
以用户为中心的异构数据集成方法
2014-08-07 12:08陈正鸣
微处理机 2014年3期
高 明,陈正鸣,吕 嘉
(河海大学物联网工程学院,常州213022)
以用户为中心的异构数据集成方法
高 明,陈正鸣,吕 嘉
(河海大学物联网工程学院,常州213022)
为了实现用户数据在不同用户应用程序间的共享,将同一用户分布在不同应用程序上的数据按照统一的数据模型组织,并存放在统一的平台上,用异构数据集成技术处理用户数据模型和统一数据模型间的异构问题,使得不同应用平台之间能实现数据共享。
以用户为中心;异构数据集成;扩展机制
1 引 言
现今,用户使用的应用程序类型呈现多样化。按应用程序功能可以分为微博类、邮件类、即时通信类等等,用户使用同一类型的应用程序也有很多种,微博应用程序中有新浪微博、腾讯微博、网易微博等等。各个应用程序的数据之间彼此隔离,互不共享,分散的应用程序各自存储和管理用户数据的方式给用户带来了不便。另外数据分散还会出现垃圾数据,与用户相关的新业务难以快速有效的开展,用户数据管理问题日益明显。
各个应用程序的数据存在着存储方式、数据格式、访问控制、用户视图、数据模型方面的不同,导致用户的信息像一个个信息孤岛,很难达到互联互通,实现数据间的共享,解决用户信息间的异构问题是实现用户信息集成的关键。
这里提出的服务平台(即中央平台)发布统一的数据模型给各个用户应用程序,通过异构数据集成技术解决数据模型之间的异构问题,使得用户应用程序中使用的各类数据能统一成中央平台规定的数据格式,用户的所有数据统一保存在中央平台,中央平台为各用户应用程序数据之间的共享提供服务。
2 基本思路
中央平台的数据模型从用户角度出发设计,将各个用户应用程序中涉及的所有数据进行分析,再将分析后的数据及其联系进行逻辑组织,生成中央数据模型。中央平台制定异构规则,并发布中央数据模型给各个用户应用程序。用户应用程序在中央平台上进行注册,将中央数据模型对应部分作为用户应用程序数据模型的基本框架,通过中央平台给出的异构规则设计出用户应用程序的数据模型,即用户数据模型。
中央数据模型与用户数据模型之间存在着差异。用户在用户应用程序中上传的数据通过JSON格式的数据接口上传到中央平台后,经过异构规则对应的异构函数处理,以中央数据模型的格式保存到中央平台上。用户应用程序可以通过异构逆函数,将中央平台的数据转换成用户应用程序能处理的格式。系统基本思路如图1所示。

图1 基本思路示意图
3 以用户为中心的数据模型
中央平台设计式的中央数据模型,从用户角度出发,设计出的中央数据模型要能满足用户需求,能实现用户数据的统一化管理,体现以用户为中心的理念,实现用户数据在不同应用程序上的重用。
3.1 中央数据模型的设计思路
现在多数用户数据模型为关系数据模型,由于用户应用程序和中央平台之间需要进行模型比较和匹配,中央数据模型使用关系数据模型。同时,关系数据模型的结构简单、清晰,具有更高的独立性,也能简化中央数据模型的建立和维护。
设计中央数据模型前首先要了解现有用户使用的应用程序,本研究以微博类、邮箱类和即时通讯类应用程序为重点,将这些社区类应用程序的数据模型中涉及到的实体和属性进行分析,依据这些实体和属性与用户的密切程度和重用价值进行筛选,再将选出的实体和属性从用户角度出发,统一进行分类,最后设计出中央数据模型。
3.2 中央数据模型实体分类
将用户数据模型中的信息进行分类,并将相关信息抽象成中央数据模型的实体。一些用户数据模型中的信息在不同类应用程序里,但从用户角度分析,有着类似的作用,同样可以抽象成中央数据模型中的实体。通信录包括用户在各应用程序平台中所包括的通信联系人,微博和社交类应用中可私信的对象,QQ、MSN等即时通信工具里的通信对象,邮箱中的通信录信息,从而使得通讯录中拥有所有建立了通信关系的对象信息。
用户同一类型的不同应用程序可能有很多种,而同一类型应用程序的实体相似度很大,可以将各个用户应用程序中描述同一实体的部分进行集成。例如,新浪微博、腾讯微博和网易微博里都有微博这一实体,这些可以统一成用户的微博这一实体。
多个实体合并为统一的实体,合并后实体中的属性可能会出现冗余重复,应首先消去多余的属性。有些属性之中存在单属性对应多属性、名称不同但指代事物相同等等的异构现象,应仔细分析后删除冗余的属性,再和其它属性统一整合到对应的实体。多数用户应用程序涉及的实体或者属性应保留到中央数据模型,少数用户应用程序涉及的实体或者属性依据其重用价值选择是否保留到中央数据模型。
中央数据模型的实体分为用户基本信息、用户社交信息、用户上传资料、用户博文、用户通信信息五大类,每个分类包含相关的实体,如图2所示。

图2 中央数据模型中实体的分类
3.3 中央数据模型的核心部分与非核心部分
按中央数据模型中内容的必要性分为核心部分和非核心部分。中央数据模型的核心部分是定义用户数据模型时不可缺少的部分,所有用户数据模型必须定义这部分,缺少核心部分会导致用户数据在一些情况下无法实现重用。非核心部分丰富了中央数据模型的业务功能,用户数据模型可以选择是否包含中央平台的非核心部分。在中央平台的建模过程中,分析各个实体和属性的必要性,并标注上“核心部分”或者“非核心部分”。
图3为中央数据模型中用户个人资料部分的简图。个人资料中的ID是中央平台唯一标示用户的信息,用户的账号信息和密码是用户登录各个平台的凭证,姓名,性别,生日,职业信息中的单位名称,教育经历中的学校名称和类型都是关于用户的重要信息。血型,家庭地址,标签信息对于多数用户应用程序而言,不是必要信息,这些信息是中央数据模型的非核心部分,图3中核心部分用灰色背景标注,非核心部分用白色背景标注。
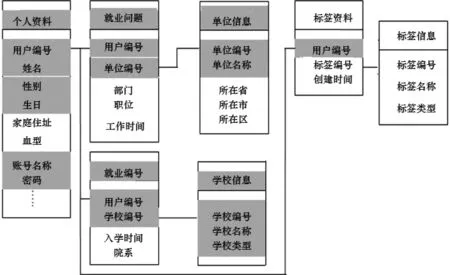
图3 中央数据模型中用户的个人资料部分简图
3.4 数据模型的扩展机制
为了丰富中央数据模型和用户数据模型的内容,增强中央数据模型和用户数据模型的适应性和扩展性,系统提出了数据模型的扩展机制。中央数据模型能扩展自身模型,以适应用户应用程序变化的需求,用户数据模型也能通过扩展机制增加中央数据模型没有的属性和实体。
3.4.1 中央数据模型的扩展
中央数据模型可以进行扩展。各个应用程序不断更新,出现新的业务功能,中央数据模型必须要扩展大多数用户数据模型中扩展的实体或者属性,以适应用户应用程序的变化。中央平台及时发布更新后的数据模型给所有用户应用程序,同时说明最新扩展的内容。
3.4.2 用户数据模型的扩展
用户数据模型也可以在自身数据模型基础上进行扩展,扩展属性到对应的实体中,也可以扩展中央数据模型中没有的实体,但要保证实体之间的联系,并在中央平台上保存扩展后的用户数据模型。例如,中央数据模型用户的微博实体中没有“标记”这一属性,某个用户应用程序希望用户数据模型中出现“标记”这一属性,用户数据模型可以通过扩展机制实现。
4 数据异构规则
用户应用程序利用用户数据模型的扩展机制,扩展中央数据模型中没有的属性或者实体,而对于模型之间对应属性间存在异构的现象,则要通过异构处理技术来统一数据格式。这里提出的用户异构数据集成方法是基于异构规则的,用户应用程序通过使用中央平台制定的异构规则来建立用户数据模型。
不同数据模型之间存在着各种语义冲突,中央平台针对用户数据特点进行分析,归纳用户异构数据的冲突类型,制定异构规则。异构规则的主要任务是分类中央数据模型和用户数据模型中语义相关属性存在的异构情况。
在实际的匹配过程中按照发生异构情况中的属性数量分为多属性冲突和单属性冲突,单属性冲突针对单一属性中类型、格式、精度方面的差异,而多属性冲突针对属性的组合方式不同。对应规则如下(其中A,B表示属性值,E表示实体,D1表示用户数据模型,D2表示中央数据模型,#表示实体主键)。
4.1 单属性异构
单属性异构主要有格式冲突和分配冲突:
(1)格式冲突:指中央数据模型和用户数据模型描述同一个属性的描述方式不同。
如:D1:User(id#,name,birthday(YYYY-MM)……);
D2:User(id#,name,birthday(YYYY-MM-DD)……);
用户数据模型中的日期类型有很多种,YYYYMM,YYYY/MM,YYYY/MM/DD,YY-MM-DD,YYMM。
假设:{A1,A2,A3……An……Am}=E1∈D1,{A1,A2,A3……An-1,Bn……Am}=E2∈D2,An和Bn存在格式冲突。
规则:中央平台枚举出所有可选的格式,用户选择对应的格式。
(2)分配冲突:指中央数据模型和用户数据模型为同一属性的相同数据类型但分配空间大小不同。
如:D1:Fans(id#,name,amount(varchar(8))……);
D2:Fans(id#,name,amount(varchar(16))……);
假设:{A1,A2,A3……An……Am}=E1∈D1,{A1,A2,A3……An-1,Bn……Am}=E2∈D2,An和Bn数据类型一致,且存在分配冲突。用户应用程序中An的数据可以直接赋值给中央平台的Bn,Bn映射到An则需要根据An的数据类型不同,使用对应的异构规则,分配冲突中各种情况下的规则如表1所示。
4.2 多属性异构
多属性异构主要为组合冲突,复杂组合冲突。
(1)组合冲突:指同一语义的属性在中央数据模型和用户数据模型中用不同的属性组合方式表示,组合方式规律可循。
如:D1:Message(id#,sendtime,content,sendplace,userid);
D2:Message(id#,sendtime,content,province,city,userid)(D2中sendplace中数据对应D1中provice中的数据和city中的数据组合)
假设:{A1,A2,A3……An-1,An,An+1……Ak-1,Ak,Ak+1……Am}=E1∈D1,{A1,A2,A3……An-1,Bn,Ak+1……Bm}=E2∈D2;且E1中属性An……Ak与E2中的Bn表示同样语义。
规则:An,An+1……Ak→Bn=An[^\n\r\t\v]An+1……Ak-1[^\n\r\t\v]Ak

表1 分配冲突Bn映射到An各种情况下的规则
(2)复杂组合冲突:指同一语义的属性存在组合冲突,且组合方式无规律可循。
如:属性name对应属性given-name和family-name的组合,但name的拆分方式没有规律,中文名字中的姓存在单复姓现象。
复杂组合冲突的规则:根据每个属性出现的概率去拆分语义复杂的属性,拆分方案和属性数据出现的概率由中央平台给出,用户应用程序选择用户数据模型需要的拆分方案。例如name属性的拆分,中央数据模型提供name拆分为famliy-name和givenname的方案。对于family-name有专门的一张表列出不同数据成为family-name的概率,属性数据按照表中famliy-name概率最大的方案进行拆分。复杂组合的逆规则为拆分后的属性按照原顺序组合。
5 用户异构数据集成流程
用户使用应用程序前,首先要在中央平台上进行注册,并录入自己的个人资料,注册后平台分配给用户一个用户ID作为标识。用户在注册时,中央平台的个人资料数据可以被重用到用户应用程序。对于每条上传的数据,中央平台统一分配一个用户数据ID对该条数据进行唯一标识,并标示数据上传的平台名称和用户ID。用户可以在任意用户应用程序上使用在中央平台上保存的相关数据,通过用户ID实现数据查询。
5.1 异构函数
中央数据模型和用户数据模型之间的映射关系是基于异构规则建立的,实际的映射关系持久化成文件,保存在中央平台上。异构函数处理用户数据是在中央平台上实现的,异构函数将用户应用程序的数据和中央平台的数据进行转化,实现了用户数据的互通。
异构函数首部中的函数名、存储方式以及函数体由中央平台给出,而异构函数中的函数类型、参数则由用户平台设计时对应的映射关系所决定。
异构函数是异构规则的具体实现,函数的更新由中央平台决定,用户平台通过修改映射关系来实现对异构函数的修改。
5.2 整体流程
用户数据通过JSON格式的数据接口上传到中央平台,中央平台读取相应的持久化文件,使用对应的异构函数对用户数据进行异构处理,处理后的数据以中央平台的格式保存在中央平台上。用户应用程序使用用户数据时,首先用户应用程序对中央平台发出数据请求,中央平台判断用户数据模型与中央数据模型之间是否存在异构,如果存在,则利用对应的异构逆函数处理用户数据后再返回给用户应用程序。用户数据在系统中的整体流程如图4所示。
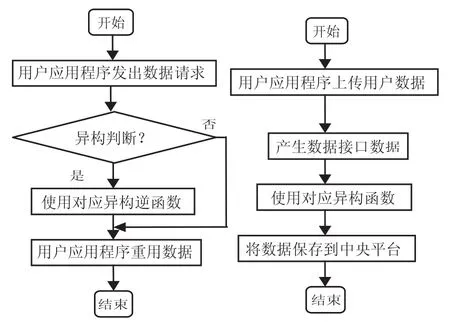
图4 平台更新用户数据(左)和查询用户数据(右)流程图
6 实例
以建立微博平台B数据模型和该平台的一条用户微博信息给微博平台B重用为实例,来说明用户数据在系统中的处理流程。
用户平台首先了解中央数据模型,以下是应用中央数据模型中的微博实体设计出用户平台数据模型对应部分的设计过程。利用格式异构规则将属性Created_at和sendtime实现映射关系,利用表示异构规则实现两者格式的映射,并将映射关系用可持久化文件保存在中央平台上,同时生成了微博平台B 的数据模型(见图5)。
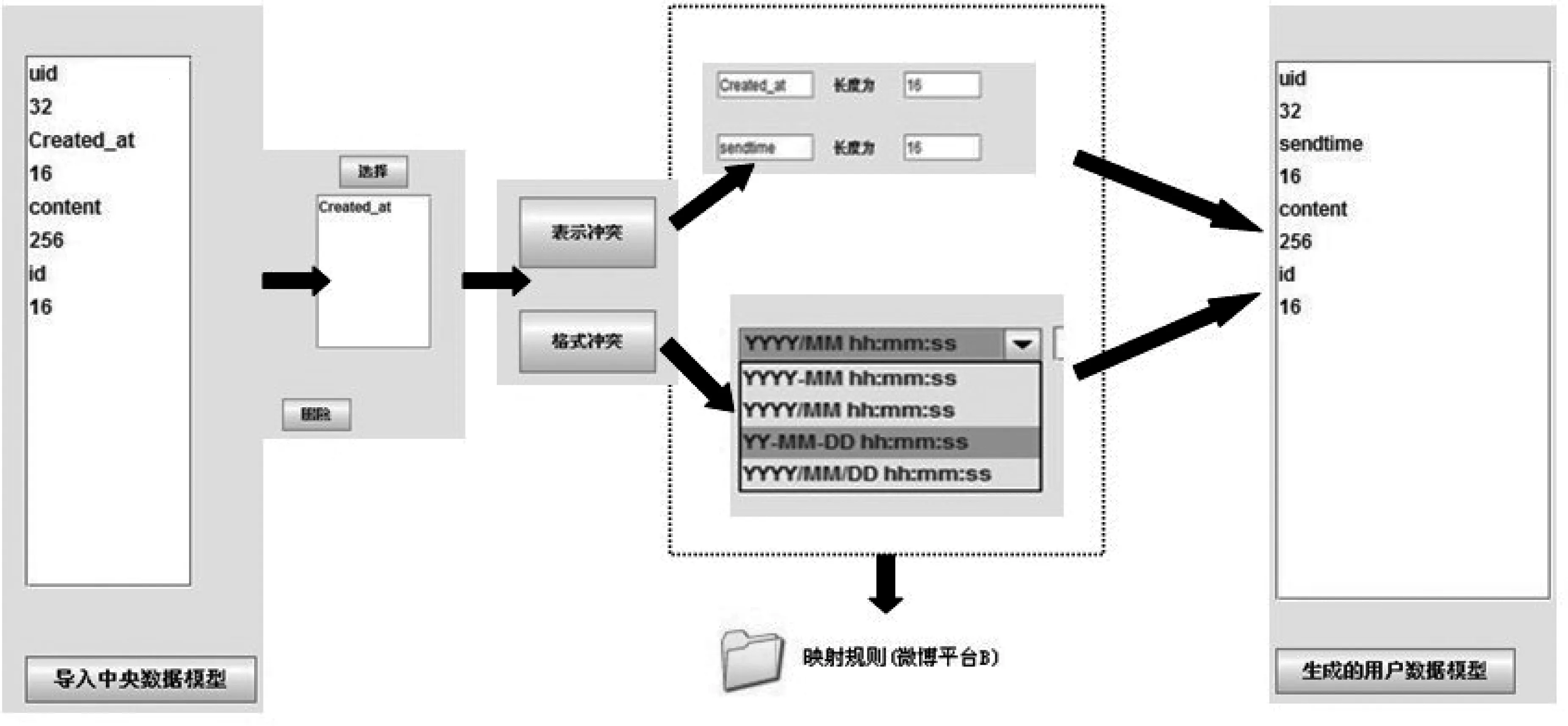
图5 微博平台B建模实例图
微博平台A利用用户数据模型的扩展机制扩展中央平台中没有的favorite字段。用户在微博平台A中的一条微博信息,通过JSON格式的数据接口提交给中央平台,其数据接口具体内容和微博平台A上显示的微博内容如下:
{"uid":1773020834,
"created_at":"2010/11/11 23:20:31",
"content":"明天会很美好",
"favourite":false,
"id":4545632}
中央平台对该条微博数据进行异构处理后保存。当微博平台B需要使用这条微博信息时,中央平台通过用户ID找到所要查询的微博数据,sendtime和created-at之间存在格式异构,通过对应的异构逆函数,将该微博数据转换成微博平台B能处理的格式,从而实现了该条微博数据在微博平台B上的重用。实例中各平台数据格式如图6所示。

图6 用户数据重用实例图
微博平台B使用此条微博,接口数据用的JSON格式和微博平台B上显示的微博内容如下:
{"uid":132457865,
"content":"明天会很美好",
"sendtime":"2010-11-11 23:20:31",
"id":4545632}
7 结束语
提出了一种将用户异构数据集成的方法。中央平台设计以用户为中心的数据模型,用户应用程序基于中央数据模型和异构规则设计用户数据模型,用户数据通过对应的异构函数处理后以统一的数据格式保存到中央平台,中央数据模型能够很好地支持用户个性化需求,数据管理更加统一集中,并保证用户数据的一致性。原型系统采用JAVA语言进行开发,具有良好的扩展性。
该系统平台仍存在一些不足,分析的异构冲突情况较少,以致用户应用程序建立用户数据模型时存在一定的局限性。在后续开发中要进一步完善用户数据异构处理的方法。
[1]陈桦,麻风梅,韩艳艳.基于XML的异构数据集成模式的研究[J].微电子学与计算机,2009,26(1):137-139,144.
[2]赵国增,郭恒川.基于本体的异构数据共享研究[J].计算机技术与发展,2010,20(10):39-42.
[3]赵志强.实现数据库数据重用的技术分析[J].软件技术,2004(6):46.
[4]周建芳,徐海银,卢正鼎.基于上下文仲裁的语义异构解决方案[J].计算机工程,2008(20):10-12.
[5]蔡国森.数据语义冲突的解决方法[J].北京工商大学学报(自然科学版),2005(3):44-46.
[6]靳强勇,李冠宇,张俊.异构数据集成技术的发展和现状[J].测绘通报,2002(11):112-114.
[7]朱凡微.基于本体的异构数据库集成关键技术研究[D].杭州:浙江大学,2008.
[8]郑娅峰.异构数据集成的研究和实现[D].西安:西北大学,2005.
A Method of User-centered Heterogeneous Data Integration
GAO Ming,CHEN Zheng-ming,LV Jia
(College of Internet of Things Engineering,Hohai University,Changzhou 213022,China)
In order to achieve the data share between the differentuser platforms,the same user data distributing on different application platforms are organized according to the unified data model in a unified platform.The heterogeneous data integration technology is used to process user data model and unify them between the heterogeneous problems for data sharing between different application platforms.
User-centered;Heterogeneous data integration;Extension mechanism
10.3969/j.issn.1002-2279.2014.03.008
TP311
:A
:1002-2279(2014)03-0025-05
高明(1988-),男,江苏常州人,硕士研究生在读,主研方向:信息系统与工程应用。
2013-12-04
猜你喜欢
小学教学研究(2022年5期)2022-04-28
电脑报(2019年12期)2019-09-10
中国计算机报(2018年30期)2018-11-12
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
中国洗涤用品工业(2017年2期)2017-04-16
电信科学(2016年11期)2016-11-23
通信电源技术(2016年6期)2016-04-20
管理现代化(2016年3期)2016-02-06
中南民族大学学报(自然科学版)(2012年4期)2012-11-26
中国土地科学(2011年11期)2011-03-20
