
基于AJAX应用程序的爬行测试算法
2014-12-23 01:28高秀慧高建华
计算机工程与设计 2014年2期
高秀慧,高建华
(上海师范大学 计算机科学与工程系,上海200234)
0 引 言
当今时代对网络的需求与日俱增,开发人员利用AJAX 技术提高页面显示和响应的速度,同时又能丰富用户的体验。AJAX 应用程序的友好性以及丰富的用户体验为自动化测试带来了新挑战:其一,传统网站通过不同的URL进行页面切换,但现在服务器不再需要保存大量的静态网页,而是用户通过请求直接从数据库里读取数据动态生成网页返回给用户;另一方面,传统网站通过整体刷新的方式呈现页面内容,但现在采用局部刷新技术,仅在浏览器和服务器之间传递少量数据,同时不影响用户对正在浏览的页面进行其他操作[1]。上述技术的运用使静态分析测试技术失去了作用,也使基于传统页面请求/响应模型的测试方法失效。
针对此问题,Mesbah[2]等提出一种ATUSA 框架,其主要思想:通过爬行AJAX 应用程序,自动点击按钮及其它用户界面元素,分析用户界面状态变化,动态推导出对程序中各种导航路径和状态建模的状态流程图,用最短路径算法从状态集中衍生测试集。夏冰[3]等对动态脚本网站采取更有效的页面获取方法,主要思想:通过训练页面元素触发事件,总结出采用事件和事件所在元素的XPath二元组表示法,在以后抓取中,只触发这些页面元素上的特定事件,进一步提升抓取效率。借鉴上述思想,本文通过改进爬行AJAX 应用程序时的不足之处,并将推导后的状态流程图通过规约法则 (合并测试路径)缩减测试集,减少测试集的生成,同时保证测试覆盖率。
1 背景及相关知识
可靠性是软件的一个质量要素,为了提高AJAX 应用程序的可靠性,测试或静态分析被广泛运用。目前已有许多工具用于测试,比如Selinimu、WebDriver、模拟用户输入点击等操作,实现Web自动化测试,但这些工具仍需要测试人员大量的手工操作。
传统Web与AJAX Web区别:AJAX 是一种将多种前端技术整合的思想。传统的网站以静态为主,通过不同的URL进行页面切换,每个不同的URL 对应不同的状态(状态是某一时刻在浏览器中呈现的DOM 结构);而采用AJAX 技术实现的Web系统普遍进行局部刷新,在用户触发事件调用JavaScript代码的同时,动态修改浏览器DOM树的内容与结构 (比如:鼠标位于图片区域,触发onmouseover事件,弹出对应的图片说明),由此生成新状态而改变用户界面的状态。由于这些状态都同属于一个URL,所以一个AJAX 页面可以同时拥有多个不同的内部状态;并且,页面上的超链接也可以指向其他URL 页面。对于Web程序的测试,一般通过设计爬行算法遍历实现,而AJAX 的技术特征对于爬行引擎如何定位并指向一个特定状态提高了难度。传统Web 数据采集转换图的节点为Web页面,转换图的边为超链接;对AJAX 而言,由于内部也会动态更改内容,所以页面内部同时会由事件触发。Matter[4]和Frey[5]都对状态 转换做了归 纳,图1 为AJAX站点模型页面状态转换图。从图1 中可以看出,AJAX 页面之间由超链接导致页面跳转,AJAX 页面内部由触发事件引起内部状态转换。
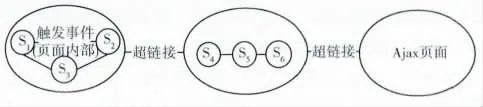
图1 AJAX 站点模型页面状态转换
2 用于状态转换图的爬行算法
本文提到的爬行算法执行客户端代码,对用户提交的每个行为进行分析,将每一次触发事件后更新的页面所对应的每棵DOM 树看做一个状态,每次事件触发是引起状态变化的条件,作为状态图的一条边,最后通过深度优先遍历推导出状态流程图。如图2所示。
2.1 状态流程图模型
状态流程图主要用于捕获用户界面的状态以及改变状态的转换条件,即流程图中记录引起DOM 变化而产生不同状态的XPath路径 (即DOM 树路径)以及各状态的集合。以下是状态流程图的定义:
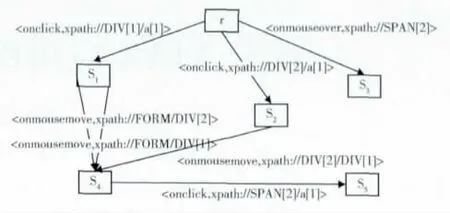
图2 状态流程
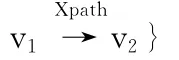
图2是状态流程图的示例,<onclick,xpath://DIV
[1]/a[1]>表示点击 “//DIV [1]/a[1]”代表的页面元素可以转换到另一状态。依据定义,初始状态r作为根节点也是起始节点,从起始节点r可以通过点击xpath路径上代表的页面元素转换到下一个状态,比如在起始节点r下,通过触发<onclick,xpath://DIV [1]/a [1]>代表的页面元素的onclick事件可以转换到S1;在状态S1下,触发<onmousemove,xpath://FORM/DIV [1]>或 者<onmousemove,xpath://FORM/DIV [2]>代表的 页面元素的onmouseover事件可以转换到S4;在状态S4下,触发<onclick,xpath://SPAN [2]/a [1]>代表的页面元素的onclick事件可以转换到S5;依此类推,将定义中的状态以及路径都由状态流程图示意;在状态S5下,由于没有输出边,即没有页面元素上可触发事件会改变DOM树的内容与结构,所以无法转换到其他状态。状态流程图为爬行算法的结果,主要为测试用例做准备,表1为状态流程图在数据库中的保存方式,当前状态下为StartState(未触发新事件的状态,比如:r),经过xpath路径中的Event事件触发后转换到NextState(触发事件后的状态,比如:r→S2,S2作为r的NextState);同时将NextState作为下一事件的StartState,即S2作为StartState);步骤同前,当新的StartState触发事件转换到NextState后 (比如:S2→S4),保存新事件并将新状态 (S4)保存至NextState。No.为状态序列号。表格为保存方式,主要为第三章节规约路径做准备。
2.2 爬行算法基本原理
传统爬虫在应用程序中爬行时,工作流程一般是从某个链接开始,获取链接地址的HTML源码,并从中抽取出<a>标签中的 “href”属性指向的URL链接,然后对已抓取的链接重复同样的步骤。但是基于AJAX 应用程序的URL不再是页面的唯一标识,传统爬虫无法抓取含有动态脚本的网页。针对AJAX 应用程序的爬虫工作流程,分析如何能抓取新链接中的隐藏链接 (候选元素)。比如:打开新浪微博首页,用浏览器打开查看源代码,清晰的发现源码中的内容远远少于页面呈现出的内容,因为在HTML 元素节点中,采取了后加载的方式调用JavaScript代码,并调用DOM 操作动态呈现,所以源码内容少。
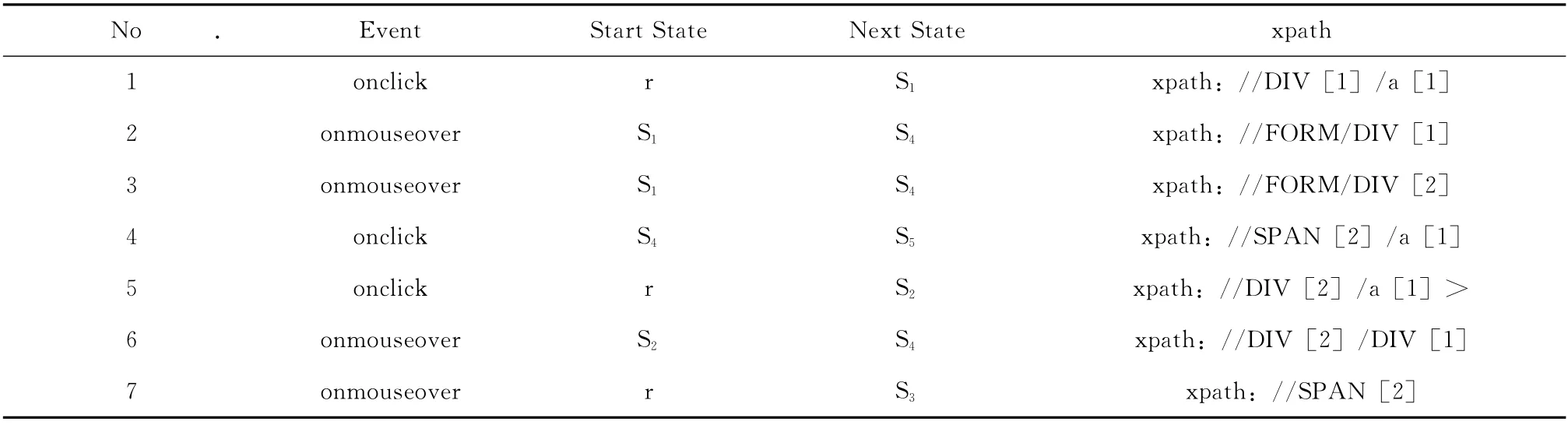
表1 状态流程图在数据库中的保存方式
2.3 优化的AJAX爬行算法
结合上述爬行算法的基本原理,提出了爬行算法的算法流程,通过不断将状态、路径关系添加至状态流程图,从而逐步增量式推导出状态流程图。图3描述了深度优先的爬行算法流程图,主要分为:算法初始化、检查候选元素、添加新状态、状态回退、判断终结条件。首先初始化嵌入式浏览器,加载URL地址,分析得到可触发事件的列表;按照深度优先算法,触发列表中的一个事件,获取触发事件后的状态;比较先前状态与触发后新状态的差异,若状态已变更,则认为状态已转换并将新状态、路径关系添加至状态流程图,若状态无变更,则认为新状态无转换并触发列表中其他事件;爬行过程不断迭代,设置新状态为当前状态继续爬行,若仍可抓取 (即仍有可触发的事件),则回到最初重新记录当前状态,步骤同前;若不可抓取,则需进行状态回退,通过重新加载原页面的方式回到先前状态,触发先前状态中的其他待触发事件;若已触发所有可触发事件,则判断是否达到最大抓取深度,防止不断出现新状态而导致爬虫陷入黑洞。
步骤1 算法初始化。在爬行算法开始之前进行初始化,启动嵌入式浏览器,初始化状态机、机器人,并根据给定的URL获取初始页面。状态机记录当前状态 (默认状态通常为r),分析得到基于当前状态的可触发事件的列表。
步骤2 检查候选元素。如何判断可触发事件是基于AJAX 应用程序的最大难点,传统网站爬虫仅靠超链接和表单来抓取资源,而优化后的爬行算法还会检查附加于事件监听器上的候选元素 (导致AJAX 页面状态转换的元素集div,a,span,input,IMG 等定义为候选元素)。对每个在DOM 树上被检测到的候选元素,爬虫在浏览器中触发候选元素上的事件,分析DOM 树的变化。假如触发的事件引起浏览器中DOM 树的变化,那么将当前DOM 树的状态和引起变化的事件路径记录,并保存至状态机。

图3 爬行算法流程
步骤3 添加新状态。比较当前状态是否与状态机中的已有状态重复,假如在状态流程图中已有类似状态,那么仅创建一条边,并识别事件的类型和路径;假如当前状态不是图中的一部分,那么创建新状态并添加至状态机。在确定新状态后,爬行算法被递归调用去寻找其余使DOM树发生变化的可能的候选元素。其中,优化后的爬行算法会计算先前DOM 树与当前DOM 树的差异,仅搜寻DOM树更改部分的候选元素,而不是对新的DOM 树搜寻所有的候选元素。
步骤4 状态回退。每次递归调用,浏览器都应回到先前状态,但基于AJAX 应用程序无法满足这一点。为了解决这个问题,可以选择保存候选元素信息 (即之前保存至状态机的DOM 树的状态和事件路径)和命令,以便下次可以直接达到想要的结果状态。通过重载应用程序,执行初始状态下的元素达到最终状态。
步骤5 判断终结条件,用于控制爬行算法。爬行算法抓取终结条件为满足以下任一项:
(1)判断是否达到最大抓取深度。深度是指由初始状态经过多次转换到达某个中间状态的转换次数。
(2)判断是否达到最大状态数,防止状态爆炸问题。
(3)当前状态是初始状态并且已触发所有可触发事件。
3 规约法则缩减测试集
通过上述优化后的爬行算法推导出状态流程图,此过程定义为第一步完整测试通过;第二步通过使用不同方法去覆盖状态流程图中的不同路径,达到测试目的,可以利用推导出的状态流程图进行测试集的生成。生成测试集的主要思想为:对状态流程图使用前K 条最短路径算法,所得出的多条最短路径就可以作为测试集使用,但由于图中所包含的状态覆盖面广,生成的测试集过多,部分测试集不具有代表性。本文通过利用合并测试路径的想法有效缩减测试集的生成,同时又不影响测试集的覆盖率。
3.1 最短路径算法
前K 条最短路径算法是最短路径的推广。给定一个有向图G= (V,E),一个正整数K 和两个顶点v1、v2,求出从v1到v2的前K 条最短路径。此算法求得的路径并不只有一条,而是多条最短路径。算法利用前K 条最短路径的思想方法,定义状态流程图中的r为v1,每个节点vi作为v2,求出r到vi的前K条最短路径。虽然用前K条最短路径求出的算法已是最优算法,但其实在推导状态流程图时会因触发不同事件生成同一状态的现象存在,比如:在页码1的状态下,点击页码2和下一页会向服务端发出请求获得同一页的数据,我们应尽量避免这类事件的重复检测。
3.2 合并测试路径
为了减少测试集的生成,本文通过规约的思想,即合并测试路径的方法生成最优的测试集,也可以理解为选取触发具有特征的事件生成测试集,同时不影响测试覆盖率。
本文对前K 条最短路径求出的所有路径规约采用了如下方法:被规约的两条XPath 路径必须其前状态 (Start-State)相同,即路径所经过的页面元素名称完全相同,并且经过xpath路径后生成的状态是同一状态 (NextState状态相同);对这两条XPath进行序号规约,如 “//div[4]/li[1]/span[1]”和 “//div [4]/li[1]/span [2]”这两个xpath,可以规约成 “//div[4]/li[1]/span[*]”;如“//div[4]/span[1]/a[1]”和 “//div[4]/span [2]/a[1]”这两个xpath,可以规约成 “//div[4]/span [*]/a
[1]”;但 是 如 “//div [4]/li[1]/span [1]”和 “//li
[1]/span[2]”这两个xpath,不可以进行规约。这样,我们便选取了一些具有特征的事件,在生成测试集时只需选择其中一条路径,无需所有的路径都被测试。同时,为了提高覆盖率,对已属于测试路径中的状态标记为已检测,第二次规约时尽可能选择未被检测过的状态。
本文对路径规约识别算法进行以下描述:
第一步:深度遍历状态流程图,得到前K 条最短路径。
第二步:对于最短路径中的xpath 路径,满足以下条件时,进行合并:
(1)xpath路径具有同父状态结点,处于同一层次;
(2)xpath路径拥有同子状态结点,处于同一层次;
(3)xpath路径符合序号规约法则;
(4)判断xpath路径是否已被检测,选择合适的xpath路径。
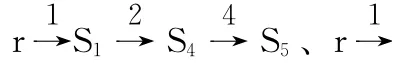
4 实验与讨论
本文实验的目的在于验证优化后的测试集在数量上明显减少以及在覆盖率上没有受到影响。本文随机选取了网站进行测试,重点关注以下两个问题:(1)优化后的AJAX 爬行算法是否能抓取候选元素;(2)本文提出的规约测试路径的方法是否有效。
4.1 实验准备
实验是在STS (spring tool suite)开发平台上编写,本文依据2.2中提到的爬虫算法进行测试。为了获得实验数据,设计了如下的测试环境,如图4所示。
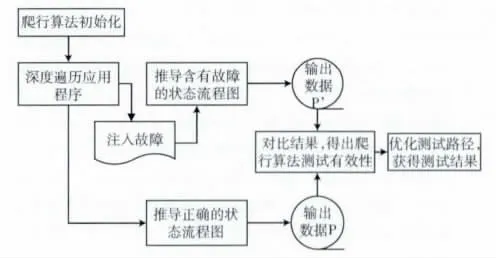
图4 测试环境
本文设计的对比实验选用了百度网站(www.baidu.com)进行测试:①设置爬行算法深度为2,利用爬虫推导出正确的状态流程图;手动对应用程序注入不同故障,推导出含有故障的状态流程图;②遍历状态流程图,分别读取正确的和注入了故障的数据,获得相应结果P和P’,对比结果分析爬行算法的测试有效性;③通过使用3.2中的路径规约识别算法,得到优化后的前K 条最短路径,比较新生成的测试路径对测试有效性的最终影响。
4.2 实验结果
实验中选用了未注入故障的应用程序以及分别注入一个或多个故障后的应用程序,结果对比输出的数据。注入故障后的应用程序由于无法抓取全部的状态数,所以生成的状态流程图一定小于未注入故障所生成的状态流程图,因此,输出的数据P’的状态数、Xpath数一定小于P。最后比对P和P’的值,得出爬行算法的有效性。
4.2.1 生成状态流程图
图5为抓取隐藏链接后生成,正确的状态流程图。通过使用爬虫算法对网站进行深度优先遍历,从www.baidu.com触发,触发所有候选元素的事件 (其中大部分为<a>标签内的隐藏事件),得到图5所示的状态流程图。
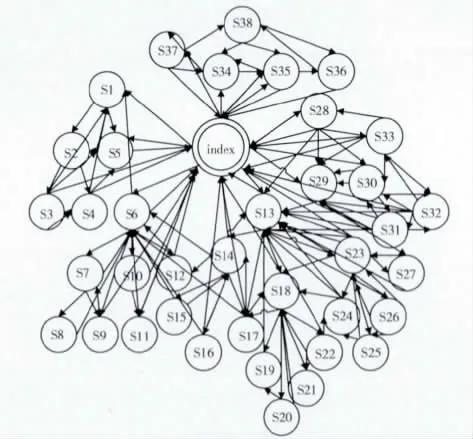
图5 百度网站状态流程
4.2.2 有效性实验数据
实验通过屏蔽代码的方式从不同位置注入故障,分别注入0、1、2、3、4个故障。表2 第一列是本次实验在不同位置注入的故障个数,第二列是应用程序所应抓取到的状态数,第三列是通过使用本论文提到的爬行算法抓取到的状态数,第四列是抓取应用程序的状态覆盖率=P’/P的结果。
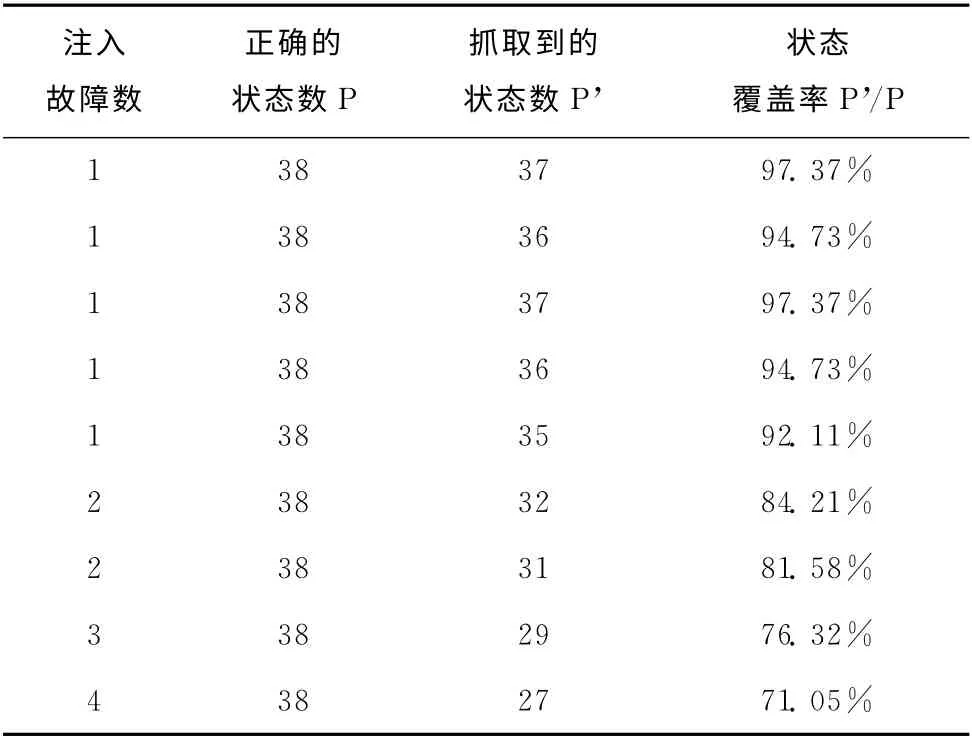
表2 有效性实验数据
从实验结果可以清晰看出,2.2 中提到的算法抓取效率高,从表2中可以看出百度应用程序在未注入故障前应获得的正确状态数为38,受故障的影响,注入不同故障后所获得的状态数逐渐减少,当注入故障为1时,状态覆盖率最高达97.37%,平均值为95.26%。注入故障数的多少不会对覆盖率产生太大影响,注入的故障位置对覆盖率会产生一定影响,原因在于出现故障的Xpath 无法生成下一状态。
4.2.3 测试集实验数据
表3为算法实验数据,从数据中可以发现状态间存在多条xpath路径,依据经验,会存在多条重复路径。优化后的AJAX 爬行算法可以抓取新链接中的隐藏链接,共生成38个不同状态,检测到的状态为100%;抓取到的xpath路径为163条,通过合并测试路径生成测试集,检测到的xpath路径为141条,覆盖率为86.5%,成功解决了AJAX应用程序难以抓取隐藏链接的难题;通过使用本文提出的路径规约识别算法后获得的测试集,测试集由58变为52,缩减了6条测试路径。

表3 算法实验数据
从实验结果中可以明显看出利用本文给出的规约方法检测的覆盖率高,符合理想的测试结果;使用规约后的测试集数量小于原来的测试集数量,达到了优化的目的。改进前的测试集为路径覆盖,覆盖面广且可靠性高,但对于大型网站而言,适用性不大;改进后的测试集在数量上减少,在大型网站中能体现出一定优势,并且保证较高的覆盖率。研究分析,对于具有极高结构相似性的网页 (特别是含有3.1中提到的重复检测)进行优化测试集,缩减的数量更加明显;并且,相信随着抓取深度的增加,状态数增加的同时,被检测到的状态数也会增加,测试集数量会持续递减。实验结果表明,上述提出的方法优越性高,减少测试人员的工作量。
5 结束语
本文讨论了测试AJAX 应用程序的最优方法:通过爬行算法,对Web应用程序进行分析,获取页面上的所有链接,推导出状态流程图,生成测试集。本文简要介绍了爬行算法的工作流程,对测试集进行优化的方法。经过初步实验,表明优化后的测试集在数量上明显减少,并能保证较高的覆盖率。当然该方法仍有一定的局限性,可以作为日后研究的方向:文中提出的爬行算法对JavaScript分析不够深入,对脚本解析的完整性需进一步加强,所以无法抓取某些特定应用程序 (例如:数独等),应进一步扩展算法的适用性。
[1]Mesbah A,Van Deursen A.An architectural style for AJAX[C]//Proceedings of the 6th Working IEEE/IFIP Conference on Software Architecture,2007:44-53.
[2]Mesbah A,Van Deursen A,Roest D.Invariant-based automatic testing of modern Web applications[J].IEEE Trans on Software Engineering,2012,38 (1):35-53.
[3]XIA Bing,GAO Jun,WANG Tengjiao,et al.An efficient valid page crawling approach for Websites with dynamic scripts[J].Journal of Software,2009,20 (Suppl):176-183 (in Chinese).[夏冰,高军,王腾蛟,等.一种高效的动态脚本网站有效 页 面 获 取 方 法 [J].软 件 学 报,2009,20 (增 刊):176-183.]
[4]Duda C,Frey G,Kossmann D,et al.AJAX crawl:Making AJAX applications searchable [C]//IEEE 25th International Conference on Data Engineering,2009:78-89.
[5]Frey G.Indexing AJAX Web applications[D].Zurich:Swiss Federal Institute of Technology Zurich,2007.
[6]Mesbah A,Van Deursen A,Bozdag E.Crawling AJAX by inferring user interface state changes [C]//8th International Conference on Web Engineering,2008:122-134.
[7]Mesbah A,Van Deursen A.Migrating multi-page Web applications to single-page AJAX interfaces [C]//Proc 11th European Conf Software Maintenance and Reeng,2007:181-190.
[8]Mesbah A,Prasad M.Automated cross-browser compatibility testing [C]//Proc 33rd Int'l Conf Software Eng,2011.
[9]Mesbah A,Bozdag E,Van Deursen A.Crawling AJAX by inferring user interface state changes [C]//Proc Eighth Int'l Conf Web Eng,2008:122-134.
[10]Roest D,Mesbah A,Van Deursen A.Regression testing AJAX applications:Coping with dynamism [C]// Proc Third Int'l Conf on Software Testing,Verification and Validation,2010:128-136.
猜你喜欢
电脑报(2019年12期)2019-09-10
测控技术(2018年7期)2018-12-09
中国计算机报(2018年30期)2018-11-12
北京航空航天大学学报(2018年10期)2018-10-30
中国惯性技术学报(2017年5期)2017-12-02
河南科技(2016年8期)2016-09-03
河南科技(2016年6期)2016-08-13
河北传媒研究(2014年4期)2014-07-12
浙江共产党员(2014年12期)2014-07-10
天津医药(2012年3期)2012-11-28
