
XML Schema匹配中的元素相似性度量算法研究
2014-09-14 07:24苟和平景永霞姜永亮
沈阳理工大学学报 2014年5期
苟和平,景永霞,姜永亮
(1. 琼台师范高等专科学校 信息技术系,海南 海口 571127;2. 海南师范大学 网络中心,海南 海口 571127)
XML Schema匹配中的元素相似性度量算法研究
苟和平1,景永霞1,姜永亮2
(1. 琼台师范高等专科学校 信息技术系,海南 海口 571127;2. 海南师范大学 网络中心,海南 海口 571127)
为了实现XML Schema自动匹配,解决XML数据共享问题,提出一种基于语义和结构的模式自动匹配算法。首先采用基于单词网络(wordnet)的语义匹配算法及字符串结构匹配(n-grams)算法计算来自两个模式树中节点对名称相似度,然后获取包含此节点对的各自路径集,再通过计算对应路径集中每对路径的最大相似度获得此节点对的结构相似度。实验分析表明此方法具有较好的查全率和查准率。
XML Schema;模式匹配;语义;路径相似
目前,在数据集成、数据仓库和数据挖掘等许多数据共享应用中,模式匹配是非常关键的技术之一[1]。由于数据模式多样,结构复杂,给数据模式的自动集成带来很大的困难[2]。随着XML的出现和广泛应用,XML已经成为数据表示和交换的标准。因此,实现XML Schema的自动集成,是实现XML型数据共享应用的关键。目前已经出现很多的XML Schema模式匹配方案和匹配系统,其中,比较典型的系统有Cupitd、COMA/COMA++、Similarity Flooding(SF)、SMatch等[3-4]。为解决XML文档之间的相似性,实现XML文档聚类,文献[5-6]把XML文档树表示为节点路径的集合,然后通过计算路径相似度进而实现XML文档相似性的判定。本文在此基础上,提出一种基于最大公共路径相似度匹配的XML Schema匹配算法。通过对XML Schema树中的所有节点进行语言学相似性分析,并将模式树表示成从根节点出发到叶子节点的路径集合,然后对路径中的节点进行相似度分析,找出待对比两条路径的公共最大相似子路径,以计算节点之间的结构相似性。
1 改进的XML Schema模式匹配算法
1.1 XML Schema匹配算法的基本概念
为后续计算方便,先给出几个相关的定义。
定义1模式树。对于一个给定的XML Schema,将其表示成树形结构T={N,E},其中N(n1,n2,…,nn),表示模式中节点的集合;E{(ni,nj)|(ni,nj)∈N},表示模式树中边的集合。
定义2路径与子路径。一条路径p=
定义3最大相似路径。给定两条包含节点ni、nj的路径pi、pj,最大相似路径P(pi,pj)是指pi、pj所有包含节点ni、nj的子路径中,以节点ni、nj对应起始的所有连续相似节点组成的路径。
模式树T1、T2如图1所示,其中待比较节点元素n1,n2,其相似性度量主要通过节点的内部属性和外部结构关系来决定。内部属性的相似度即节点的语言学相似度lingSim(N1,N2),通过计算节点的名称、数据类型和基数约束等相似度获得;外部结构即节点的结构相似度strucSim(n1,n2),是指节点的祖先节点和孩子节点的相似性分析。节点相似度的计算如公式(1)所示。
nodeSim(n1,n2)=w1*lingSim(n1,n2)+w2*strucSim(n1,n2)
(1)
式中w1、w2分别是语言学相似度和结构相似度的权重,w1+w2=1。同时在计算节点相似度时需要指定语义相似度阈值和路径相似度阈值。
1.2 语言学相似度
对于两个节点n1∈T1,n2∈T2,则其语言学相似度lingSim(n1,n2)由计算节点的名称相似度(nameSim)、数据类型相似度(datatypeSim)和约束相似度(constSim)来决定,如公式(2)所示。

图1 XML Schema模式树
lingSim(n1,n2)=λ1*nameSim(n1,n2)+
λ2*datatypeSim(n1,n2)+
λ3*constSim(n1,n2)
(2)
式中λ1、λ2、λ3分别是对应相似度的权重,且λ1+λ2+λ3=1。
1)名称相似度计算
对于节点名称相似度主要是从节点元素的name属性,如:
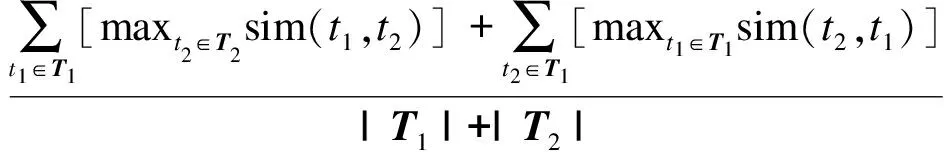
(3)
式中,sim(t1,t2)=
max(semanticSim(t1,t2),ngramSim(t1,t2)),
|T1|和|T2|为两个名字字符串包含的独立单词数,字符串结构匹配(ngramSim)采用n-grams方法[8]计算。
例如:t1=″date″,t2=″day″,采用wordnet计算语义相似结果为:semanticSim(t1,t2)=0.9176;本文采用2-gram方法计算结构相似度,名称date和day分别表示为{da,at,te}和{da,ay},则

式中:a为t1中包含2-gram 的数量;b为t2中包含2-gram的数量;c为t1、t2中包含公共2-gram的数量。
2)数据类型相似度
数据类型相似度是节点语言学匹配的另一个主要指标,有些节点虽然在语义上非常相似,但由于其数据类型不同,也可能表达完全不同的意思。因此,本文在进行数据类型匹配时需要查询文献[6,9]提出的数据类型相似度表(如表1所示),以获得数据类型匹配程度。

表1 数据类型相似度表
3)基数约束相似性分析
基数约束主要是对XML Schema 模式中节点的minOccurs和maxOccurs两个属性进行相似性判断,minOccurs和maxOccurs取值及和DTD的关系如表2所示。其取值的相似性主要是通过与DTD中的约束关系进行映射得到基数约束的相似度表[6](如表3所示)。本文中的基数约束相似度主要是通过查询此相似度表获得。

表2 XSD和DTD之间的映射关系

表3 基数约束相似度表
1.3 节点结构相似度
节点结构相似度主要是计算两个节点所对应的路径相似度。这样能够避免由于本来不应匹配的元素由于语义相同而匹配在一起。对于节点n1∈T1,n2∈T2,则n1、n2的结构相似度计算如下:
1)分别计算包含节点n1、n2的路径集P1={pi}(i=1,2,…,m),P2={pj}(j=1,2,…,n),其中,m、n分别指P1、P2中所包含的路径个数。
2)对于P1中的路径pi,分别计算与P2中的各个路径pj的最大相似度MSP(pj,pi)。
3)对于P2中的路径pj,分别计算与P1中的各个路径pi最大相似度MSP(pi,pj)。
4)计算机两个节点的结构相似度。
计算方法如公式(4)所示。

(4)
式中,最大相似度MSP(pi,pj)的计算过程如下:
设pi=
根据图2所示,以(n1,n2)节点对为初始点,分别向前和向后比较两个路径中的节点对。在上例中,向前比较,则先比较(f,5),如果(f,5)的语言学相似度大于指定的语言学相似度阈值,则将此节点的语言学相似度加入到MSP(pi,pj)中,分别移动两路径的指针,进行下一轮比较,即(e,4)节点对的比较,直到其节点对语言相似度小于指定阈值时,向前比较停止,然后继续后向节点对的比较,即开始比较节点对(g,6)等,方法同前向比较。具体计算算法如下:

图2 路径最大相似度计算示例
输入:待计算的两条路径pi、pj
输出:路径最大相似度MSP(pi,pj)
elea[]=pi.split(″/″);
eleb[]=pj.split(″/″);
numa=elea.length;
numb=eleb.length;
m=k=location(pi,n1);
n=l=location(pj,n2);
while(m>0 &&n>0){
sim=lingSim(elea[m-1],elea[n-1]);
if(sim>0)eachpathsim=eachpathsim+sim;
else break;
m--;
n--;
}
while(k k++; j++; sim=lingSim(elea[k],elea[l]); if(sim>0)eachpathsim=eachpathsim+sim; else break; } max=(numa>numb? numa:numb); MSP(pi,pj)=eachpathsim/(max-1); 根据图1所示的XML Schema模式树,将其进行节点和路径序列化后,得到模式树中的节点集N和路径集合P。其中路径主要是从根节点出发到达各个叶子节点的路径,路径集如表4、表5所示。 表4 模式T1的路径集P1 表5 模式T2的路径集P2 根据文献[1]中算法的匹配参数选择办法,选用其相应的参数为:权重值w1=0.5、w2=0.5、λ1=0.8、λ2=0.1、λ3=0.1及语义和路径相似度阈值γ1=0.3、γ2=0.3,则模式树T1和T2的节点语义相似度矩阵和结构相似度如图3和图4所示,其最终的节点匹配结果如图5所示。 图3 模式树T1和T2的节点语义相似度矩阵 图4 模式树T1和T2的节点结构相似度矩阵 图5 模式树T1和T2的节点匹配相似度矩阵 通过上述XML Schema模式节点的语言学和结构匹配算法和图5所示的计算结果,获得两个模式中所匹配的节点如表6所示。 XML Schema匹配的评价标准主要是查准率(precision)、查全率(recall)和F-measure,计算如公式5所示。 (5) 式中:A表示本来相似但没有识别出匹配的节点;B表示识别出的正确匹配的节点;C表示识别出的错误匹配的节点。 表6 模式树中的节点匹配映射表 本文同时实现了文献[1]中提出的XML Schema匹配算法,对于上述实验案例,在相同的权重与相似度阈值的条件下,其与本文算法的查准率(precision)、查全率(recall)和F-measure的值比较如图6所示。实验结果表明,本文算法的F-Measure的值比文献[1]提出算法的值高,表明此算法能够较好地识别不同模式中的相似节点对。 图6 算法性能比较 本文提出的一种基于节点元素的语言相似度和结构相似度的模式匹配算法,主要是针对节点元素在语言相似度大于指定阈值的前提下进行节点的结构匹配。结构匹配主要是计算节点的路径相似度,通过找出包含待对比节点的所有路径集,对于路径集中的每对待匹配路径计算出其最大相似度作为结构相似度。实验结果表明,本文提出的算法具有较好的可行性,但由于在算法中采用了wordnet单词网络计算语义相似度,致使计算时间增加。如何采用一种自翻译的技术来实现语义相似度计算,将是今后的努力方向。 [1]Algergawy A,Nayak R,Saake G. XML Schema Element Similarity Measures:A Schema Matching Context[C].In:On the Move to Meaningful Internet Systems:OTM 2009,Vilamoura,Portugal,1-6,2009:1-6. [2]李君君.信息集成:基于XML Schema 的模式匹配[J].情报科学,2006,24(11):1696-1699. [3]Do H H,Rahm E.Matching large schemas:Approaches and evaluation[J].Information Systems,2007,32(6):857-885. [4]Giunchiglia F,Shvaiko P,Yatskevich M.S-Match.an algorithm and an implementation of semantic matching[C].Also:In Proceedings of the European Semantic Web Symposium,LNCS 3053,2004:61-75. [5]Nayak R,Tran T.A Progressive Clustering Algorithm to Group the XML Data by Structural and Semantic Similarity[J].International Journal of Pattern Recognition and Artificial Intelligence,2007,21(4):723-743. [6]王大刚,谢荣传,彭俊.基于XML Schema 的数据匹配方法的研究[J].计算机技术与发展,2008,18(6):28-31. [7]George M,Christiane F.WordNet:An Electronic Lexical Database[M].cambridge:MIT Press,1998:23-46.[8]Nayak R,Tran T.A progressive clustering algorithm to group the XML data by structural and semantic similarity[J].International Journal of Pattern Recognition and Artificial Intelligence,2007,21(4):723-743. [9]Algergawy A,Nayak R,Saake G.Element similarity measures in XML schema matching[J].Information Sciences,2010,(180):4975-4998. StudyonElementSimilarityMeasureinXMLSchemaMatching GOU Heping1,JING Yongxia1,JIANG Yongliang2 (1. Department of Information Technology,Qiongtai Teachers College,Haikou 571127,China;2. Network Center,HaiNan Normal University,Haikou 571127,China) Order to realize the XML schema matching and to solve the difficulty of XML data sharing,an approach based on semantics and structure is presented in this to achieve automatic schema matching.Semantic measure based on wordnet techniques and syntactic measure based on n-grams are proposed to find similarity degree among schema tree element names.The structural similarity among two different XML schema elements is measured by finding the maximum similarity in which each pair path includes the two elements respectively.Experimental results indicate that the proposed method has high precision and recall. XML Schema;schema matching;semantics;path similarity 2014-03-24 国家自然科学基金项目(71361008);海南省自然科学基金项目(612136);海南省高等学校科学研究项目(Hjkj2013-53) 苟和平(1978—),男,副教授,研究方向:信息集成、数据挖掘。 1003-1251(2014)05-0015-06 TP311.5 A 马金发)2 实验分析







3 结束语
猜你喜欢
数学物理学报(2022年5期)2022-10-09
电子元器件与信息技术(2021年5期)2021-07-27
天津外国语大学学报(2021年1期)2021-03-29
河北画报(2020年8期)2020-10-27
天津外国语大学学报(2020年4期)2020-08-24
数码世界(2020年5期)2020-06-23
计算机时代(2017年2期)2017-03-06
海外华文教育(2016年1期)2017-01-20
电脑知识与技术(2016年13期)2016-06-29
浙江大学学报(工学版)(2016年2期)2016-06-05
