
稀疏低秩模型下的单通道自学习语音增强算法
2014-07-25 04:29李轶南杨吉斌吴海佳张立伟
数据采集与处理 2014年2期
李轶南 贾 冲 杨吉斌 吴海佳 张立伟
(解放军理工大学指挥信息系统学院,南京,210007)
引 言
语音信号在实际的应用中不可避免地会受到来自周围环境噪声的污染,导致语音质量和可懂度的下降。学者们一直致力于研究增强算法以期实现从被噪声污染的语音信号中尽可能准确地恢复出原始语音信号。自20世纪70年代以来,出现了诸如谱减法、卡尔曼滤波法、信号子空间法等诸多经典算法[1-2],相应的改进算法也层出不穷,然而这些算法在去除实际环境中的噪声,特别是非平稳噪声以及类语音噪声时,其效果往往难以令人满意。
近年来,字典学习算法不断涌现[3-4],基于字典学习的语音增强算法成为学者们研究的热点,新的算法不断被提出,这些新算法的出现为解决传统增强算法难以解决的棘手问题带来了新的曙光。
文献[5]对语音和噪声分别进行字典学习,得到二者的非负联合字典,通过将带噪语音在联合字典上进行投影,分离出纯净语音。文献[6]发展了联合字典的思想,将卷积模型引入字典学习的过程中,使字典中的原子能够更好地反映出语音的时频域结构特征。尽管上述增强算法能够获得较好的增强效果,但是这种基于全监督字典学习的增强算法需要大量语音和噪声的先验知识,使得这些方法难以推广到实际应用之中。
学者们提出了很多新的更加实用的增强算法。文献[7]基于非负稀疏编码(Non-negative sparse coding,NNSC)提出一种半监督增强算法,只需要预先训练出噪声字典,就能够实现对于带噪语音中特定噪声的去除。文献[8]使用K-SVD算法预先训练得到语音字典,利用话音激活检测(Voice activity detection,VAD)在无语音期间获取噪声字典,实现了纯净语音信号的提取。这些方法虽然降低了对于先验知识的需求,但是依然无法实现无监督条件下的语音增强,使得上述算法仍然具有其自身的局限性。
自文献[9]提出鲁棒主成分分析(Robust principal component analysis,RPCA)以来,语音的稀疏低秩建模逐渐成为研究热点[10-11]。受RPCA思想的启发,本文将稀疏低秩模型引入到基于字典学习的语音增强中去,提出一种自学习语音增强算法。该算法根据噪声是否易于进行低秩建模将噪声区分为结构化噪声和非结构化噪声两类。首先通过 Go Decomposition(GoDec)算法[12]将带噪语音幅度谱分解为稀疏、低秩和噪声3部分,通过舍弃噪声部分去除非结构化噪声;然后,通过字典学习算法对低秩部分进行自学习,得到结构化噪声的字典;最后,使用所得噪声字典和迭代公式,分离出纯净语音的幅度谱。实验结果表明,本文算法能够在保留语音固有谐波特性的同时有效移除噪声,增强效果显著优于诸如RPCA和多带谱减法等无监督增强算法。
1 语音的稀疏低秩模型
主成分分析(Principal component analysis,PCA)是最常用的降维方法,该方法能够较好地挖掘出高维数据样本中潜在的低维特征。然而,当样本数据中存在少数数值偏差较大的样本时,其分解所得的结果往往会严重偏离实际。为此,Candès等人利用凸优化相关理论提出了一种新的解决方法——鲁棒主成分分析(Robust principal component analysis,RPCA)。RPCA能够将一个被任意大小的稀疏噪声所污染的数据矩阵分解为一个稀疏矩阵和一个低秩矩阵之和,从而克服了传统PCA算法对于稀疏的高强度噪声敏感的不足。
1.1 鲁棒主成分分析
假设被噪声污染的幅度谱为Y,且Y中的噪声具有潜在的低秩结构,由于语音信号具有时频域上的稀疏性,那么就能够将Y分解为低秩部分L和稀疏部分S之和,如式(1)所示

式(1)可以使用下面的优化问题来进一步描述



对于式(3)可以使用增广拉格朗日乘子法(Augmented lagrange multiplier,ALM)[13]来 方便地进行求取。
1.2 稀疏低秩模型在语音分离中的应用
文献[10]首次将RPCA算法应用到语音分离中,实现了歌唱语音和音乐伴奏的无监督分离。文献[10]指出,音乐伴奏往往具有明显的重复结构,所对应的幅度谱具备明显的低秩特征;与此同时,歌唱语音具有显著的谐波结构,这使得歌唱语音在整个歌曲的幅度谱上表现地十分稀疏。依据上述事实,文献通过RPCA算法分解歌曲的幅度谱,所得的低秩部分代表了音乐伴奏,而稀疏部分则对应于歌唱语音,据此实现了二者的分离。
然而,实际环境中的背景噪声较上面所述场景更为复杂,既有类似于音乐伴奏的低秩噪声,又有诸如高斯噪声一类的高维噪声,因此,直接应用RPCA进行增强往往效果并不理想,后面的实验将会证明这一点。进一步的研究显示,将带噪语音幅度谱分解为低秩、稀疏和噪声3部分之和的分解模型更加合理。在此分解模型下,低秩部分代表了噪声中结构性强的部分;语音信号由于其固有的短时平稳性,将会被分解到稀疏部分中去;噪声部分则代表了密集的非结构化噪声,是噪声中结构特征不明显的部分。本文算法依据上述分解模型实现了无监督条件下的单通道语音增强。
2 单通道自学习语音增强算法
增强算法对于传统的语音加性噪声模型进行了进一步的细化和完善:假设y(t)为带噪语音信号,s(t)为纯净语音信号,n(t)为噪声信号。根据n(t)是否易于进行低秩建模将噪声进一步细化区分为结构化噪声和非结构化噪声两部分
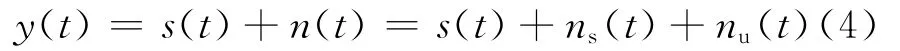
式中:ns(t)是噪声中结构性强的部分,即结构化噪声部分;nu(t)则噪声中结构性不明显的部分,即非结构化噪声部分。
本文增强算法如图1所示。首先对于带噪语音进行短时傅里叶变换(Short time Fourier transformation,STFT),求取带噪语音的幅度谱,然后使用矩阵的稀疏低秩分解将带噪语音的幅度谱分解为低秩、稀疏和噪声3部分,通过舍弃噪声部分移除非结构化噪声nu(t),通过对于低秩部分进行学习得到结构化噪声部分ns(t)的字典Dn;最后利用所得的噪声字典和相应的乘性迭代公式分离出纯净语音信号。
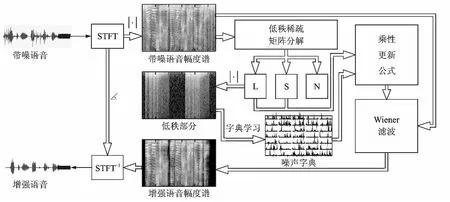
图1 增强算法流程图Fig.1 Pipeline of the proposed algorithm
2.1 语音幅度谱表示
首先对带噪语音信号y(t)进行分帧加窗,然后计算每一帧的快速傅里叶变换(Fast Fourier transformation,FFT)得到y(t)的短时傅里叶变换(Short time Fourier transformation,STFT )。

式中:W为所取语音帧帧长和FFT的长度,h(n)(n=0,…,W-1)为归一化语音窗,R=titi-1为相邻语音帧之间交叠的样点个数,取R=L/2。若带噪语音信号的帧数为N,则经STFT变换后所得矩阵的大小为W×N。通过对求取绝对值就可以得到带噪语音的幅度谱

记录下中相应的相位信息∠,以便在语音重构时对语音波形进行恢复。
2.2 语音幅度谱的稀疏低秩分解
GoDec算法是在RPCA的基础上优化了矩阵的稀疏低秩分解模型而得到的一种矩阵分解算法。使用该算法可以将带噪语音的幅度谱分解为3个矩阵之和,即
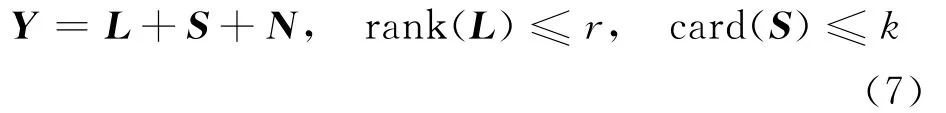
式中:rank(L)表示的是矩阵L的秩,card(S)表示的是矩阵S的势,即矩阵中非零元素的数目。
为了求解式(7),将其转化为两个最优化的子问题,其本质是在残差最小化的条件下,对低秩和稀疏矩阵分别进行估计,如式(8)
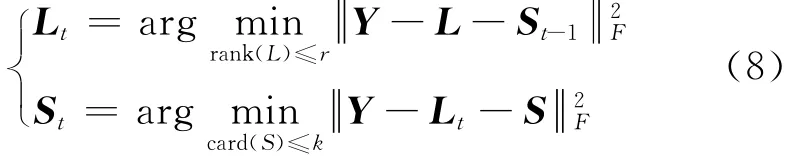
在求解式(8)中两个子问题的迭代过程中计算量开销最大的运算为SVD运算,GoDec算法采用双边随机投影(Bilateral random projection,BRP)来代替SVD运算,大大提高了运算效率,显著降低了算法的计算复杂度。
使用GoDec算法将所得的幅度谱矩阵Y分解为低秩L,稀疏S和噪声N三个部分。由于非结构化噪声部分很难用稀疏部分S或是低秩部分L来表示,此类噪声通常被GoDec算法分解到噪声部分即矩阵N中,直接去除此部分即可移除非结构化噪声。
根据上述分析,直接将带噪语音的幅度谱分解为低秩、稀疏和噪声3部分似乎就能实现对于语音信号的增强。然而,实际的实验结果显示直接将矩阵进行稀疏低秩分解难以实现对非平稳噪声环境下3部分的完美分离,这主要是因为单纯的稀疏低秩分解所得的低秩部分更关注语音信号在时频域上的重复性,而并不侧重于研究这些重复信号所具有的具体特征。为了克服这个缺点,本文算法引入字典学习算法来学习这些不断重复的噪声信号所具有的独特特征,从而进一步提升语噪分离的性能。
2.3 稀疏低秩模型下的自学习语音增强
结构化噪声部分通常具有比语音信号更加明显的重复和冗余结构。通过选取合适的秩,就能够在矩阵分解所得的低秩部分,即在矩阵L中获取到此类噪声的结构信息,通过对低秩部分进行字典学习,就能够获取相应的噪声字典,从而实现自学习。
相关研究表明,由局部到整体的累加方式更符合人类感官从局部到整体的认知过程且人耳对声音相位不敏感,这里首先对L求模值,然后通过非负矩阵分解(Non-negative matrix factorization,NMF)[14]的方式获得结构化噪声的归一化非负字典Dn。设结构化噪声字典中原子的个数为num,则有
式中:∈RW×N为稀疏低秩分解所得的低秩矩阵的模值,Dn∈RW×num和C′n∈Rnum×N分别为结构化噪声的归一化非负字典和对应的增益系数矩阵。
假设移除非结构化噪声以后的语音幅度谱为,纯净语音的字典为Ds,对应的增益系数矩阵为Cs,结构化噪声字典为Dn,相应的增益系数矩阵为Cn。语音增强问题就转化为
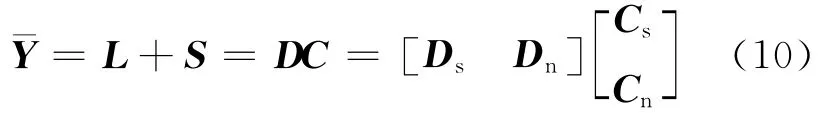
固定从低秩部分中学习得到的结构化噪声字典Dn,并使用下面的基于梯度下降的乘性更新公式[15]更新剩下的3个矩阵

式中:1为全1矩阵,λs和λn是控制增益矩阵稀疏度的常数,符号⊗表示矩阵或向量中对应元素的乘。
2.4 增强语音波形重构
经过式(11-13)的若干次的迭代后,就能够分离出纯净语音和对应噪声。本文采用Wiener滤波法进行后处理,来进一步提升算法的增强效果,使得增强后的语音听起来更自然。
Wiener滤波可以认为是对于语音时频域上的最小均方误差估计,其频域表达式为
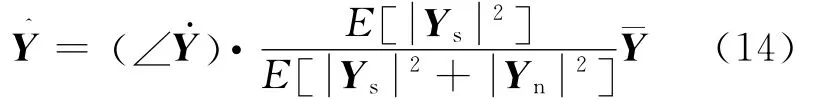
式中:Ys=DsCs,Yn=DnCn,∠为STFT时记录下的带噪语音相位信息。
将估计出的语音频谱进行逆STFT就可以重构出增强后的语音波形。
3 增强算法性能评估
实验选用的纯净语音来自TIMIT标准语音库中的男女语音片段各5句,噪声则来自Noisex-92标准噪声库[16],将二者下采样到8kHz,信噪比分别选取-5,0,5和10dB对算法分别进行评估。在稀疏低秩分解中,设定低秩部分的秩为1,来获取重复性明显的噪声部分,同时避免语音信号过多地泄露到低秩部分中。纯净语音和噪声字典的原子个数均设定为40。在字典更新的过程中,乘性迭代公式进行不超过200次的迭代。
测试实验着重选取了Pink,F16,Machinegun和Babble 4种具有代表性的噪声进行测试。其中Pink是自然界中最常见的噪声,其频率分量功率主要分布在中低频段,并没有明显的时频结构,代表了非结构化噪声;F16为美军双座F16战斗机巡航过程中座舱内的噪声,能量集中在在0~700Hz和2 750Hz频带附近且呈现出不均匀的变化特性;Machinegun为机枪扫射时所发出的噪声,能够代表瞬时噪声;Babble为有容纳大约100个人个同时在讲话的人的餐厅中的背景噪声,能量主要集中在低频段,是类语音噪声的代表)
采用BSS-EVAL评价体系[17]、短时客观可懂度测量(Short-Time objective intelligibility measure,STOI)[18]和语音质量客观评估方法(Perceptual evaluation of speech quality,PESQ)[19]对语音的性能进行评估。其中,BSS-EVAL是目前公认的性能比较好的盲源分离算法评估体系,该评估体系通过计算信源引入噪声比(Signal artifacts ratio,SAR)、信干比(Signal to interference ratio,SIR)、信 源 失 真 比 (Signal to distortion ratio,SDR),从不同方面反映了增强算法的效果;STOI是一种比较新的机器驱动的可懂度客观评估方法,其计算值与人对于语音的实际可懂度高度相关;PESQ是用来评价语音的主观试听效果的客观计算方法,能够很好地近似平均意见得分(Mean opinion score,MOS)。
将本文所提出的基于稀疏低秩模型的自学习语音增强算法与RPCA算法和多带谱减法(Multiband spectral subtraction,MBSS)[20]两种无监督算法进行比较来对本文算法进行评估。其中,RPCA算法是一种基于稀疏低秩分解的无监督分离方法,在分离歌唱和伴奏时,体现出很好的性能;MBSS是一种性能比较好的增强算法,在多种噪声环境下均能获得较好的增强效果。
图2给出了4种噪声环境下BSS-EVAL评价体系中3个关键指标的平均测量值。在这3个指标中,SAR对于分离过程中引入噪声的大小进行评估,SIR是表征增强算法对噪声抑制程度的一个值,SDR则反映了分离算法的总体性能。3个指标越高的算法,相应的性能也就越好。
由图2中可以看出,本文算法的SAR测度平均比 RPCA方法高出3.3dB,比 MBSS高出5.5dB。在SIR测度方面,本文算法平均比RPCA高出2.3dB,比 MBSS高出5.8dB。SDR测度显示,本文算法比RPCA高出2.1dB,比MBSS高出5.3dB。这些指标说明相较于其他两种算法,本文算法引入更少的噪声,具有更好的噪声抑制能力,其综合性能指标也更加优越。

图2 BSS-EVAL评价体系平均测量值Fig.2 Performance of MBSS,RPCA and the proposed algorithm in terms of BSS-EVAL metrics

图3 STOI平均测量值Fig.3 Average short-time objective intelligibility measures of different algorithms
图3列出了3种增强方法的STOI测量值。可以看出,本文算法具有比其他两种方法更高的测量值。这说明,本文算法的可懂度要高于其他两种算法,并且随着信噪比的下降,本文算法的可懂度下降相对缓慢,这说明本文算法在低信噪比下仍具有较好的可懂度。
表1列举了3种增强方法在4种不同噪声环境和输入信噪比下的PESQ测量值,这些测量值进一步验证本文算法的性能。

表1 不同算法和噪声下的PESQ值Table 1 PESQ scores of different algorithms and noises
然而,无论是BSS-EVAL评价体系、STOI测度还是PESQ值,都只能够从宏观上反映算法的性能,为了更好地观察出增强语音信号的细节特征,本文给出了3种增强算法对于输入信噪比为5dB,被F16飞机噪声所污染的纯净语音进行增强前后的语谱图,如图4所示。
可见,RPCA比MBSS更好地去除了噪声,然而也带来了更大的语音损伤。在2 750Hz的频带附近,使用RPCA进行增强的结果依然存在少量噪声残留,导致了类似音乐噪声的试听感受。本文算法在继承了RPCA优点的同时,很好地克服了RPCA的缺点,能够在有效去除噪声的前提下,较好地保持语音信号的固有谐波特性,增强效果明显优于前两种算法。
4 结束语
本文基于矩阵的稀疏低秩分解提出一种单通道自学习语音增强算法,实现了对于语音信号的无监督增强,该算法能够在保留语音信号固有谐波特性的同时很好地移除噪声。在低信噪比条件下,本文算法的增强结果依然能够保持较高的可懂度,其增强性能显著优于鲁棒主成分分析方法和多带谱减法。

图4 语音语谱图Fig.4 Spectrograms
[1]Mohammadiha N,Smaragdis P,Leijon A.Supervised and unsupervised speech enhancement using nonnegative matrix factorization[J].IEEE Transactions on Audio,Speech and Language Processing,2013,21(10):2140-2151.
[2]张丽艳,殷福亮.一种改进的奇异值分解语音增强方法[J].电子与信息学报,2008,30(2):357-361.
Zhang Liyan,Yin Fuliang.An improved speech enhancement method based on SVD[J].Jounal of E-lectronics &Information Technology,2008,30(2):357-361.
[3]曾理,张雄伟,陈亮,等.基于压缩感知的K-L分解语音稀疏表示算法[J].数据采集与处理,2013,28(3):267-273.
Zeng Li,Zhang Xiongwei,Chen Liang,et al.Compressed-sensing-based speech sparse representation with K-L expansion[J].Journal of Data Acquisition and Processing,2013,28(3):357-361.
[4]王天荆,郑宝玉,杨震.基于自适应冗余字典的语音信号稀疏表示算法[J].电子与信息学报.2011,33(10):2372-2377.
Wang Tianjing,Zheng Baoyu,Yang Zhen.A speech signal sparse representation algorithm based on adaptive overcomplete dictionary[J].Journal of Electronics &Information Technology,2011,33(10):2372-2377.
[5]Wilson K,Raj B,Smaragdis P,et al.Speech denoising using nonnegative matrix factorization with priors[C]∥ICASSP.Las Vegas:IEEE,2008:4029-4032.
[6]Smaragdis P.Convolution speech bases and their application to supervised speech separation[J].IEEE Transactions on Audio,Speech and Language Processing,2007,15(1):1-12.
[7]Mikkel N S,Jan L,Fu-Tien,et al.Wind noise reduction using non-negative sparse coding[C]∥IEEE Workshop on Machine Learning for Signal Processing.Thessaloniki:IEEE,2007:431-436.
[8]Christian D S,Tomas D,Joachim M,et al.Speech enhancement using generative dictionary learning[J].IEEE Transactions on Audio,Speech and Language Processing,2012,20(6):1698-1712.
[9]Emmanuel J C,Xiaodong Li,Yi Ma,et al.Robust principal component analysis[J].Journal of the ACM,2011,58(3):1-37.
[10]Huang Po-Sen,Chen S D,Smaragdis P,et al.Singing-voice separation from monaural recordings using robust principal component analysis[C]∥ICASSP.Kyoto:IEEE,2012:57-60.
[11]Sprechmann P,Bronstein A,Bronstein M,et al.Learnable low rank sparse models for speech denoising[C]∥ICASSP.Vancouver,Canada:IEEE,2013:136-140.
[12]Zhou Tianyi,Tao Dacheng.GoDec:randomized lowrank &sparse matrix decomposition in noisy case[C]∥28th International Conference on Machine Learning.Bellevue,Washington:Springer Berlin Heidelberg,2011:33-40.
[13]Lin Z,Chen M,Ma Y.The augmented Lagrange multiplier method for exact recovery of a corrupted low-rank matrices[EB/OL].http:∥arxiv.org/abs/1009.5055,2010-9-26.
[14]Lee D D,Seung H S.Learning parts of objects by non-negative matrix factorization[J].Nature,1999,401(6755):788-791.
[15]Kristian T A.Wind noise reduction in single channel speech signals[D].Technical University of Demark,2008:25-37.
[16]Rice University Digital Signal (DSP) group.Noisex92Noise Database[EB/OL].http:∥spib.rice.edu/spib/select_noise.html.1996-8-16.
[17]Vincent E,Gribonval R,Fevotte C.Performance measurement in blind audio source separation[J].IEEE Transaction on Audio,Speech,and Language Processing,2006,14(4):1462-1469.
[18]Cees H T,Richard C,Hendriks,et al.An algorithm for intelligibility prediction of time-frequency weighted noisy speech[J].IEEE Transactions on Audio,Speech and Language Processing,2011,19(7):2125-2136.
[19]International Telecommunication Union.Perceptual evaluation of speech quality (PESQ):an objective method for end-to-end speech quality assessment of narrowband telephone networks and speech codecs,recommendation-862[S].P.862.Switzerland Geneva:ITU-T,2001.
[20]Philipos C,Loizou.Speech enhancement:Theory and practice[M].Boca Raton,Florida:Taylor and Francis,2007:120-125.
猜你喜欢
股市动态分析(2021年25期)2021-12-30
河北理科教学研究(2021年4期)2021-04-19
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
小学阅读指南·低年级版(2019年11期)2019-07-01
宇航计测技术(2018年3期)2018-09-08
小天使·一年级语数英综合(2017年11期)2017-12-05
制造业自动化(2017年2期)2017-03-20
读者(2016年14期)2016-06-29
股市动态分析(2014年27期)2014-07-29
