
基于ARM NEON的H.265解码器优化
2014-09-18 00:15简欢
电视技术 2014年15期
简 欢
(福州瑞芯微电子有限公司,福建福州350003)
ARM NEON已广泛应用于数字信号处理和多媒体应用中,特别是音视频编解码。本文基于ARM Cortex A9处理器平台,对NEON处理器的结构、指令和编程优化方法等技术进行了研究,并在此平台上开展了H.265解码器的具体实现和优化。通过在瑞芯微电子的RK3188 SDK开发板上的实际测试,结果表明NEON处理器可以较好地提高H.265软件解码器在Cortex A9处理器上的执行效率。
1 ARM Cortex A9架构及NEON处理器简介
1.1 ARM Cortex A9架构
ARM Cortex A9是高性能ARM处理器,可实现各种基于ARM v7体系结构的应用和功能。Cortex A9处理器具备高效的、长度动态可变和多指令执行超标量体系结构,提供采用乱序猜测方式执行的8阶管道处理器。在消费类、网络、企业和移动应用中,Cortex A9都展示出了极高的性能和效率。
Cortex A9微体系结构既可以配置成可伸缩的多核处理器,也可以配置成单核处理器。可伸缩的多核处理器和单核处理器支持多种L1高速缓存配置,同时支持可选的L2高速缓存控制器,Cortex A9的灵活性保证了对各种应用领域和市场的适用性。
1.2 NEON多媒体处理器简介
Cortex-A9的NEON处理器设计是基于ARM v7的SIMD(Single Instruction Multiple Data)和矢量浮点计算VFP v3(Vector Floating-Point)指令集进行的,在不同的芯片设计中NEON组件是可选的。在多媒体处理领域,如音视频编解码器、图像处理和语音信号处理,以及通信领域,如基带信息处理,NEON处理器都有自己独特的优势。
NEON处理器是ARM Cortex A系列处理器的128位SIMD(单指令多数据)体系结构扩展,它具有32个64 bit位宽寄存器或者16个128 bit位宽寄存器,所有的寄存器都被视为具有相同数据类型的一个向量,支持多种数据类型,包括有符号和无符号数据类型,也包括单精度浮点数据类型。另外,NEON指令都是针对相同数据类型的通道处理的,即所有通道执行相同的指令操作。
图1是NEON寄存器的视图,16个128 bit的4 byte寄存器Q0~Q15,或者32个64 bit的双字寄存器D0~D31。注意NEON寄存器和ARM寄存器存在区别,但NEON会采用ARM的寄存器作为地址寄存器进行间接寻址。

图1 NEON寄存器视图
图2是NEON单个寄存器组的元素分配,表示了NEON可支持的操作类型数据。包括有符号或者无符号的8 bit、16 bit、32 bit和64 bit的整型数据(I8,S8,U8,I16,S16,U16,I32,S32,U32,I64,S64,U64)或者单精度浮点数据(F32)。
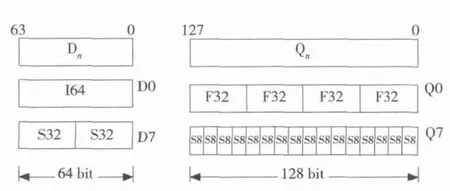
图2 NEON单个寄存器组的元素分配
NEON处理器同时支持内存非对齐访问和对齐访问,对齐访问的速度更快,可通过指定@bits来确定地址对齐的位数,如@32,@64,@128等。数据加载和存储支持交错打包方式,即支持有2、3、4个通道的交错数据加载和存储。除此之外,还能在标量和向量间进行数据的移动,但速度较慢。同时,NEON也支持单精度浮点的数据运算。
2 NEON编程优化方法
NEON编程优化方法通常包括如下几种手段:
1)编写汇编代码
最直接使用NEON的方式是编写NEON汇编代码。相对于其他的DSP编程语言,NEON的编写并不复杂。但要写出高质量的,能对性能有较大优化的汇编仍然具有一定难度。在对一个模块进行NEON汇编优化之前,需要先确保对模块的算法优化做到了最佳,特别是按照NEON的并行处理指令思路来改写模块,要将模块改写成使其尽量满足NEON的并行处理框架。完成了算法优化后,即可动手开始编写汇编代码。
和传统的Intel X86汇编、DSP汇编相同,NEON汇编也涉及到出栈入栈操作,这要求汇编代码编写者小心对待,以免因为入栈和出栈不一致导致程序运行错误。
2)采用内联函数(Intrinsic Function)
内联函数可以被C和C++的程序所调用,可自动进行类型检测和寄存器分配。内联函数在被编译器编译的时候,它会被转化为有序的NEON指令进行执行。简单的看,采用内联函数可以实现在高级语言(如C/C++)中直接使用低级语言(如NEON)的功能。内联函数最大的好处是程序员不用去接触汇编,可以减小优化的难度。但采用内联函数获得的优化效率没有直接使用汇编代码获得的优化效率高。
3)自动矢量化
ARM编译器可针对C/C++代码进行自动矢量化操作,这样做的一个好处就是程序员不需要编写汇编代码或者使用内联函数,即可实现NEON优化的效果。用C进行编程同时也保证了在不同平台上的兼容性。
在C语言的for循环内部使用自动矢量化技术可获得较好的性能优化结果。假设在执行循环体操作时,每次循环内部执行的操作相同,则可以采用自动矢量化技术,将多次循环的操作尽可能转换成一次操作完成。在一次操作中,有多个计算单元按照相同的操作步骤来完成多次循环执行。
4)使用第三方的NEON库(NEON Library)
ARM公司本身对常见的算法进行了NEON优化,并封装成Library。如针对多媒体跨平台API的OPENMAX[1],ARM 提供了针对 OPENAM 开发层(OPENMAX DEVELOPMENT LAYER)的优化实现。在开源代码社区,有不少开发者和感兴趣的人提供了很多基于NEON优化的library,这些Library覆盖了音视频编解码和数字信号处理的常见模块。一个著名的NEON代码优化社区是Project Ne10[2]。
3 H.265解码器NEON优化
本文采用开源的 OPENHEVC[3]作为 H.265[4]解码器进行优化。相对于H.265标准的参考实现HM[5],OPENHEVC解码器同样符合H.265标准的语法语义,其实现更为简练和高效。解码器主要模块包括熵解码、反量化、反变换、帧内预测、帧间运动补偿(MC)、去块效应环路滤波(Deblocking)和样本自适应偏移量滤波器(SAO)等。其解码器框图如图3所示。
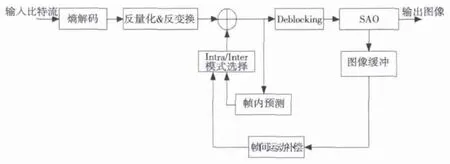
图3OPENHEVC解码基本框架
在OPENHEVC解码器中,由于熵解码模块的串行程度高,条件分支过多,不适合采用NEON进行优化,该模块可用ARM指令和Thumb指令代替NEON指令进行优化。对于其他模块,如整数反余弦变换(IDCT),MC和Deblocking等,模块算法中对于不同像素点的运算过程可以高度并行,并且运算步骤基本一致,适合采用NEON优化。因此对这部分进行了充分的NEON优化。由于优化的模块较多,这里仅以IDCT为例,来说明NEON优化的思路及具体实现。
H.265编码标准中对变换单元(Transform Unit,TU)通过使用整数正弦变换(DST)和整数余弦变换(DCT)将时空域信号转换为频域信号,再进行量化,达到压缩的目的。相应地,在H.265解码端,需要进行整数反正弦变换(IDST)和整数反余弦变换(IDCT)。
H.265指定了4种不同的TU块尺寸,分别为4×4,8×8,16×16和32×32。在帧内编码中,4×4亮度变换块采用DST进行整数变换,以此提高大约1%的压缩比[6]。除此之外,其他类型的变换块均统一采用IDCT进行处理。
以8×8 IDCT为例,描述如何采用NEON进行加速。

式中:X为8×8 TU块的数据;M为8×8 IDCT的系数变换矩阵;MT为M的转置矩阵;Z为8×8 IDCT的最终结果。M具体取值为


即首先得到IDCT的一维运算结果Y,然后将MT和Y做矩阵乘法得到IDCT的二维运算结果Z。
对IDCT的一维运算采用蝶形变换来进行算法优化,其实现框图如图4所示。
观察式(1),可将其变换成如下等式
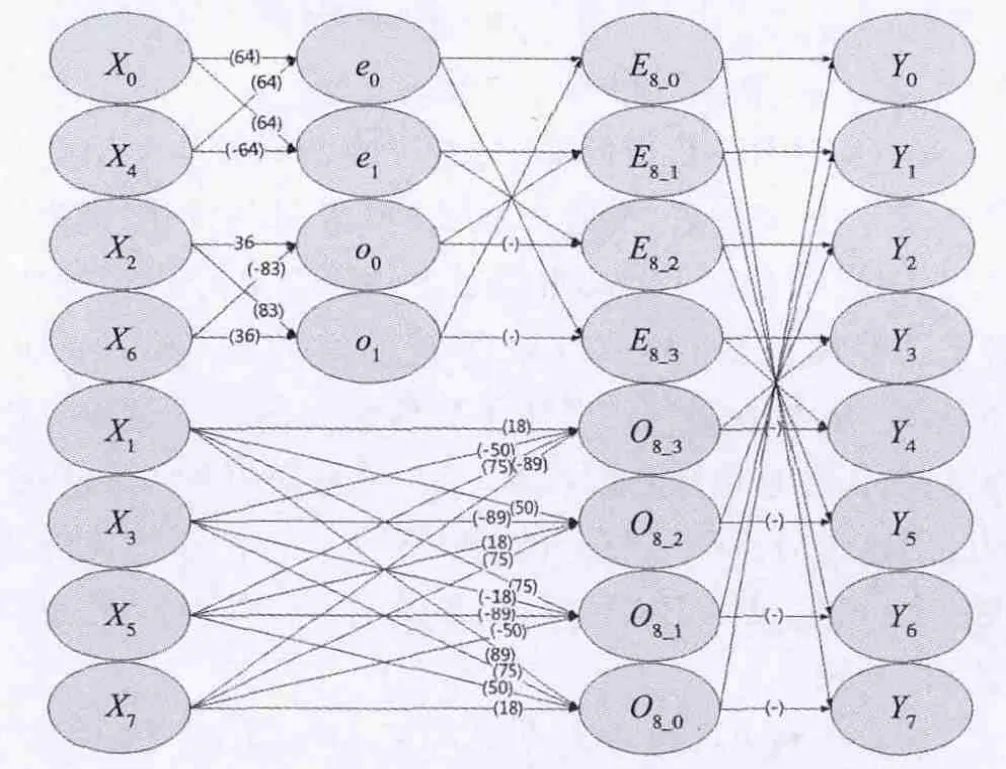
图4 H.265,8×8 IDCT 1-D蝶形运算示意图
图4中x0到x7表示8×8 TU块的同一列系数,x0表示该列的第一个系数,x7表示该列的最后一个系数。采用一维快速蝶形运算来实现IDCT算法,虽然从C代码层面上已经有效降低了计算复杂度,但每次运算都只针对矩阵中一列系数,对于8×8矩阵来说,需要对8列系数进行8次相同运算,才能完成整个一维快速蝶形运算。而采用NEON进行并行优化,可以将4次运算合并为1次,因此可极大提高运算速度。
基于IDCT的快速蝶形运算思路,采用NEON对IDCT进行优化的整体思路如下:
1)在8×8 IDCT实现中,TU块的系数采用16位无符号整数表示。充分利用NEON的128 bit位宽,可一次用2个连续的64位D寄存器(也可以用1个128位Q寄存器表示)保存TU块一行8个系数。
2)NEON支持最多4个16 bit整数同时进行乘累加,因此通过前面加载进来的8个系数,需要执行两次乘累加操作。由于8×8块左边4列和右边4列的操作完全一样,因此可以将8×8 TU块分为左右两个8×4子块,对子块采用快速蝶形运算得到8×4一维运算结果。
以左边8×4子块为例,详细描述快速蝶形运算的NEON实现步骤。
(1)将8×4 TU块的32个数据加载进D寄存器,后面的运算将不再从内存中读取数据。
(2)计算图4 中O8_0~O8_3。将M[1][8],M[3][8],M[5][8]和M[7][8]的值赋给 D 寄存器,为后面的乘累加操作做准备。
(3)对4个系数同时进行乘累加,得到O8_0。其示意图如图5a所示。同理可得到O8_1,O8_2和O8_3的结果。
(4)计算图4 中E8_0~E8_3。将M[1][8],M[3][8],M[5][8]和M[7][8]的值赋给 D 寄存器,为后面的乘累加操作做准备。
(5)如图5b所示,对4个系数同时进行乘累加,得到e0。同理得到e1。
(6)和步骤(5)类似,如图5c计算得到o0,o1。
(7)将e0,e1,o0和o1进行交叉相加减,得到E8_0~E8_3。
(8)最后对E8_0~E8_3,O8_0~O8_3进行交叉相加减,并最终经过移位操作后得到最终结果。
为方便NEON在做IDCT二维计算的时候,可以如一维计算一样,一次加载连续多个数据进入D寄存器,需要对IDCT一维输出结果进行转置。NEON中的VZIP指令可以帮助实现这样的操作。VZIP指令可交叉存取两个向量的元素。以VZIP.8为例,如图6所示,可将dn和dm两个寄存器每8 bit进行交叉存储。

图5 计算O8_0,e0和O0框图
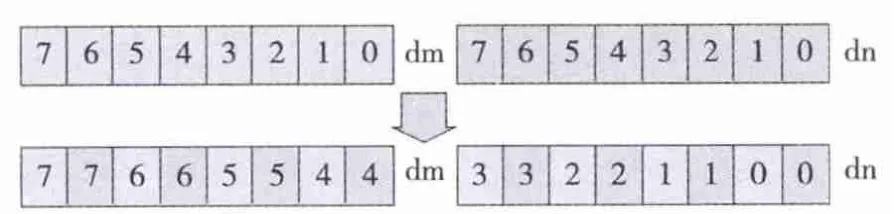
图6 VZIP.8 dn,dm示意图
二维运算过程和一维运算过程基本相似,这里不再叙述。二维运算的结果即最终的IDCT运算结果。
4 OPENHEVC解码器NEON优化结果测
本文采用了内置瑞芯微电子 RK3188处理器[7]的SDK开发板作为测试平台,其CPU为ARM Cortex A9四核,带NEON和VFP加速处理单元,CPU主频最高可运行至1.6 GHz。
软件平台采用Android 4.4操作系统,通过对H.265编码视频的解码帧率测试,来评估NEON优化代码的效率。本文采用了包括各种分辨率和码率的测试序列进行解码测试,优化效果随着分辨率上升愈显明显。具体优化结果如表1所示。

表1 OPENHEVC解码器整体优化效果对比
5 小结
ARM NEON技术广泛应用于多媒体优化中。NEON的SIMD架构使得其非常适合多媒体编解码器中的许多计算密集型模块。NEON在H.265解码器中的优化效果表明,采用NEON进行多媒体优化效果显著,能较好地提高多媒体应用的执行效率。
:
[1] The standard for media library portability[EB/OL].[2014-02-05].http://www.khronos.org/openmax/.
[2] An open optimized software library project for the ARM architecture[EB/OL].[2014-02-05].http://projectne10.github.io/Ne10/.
[3] OpenHEVC [EB/OL].[2014-02-05].https://github.com/Open-HEVC/openHEVC.
[4] ITU-T recommendation H.265 [EB/OL].[2014-02-05].http://download.csdn.net/download/sugufe/5593167.
[5] HEVC Test Model(HM)documentation[EB/OL].[2014-02-05].https://hevc.hhi.fraunhofer.de/HM-doc/.
[6] SAXENA A,FERNANDES F C.DCT/DST-based transform coding for intra prediction in image/video coding[J].IEEE Trans.Image Processing,2013,22(10):1685-1688.
[7] RK31 Series[EB/OL].[2014-02-05].http://www.rock-chips.com/a/en/products/RK31_Series/2013/0808/314.html.
猜你喜欢
光通信研究(2022年2期)2022-03-29
有色金属设计(2022年4期)2022-02-04
小学生必读(低年级版)(2021年10期)2022-01-18
苏州科技大学学报(工程技术版)(2021年2期)2021-07-02
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
计算机应用(2020年5期)2020-06-07
家庭影院技术(2019年8期)2019-12-04
装备制造技术(2013年6期)2013-06-26
网络安全与数据管理(2011年24期)2011-08-08
