
面向大规模告警数据的高性能信息筛选系统
2014-12-23 01:31郑哲渊
计算机工程与设计 2014年2期
郑哲渊,刘 渊
(江南大学 数字媒体学院,江苏 无锡214000)
0 引 言
入侵检测技术[1](IDS)是一种对入侵行为进行检测的技术,是包括技术、人、工具3 方面因素的一个整体。但人们大多为了追求IDS的低漏报率,都以牺牲其效率作为代价,这在大规模大数据量的网络环境中,无疑是不可取的。所以,研究如何从大规模告警数据中筛选出有用的入侵信息,是当前的关键问题。相关研究工作如下:
文献 [2]介绍了TACC组件,该组件的中心思想是对告警数据中的某一属性相同的告警的归并操作,从而降低了告警的数量,但是对于冗余信息的 “误报”问题,却没有得到解决;文献 [3]在TACC组件的基础上,加入了因果关系的关联方法,介绍TIAA,其基本思想是每个攻击都有前后关联,需要分别建立攻击的前奏和后续知识库,通过告警匹配的方法完成关联,此方法的缺陷是需要大量攻击的先验知识,这就限制了其可扩展性和实时性;文献[4]介绍了WINEP,其思想是采用短频繁集递归产生长频繁集的方式,取得了不错的效果,但是忽略了告警的 “正常”行为模式,使得结果会出现偏差;文献 [5]提出了A3PC系统,该系统能较好的滤除冗余信息,但是在大规模数据下,其核心算法Apriori[6]由于要多次扫描数据库,会使得系统的性能急剧下降,难以适应信息筛选的实时性要求。
鉴于当前信息筛选方法难以满足面向大规模数据的实时性处理需求,本文提出面向大规模告警数据的快速筛选系统 (rapid screening system for large-scale alarm data,RSS),能快速有效的筛选出有用信息,并为网络管理者提供宏观的视图展示。为提升系统性能,本文重点研究高性能数据挖掘算法[7]。
1 面向大规模告警数据的快速筛选系统
经研究表明,根原因 (root cause)会使得IDS产生大量的告警,并且由于根原因的稳定性,大量重复性的告警信息会不断的产生,直至相应的根原因被移除。然而,根原因都是由于用户或者系统的正常行为产生的,因此产生的告警都可以看成是IDS的误报。由此,可以得出如下结论:少量的根原因产生绝大部分告警;无论真实攻击存在与否,告警的产生都有一定的周期性和趋势性。因此,假设A 为全部告警信息,则存在A 的一个子集A`,即使在没有真实攻击的情况下,也会频繁或周期性的出现,这部分告警就能看成是由根原因产生的,因此能认为是告警的“正常”行为模式,相对的, (A-A`)部分的告警能认为是“异常”行为模式。这些 “异常”行为模式是网络安全管理者需要关注的重点,为此本文研究如何从全部告警信息提取出少量的不定期出现的具有 “异常”行为模式的那部分告警,以提升提高IDS的效率,并降低其误报率。
本文提出的面向大规模告警数据的快速筛选系统(RSS系统)框架如图1所示。该系统位于IDS的后端,主要目的是从大规模IDS告警信息中快速有效的筛选出有用的告警信息,提升系统的时效性。系统主要由3部分组成:预处理模块、实时处理模块和输出模块。

图1 RSS模型框架
1.1 预处理模块
Snort[8]是目前运用最广泛的IDS系统之一,本系统也是基于Snort进行的研究。本系统预处理模块位于Snort的告警输出端,对告警数据进行预处理。
(1)Snort产生的告警数据库包含Shcema、Sensor、Event、Signature等15张表,每张表中又有若干告警属性,而其中有些属性对于告警的后续处理用处不大,若是全部作为RSS的输入,会增加系统的开销。基于以上考虑,预处理模块对原始告警属性进行精简,选取其中一部分属性进行研究。本文提取了组号、组内编号、告警大类信息、rules种类、源地址、目的地址、源端口、目的端口、时间、协议等10 个属性的属性集,对原始告警进行归一化处理。
(2)当用户在短期内进行某些重复操作或是遭受拒绝服务攻击等情况时,Snort会在段时间内产生大量告警,这些告警的共同特征是除了组内编号和时间这两个属性不同之外,其他各属性均相同,这样的告警数据集合可看成是“同一”告警。当这种告警数据大量出现时,就会增大告警数据库的规模。为了解决此问题,预处理模块在告警属性集中增加一个告警条数属性,用于表征在一个短时间段内的 “同一”告警的条数,这样就将 “同一”告警合并成一条,减小数据库规模。
1.2 实时处理模块
实时处理模块位于预处理模块后,是对告警数据的进一步处理。该模块分为两个部分:快速筛选 (rapid screening,RS)子 模 块 和 实 时 在 线 聚 类 分 析 (real-time online clustering analysis,ROCA)子模块。
RS是通过高性能数据挖掘算法,利用告警数据集挖掘得到若干关联规则,然后依据这些规则对后续的告警进行筛选,得到我们需要的具有 “异常”行为模式的告警。现在常见的数 据挖掘 算法有Apriori、FP-Growth[9]、COFITree[10]等。此外,考虑到告警数据流具有实时性,系统定义了关联规则的有效时间,并对数据流进行实时抽样。当规则失效时,对抽样得到的小数据集进行挖掘,产生新的规则,以保证关联规则的有效性。
ROCA 模块布置在RS模块之后,对筛选出来的告警数据进行深入分析,以挖掘其内在联系。根据告警数据流的实时性、连续性和顺序性等特性,ROCA 使用了实时在线数据流增量聚类方法LOCALSEARCH[11],使得聚类形态能实时的反映出数据流的变化情况。
1.3 输出模块
实时处理模块最终得到各个聚类的结果,输出模块的目的是将这些抽象的聚类结果转换成精简的视图,方便网络管理者观察。每一个聚类代表一种可能的攻击,该模块任务就是根据该聚类的特征,如告警个数、告警属性等,与攻击特征库进行比对,并得到该聚类属于各种攻击的可能性 (百分比)。输出模块将结果用饼状图显示,让管理人员直观看到每个聚类可能存在的攻击类型,并将每次的结果存入结果数据库,与最近两次的结果集做比较,按照攻击种类连续出现的次数将其威胁指数分别定为一级、二级和三级 (三级最高)。按威胁指数从高到低的排序方式将攻击类型用表格形式列出,以便管理人员优先处理威胁指数高的攻击类型。
RSS是针对IDS系统的低漏报率和系统效率之间的矛盾,对IDS告警数据进行快速筛选,挖掘其内在联系,从大规模告警数据中得到有用的信息。该系统考虑到告警数据的实时性,加入了时间有效性;并运用实时的在线聚类分析方法,周期性的挖掘数据间的联系,确保聚类结果能正确反映当前告警数据的特征。RSS系统的开销主要集中在数据筛选的部分,因此数据挖掘算法的性能也就直接决定了系统的整体性能。在大规模告警数据的环境下,数据挖掘算法的性能显得非常关键,下面将围绕与RSS有关的数据挖掘算法进行分析研究。
2 若干数据挖掘算法比较
由于告警数据的大规模性和实时性,系统在选取数据挖掘算法时必须在其时间复杂度和空间复杂度等性能上做综合评判。本节就对几种主流的数据挖掘算法进行分析比较,并从中选出适合本系统的算法。
2.1 Apriori算法
Apriori算法由Agrawal R.等在1994年提出,使用逐层搜索的迭代方法找出最大频繁项集。其算法的基本构造:
(1)遍历所有数据集中的项,找出所有满足最小支持度 (minsup)的项,组成1-项频繁集。
(2)从第2步开始,循环处理直到没有新的最大项集生成。循环过程:第K 步中,根据K-1步中生成的K-1维最大项集按照自连接的方式产生K 维候选项集,然后遍历D中每个事务,得到各个项的支持度,找出支持度大于minsup的项,组成K 维频繁项集。
(3)由最小置信度,在最大频繁集中筛选出关联规则。
显而易见,该算法在实际应用中存在两个方面的不足:首先,在每次生成候选项集时,都需要遍历整个数据集,当最大项集的维数较高时,算法的时间开销会严重增加;其次,当候选项集的规模很大时,会增加其空间开销。
2.2 FP-Growth算法
FP-Growth算法是J.Han等人提出的一种不产生候选集频繁项集生成算法,称为频繁模式增长 (Frequent-Pattern Growth)。FP-Growth算法采用频繁模式树 (FP-Tree)储存数据集的信息,最大限度的压缩了数据集并保证了数据的完整性,然后通过对FP-Tree的一次遍历,得到最大频繁集。
算法主要分为两部分:生成频繁模式树 (FP-Tree)和模式增长算法。
2.2.1 构建FP-Tree
输入:数据集 (D)和最小支持度 (minsup)。
输出:FP-Tree。
方法:
(1)遍历D,根据minsup得到1-项频繁集。
(2)再次遍历D,将D 中的每个事务 (T)都与1-项频繁集进行比较,选出T 中属于1-项频繁集中的项并按升序排列,得到项集L。将L 中的项与FP-Tree中的节点元素比较,若相等,则节点的支持度加1;若不相等,则将该项插入FP-Tree中,并将其支持度置1。如此重复,直至遍历完整个D,得到完整的FP-Tree。
2.2.2 模式增长
其主要算法思想如下:
输入:生成的FP-Tree,最小支持度阈值minsup。
输出:最大频繁集。
方法:调用FP-Growth (Tree,a)

可见,此算法只需两次遍历数据集,但是需要不断的递归寻找短模式,然后连接其后缀,最终得到最大频繁集。
2.3 COFI-Tree算法
COFI-Tree算法同样基于FP-Tree,并为1-项频繁集中的每个项都创建一个COFI-Tree,具体算法思想如下:
输入:FP-Tree,1-项频繁集。
输出:最大频繁集。
方法:
(1)for 1-项频繁集中的每个项xido{
(2) 根据指针找到FP-Tree中的所有xi所在位置,并以它为底自底向上搜索这一支上的所有节点,同一支上所有节点的支持度与该支中的xi的支持度一致。然后构造xi的COFI-Tree,根据minsup得到的结果放入最大频繁集候选集}
(3)对最大频繁集候选集进行查看,若有存在包含关系的项,就进行合并,获得最大频繁集。
该算法的特点是某一时间在内存中只有一个COFITree,这样占用内存空间较小,使得算法运行速度快。
2.4 算法性能比较
本文从空间复杂度和时间复杂度这两个方面对以上3个算法进行分析。
从时间复杂度的角度,主要看算法遍历数据集的次数。设1-项频繁集中项的个数为L1,数据集事务个数为S,首先,Apriori算法中,需要构造候选项集,对候选项集中的每一项都遍历数据集,其中K 维候选项集的项个数CK可用 (LK-1-1)LK-1/2大致表示。为了结果表示方便,用C表示候选项集的平均数,当最大频繁集的维数为M,则Apriori算法的时间复杂度可表示为O(M*C*N)。其次,FP-Growth和COFI-Tree算法都只需要遍历数据集两遍,所以它们的时间复杂度可看成是一致的,都是O(N*L1)。
从空间复杂度的角度,首先给出空间复杂度的定义:空间复杂度是对一个算法在运行过程中临时占用存储空间大小的量度。Apriori算法每次只处理一个事务,所以空间复杂度记为O(1)。FP-Growth 需要要递归建立条件FPTree,要用到临时堆栈存储数据,其空间复杂度记为O(N)。COFI-Tree同一时间在内存中只需要建立一棵COFITree,所以空间复杂度是O(1)。
由表1,从时间复杂度来看,FP-Growth和COFI-Tree算法至少要比Apriori算法低一个数量级;从空间复杂度来看,FP-Growth要比其他两种算法高。因此,相比之下,COFI-Tree算法在综合性能方面要优于其他两种算法。

表1 数据挖掘算法的复杂度比较
3 实验验证与分析
3.1 实验环境
为了验证不同算法运用于RSS上的性能差异,本文在CentOS 5.3 上 进 行 测 试,测 试 环 境 为DELL 服 务 器(CPU:E5520 2.27GHz*16,内存:8G)。本实验使用的是MIT Lincoln实验室开发的DARPA 1999年IDS测试数据集,该数据集包含了5周的测试数据,其中包括不含任何攻击的正常数据和包含多种攻击类型的攻击数据。这也使得实验环境更贴近实际的网络环境,所以也保证了测试结果的正确性。
利用Snort 的默认规则分别对这五周的outside.tcpdump测试文件进行检测,得到相应的告警数据集,并在不同告警数的情况下在RSS中分别使用Apriori算法和COFI-Tree算法进行测试,并从时间、CPU 利用率、内存占用率等方面对系统性能进行测试。
3.2 实验结果分析
本实验运用了前二周、前三周和前五周的outside.tcpdump产生告警 数据集,分别得到2.5 万、13.8 万和16.2万的告警数据。图2、表2和表3分别是当告警数不同情况下Apriori算法和COFI-Tree算法对CPU 的占用率、系统时间的开销和系统内存消耗的对比。
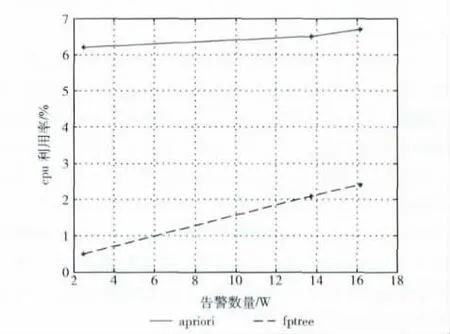
图2 CPU 占用率比较
由图2可看出,COFI-Tree算法在计算时CPU 的占用率明显比Apriori算法低很多。
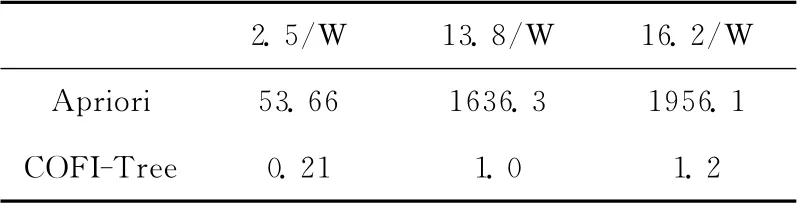
表2 时间开销比较

表3 内存开销比较
表2和表3分别从时间和空间开销将两算法进行了对比,结果显而易见,COFI-Tree在时间开销上远比Apriori算法要少,且随着告警数量的增加基本维持在1 秒左右,而Apriori算法随告警数量的增加时间的开销也随之增加,且涨幅很大,最后已经接近2000 秒;空间开销方面,COFI-Tree算法的优势也是很明显。
表4为两种算法在不同告警数量的情况下得到的最大频繁项集,括号内的是项的支持度。比较后可得出,使用Apriori算法和COFI-Tree算法的结果近似完全一致。

表4 最大频繁集比较
由上分析可得,无论是从CPU 占用率、时间开销还是空间开销的角度,COFI-Tree算法都比Apriori算法有着明显的改进,且最后得到的最大项集基本一致。由此,充分说明了基于COFI-Tree算法的RSS系统具有高性能。
4 结束语
本文提出了一种位于IDS后端的通用系统RSS,主要是对告警数据进行筛选并挖掘出其内部联系,最后利用精简的视图展现结果。相对于以往的IDS系统为了降低漏报率而牺牲效率的做法,本系统在保证了IDS的低漏报率的情况下,对系统的效率进行提高。同时,从时间和空间复杂度这两个方面分析了几种数据挖掘算法性能上的差异,从理论上证实了COFI-Tree的优越性。并且结合现在大规模告警数据的环境,分别将Apriori算法和COFI-Tree算法用于本系统,在两者实验结果基本相同的情况下,使用COFI-Tree的系统在时间开销和空间开销上都有明显改善。
[1]CAI Hongmin,WU Naiqi,CHEN Su,et al.Research and implement of distributed intrusion detection system [J].Computer Engineering and Design,2009,30(6):1383-1386 (in Chinese).[蔡洪民,伍乃骐,陈素,等.分布式入侵检测系统的研究与实现[J].计算机工程与设计,2009,30(6):1383-1386.]
[2]Alexander Hofmann,Bernhard Sick.Online intrusion alert aggregation with generative data stream modeling [J].IEEE Transactions on Dependable and Secure Computing,2011,8(2):282-294.
[3]Ganapathi Reddy K L,Srinivas K.GDS-an efficient approach for online intrusion alert aggregation [J].International Journal of Computer Application,2012,2 (1):131-139.
[4]Kimmo H¨at¨onen.Data mining for telecommunications network log analysis [M].Department of Computer Science Series of Publications,2009.
[5]TIAN Zhihong,ZHANG Yongzheng,ZHANG Weizhe,et al.An adaptive alert correlation method based on pattern mining and clustering analysis[J].Journal of Computer Research and Development,2009,46 (8):1304-1315 (in Chinese).[田志宏,张永铮,张伟哲,等.基于模式挖掘和聚类分析的自适应告警 关 联 [J]. 计 算 机 研 究 与 发 展,2009,46 (8):1304-1315.]
[6]CUI Guanxun,LI Liang.Research and improvement on Apriori algorithm of association rule mining[J].Journal of Computer Applications,2010,30 (11):2952-2955 (in Chinese).[崔贯勋,李梁.关联规则挖掘中Apriori算法的研究与改进 [J].计算机应用,2010,30 (11):2952-2955.]
[7]WANG Aiping,WANG Zhanfeng.Common algorithms of association rules mining in data mining [J].Computer Technology and Development,2010,20 (4):105-108 (in Chinese). [王爱平,王占凤.数据挖掘中常用关联规则挖掘算法 [J].计算机技术与发展,2010,20 (4):105-108.]
[8]Go'mez J,Gil C,Padilla N,et al.Design of a snort-based hybrid intrusion detection system [C]//Proceedings of the 10th International Work-Conference on Artificial Neural Networks,2009:515-522.
[9]Wang Lei,Fan Xingjuan.Mining data association based on a revised FP-growth algorithm [C]//IEEE Conference Publications,2012:91-95.
[10]Virendra Kumar Shrivastava,Dr Parveen Kumar.FP-tree and COFI based approach for mining of multiple level association rules in large databases[J].International Journal of Computer Science and Information Security,2010,7 (2):273-279.
[11]Wu Ou,Hu Weiming.Efficient clustering aggregation based on data fragments[J].IEEE Transaction on Systems Man and Cybernetics Part B-Cybernetics,2012,42 (3):913-926.
猜你喜欢
高技术通讯(2021年3期)2021-06-09
中国惯性技术学报(2019年6期)2019-03-04
天津科技大学学报(2018年4期)2018-08-22
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
北京航空航天大学学报(2017年12期)2017-04-23
火控雷达技术(2016年3期)2016-02-06
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
铁路通信信号工程技术(2014年5期)2014-02-28
网络安全与数据管理(2010年1期)2010-05-18
浙江师范大学学报(自然科学版)(2010年2期)2010-01-11
