
视频中人体行为分析
2014-09-11 09:10史东承冯占君长春工业大学计算机科学与工程学院长春130012
吉林大学学报(信息科学版) 2014年5期
史东承, 冯占君(长春工业大学 计算机科学与工程学院, 长春 130012)
视频中人体行为分析
史东承, 冯占君
(长春工业大学 计算机科学与工程学院, 长春 130012)
为实现机器视觉代替人眼观察、 认知世界以及减少背景和噪声对视频中人体特征提取的影响, 以提高识别效果, 在研究人体动作表征与识别的基础上, 充分考虑局部和全局特征的优缺点, 提出了基于局部时空兴趣点和全局累积边缘图像特征相结合的人体行为分析方法。首先, 从视频序列中提取局部时空兴趣点和全局累积边缘图像特征; 然后用加权字典向量法将两者有机地结合在一起; 最后利用最近距离法进行人体行为分析和识别。该方法可有效获得人体时空特征、 人体边缘轮廓、 人的运动趋势和强烈程度。实验结果表明, 该方法快速, 相比其他算法识别率大致提高了2%~5%。
时空兴趣点; 累积边缘图像; 行为分析
0 引 言
视频中人体行为分析就是在非人为的干预下, 综合利用机器视觉、 模式识别、 图像处理、 人工智能等多学科的知识和技术对视频中人体行为进行分析, 实现场景中人体定位和跟踪, 并在此基础上分析和判断人体行为。人体行为分析在智能视频监控、 高级人机交互、 视频会议以及医疗诊断等方面有着广泛的应用前景和巨大的商业价值。
近年来, 对视频中人体行为的分析, 人们提出了许多方法, 并取得了良好效果。Bobick等[1]提出运动历史图(MHI: Motion History Image), 该方法充分利用了信息资源, 快速高效, 但没有解决目标跟踪问题, 且对户外场景的噪声干扰敏感。Efros等[2]提出一种基于光流法的时空运动描述子, 他将光流场进行了拓展, 该方法获得更详细的运动方向信息。Yilmaz等[3]提出时空体积(STV: Spatio-Temporal Volumes)方法, 该方法依赖于每帧图像中人体区域的准确提取, 但仅局限于若干种简单的单人行为, 不易扩展到多人间的复杂行为。Ahmad等[4]提出局部-全局光流(CLGOF: Combine Local-Global Optic Flow)法描述人体行为。Gorelick等[5]提出时空形状(STS: Space-Time Shape), 该方法由运动图像序列构建时空轮廓图, 通过求解泊松方程提取轮廓图的外形结构及运动方向特征, 该行为表征方法对目标的部分遮挡、 尺度缩放及视角的变化都有一定的鲁棒性。文献[6]采用3D模型法解决视觉变化的问题, 文献[7]对彩色直方图和姿态特征等进行了改进, 可以更好地获得目标连续的位置、 速度、 颜色和姿态等信息, 文献[8]提出耦合的基于观测向量分解的隐马尔科夫模型用于多人交互和遮挡问题, 文献[9]采用了几种特征相结合的方法对人体行为进行分析。
近年来, 时空兴趣点(STPI: Space-Time Points of Interest)也广泛应用于人体行为分析中。Dollar等[10]提出了基于Gabor滤波器的局部时空兴趣点算法, 并利用基于Cuboids的特征描述子。文献[11]将时空兴趣点用于两人交互中, 文献[12,13]采用了改进的时空兴趣点方法。
全局和局部特征都是通过提取感兴趣的区域表征人体行为。作为人体行为特征描述算子之一, 方向梯度直方图(HOG:Histogram of Oriented Gradient)首次用于人体行为检测[14], 随后是光流方向直方图[15], 后来在HOG基础上加入多尺度的思想, 得到方向梯度直方图金字塔, 目前已经应用在人体行为识别中。上述人体行为识别算法测试环境都是在单一环境下得到的, 并未应用到复杂的环境中, 而且面临光照、 人穿衣颜色和背景颜色相似度、 噪声等影响。基于上述问题, 笔者提出基于局部时空兴趣点和全局累积边缘图像特征描述子, 并用加权字典向量法将两者有机结合在一起, 该方法有效提高了视频中人体行为分析的识别率。
1 动作表示
1.1 时空兴趣点
时空兴趣点就是从视频中寻找出感兴趣且能代表视频中人体动作发生的时空事件。基于高斯滤波器和Gabor滤波器结合的局部时空兴趣点检测算法如下。
1) 对图像序列在空间域上进行高斯滤波, 然后在时间域上进行一维的Gabor滤波。
设视频序列为f,f中每帧二维图像的像素点亮度映射为f′:R2→R。利用高斯函数将g中的每帧图像转换到高斯空间, 得g:R2×R→R。如

2) 对经过高斯平滑的视频序列f:R2×R→R, 沿f的时间轴方向, 对每列元素进行选定窗口的一维Gabor滤波
其中hev(t,τ,ω)=-cos(2πtω)e-t2/τ2,hod(t,τ,ω)=-sin(2πtω)e-t2/τ2。τ2为滤波器在时间域上的尺度,ω为Gabor滤波器窗口大小,T为像素点强度。计算f中每点的R值, 根据设定窗口的大小对T进行极大值滤波, 检测出局部时空兴趣点的位置。
三维空间中点(x,y,t)的梯度矢量由梯度幅值m3D及两个方向的梯度夹角θ和σ组成, 定义如下

其中lx,ly,lt分别可在x,y,t方向上通过差值运算得到, 例如
lx=l(x+1,y,t)-l(x-1,y,t),ly=l(x,y+1,t)-l(x,y-1,t),lt=l(x,y,t+1)-l(x,y,t-1)

图1 3D-SIFT描述符Fig.1 3D-SIFT Descriptor
在准确提取视频中兴趣点的基础上, 抽取以兴趣点为中心的时空立方体, 将立方体划分为8个4×4×4的单元立方体(CU: Unit Cube), 统计每个CU的梯度直方图, 然后将所有CU的直方图联合起来, 构成该兴趣点的3D-SIFT[16]描述符(见图1)。
计算CU的梯度直方图, 由于立方体像素点的梯度矢量由(m3D,θ,σ)构成, 其中梯度方向包含了两个夹角θ和σ。将θ和σ的值按大小相等划分为若干个值的子区间。再定义一个变量φ,φ表示球面以水平方向和垂直方向而划分的子区间面积。 由于球面的特性, 所以划分的每个子区间面积不同, 且越靠近边界的子区间, 其面积越小。因此, 必须对其进行归一化处理,φ的计算公式如下

CU的梯度直方图计算如式

其中d(x,y,t)=-((x-x′)2+(y-y′)2+(t-t′)2)/(2α2)。iθ和iσ为特定角度θ和σ的子区间,α为尺度空间因子, (x,y,t)表示感兴趣点的坐标, (x′,y′,t′)表示该像素点在梯度直方图中的坐标,m3D(x′,y′,t′)为该像素点的灰度梯度幅值。
1.2 累计边缘图像
边缘检测的目的是表示一幅图像的边缘信息, 因为边缘图像能反映运动目标的边缘轮廓信息, 而轮廓形状是人们区别物体的重要因素之一。累积边缘图像就是把视频分为图像帧序列, 并提取每帧的边缘特征, 然后将每帧图像的灰度边缘特征累积到一幅图像中, 形成边缘图像帧序列。该方法的基本思想与经典的MHI(Motion History Image)很像, 但它获得的信息比MHI更丰富, 且能更好地表示人体行为。
设M(x,y)表示视频经过形态梯度操作处理后的某一帧图像;N(x,y)是M(x,y)经过Sobel算子得到的二值边缘图像;F(x,y)是M(x,y)与N(x,y)在每个像素点上相乘得到的边缘灰度图像, 大小与M(x,y)相同。又设H(x,y,t)为t时刻的灰度边缘特征累积图像, 则

以下为累积边缘图像(AEI: Accumulated Edge Image) 的计算步骤:
步骤1 初始化H(x,y,t), 所有像素初始化为0, 时间t为0;
步骤2 在视频中第1帧形态梯度图像M(x,y)上使用Sobel算子检测得到边缘图像N(x,y);
步骤3M(x,y)和N(x,y)相乘得F(x,y);
步骤4F(x,y)与前帧得到的H(x,y,t-1)在每个像素点上进行比较, 取灰度值大的像素点的灰度值为H(x,y,t)的新值;
步骤5 返回至步骤2, 直到视频的最后一帧。
累积边缘图像不是将每帧二值图像累积到一幅图像中, 而是将灰度边缘图像累积到一幅图像中。
2 动作分类
在训练视频构成的CU中, 随机选择一些CU, 采用K均值算法, 形成一个时空兴趣点代码字典。每个CU对应一个与其距离最近的代码, 称为时空兴趣点单词。给定一个时空兴趣点代码字典U=(u1,u2,…,um)以及一个时空兴趣点单词序列, 将该序列在代码字典U上的直方图定义为时空兴趣点字典(DSTPI: Dictionary of Space-Time Points of Interest)向量, 记为
其中元素(ui,pi)表示代码u在时空兴趣点单词序列中出现的次数为pi。同理, 得到累积边缘图像代码字典V=(v1,v2,…,vn)和累积边缘图像字典(DAEI: Dictionary of Accumulated Edge Image)向量
其中qi为累积边缘图像单词在序列中出现的次数。
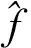
任意视频序列f, 其时空兴趣点字典向量和累积边缘字典向量分别为式(5)和式(6), 则视频序列f的加权字典向量定义为
((u1,λp1),…,(um,λpm),(v1,(1-λ)q1),…,(vn,(1-λ)qn))
其中λ=w(∑i=[1 ∶m]pi/∑i=[1 ∶n]qi)。
权重曲线w(x)为双曲正切函数
其中自变量x为视频序列f对应时空兴趣点单词数量与累积边缘图像单词数量之比。

其中Y=[y1,y2,…,yn,c],Jj=[γj1,γj2,…,γjn,c],c={c1,c2,…,cj}表示类别。
3 测试实验结果和分析
为了测试笔者算法的分类效果, 使用瑞典皇家理工学院机器视觉实验室的KTH视频数据库、 以色列Weizmann研究所的Weizmann视频数据库和某大学图像实验室小组录制的视频(CCUT-VDB)。KTH视频数据库包含6种动作: 走(walking)、 慢跑(jogging)、 跑(running)、 拳击(boxing)、 双手挥臂(handwaving)和拍手(handclapping), 它由25个表演者分别在4种不同的环境(室外、 室内, 室外放大, 室外且穿不同颜色的衣服)下完成。包含599段视频, 每段视频分辨率为160×120, 帧速率为25帧/s, 每段视频大约是4 s。Weizmann视频数据库包含10种动作: 走(walk)、 跑(run)、 跳(jump)、 侧移(side)、 弯腰(bend)、 原地跳(pjump)、 jack、 skip、 单挥臂(wave1)和双挥臂(wave2), 每种动作由10个人完成, 背景和视角均不变。包含90段视频, 每段视频分辨率为180×144。帧速率为50帧/s, 每段视频大约是4 s。某大学图像实验室小组自己录制的动作视频数据库由4个人完成6种典型的动作, 其中包括在相同背景下多个动作。图2为KTH和Weizmann视频数据库样本图像, 图3为某大学实验室视频数据库样本图像CCUT-VDB。

图2 KTH和Weizmann视频数据库Fig.2 KTH and Weizmann video database

图3 实验室视频数据CCUT-VDBFig.3 CCUT-VDB video data in the lab
对于时空兴趣点的检测, 选用Dollar推荐的参数:σ=2,τ=4,ω=4/τ。在上面参数值条件下对KTH、 Weiznman视频数据库检测结果如图4所示, 实验室视频数据库检测结果如图5所示。

图4 KTH和Weiznman视频数据兴趣点检测Fig.4 KTH and Weiznman video detection of interest points data

图5 实验室视频数据CCUT-VDB兴趣点检测Fig.5 CCUT-VDB interest point detection
边缘图像能反映人的边缘轮廓信息, 而累积边缘图像可以反映人运动趋势及强烈程度。实验中首先把视频序列f分解为图像帧序列, 提取每帧图像边缘特征, 经过计算得到每帧图像的灰度边缘特征, 然后将得到的每帧灰度边缘图像累积到一幅图像中, 得到累积边缘图像(见图6)。

图6 累积边缘图像Fig.6 Accumulated edge image
在得到上述两种结果图后, 采用加权字典向量法将DSTPI(Dictionary of Space-Time Points of Interest)和DAEI(Dictionary of Accumulated Edge Image)特征有机的结合起来, 并训练部分视频作为样本, 然后采用最小距离法对其进行分类。表1是传统经典检测算法得到的结果和采用笔者的STPI-AEI检测算法得到的分类结果对比, 表2是前人的算法和笔者检测算法的平均识别率。通过检测结果得出, 对于相同的行为, 笔者检测算法对人行为的识别率明显优于传统经典检测算法。

表1 传统经典方法识别结果和笔者方法得到的识别结果对比
与传统方法相比, 笔者方法在相同环境和相同动作下的识别率有明显提高。可看出, 笔者方法某些动作的识别率为100%, 而其他一些相近的动作间还有较大的识别误差。识别率为100%的这些动作发生在相同的区域, 且对人体轮廓和运动趋势有要求而对运动强烈程度要求不高。其他一些动作是人体的四肢运动, 对人体的运动强烈程度要求较高, 由此看出, 笔者算法在检测运动强烈程度方面虽有提高但还有所欠缺。
表2给出了KTH和Weizmann数据库上其他经典方法和笔者方法的识别率比较结果, 由表2中数据可以得出, 笔者方法的识别率有明显提高。

表2 不同方法的检测平均识别率
4 结 语
笔者提出了基于局部时空兴趣点和全局累积边缘图像特征描述方法, 并用加权字典向量法将两者有机结合在一起。集合了全局特征和局部特征的优缺点, 克服了现实中的部分缺点, 如: 背景、 光照、 噪声和遮挡等影响。提出的方法不仅可以处理提供的视频数据库, 还可以处理网络上的视频数据, 都具有良好效果。该方法不仅识别率高, 且加强了对运动强烈程度的检测, 提高了相似动作的识别率。
[1]BOBICK A F, DAVIS J W. The Recognition If Human Movement Using Temporal Templates [J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2001, 23(3): 257-267.
[2]EFROS A A, BERG A C, MORI G, et al. Recognition Action at a Distance [C]∥Proc of the 9th IEEE Int’l Conf on Computer Vision. Washington: IEEE Computer Society, 2003: 726.
[3]YILMAZ A, SHAH M. Action Sketch: A Novel Action Representation [C]∥Proc of the 2005 IEEE Computer Society Conf on Computer Vision and Patter Recognition. Washington: IEEE Computer Society, 2005: 984-989.
[4]AHMAD M, LEE S. Human Action Recognition Using and CLG-Motion Flow from Multi-View Image Sequences [J]. Pattern Recognition, 2008, 41(7): 2237-2252.
[5]GORELICK L, BLANK M, SHECHTMAN E, et al. Action as Space-Time Shapes [J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2007, 29(12): 2247-2253.
[6]谷军霞, 丁晓青, 王生进. 基于人体行为3D模型的2D行为识别 [J]. 自动化学报, 2010, 36(1): 46-53. GU Junxia, DING Xiaoqing, WANG Shengjin. Human 3D Model-Based 2D Action Recognition [J]. Acta Automatica Sinca, 2010, 36(1): 46-53.
[7]张德才. 视频流中多人体跟踪算法研究 [D].长春: 吉林大学计算机科学与技术学院, 2011. ZHANG Decai. Multiple Human Studies Video Stream Tracking [D]. Changchun: College of Computer Science and Technology, Jilin University, 2011.
[8]郭萍. 基于视频的人体行为分析 [D]. 北京: 北京交通大学交通运输学院, 2012. GUO Ping. Analysis of Human Action Based on Video [D]. Beijing: College of Transportation Institute, Beijin Jiaotong University, 2012.
[9]李佳. 基于视频的室内人体简单行为分析 [D]. 西安: 西安电子科技大学电子工程学院, 2013. LI Jia. Analysis of Video Based Indoor Simple Human Action [D]. Xi’an: College of Electronic Engineering, Xi’an University of Electronic Science and Technology, 2013.
[10]DOLLAR P, RABAUD V, COTTRELL G, et al. Behavior Recognition via Sparse Spatio-Teporal Features [C]∥Visual Surveillance and Performance Evaluation of Tracking and Surveillange. USA: IEEE, 2005: 65-72.
[11]韩磊, 李君峰, 贾云得. 基于时空单词的两人交互行为识别方法 [J]. 计算机学报, 2010, 33(4): 776-784. HAN Lei, LI Junfeng, JIA Yunde. Human Interaction Recognition Using Spatio-Temporal Words [J]. Chinese Journal of Computer, 2010, 33(4): 776-784.
[12]刘长红, 陈勇, 王明文. 杂乱背景和摄像机移动下的时空兴趣点检测 [J]. 中国图像图形学报, 2013, 18(8): 982-989. LIU Changhong, CHEN Yong, WANG Mingwen. Under the Clutter Background and Camera Movement of Space-Time Interest Point Detection [J]. China Journal of Image and Graphics, 2013, 18(8): 982-989.
[13]付朝霞, 王黎明. 基于时空兴趣点的人体行为识别 [J]. 微电子学与计算机, 2013(8): 28-30. FU Zhaoxia, WANG Liming. Human Action Recognition Based on Space-Time [J]. Microelectronics and Computer, 2013(8): 28-30.
[14]DALAL N, TRIGGS B, SCHMID C. Histograms of Oriented Gradients for Human Detection [C]∥Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego, USA: IEEE, 2005: 886-893.
[15]YUAN Junsong, LIU Zicheng, WU Ying. Discriminative Video Pattern Search for Efficient Action Detection [J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2011, 33(9): 1728-1743.
[16]SHAO L, MATTIVI R. Feature Detector and Descriptor Evaluation in Human Action Recognition [C]∥Proceedings of the ACM International Conference on Image and Video Retrieval. [S.l.]: ACM, 2010: 477-484.
(责任编辑: 刘俏亮)
Analysis of Human Action in Video
SHI Dongcheng, FENG Zhanjun
(College of Computer Science and Engineering, Changchun University of Technology, Changchun 130012, China)
In order to solve machine vision reduce the effects of background and noise on the video feature extraction, and to improve recognition results. We propose a human action analysis method by combining the local space-time interest points and global accumulated edge image feature based on the study of human action representation and the full consideration of the advantages and disadvantage of the local and global features. First, local space-time points of interest and global accumulated edge image feature are extracted from the video sequences. Then we use the weighted dictionary to combine them together organically, finally we use the minimums distance method for human action analysis and identification. This method can effectively obtain the spatial characteristics of human, human edge contour and the human movement trends and intensity, the experimental show that our method is faster and gains a higher recognition accuracy generally inceased by 2% to 5%.
space-time point of interest; accumulated edge image; action analysis
1671-5896(2014)05-0521-07
2013-11-02
国家自然科学基金资助项目(11071026)
史东承(1959— ), 男, 长春人, 长春工业大学教授, 硕士生导师, 主要从事图像与视频通信、 视频分析、 基于内容的媒体分析与检索、 数字媒体内容理解、 智能视频监控系统、 视觉计算、 图像处理与模式识别研究, (Tel)86-18686485278(E-mail)dcshi@mail.ccut.edu.cn。
TP391; TG156
: A
猜你喜欢
湘潭大学自然科学学报(2022年2期)2022-07-28
四川党的建设(2022年8期)2022-04-28
小学生学习指导(低年级)(2020年11期)2020-12-14
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
摄影之友(影像视觉)(2018年12期)2019-01-28
作文大王·低年级(2018年10期)2018-12-06
中国交通信息化(2018年3期)2018-06-13
初中生世界·八年级(2017年3期)2017-03-24
中国交通信息化(2016年2期)2016-06-06
