
顾及结果完整性的遥感影像分布式边缘提取方法
2014-12-23 01:26程付超
计算机工程与设计 2014年2期
程付超,苗 放,2,陈 垦
(1.成都理工大学 地球探测与信息技术教育部重点实验室,四川 成都610059;2.成都理工大学 地质灾害防治与地质环境保护国家重点实验室,四川 成都610059)
0 引 言
目前,对于海量遥感影像的边缘提取,通常采用的方法是 通 过MPI (message passing interface)进 行 并 行 编程[1],实现基于集群的边缘提取并行处理。但是,由于MPI环境的构建和编程难度较大,限制了其发展和应用。Hadoop MapReduce计算模型具有较好的易用性,但其本身并不支持影像数据的计算与处理,需要对影像数据集的划分方法及其相关接口进行设计和实现[2]。现有基于Hadoop的遥感影像分布式计算方法中,数据集划分缺乏对影像数据特征的充分考虑[3-5],往往采用单层平均分割[6],直接将影像数据按照固定粒度分为多个影像块,某些影像特征被分割到多个影像块中,造成影像特征丢失,影响计算结果的完整性。
为了解决这个问题,需要引入遥感影像组织技术作为分布式计算的数据集划分算法。但现有技术中,剖分影像金字塔[7]主要针对影像的显示和存储进行设计,采用四叉树分割,影像层级较多,不适用于分布式计算;广义影像金字塔[8]主要面向云存储进行设计,生成算法较为复杂,也不完全适用于分布式边缘提取计算;文献 [9]中提出一种并行处理机制,需要在数据预处理阶段对提取的目标对象的最小矩形进行计算,其实质上还是一种单层分割,仍存在特征丢失问题;其它一些遥感影像组织方式,如球面剖分模型[10]和文献 [11]中提到的分布式遥感影像组织方法都具有类似的问题;而且,上述方法都需要在计算前将数据分块单独储存并进行分发,数据迁移量较大,不符合目前大数据计算中 “计算推向数据”[12]的思想。
针对现有计算方法在数据集划分方法上存在的不足,本文提出了一种多层冗余的遥感影像数据集剖分模型——弹性影像金字塔 (resilient image pyramid,RIP),该模型按照预设的分辨率倍率将原始影像划分为多个影像层级,并对每层影像数据按照一定的粒度进行正方形剖分,将其划分为多个影像分区 (Region),从而将原始影像数据划分为多层冗余的组织结构,保证原始影像特征的完整性。同时,RIP通过原始像素坐标对影像分区进行索引,将影像金字塔以关键元数据的形式存储,减少了计算中的数据迁移量。
在RIP基础上,根据相关项目中海量遥感影像边缘提取的实际需求,本文设计并实现了一种适用于海量遥感影像边缘提取的MapReduce计算方法,将影像数据封装为Key-Value格式,通过Hadoop把计算任务和RIP的关键元数据分发到具有相应资源的计算节点上,各节点按照关键元数据生成影像分区并进行边缘提取,最后采用一种面向空间面实体的简单密度聚类算法实现冗余结果的归并。在实验分析中,采用本文计算方法对多幅嫦娥影像进行了月坑提取,提取率相比使用现有方法分别提升了12.25%、9.29%和20.14%,而增加的时耗始终维持在5%以下。
1 弹性影像金字塔
弹性影像金字塔 (RIP)是一种面向MapReduce计算的多分辨率层次影像模型,其影像层级结构是弹性可调整的,可以灵活的控制影像分层策略,实现影像金字塔的按需构建。
1.1 弹性影像金字塔的构建
在弹性影像金字塔中,会按照预设的分辨率倍率将原始影像划分为多个影像层级,并对每层影像数据按照一定的粒度进行正方形剖分,从而将原始影像数据划分为多个影像分区 (Region)。构建RIP的关键在于其分层策略和分区方法,如图1所示。1.1.1 RIP的分层策略
分层策略用于确定RIP 的层级数量和每一层数据的像素大小。构建RIP首先需要对分辨率倍率进行设定,并按照倍率对原始影像进行多次重采样,从而形成多个分辨率层次的影像金字塔结构。从金字塔的底层开始,影像分辨率逐层降低,数据量也逐层减少,当某层影像的数据量小于等于一个影像分区粒度时,则结束分层,具体算法如下。

图1 弹性影像金字塔的结构
算法1:(RIP分层算法)
(1)设定相邻影像间的分辨率倍率T

其中,ResH为相邻两层影像中的较高分辨率,ResL为较低分辨率,因此T 应该大于等于1。
(2)使用原始影像数据作为金字塔第0层数据,令其像素大小为WO·HO。
(3)计算第L 层 (L>0)的影像的分辨率倍率TL

(4)计算第L 层影像的像素大小WL·HL

(5)计算第L 层影像的数据量QL

式中:DC——影像的色深。
(6)若第L 层影像数据量QL大于一个影像分区粒度,返回第 (2)步,计算第L+1层;否则,终止分层,金字塔层级数量为L。
1.1.2 影像的分区方法
影像的分区方法主要用于确定金字塔某一层的影像分区数量。在对一层影像数据进行分区时,需要考虑计算效率和I/O 效率两方面因素:①在MapReduce计算中,为了提高计算效率,需要减少影像分区数量;②另一方面,由于计算的输入数据和结果数据等都需要通过HDFS进行存储,影像分区大小还应该与HDFS的数据分片方式相兼容。因此,在RIP中采用了基于大粒度的影像分区方式,分区粒度默认为64MB,还可扩展到128MB 或更大粒度。令分区粒度为QR,影像色深为DC,设影像分区的像素宽度为SR,则影像分区的像素大小为S2R

在剖分过程中,如果存在不足S2R像素的 “尾块”,应对其进行补足。
1.2 影像分区的索引及存储方法
1.2.1 基于原始像素坐标的影像分区索引方法
传统的影像金字塔模型一般采用可递归的空间填充曲线对影像分块进行编码,其目的是为了提高空间检索效率。在分布式特征提取计算中,每个影像分区是被独立计算的,关注点集中在不同层级影像分区的重叠和冗余问题。因此,本文采用了一种基于原始影像像素坐标的影像分区索引方法。RIP中的影像层是原始影像通过一定的降采样处理后形成的,各影像层中的像素能够按照一定的算法映射到原始影像的对应像素上。对原始影像的像素坐标描述形式进行约定后,即可以用来描述来自不同层次的影像分区的幅面范围,从而判断各影像分区的重叠和冗余情况,为MapReduce计算中的结果归并提供依据。
RIP中约定原始像素的左上点为坐标原点,各影像分区坐标可通过数组RID进行描述
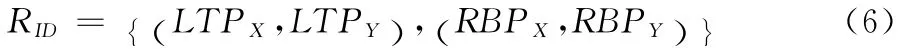
其中,(LTPX,LTPY)和 (RBPX,RBPY)分别表示分区左上点和右下点对应于原始影像的像素坐标,如图2所示。第L 层影像的分区坐标计算方法如下
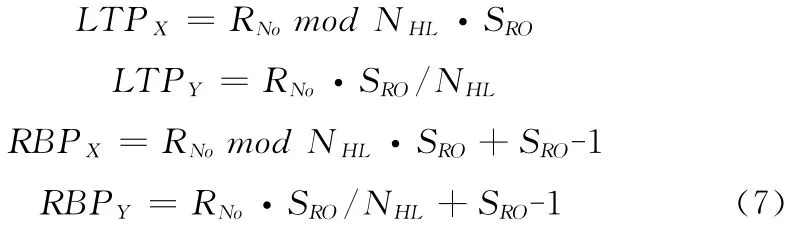
其中,RNo是影像分区在该层影像中的序号,按照行扫描的方法进行计算。NHL是第L 层影像中横向的影像分区个数。令该层影像像素大小为WL·HL,则

SRO是第L 层影像分区对应的原始影像区域的像素宽度

由于RIP中不可能存在内容完全相同的两个影像分区,因此可以采用RID作为影像分区的唯一标识符。同时,通过对比不同影像分区的LTPX、LTPY、RBPX和RBPY数值,可以较快的确定分区间的相交和重叠关系。
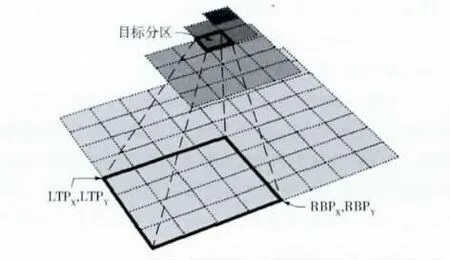
图2 像素坐标的映射
1.2.2 基于关键元数据的影像分区存储方法
RIP并不对每个影像分区的数据内容进行单独存储,而只存储构建RIP所必须的关键元数据。在进行分布式计算的时候,计算任务和元数据被分发到存储有相应资源数据的节点上,计算节点可以通过元数据较快速的生成所需的影像分区数据,从而减少了数据传输过程中的网络带宽、流量和时空开销。构建RIP的关键元数据包括基础元数据、层级元数据和分区元数据3类,见表1。

表1 构建RIP的关键元数据
2 边缘提取MapReduce计算方法
2.1 面向影像分区的Key-Value封装
遥感影像是一种非结构化数据,不能像结构化数据那样直接转化成Key-Value格式。本文采用的方法是以RIP中的一个影像分区为一个Value,并以影像分区的RID值为Key,建立Key-Value映射关系。对于计算的中间结果,同样按照这种思路进行处理,也使用RID作为Key,将其封装为Key-Value格式。这种方法的优点在于,每个Value都有且只有一个与之对应的Key值,能够确保输入数据和中间结果数据在整个计算过程中都是可标识的。同时,一个Key-Value就是一个完整的输入数据块,简化了计算中的Map过程。
2.2 基于RIP的影像边缘提取
基于RIP 的影像边缘提取主要包括数据集划分(Splite)、分布式处理 (Process)和结果归并 (Cluster)这3个过程,具体步骤及其与Hadoop MapReduce框架的关系如图3所示。
(1)数据集分割。按照RIP的构建方式,对原始影像数据进行分割,计算其关键元数据,并将计算任务和RIP的关键元数据以XML格式提交给Hadoop中的JobTracker。

图3 基于RIP的影像边缘提取方法
(2)分布式处理。JobTracker将计算任务和相关影像分区元数据分发给各个TaskTracker;Task-Tracker根据元数据去HDFS中实时获取影像分区,并按照用户编写的算法对其进行边缘提取处理;处理后得到的中间结果被缓存到本地,作为输入数据提供给后续归并计算使用。
(3)结果归并。通过RID可以判断各层级不同影像分区之间的重叠关系,从而将中间结果分为多个可能存在冗余的结果集,对同一结果集内的数据进行聚类分析,发现冗余结果并将之删除。
2.3 面向空间面实体的简单密度聚类算法
对于重复的中间结果,本文采用了一种较为简单的算法进行聚类分析,即以中间结果中空间面实体的几何形心距离和面积差值为距离度量,采用DBSCAN 算法进行密度聚类。
(1)距离度量
1)几何形心距离

其中,cA和cB分别为空间面实体A 和B 的形心坐标,该坐标是将提取出的空间面实体映射到原始影像相应位置后计算出的像素坐标。几何形心距离通过不同空间面实体形心坐标的像素偏移量进行衡量。
2)面积差值距离
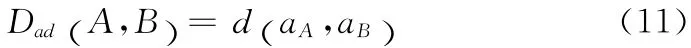
其中,aA和aB为空间面实体A 和B 的像素面积,该面积值同样是映射到原始影像上计算的,以保证不同层级结果的面积单位是一致的。面积差值距离通过不同实体间面积的像素差值来进行衡量。
(2)输入输出
输入包含n个空间面实体的数据集,几何形心距离邻近域半径ec,面积差值距离邻近域半径ead,核心实体邻近域内 (同时满足ec和ead)的最少实体数目MinPts;输出k个满足密度条件的空间面实体簇。
(3)算法流程
算法2:(面向空间面实体的简单密度聚类算法,其流程如图4所示。)
3 实验分析

图4 密度聚类算法流程
本文在CentOS 6.2环境下使用Java语言开发了一个验证系统,使用的Hadoop版本为0.20.205,部署在一个控制节点,3个计算节点的实验集群上,节点之间通过千兆网卡连接。实验所用的服务器主要参数指标为:Intel Xeon E3-1230 3.2GHz、内存8GB DDR3、硬盘1TB SATA。实验过程中采用基于Sobel算子的圆形构造提取算法,在月球遥感影像上进行撞击坑提取,该算法在月球中高纬度地区的提取准确率能够达到78%~80%。本文实验分为参数优化实验和性能分析实验,前者通过小数据量实验,与单机处理结果对比,优化本文方法中的各参数取值;后者采用大数据量的实验数据,与现有的影像单层分割的分布式边缘提取方法进行对比,分析本文方法的效果和性能。
3.1 参数优化实验
在RIP的构建和分布式边缘提取中,对处理结果存在较大影响的参数有4个,见表2。本实验首先以单台服务器进行月坑提取,并以此结果为依据,设计对照组实验,对各参数进行优化。实验数据选用嫦娥一号月球影像数据,影像范围-14°44′26.16″~29°43′35.79″N,-27°14′24.25″~16°55′21.83″E,数据量约700M,如图5 (a)所示。

表2 待优化参数
经实际测试,采用单台服务器提取得到月坑数量为139217个。为了模拟实际应用中高分辨率影像数据量大,影像分区较多的情况,对照实验中将影像分区粒度设为1M,以保证参数优化的准确性。

图5 实验数据
3.1.1 对照实验一——RIP分层策略实验
本实验针对构建RIP时参数T 的选择问题,在其余参数取默认值的情况下,测试不同的T 值对提取结果的影响,实验结果见表3。可以看出,随着T 取值的增加,处理时耗呈降低的趋势,这是由于需要处理的数据量逐渐减少。本实验中提取效果受其余参数的影响,提取率与单机提取还有较大差距,但从总体趋势上看,T 取值 [2,5]区间的提取效果较佳。综合性能和效果两方面因素,T 较佳的取值区间是 [4,5]。
3.1.2 对照实验二——聚类算法实验
本实验针对结果聚类中相关参数的取值问题,保持T取值5,实验不同参数组合对提取结果的影响,结果见表4,具体分析如下:
(1)从序号为1、2、3、4的列可以看出,当ec取值过小时,会遗漏部分冗余结果,造成提取的月坑数量过多;当ec值过大时,又会将部分位置较为接近的月坑误判为冗余结果,造成输出数据减少。从结果看,ec较为合适的取值大小为20左右。
(2)从1、5、6、7、8列可以看到,ead取值对结果的影像变化趋势与ec类似,取值过小,输出增加,取值过大,输出减少,较为合适的ead值为50左右。
(3)从7、9、10这3列看,MinPts取值1较为合适,原因在于实验中T 值为5,各层影像间的分辨率差别较大,某些中小型月坑只能在两到三层影像中提取到,无法满足MinPts条件,导致冗余结果未被处理。
从两次对照实验的结果可以看出,本文所述的分布式边缘提取处理方法在采用T=5,ec=20,ead=50,MinPts=1的参数设置时,提取效果与单机实验结果较为接近。

表3 RIP分层策略实验结果

表4 聚类算法实验结果
3.2 性能分析实验
本实验分别采用基于RIP 的影像边缘提取方法与现有基于单层分割的方法进行对比测试,分析本文方法在保障结果完整性方面的效果。实验数据采用嫦娥二号月球影像数据,为了测试在不同复杂度影像状态下本文方法的表现,选取了3块数据进行实验,如图5 (b)-(d),经纬度范围见表5。
实验中,各参数按照优化结果进行设置,影像分区粒度设为64M。为了减少提取算法本身的误差,本实验只对原始影像中直径大于143像素 (约等于1000米)的撞击坑进行统计。实验结果见表6,虽然提取算法的不稳定性导致提取结果出现了一定的波动,但从均值可以看出由于影像复杂程度不同,结果也有所不同。在3次实验中,与现有方法相比,采用本文方法进行月坑提取使结果数量得到了不同程度的提升,分别为12.25%、9.29%和20.14%,而增加的时耗始终维持在5%以下。这一结果表明,本文方法由于采用了RIP进行数据集划分,对于在分布式边缘提取计算中提高结果集完整性具有较好的效果。

表5 性能分析实验数据
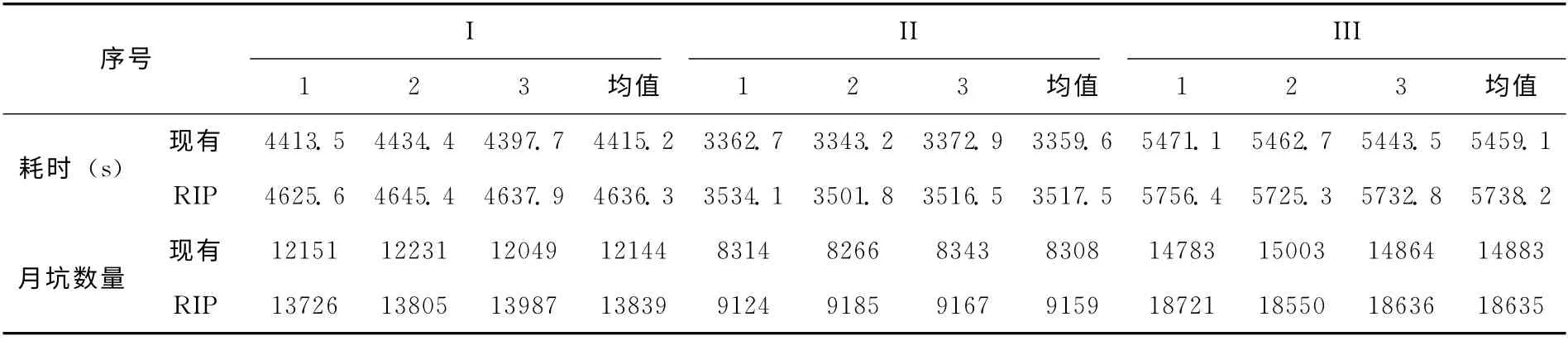
表6 性能分析实验结果
4 结束语
本文针对现有计算框架在数据集划分方法上存在的不足,重点论述了RIP 的构建、索引和存储,提出并实现了一种面向海量遥感影像的边缘提取MapReduce计算方法。实验分析结果表明,采用本文计算方法进行遥感影像分布式边缘提取,相比使用传统平均分割数据集的方法,在不同影像复杂度的提取率分别提升了12.25%、9.29%和20.14%,而增加的时耗始终维持在5%以下。下一步的研究将集中在如何对RIP及其分布式计算方法中的相关参数进行更进一步地优化,并将其推广到遥感影像处理的其它领域。
[1]SHEN Zhanfeng,LUO Jiancheng,CHEN Qiuxiao,et al.High-efficiency remotely sensed image parallel processing method study based on MPI[J].Journal of Image and Graphics,2007,12 (12):2132-2136 (in Chinese).[沈占锋,骆剑承,陈秋晓,等.基于MPI的遥感影像高效能并行处理方法研究[J].中国图象图形学报,2007,12 (12):2132-2136.]
[2]HUO Shumin.Research of the key technologies of management of massive image data based on Hadoop[D].Changsha:National University of Defense Technology,2010 (in Chinese).[霍树民.基于Hadoop 的海量影像数据管理关键技术研究[D].长沙:国防科学技术大学,2010.]
[3]CHEN Weiwei,WU Haijia,XU Guanghui.Optimization model of file partition in distributed storage environment[J].Journal of PLA University of Science and Technology (Natural Science Edition),2010,11 (4):413-416 (in Chinese).[陈卫卫,吴海佳,胥光辉.分布式存储中文件分割的最优化模型 [J].解放军理工大学学报 (自然科学版),2010,11(4):413-416.]
[4]XUE Shengjun,LIU Yin.Establishment and test of meteorological data warehouse based on Hadoop [J].Computer Measurement & Control,2012,20 (4):926-928 (in Chinese).[薛胜军,刘寅.基于Hadoop的气象信息数据仓库建立与 测 试 [J].计 算 机 测 量 与 控 制,2012,20 (4):926-928.]
[5]WANG Xudong.Distributed file system management technology research based on the massive remote sensing image data[D].Lanzhou:Lanzhou Jiaotong University,2012 (in Chinese).[王旭东.面向海量遥感影像数据的分布式文件系统管理技术研究 [D].兰州:兰州交通大学,2012.]
[6]KANG Junfeng.Technologies of storage and efficient management on cloud computing for high resolution remote sensing image[D].Hangzhou:Zhejiang University,2011 (in Chinese).[康俊锋.云计算环境下高分辨率遥感影像存储与高效管理技术研究 [D].杭州:浙江大学,2011.]
[7]CHENG Chengqi,ZHANG Endong,WAN Yuanwei,et al.Research on remote sensing image subdivision pyramid [J].Geography and Geo-Information Science,2010,26 (1):19-23 (in Chinese).[程承旗,张恩东,万元嵬,等.遥感影像剖分金字塔研究 [J].地理与地理信息科学,2010,26 (1):19-23.]
[8]XIA Yubin,LIU Fengtao.Generalized image pyramid and coding method-oriented cloud computing[J].Journal of Huazhong University of Science and Technology (Natural Science Edition),2012 (S1):22-25 (in Chinese). [夏榆滨,刘丰滔.面向云计算的广义影像金字塔与编码方法 [J].华中科技大学学报(自然科学版),2012 (S1):22-25.]
[9]ZENG Zhi,LIU Renyi,LI Xiantao,et al.A mechanism of remote sensing image for parallel processing base on splitting blocks[J].Journal of Zhejiang University (Science Edition),2012,39 (2):225-230 (in Chinese).[曾志,刘仁义,李先涛,等.一种基于分块的遥感影像并行处理机制 [J].浙江大学学报 (理学版),2012,39 (2):225-230.]
[10]LV Xuefeng,CHENG Chengqi,GUAN Li.Framework and encoding analysis of global subdivision grid [J].Science of Surveying and Mapping,2011,36 (3):11-14 (in Chinese).[吕雪锋,程承旗,关丽.球面剖分模型的架构与编码分析[J].测绘科学,2011,36 (3):11-14.]
[11]CHEN Tianqing,XIE Jiancang,LI Jianxun,et al.Organization and schedule of remote sensing images under distributed environment[J].Computer Engineering,2010,36 (23):9-12 (in Chinese).[陈田庆,解建仓,李建勋,等.分布式环境下的遥感影像组织与调度[J].计算机工程,2010,36 (23):9-12.]
[12]QIN Xiongpai,WANG Huiju,DU Xiaoyong,et al.Big data analysis-competition and symbiosis of RDBMS and MapReduce[J].Journal of Software,2012,23 (1):32-45 (in Chinese). [覃雄派,王会举,杜小勇,等.大数据分析—RDBMS与MapReduce的竞争与共生 [J].软件学报,2012,23(1):32-45.]
猜你喜欢
环球时报(2022-09-19)2022-09-19
环球时报(2022-03-29)2022-03-29
考试与评价·七年级版(2020年4期)2020-10-23
少儿美术(快乐历史地理)(2019年2期)2019-06-12
知识经济·中国直销(2018年7期)2018-07-27
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
童话世界(2017年11期)2017-05-17
雷达与对抗(2015年3期)2015-12-09
电测与仪表(2015年8期)2015-04-09
