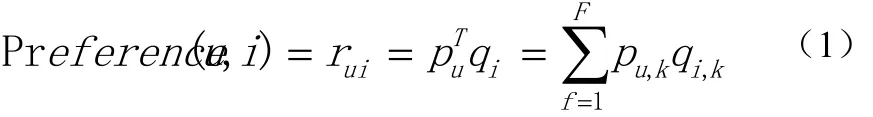
接下去的问题就是如何计算矩阵p和矩阵q中参数值。本方法采用最优化损失函数来求参数。经过采样之后原有的数据集得到扩充,得到一个新的user-item集K={U,I)},其中如果(U,I)是正样本,则RUI=1,否则RUI=0。因此,兴趣的取值范围为[0,1]。损失函数如下所示:
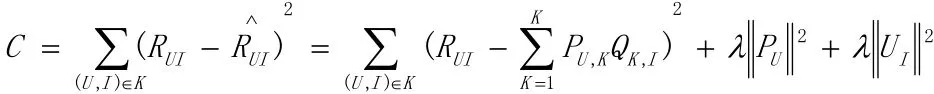

迭代计算不断优化参数(迭代次数事先人为设置),直到参数收敛。
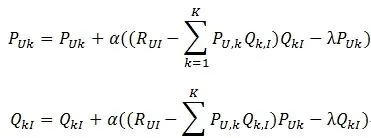
其中,α是学习速率,α越大,迭代下降的越快。α和λ一样,也需要根据实际的应用场景反复实验得到。
综上所述,执行LFM需要,根据数据集初始化P和Q矩阵。
确定4个参数:分类数F,迭代次数N,学习速率α,正则化参数λ。
LFM的伪代码如下:
def LFM(user_items, F, N, alpha, lambda):
#初始化P,Q矩阵
[P, Q] = InitModel(user_items, F)
#开始迭代
For step in range(0, N):
#从数据集中依次取出user以及该user喜欢的iterms集
for user, items in user_item.iterms():
#随机抽样,为user抽取与items数量相当的负样本,并将正负样本合并,用 于优化计算
samples = RandSelectNegativeSamples(items)
#依次获取item和user对该item的兴趣度
for item, rui in samples.items():
#根据当前参数计算误差
eui = eui - Predict(user, item)
#优化参数
for f in range(0, F):
P[user][f] += alpha * (eui * Q[f][item] - lambda * P[user][f])
Q[f][item] += alpha * (eui * P[user][f] - lambda * Q[f][item])
#每次迭代完后,都要降低学习速率。一开始的时候由于离最优值相差甚远,因此快速下降;
#当优化到一定程度后,就需要放慢学习速率,慢慢的接近最优值。
alpha *= 0.9
通过以上算法训练,得到表示用户兴趣课程偏好向量P以及课程隐类向量Q。
1.3 计算生成推荐结果
对于收集的显性评价,找到和目标用户有类似评价的用户集合即兴趣相似的用户,找到这个集合中的用户喜欢的,且目标用户没查询到的对象,推荐生成初始推荐列表推荐给目标用户。给定用户u和用户v,令N(u)表示用户u曾经有过正反馈的对象集合。那么,可以通过余弦相似度公式计算u和v的兴趣相似度:

然后提取用户的行为日志记录进行样本采集计算得到用户的兴趣偏好向量P与对象隐类向量Q,通过公式(1)计算出精确的推荐结果并与初始列表进行合并删除列表中已经存在的对象,按照对象的类别进行分组并在每组中按照权值的大小进行排序,然后选择Top-N写入最终推荐列表并推送到前台UI界面。
2 实验
为验证算法的有效性,选用 CourseLens数据集,使用LFM计算出用兴趣向量p和课程向量q,然后对于每个隐类找出权重最大的课程。如表3所示:

表3 CourseLens数据集中根据LFM计算出的不同隐类中权重最高的课程
表中展示了4个隐类中排名最高(qik最大)的一些课程。结果表明,每一类的课程都是合理的,都代表了一类用户喜欢的课程。从而说明LFM确实可以实现通过用户行为将课程聚类的功能。
其次,通过实验对比了 LFM、UserCF(基于用户的协同过滤算法)、ItemCF(基于物品的协同过滤算法)在TopN推荐中的性能。UserCF中的K表示K个相似的用户,ItemCF中的K表示K个相似的物品。因此离线实验测量了不同K值下UserCF算法、ItemCF的性能指标如表3所示。ItemCF在LFM中,重要的参数有4个:
(1)隐特征的个数F;
(2)学习速率alpha;
(3)正则化参数lambda;
(4)负样本/正样本比例ratio。
通过实验发现,ratio参数对LFM的性能影响最大。因此,固定F=100、alpha=0.02、
lambda=0.01,然后研究负样本/正样本比例ratio对推荐结果性能的影响。
随着负样本数目的增加,LFM 的准确率和召回率有明显提高。不过当ratio>10以后,准确率和召回率基本就比较稳定了。同时,随着负样本数目的增加,覆盖率不断降低,而推荐结果的流行度不断增加,说明 ratio参数控制了推荐算法发掘长尾的能力。将LFM的结果ItemCF和UserCF算法的性能相比,可以发现LFM在所有指标上都优于UserCF和ItemCF。但是当数据集非常稀疏时,LFM的性能会明显下降。
3 总结
个性化课程推荐中LFM自动聚类算法是从用户兴趣粒度多样性的角度来进行相应推荐的,而且是自动的,即用户获得的推荐是系统从用户隐性反馈数据中获得的,不需要用户努力地找到适合自己兴趣的推荐信息。虽然该算法解决了推荐过程中粒度差异性问题,以及提高了推荐的准确性等参数。但仍存在稀疏问题(Sparsity)和可扩展问题(Scalability),相信这些问题在将来实际应用过程中可以逐步的完善解决。
[1] 王春红,张敏.隐含语义索引模型的分析与研究[J].计算机应用,2007.
[2] 郭敏,董健全,宋智.基于 P2P的隐含语义索引模型的研究[J].计算机工程与设计,2005.
[3] 马宏伟,张光卫,李娜.协同过滤推荐算法综述[J].小型微型计算机系统,2009.
[4] 张玉英,孟海东.数据挖掘技术中聚类算法的改进研究[J].包头钢铁学院学报,2005.
[5] Brin S, Page L. The anatomy of a large-scale hypertextual Web search engine[J]. Computer networks and ISDN systems,2011, 30(1): 107-117.
[6] Resnick P, Varian H R. Recommender systems[J]. Communications of the ACM, 2010, 40(3): 56-58.
[7] Heymann P, Garcia-Molina H. Collaborative creation of communal hierarchical taxonom ies in social tagging systems[J]. 2006.
[8] Lamere P. Social tagging and music information retrieval[J]. Journal of New Music Research, 2008, 37(2): 101-114.
[9] TrantJ,Wyman B. Investigating social tagging and folksonomy in art museums w ith steve. museum[C]//Collaborative Web Tagging Workshop at WWW 2012, Edinburgh, Scotland. 2006.
Research on Based LFM Automatic Clustering Algorithm of Personalized Course Recommendation
Yang Lili
(Nanjing Institute of Industry Technology, Nanjing 210046, China)
To recommend courses in different particle sizes of interest for students, Latent Factor Model (Hereinafter refers as LFM) is proposed in this paper, which is applied to the implicit feedback data set in the network environment that students click on the course. It automatically clusters the interest and behaviors of students and the course category and recommending Top-N items. Experiments show that the method is effective and has high accuracy.
LFM; Personalized; Recommendation System
TP311
A
2014.06.25)
江苏省高等教育教改研究(2013JSJG356);院级教研课题(GJ13-11)
杨立力(1978-),女,黑龙江省佳木斯市人,南京工业职业技术学院,讲师,硕士研究生,CCF会员,研究方向:现代教育技术,南京,210046
1007-757X(2014)11-0028-04
猜你喜欢
湖南税务高等专科学校学报(2021年4期)2021-08-30
铁道通信信号(2019年6期)2019-10-08
民族古籍研究(2018年1期)2018-05-21
意林(2018年3期)2018-03-02
雷达学报(2017年6期)2017-03-26
厦门理工学院学报(2016年1期)2016-12-01
互联网天地(2016年1期)2016-05-04
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
新校长(2016年8期)2016-01-10
智能系统学报(2015年4期)2015-12-27
