
基于词干提取的维吾尔语事件类时间短语识别
2014-12-23 01:28邹岳琳吐尔根依布拉音麦热哈巴艾力艾山吾买尔帕力旦吐尔逊
计算机工程与设计 2014年2期
邹岳琳,吐尔根·依布拉音,麦热哈巴·艾力,艾山·吾买尔,帕力旦·吐尔逊
(1.新疆大学 信息科学与工程学院,新疆 乌鲁木齐830046;2.新疆大学 软件学院,新疆 乌鲁木齐830008)
0 引 言
时间信息抽取[1]作为命名实体识别[2,3]的子任务,逐渐成为自然语言处理研究中的热点问题。在计算语言学领域,通过提取出时间短语、事件和时间的关系来计算时间维度并获取自然语言中精确的时间表达式,最终确定文本中时间信息和事件信息的映射关系。自1998年MUC-7首次在命名实体定义中加进了对时间评测要求以来,不少语种[4,5]的时间抽取任务已逐步完善,但对于实现像维吾尔语这样典型黏着性语言的时间信息抽取仍是一个挑战。
维吾尔语属于阿尔泰语系突厥语族,是典型的黏着性语言,具有强大的形态生产特性,一个给定的词干后缀接若干个词缀可产生多个词汇,如:küz(秋天)-küzlük (秋天的)-küzlüki(在秋天)-küzlükiche(直到秋天),因而引起数据稀疏的问题。本文研究维吾尔语文本中一类特殊的时间信息-事件类 时间短语 (uyghur event-anchored temporal expressions,UETE),该类时间短语不含数字且无明显边界特征,是一种隐性的时间,因而使用一般规则方法难以识别。为解决上述问题,本文考虑黏着语典型特征,提出一种将词级别的UETE识别转换为基于词干的UETE 识别方法。实验结果表明这一方法对其它黏着性语言研究具有通用性和扩展性。
1 研究背景
在自然语言中,时间信息用来描述事件的发生、变化及事件间的先后顺序。时间信息的表达具有多样性、无规则性和不唯一性,其类别以是否包含数字特征可分为显性时间信息和隐性时间信息;以参考对象可分为相对时间和绝对时间;以坐标系理论又可分为时间点和时间段。丰富多样的表述形式给时间信息识别增大了难度,国内外文献中常用的解决方法主要是基于规则 (rule-based)的方法和基于统计 (statistic-based)的方法。通常识别对象具有多样性、无规则性等特点,基于规则的方法需要人工构建大量规则,代价高,难以全面概括复杂的语言现象,对于不同语言得到的规则不具有可移植性。而基于机器学习的统计方法多是通过分类器学习,利用特征将识别问题转化为序列标注问题,在信息识别中有着不错的表现,但对语料严格依赖。
现阶段信息识别研究涉及语种包括英语[6],德语[7],西班 牙 语[8],日 语[9],汉 语[10],法 语[11],意 大 利 语[12],葡萄牙语[13],俄语[14]等。相对来说维吾尔语的信息识别研究由于条件限制,起步较晚,命名实体识别任务尚处于初级阶段,研究者多选用基于规则方法进行命名实体识别[15,16]。考虑到维吾尔语与土耳其语同属阿尔泰语系突厥语族,都属于黏着性语言,语法较相似,因而以土耳其语对两种主流方法进行对比分析。
在基于规则的方法研究,Küük等[17]在土耳其语命名实体识别研究中做出了比较具有代表性的尝试,文中提出建立多个词典资源和模式库,通过规则匹配方式对人名、地名和机构名进行识别。作者提出的方法使用起来非常简单,易于理解,且实验结果表明取得了较好识别效果,但该方法人工工作量较大,需要分别建立人名、地名及机构名的词典库和模式库,建立语法规则。
在基于统计的方法研究,Som T 等[18]在其研究中使用隐马尔可夫模型,利用机器学习的方式进行尝试,充分利用标注语料特征,使得识别率、召回率提高。实验结果表明,基于机器学习的统计方法在信息识别任务中有着不错的表现,适合大规模复杂语料情况。
本文采用基于统计的条件随机场模型,通过对UETE构成特点分析,结合黏着语构词特征,分别在词汇层面和词干层面实现UETE短语的识别,在新疆大学维吾尔语百万词词法分析语料库的实验结果显著,F-值达到85.37%,这一结果对于其它黏着语言的研究具有参考价值。
2 维吾尔语的事件类时间短语
2.1 概 述
时间信息识别研究中存在时间短语边界定位不准确和复杂时间短语识别困难两大问题,除此之外维吾尔语复杂的形态变化也增加了UETE 的识别难度。其形态变化可分为两种情况,其一,词干后缀接不同词缀,表现出不同形态而表达不同意义。如:yaz (夏天,n.)-yazniN (夏天的,adj.)-yazda(在夏天的时候,adv.);其二,词干缀接词缀时,可多层缀接,这也是导致维吾尔语词汇量庞大的原因。如汉语中 “你们不能进行标准化吗?”翻译成维吾尔语为 “lchemlextürelmemsiler”,由词干 “lchem” (标准)缀接多个词缀 (+lex+tür+el+m+siler),仅通过一个词干缀接多层词缀实现完整语法功能。
2.2 UETE定义和分类
定义 在句子中以事件为参考系的时间信息,一般是事件及与时间描述相关词汇的组合。如:yighinchixtin burun (开会之前)。其中,事件为 “yighinchixtin(开会)”,时间描述相关词汇为 “burun (……之前)”。
由定义可以看出,事件类时间短语不同于含有数字特征的显性时间短语,也不给出事件发生的精确时间,它属于一种相对时间信息,是以一个事件为参考系而确定另一事件的发生时间,其中起参考系作用的事件被称为参考事件。以参考事件为中心映射到坐标轴,对应的点和段分别称为时点事件类时间和时段事件类时间。时点事件类时间用来表示在什么时候发生的事件行为,如:hadise yüz bergen chüshtin kyin (事故发生的当天),而时段事件类时间用来表示在什么时间段里发生的事件行为,如inqilapning deslepliride(改革初期),tamaqtin kyinki ikki saet(吃 过饭两个小时后)等。
2.3 UETE特点和结构
事件类时间短语以事件为中心,其表达的时间信息是隐性的,有时不易察觉。如mekteptin qaytqandin kyin (放学后),其中包含的时间信息很容易被人为忽略。此外,维吾尔语强大的形态生成功能也使得其事件类时间短语的构成更为复杂,其形态变化按词干意义划分可分为两类:其一,某些非时间后附加成分可能构成时间词,如desse(踩)-desside(立刻);其二,某些时间词后可附加词尾构成不同时间词,如kech (晚上)-kchiche(整夜)。
由定义,维吾尔语事件类时间短语一般由事件+边界搭配词构成。如:sawaqdashlar mektepke kelgendin bri nahaytti tiriship Oqudi.(同学们来校后学习很努力),其中“mektepke kelgendin”为中心事件,“bri”(以来)为边界搭配词。在维吾尔语中,这样的边界词还有:toxtimaq (截止),kyin (之后,以后),mezgil(期间,时期),Ilgiri(以前),deslepki mezgil(初 期,前 期),harpa (前 夕),waqit(时候)等。
3 条件随机场模型
条件随机场 (conditional random fields,CRFs)是一种典型的序列标注判别模型,最早在2001年由Lafferty等提出,模型思想的主要来源是最大熵模型,可以被看成是一个无向图模型或马尔可夫随机场。该模型是在给定观察序列的条件下,计算整个观察序列状态标记的联合条件概率的无向图模型,采用一阶链式结构来构造模型 (如图1所示)。
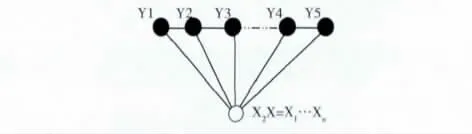
图1 条件随机场概率模型
根据最大熵原理和无向图理论,对输入观察序列X =(x1,x2,…xn),状态序列Y =(y1,y2…yn),CRFs的形式可以用一个联合条件概率分布P =(Y X)来表示,定义为

其中,λj和μj 为特征权重,可采用IIS (improved iterative scaling)、感 知 机 (perceptron)或GIS (generalized iterative scaling)等迭代算法估算。
而

CRFs是一种典型判别式模型,常被用于解决序列化标注问题。它兼具判别式模型的优点和产生式模型的特点,考虑到上下文标记间的转移概率,不再是对每个节点都进行归一化,而是对所有特征进行全局归一化,以序列化的
4 UETE的识别系统
4.1 基于CRFs的UETE识别模型
对于UETE的识别,不仅是要能自动识别隐性的事件类时间,更重要的是能确定其精确匹配的边界。本文采用基于条件随机场模型的识别方法,目前用于实现CRFs的工具包有Flex CRF,CRF++和Pocket CRF等,本文利用C#对CRFs开源工具包CRF++0.57[19]进行了改写,开发了维吾尔语事件类时间短语识别系统,基于CRFs 的UETE识别 (如图2 所示)主要有数据训练和数据测试两部分。
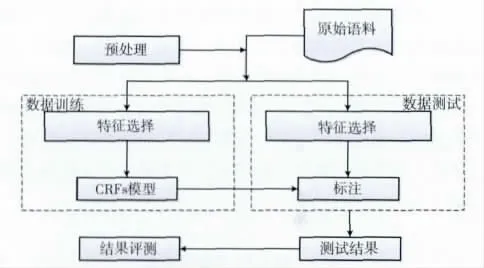
图2 基于CRFs模型的UETE抽取模型
4.2 特征选择
为了获取最优实验结果,特征选择在CRFs模型中对识别效率有着极为重要的影响。有效的特征集合不但能有效地降低干扰噪声、压缩特征空间减少计算量,更有助于提高标注效率和识别准确率。经过分析,影响事件类时间识别效果的因素主要有词、词性、位置特征等。综合考虑本文特征选择如下:
(1)词汇特征 (WORD):词是维吾尔语最小单位,源语料中词本身被作为一个特征。同时前两个词和后两个词也被作为上下文特征。
(2)词性特征 (POS):词性用来表明词在句子中充当的语法功能,对源语料预处理时标注出每个词的属性,这一特征可以在检测时定位时间短语边界词的位置。
(3)位置特征 (LOC):利用事件类时间短语出现的位置作为特征。事件类时间短语出现在句首,常用于表示事件发生的特定时间。
(4)词表特征 (DIC):通过对现有语料库资源统计,人工统计建立维吾尔语时间边界词词表,作为外部特征。
4.3 标注策略
本文标注策略借鉴了组块分析的方法,采用包含信息比较丰富的IOE2 标注策略,标记集合定义为 {B,I,E,O},各标记含义见表1。如: “sawaqdashlar mektepke kelgendin bri nahaytti tiriship Oqudi.(同学们来校 后学习很 努 力)”, 标 注 为 “sawaqdashlar/O mektepke/B kelgendin/I bri/E nahaytti/O tiriship/O Oqudi/O./O”。

表1 S/E标注策略标记集合定义
4.4 特征模版设计
为了充分考虑维吾尔语典型的黏着性语言特点,生成能反映语言本身内在规律的模型,借助于CRFs模版,综合利用词、词性、上下文等特征。在本实验中,还将边界词词表作为外部特征引入。CRFs模型通过特征模版的选择来调整特征函数集,尤其对于复合特征模版的选择需要多次尝试,最终确定最优特征模版。本文部分特征模版示例见表2。
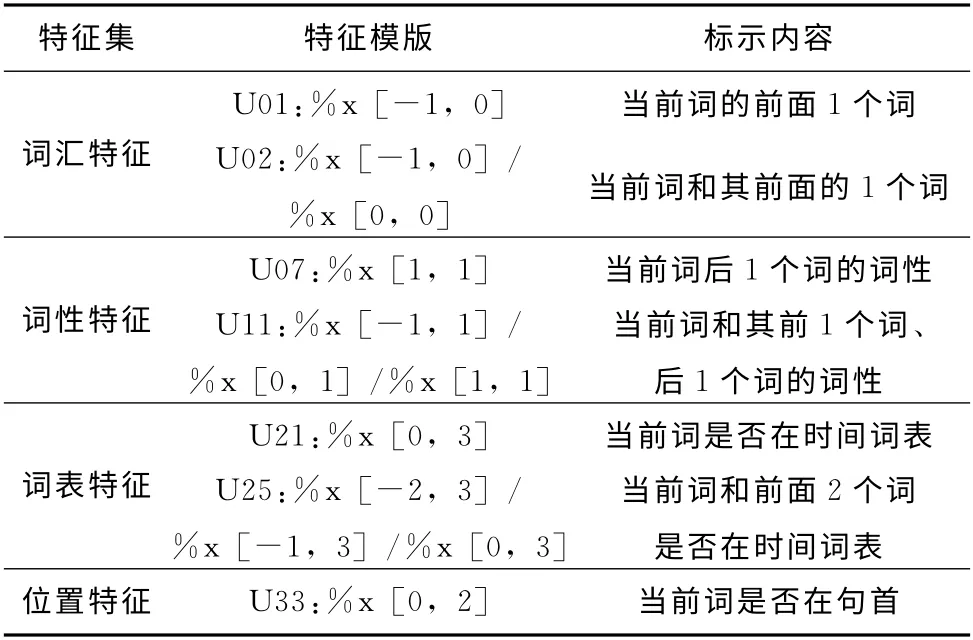
表2 部分特征模版示例
5 实验结果分析与评测
5.1 实验语料
实验利用C#改写的crf++程序,在新疆大学多语种重点实验室的 《维吾尔语百万词词法分析语料库》进行测试,该语料库涉及政治、经济、文学、科技等领域,囊括如小说 《故乡》,报告 《十七大报告》,农业杂志 《棉花技术》《知识-力量》 《新疆社科》和 《小麦》等的部分内容。实验从中随机抽取句子26046个,采用 《新疆大学维吾尔语词性标注规范》[20]进行词性标注。进而对所有单词进行词干提取,通过人工方式对事件类时间短语标注,作为实验训练和测试语料。实验中使用交叉验证法,每次随机选取75%作为训练语料,其余25%作为测试语料。使用语料信息见表3。

表3 实验语料信息统计
5.2 实验结果
本文 实 验 结 果 评 测 采 用 CoNLL-2000 的conlleval.pl[21]。对识别性能评估时,采用3个评测指标:准确率(precision,P),召回率 (recall,R),综合指标F-值 (Fmeasure,F)

为验证本文提出的方法,分别进行基于词级别和词干提取后基于词干级别的事件类时间短语识别实验。
实验1:词级别的UETE识别实验
本组实验以词为基线数据,分为五小组并分别使用如下组合特征:①Baseline:当前使用词特征;②Baseline+POS:当前词特征+当前词词性特征;③Baseline+POS+DIC:当前词特征+当前词词性特征+当前词是否在词表;④Baseline+POS+DIC+LOC:当前词特征+当前词词性特征+当前词是否在词表+当前词位置是否在句首;⑤All Features:即当前词特征+当前词词性特征+当前词是否在词表+当前词位置特征+上下文特征。
识别结果见表4。从表4可以看出,即使在仅考虑词汇特征时,对于维吾尔语事件类时间短语的识别已有较好的识别率,在Baseline基础上识别效率随着特征的加入而不断提高,说明CRFs对特征融合能力较强。在依次加入词性、位置、词表和上下文特征后,总结果得到很大提高,F-值达到84.49%。结合表3的语料信息统计,语料中事件类时间短语仅占2.18%,但即使对于较少的数据来说,识别效果仍然很好,说明本实验采用CRFs模型能有效克服数据稀疏现象。

表4 每组特征对识别结果的影响 (%)
实验2:词干级别的UETE识别实验
为了与基于词汇的识别结果进行对比,在对所有句子中的单词进行词干提取后,使用基于词干的方法,以提取出的词干为基线数据,仍使用实验1的分组方式,将Baseline替换为词干特征,以相同的5组组合特征集合再次进行识别,实验结果见表5。
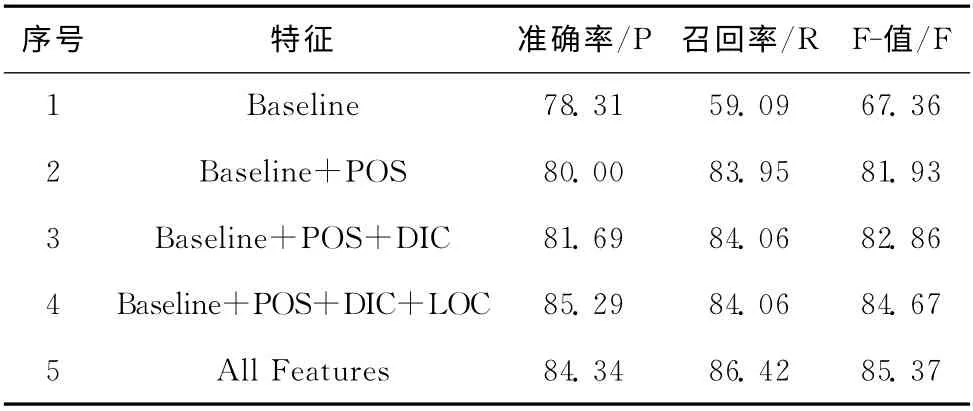
表5 每组特征对识别结果的影响 (%)
对比表4和表5不难看出,每个特征加入后识别效果都有不同程度提高,融合所有特征后,总结果得到很大提高。比较两组识别结果可以发现,词干提取后的识别率要优于基于词汇的识别结果,对比各组数据发现该结果产生原因是由于黏着性语言丰富的形态变化而导致的特征稀疏现象。
通过对实验结果分析,常见维吾尔语事件类时间短语识别错误可归类为以下3种:
(1)语料标注错误。事件类时间短语由于其以事件为锚点,不含数字、明显时间特征而难于发现,因此在进行原始语料人工标注时可能漏标或错标时间信息,导致错误级联放大引起结果标注错误。
(2)边界定位错误。一个事件类时间短语可能由多个词组成,CRFs虽然能识别出其中的边界指示词,但是却不能准确定位事件类时间短语的完整边界。
(3)由外部特征引起的错误。存在边界词表中的词,在当前上下文中可能不再表示时间意义,从而引起对非事件类时间短语的错误标注。如: “Zomigerlik axiri meghlup bolidu.”(霸权主义终归要失败),其中 “axiri”不再具有时间意义,只是表示说话人认为事物发展具有 “必然性”的模糊义。
6 结束语
本文针对维吾尔语典型的黏着语特性,利用现有的维吾尔语百万词词法分析语料库,以条件随机场模型为基础,改写crf++工具包,实现了维吾尔语事件类时间短语的识别,以基于词和基于词干两种方式进行对比实验,在Baseline的基础上引入其它特征,提高识别效率。在模型训练过程中还利用了边界词词表作为外部特征,该特征的加入显著的提高了识别效果。从实验结果来看,该方法是可行的,对事件类时间短语的识别是有效的。
由于维吾尔语命名实体识别研究起步较晚,各项研究尚不完善,目前对人名、地名、机构名的识别因语料库等多种原因限制,也多采用基于规则的方法,而时间短语识别是其中的一个新课题,尚无学者研究,因此对比同属黏着语的土耳其语研究文献 [17]的结果,表明本文方法较好地解决了事件类时间短语的准确识别和边界定位问题。因本文提出的方法不依赖具体语言和领域,实验结果对其它黏着语的研究具有参考价值。
时间信息的识别和抽取,最终目标是建立时间和事件、以及事件和事件之间的关系。因此在以后研究中将重点解决以下问题:
(1)由于本文采用机器学习方法严格依赖于语料规模和人工标注结果,由实验错误分析可知目前语料标注标准不够完善,因此下一步将建立准确标注规则,扩大标注语料库。
(2)分析事件类时间短语语法结构,该类时间短语除去一部分特殊的由 “事件+词缀”构成,其它多是由 “事件+边界词”构成,根据构成方式找到一种能将统计与规则结合的识别方法,进而提高识别准确率。
(3)利用识别结果抽取出事件类时间信息和事件,最终达到建立事件与时间的映射关系的目的。这一模型的建立对维吾尔语的机器翻译、信息抽取等自然语言处理研究任务具有积极意义。
[1]Sasayama M,Kuroiwa S,Ren F.Extracting date/time expressions in super‐function based Japanese-English machine translation [J].Electronics and Communications in Japan,2011,94 (4):44-54.
[2]Strtgen J,Gertz M.HeidelTime:High quality rule-based extraction and normalization of temporal expressions[C]//Proceedings of the 5th International Workshop on Semantic Evaluation.Association for Computational Linguistics,2010:321-324.
[3]Dos Santos C N,MilidiúR L.Entropy guided transformation learning:Algorithms and applications[M].London:Springer,2012:51-58.
[4]UzZaman N,Allen J F.TRIPS and TRIOS system for TempEval-2:Extracting temporal information from text[C]//Proceedings of the 5th International Workshop on Semantic Evaluation. Association for Computational Linguistics,2010:276-283.
[5]Lee C,Ryu P M,Kim H K.Named entity recognition using a modified Pegasos algorithm [C]//Proceedings of the 20th ACM International Conference on Information and Knowledge Management.ACM,2011:2337-2340.
[6]Ritter A,Clark S,Etzioni O.Named entity recognition in tweets:An experimental study [C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing.Association for Computational Linguistics,2011:1524-1534.
[7]Faruqui M,Padó S,Sprachverarbeitung M.Training and evaluating a German named entity recognizer with semantic generalization [J].Semantic Approaches in Natural Language Processing,2010,124 (9):129-135.
[8]Finkel J R,Manning C D.Nested named entity recognition[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing.Association for Computational Linguistics,2009:141-150.
[9]Ptaszynski M,Rzepka R,Araki K,et al.Annotating syntactic information on 5.5billion word corpus of Japanese blogs[C]//Proceedings of the 18th Annual Meeting of the Association for Natural Language Processing,2012:385-388.
[10]Guo H,Zhu H,Guo Z,et al.Domain adaptation with latent semantic association for named entity recognition [C]//Proceedings of Human Language Technologies:The Annual Conference of the North American Chapter of the Association for Computational Linguistics,2009:281-289.
[11]Rizzo G,Troncy R.Nerd:A framework for unifying named entity recognition and disambiguation extraction tools [C]//Proceedings of the Demonstrations at the 13th Conference of the European Chapter of the Association for Computational Linguistics,2012:73-76.
[12]Buscaldi D,Magnini B.Grounding toponyms in an Italian local news corpus [C]//Proceedings of the 6th Workshop on Geographic Information Retrieval.ACM,2010:15-19.
[13]Marcińczuk M,Piasecki M.Study on named entity recognition for Polish based on hidden Markov models [C]//Text,Speech and Dialogue.Berlin:Springer Berlin Heidelberg,2010:142-149.
[14]Nabende P,Tiedemann J,Nerbonne J.Pair hidden Markov model for named entity matching [M].Innovations and Advances in Computer Sciences and Engineering.Netherlands:Springer,2010:497-502.
[15] Mirigu,Tuergen,LIU Qun.Uighur organization name recognition [C]//The Fourth Session of Chinese Minority Youth Conference on Natural Language Information Processing.Qinghai:Qinghai Normal University,2012:112-117(in Chinese).[米日姑,吐尔根,刘群.基于语法语义知识的维吾尔文机构名识别 [C]//第四届中国少数民族青年自然语言信息处理学术研讨会.青海:青海师范大学,2012:112-117.]
[16]LI Jiazheng,LIU Kai,Mairehaba,et al.Recognition and translation for Chinese names in Uighur language[J].Journal of Chinese Information Processing,2011,25 (4):82-87 (in Chinese).[李佳正,刘凯,麦热哈巴,等.维吾尔语中汉族人名的识别及翻译 [J].中文信息学报,2011,25 (4):82-87.]
[17]Küük D,Yazici A.Rule-based named entity recognition from Turkish texts[C]//Proceedings of the International Symposium on Innovations in Intelligent Systems and Applications,2009:30-36.
[18]Som T,Can D,Saraclar M.HMM-based sliding video text recognition for Turkish broadcast news [C]//24th International Symposium on Computer and Information Sciences,2009:475-479.
[19]CRF++:Yet another CRF toolkit[EB/OL]. [2011-08-05].http://crfpp.sourceforge.net/.
[20]Turgun,YUAN Baoshe.A survey on minority language information processing research and application in Xinjiang [J].Journal of Chinese Information Processing,2011,25 (6):149-156 (in Chinese).[吐尔根,袁保社.新疆少数民族语言文字信息处理研究与应用 [J].中文信息学报,2011,25(6):149-156.]
[21]Melli G,Ester M.Supervised identification and linking of concept mentions to a domain-specific ontology [C]//Proceedings of the 19th ACM International Conference on Information and Knowledge Management.ACM,2010:1717-1720.
猜你喜欢
现代职业教育·高职高专(2020年22期)2020-03-24
中文信息学报(2018年11期)2018-12-20
自动化学报(2017年4期)2017-06-15
海外华文教育(2016年1期)2017-01-20
当代教育理论与实践(2015年9期)2015-12-16
新疆大学学报(哲学社会科学版)(2015年5期)2015-10-12
语言与翻译(2015年4期)2015-07-18
中文信息学报(2015年5期)2015-04-21
中文信息学报(2015年3期)2015-04-21
民族古籍研究(2014年0期)2014-10-27
