
基于听觉仿生模型的乐器识别
2014-09-15 04:29秦晓瑜陈海霞王连明
东北师大学报(自然科学版) 2014年1期
张 琳,王 珊,秦晓瑜,陈海霞,王连明
(1.东北师范大学应用电子技术研究所,吉林 长春 130024;2.通化师范学院物理系,吉林 通化 134000)
乐器识别作为声源识别的一个重要分类,是深入研究音频检索的基础.传统的乐器识别大多是以MFCC和LPCC等作为乐器的声学特征[1],采用高斯混合模型、隐马尔可夫模型和神经网络等方法进行识别.文献[2]研究了Mel频率、delta倒谱系数和线性预测倒谱系数等声学特征,然后用这些特征对16种西方管弦乐器进行了自动识别比较,其中最高的识别正确率不到80%[3-4].对于使用不同乐器的独奏表演或者不同的音乐片段,基于不同的声学特征进行识别,识别精度往往差别很大,而且不能找到一个良好的声学特征在识别各种乐器时均能表现出良好的健壮性.然而,研究发现,人类的听觉系统在听音辨物方面有独特的优势,对不同声音的快速分辨几乎是稳定的,这就启发人们在某些环节上模仿人类听觉系统的听觉机理的处理机制,以提高识别系统对各种乐器识别的稳定性.
现有的听觉模型主要用于语音识别[5],采用包含时间信息的三维同步谱和发放率谱模拟耳蜗核的特征提取功能,并且采用5层自组织特征映射(self-organizing map,SOM)网络模拟听皮层的神经网络拓扑结构,该模型复杂、计算量大.
针对乐器识别这一具体应用,本文基于文献研究成果,提出了只提取频率和强度二维特征的耳蜗背腹侧核(posteroventral cochlear nucleus,PVCN)模型和单层SOM的听皮层模型,简化了模型复杂度.
1 听觉系统生理结构及其数学模型
听觉系统是对声音收集、传导、处理、综合的感觉系统,一般将听觉系统划分为外周听觉系统和听觉中枢神经系统.外周听觉系统包括外耳、中耳和内耳.中枢神经系统由下而上依次为耳蜗核、上橄榄复核、外侧丘系、下丘、内侧膝状体核、听皮层.基于听觉系统的生理结构,构建其数学模型并用MATLAB软件进行计算机仿真.整个仿生听觉系统流程如图1所示.
1.1 基底膜和gammatone滤波器模型
耳蜗对声波的分析,是由基底膜的机械作用完成的.基底膜从功能上看相当于一个频谱分析仪,它能够把传入人耳的声音信号在频域上按频带进行分解.不同频率的声音产生不同的行波,其峰值出现在基底膜的不同位置上(如图2所示) .图2中显示的是展平的耳蜗,其中:a是高频声音产生的行波,在狭窄而呈刚性的基底膜基部附近耗散;b是低频声音产生的行波能够一直传播到蜗顶才消失;c是在基底膜上产生最大振幅的频率的位置编码[6].
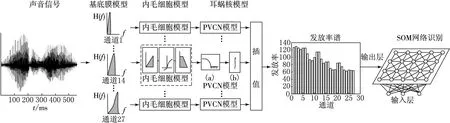
图1 仿生听觉系统流程图
基底膜不同位置对声音的响应过程相当于一个带通滤波器,各种研究表明,基于听觉心理和听觉生理的gammatone滤波器组模型能很好地模拟基底膜的滤波特性.Gammatone滤波器在时域上用一个冲击响应函数来表示其滤波特性,该gammatone函数表达式为

图2 基底膜对不同频率声音的反应

其中:n是滤波器阶数(在此n=4);u(t)是单位阶跃函数,当t<0,u(t)=0(当t>0,u(t)=1);f0是中心频率,单位为 Hz;Ф是初始相位,且Ф=0;B是gammatone滤波器的带宽且B=b1·ERB(f0),b1=1.019,ERB是等效矩阵带宽,且 ERB(f0)=24.7+0.108f0.将gammatone函数进行Laplace变换,再从s域映射到离散z域,得到8阶的z域传递函数[7],则每个gammatone滤波器由4个二阶的传递函数级联实现.该滤波器中采样频率为40kHz.
1.2 内毛细胞及其Meddis模型
内毛细胞是将机械能转化成膜电位极性的听觉感受器细胞.每个内毛细胞含有大约100个毛状的静纤毛,静纤毛的弯曲导致内毛细胞发生去极化和超极化,将声压转换成神经电信号,这一过程是对声波幅度进行脉冲编码,脉冲发放概率与输入声波幅度相对应.内毛细胞以及与听觉神经相连的突触区域有几个重要的生理反应特性,如半波整流、非线性饱和抑制、短时自适应和快速自适应特性等.
内毛细胞脉冲的发放概率是声音刺激的强度的函数,这一级公认的模型是Meddis模型,这一模型与真实的生理学实验结果非常接近.Meddis模型假定在毛细胞中存在3个传递神经递质的发放源,且神经传递素在这3个发放源中通过再回收和再综合处理环路传递信息[8-9].

则神经的发放概率为:

(2)—(6)式组成了整个内毛细胞 Meddis模型,其中k(t)是细胞膜的渗透性,stim(t)是输入声波的瞬时幅度,q(t)是自由释放的递质量,c(t)是突触间隙包含的递质量,w(t)是再生仓库中的递质量,g,y,x,r,l,h,A 和B 是时间常数,dt为采样间隔[8].
1.3 耳蜗后腹侧核及其PVCN模型
耳蜗核一般分为3个子核,分别为前腹侧核(AVCN)、后腹侧核(PVCN)和背侧核(DCN).AVCN中神经元主要功能是对低频刺激锁相;DCN的神经元主要功能是侧抑制作用;PVCN中主要是建立和振荡反应类型神经元.生理学实验表明振荡反应类型的神经元在刺激过程中不断发放,发放率单调依赖于刺激的强度,此类神经元提取声音信号的强度信息.本文为获取表征声音信号强度的发放率信息,忽略了AVCN和DCN的功能,建立PVCN模型模拟PVCN的功能.
PVCN模型主要完成对乐器声音特征的提取.该PVCN模型包含包络检测、短时积分和插值3个步骤.通过包络检测获取各通道的平均发放率,包络检测功能由一个低通滤波器实现,其表达式如(7)式所示.短时积分由一个积分器实现,获取各通道的平均发放率信息,积分器表达式如(8)式所示.最后,通过对各通道的平均发放率做插值,获取发放率谱,该发放率谱是包含声音频率和强度信息的二维特征.

1.4 听皮层及其SOM模型
听皮层是处理声音使人产生听觉的大脑高级中枢.研究表明,大脑接受外界输入模式时,将会分为不同的对应区域,各区域对输入模式具有不同的响应特征,而且这个过程是自动完成的,这种学习被称为自组织学习.
1981年,Kohonen教授提出一种自组织特征映射网,简称SOM[10].该网络与人大脑中的自组织映射特性非常相似,能将任意维输入模式在输出层映射成一维或二维图形,并保持其拓扑结构不变.因此,本文选用SOM网络模拟大脑听皮层的功能.如图3所示,SOM是一个两层的神经网络,输入层模拟感知外界输入信息的耳,输出层(也被称为竞争层)模拟做出响应的听皮层.竞争层上的神经元以二维形式排列成节点矩阵.文献[11]中详细描述了自组织算法的具体步骤.

图3 SOM的二维网络结构
2 仿真实现
本文仿生听觉系统包含27个并行通道,用Bark代表一个临界频带的宽度,则覆盖的频率范围是从1.3到18Bark,对应频率为133~5400Hz,每路覆盖2/3Bark.尽管使用更多的通道可以使耳蜗输出的空间分辨率提高,但是同时计算时间和复杂度也会增加.因此,为了平衡空间分辨率和计算量,本文选择27个并行的gammatone滤波器组模拟基底膜的并行频率通道.在gammatone滤波器模型之后各级、各通道的输出将分别被处理.
内毛细胞Meddis模型包括半波整流和非线性饱和、短时自适应、低通滤波和快速自动增益控制.根据生理学实验,Meddis模型的各参数取值:A=5,B=300,g=2000,y=8,l=2500,r=6580,x=66.31,h=50000[8].经过 Meddis模型,获取了各通道脉冲的发放概率.
PVCN模型从各通道中提取发放率谱,该发放率谱即为本系统的特征矢量.图1描述了各通道PVCN模型具体的处理流程,图1(a)为用作包络检测的低通滤波器,以获取平均发放概率信息.图1(b)是积分器.各通道的积分值被称为发放率,最后通过对各个通道的发放率做插值,获得发放率谱.
本文所用素材库来自于加拿大麦吉尔大学MUMS库,挑选在室内环境下采集的吉他、竖琴、小号、钢琴、萨克斯、喇叭和小提琴7种乐器的共243个独奏乐曲文件,采样频率为44.1kHz,建立本文所用乐器素材库.将乐器素材库中的243首乐曲送入如图1所示的仿生听觉系统,获得243个发放率谱特征矢量,每个特征矢量均为27维.为直观的表示不同乐器特征矢量之间的差异,每种乐器任意选取一个特征矢量,绘制成发放率谱图.图4即为绘制的7种乐器的发放率谱图,在每种乐器的发放率谱图中,横轴代表通道,不同通道即为不同中心频率,纵轴表示发放率大小.发放率谱图是特征矢量的图形化表示.

图4 7种乐器的发放率谱图
3 识别结果
将7种乐器的243个特征矢量以33%/67%比例分别用作训练样本和测试样本,建立一个二维的SOM神经网络对样本进行分类识别.该网络输入层由27个神经元组成,相应于特征矢量的维数.竞争层是由5×5=25个神经元组成的二维平面阵列.将78个训练样本送入网络,训练结果如图5所示.
图5中由x轴和y轴组成的二维平面即表示SOM网络的竞争层,25个方格代表25个神经元,z轴表示神经元突起的高度.神经元的突起由样本重叠形成,表示这些神经元在训练中总是被击中,在竞争中获胜.相反,那些未突起的神经元由于未被样本击中,在竞争中失败.在二维平面上的7个神经元突起,表示训练样本被分成了7类,每一个突起表示一类,即一种乐器.
最后,将165个测试样本送入SOM网络进行测试,测试结果如表1所示,平均识别率在75%以上.

图5 训练结果示意图
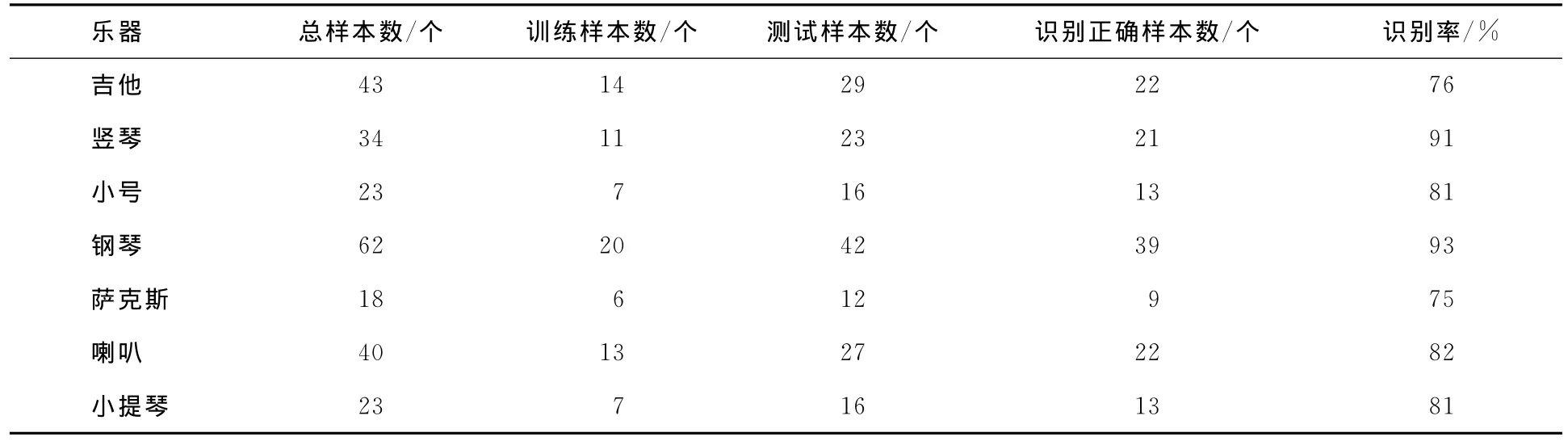
表1 乐器识别结果
4 结论与展望
本文提出了一个对于独奏乐曲乐器识别的仿生听觉系统.与以往用数字信号处理提取单一乐器声学特征并用基于统计的分类方法来进行乐器识别相比,本文仿生听觉系统提取的发放率谱特征在识别各种乐器时均能表现出良好的健壮性,平均识别率在75%以上.实验证明了本文听觉仿生系统中PVCN模型提取的二维特征参数及简化的听皮层SOM模型在乐器识别中的有效性.
本文系统也具有一定的局限性,由于PVCN模型积分时间的限制,只对每个乐器1s短时声音进行特征提取,未能涵盖乐器不同音域的所有特征.如果采用连续乐曲声音进行乐器识别,将会有效提高识别率.同时,本文系统为简化计算,只采用了27个并行通道,覆盖的频率范围仅为133~5400Hz,不能充分利用各类乐器的声音信息,如果增加通道数量和扩大覆盖的频率范围,会使识别率有更大的提高.这也是我们未来的改进方向.
[1]ERONEN A.Comparison of features for musical instrument recognition[J].Workshop on Signal Processing for Audio and Acoustics(WASPAA),2001:19-22.
[2]SUMIT KUMAR BANCHHOR,ARIF KHAN.Musical instrument recognition using spectrogram and autocorrelation.International Journal of Soft Computing and Engineering[J].2012,2(1):1-4.
[3]林玉志.基于声学特征的乐器识别研究[D].广州:华南理工大学,2012.
[4]邓见光,潘晓恒,林玉志.基于声学特征的乐器识别综述[J].东莞理工学院学报,2012,19(3):58-64.
[5]吴玺宏.人工神经网络听觉模型及其在说话人识别中的应用[D].北京:北京大学,1995.
[6]MARK E BEAR,BRRY W CONNORS,MICHAEL A PARADISO.神经科学——探索脑(中文版)第2版[M].北京:高等教育出版社,2004:332-361.
[7]陈世雄,宫琴,金慧君.用 Gammatone滤波器组仿真人耳基底膜的特性[J].清华大学学报:自然科学版,2008,48(6):1045-1046.
[8]MEDDIS R.Simulation of mechanical to neural transduction in the auditory receptor[J].Journal of the Acoustical Society of America,1986,79(3):702-711.
[9]ALISTAIR MCEWAN,ANDRÉVAN SCHAIK.A silicon representation of the meddis inner hair cell model[J].Proceedings of the ICSC Symposia on Intelligent Systems & Application,2000:1544-078.
[10]TEUVO KOHONEN.The Self-organizing Maps[J].Proceedings of the IEEE,1990,78(9):1464-1480.
[11]杨占华,杨燕.SOM 神经网络算法的研究与进展[J].2006,32(16):201-203.
猜你喜欢
听力学及言语疾病杂志(2022年5期)2022-09-20
基础医学与临床(2020年6期)2020-02-12
中华耳科学杂志(2020年6期)2020-01-08
电子制作(2019年11期)2019-07-04
电子制作(2018年16期)2018-09-26
振动与冲击(2018年4期)2018-03-05
中华耳科学杂志(2018年6期)2018-01-16
振动与冲击(2017年14期)2017-07-19
系统工程与电子技术(2016年7期)2016-08-21
火控雷达技术(2016年2期)2016-02-06
