
基于GPS轨迹的周期模式发现
2015-01-24 12:24李海
电子设计工程 2015年21期
李海
(江苏科技大学 计算机科学与工程学院,江苏 镇江 211003)
智能手机和穿戴设备的兴起使得GPS轨迹记录的采集越来越方便,也为轨迹数据挖掘研究带来了极大的便利。由于人类活动是有着某些显著的且相对固定的移动模式[1],所以周期模式的挖掘不仅为移动数据的压缩提供了帮助[2-3]同时还可以用来预测该对象未来的移动方向[4]及发现移动对象的异常行为。然而,从GPS记录中发现用户的周期模式是一件非常有挑战的事情。其中有两个主要问题需要解决:如何有效预处理GPS数据和如何从时间序列的发现周期模式。
已经有很多人针对周期模式发现这个问题进行了研究,但是他们很少考虑到GPS数据特殊性:数据不是完全正确、采样频率的不确定、数据的不完整等。2010年,Li提出将傅里叶变换和自相关系数结合寻找周期模式[5],该方法的不足之处在于采样频率过低和数据不完整的情况下,很少能找到周期模式。由于用户的GPS设备不一定是随时都处于工作状态以及面临大量用户数据的时候,采样点过密,会产生大量的数据冗余,所以文中主要研究如何处理低采样的情况。
针对GPS数据的特殊性,文中提出一种周期模式的发现方法GMPF(GPSMulti-Periodic Find),可以有效处理数据稀疏和不完整的问题。基本的算法思路:首先对GPS记录进行预处理并聚类得到需要的兴趣点,然后对兴趣点进行采样得到多个二进制的序列,最后采用基于概率的周期发现算法,从二值序列中发现每个兴趣点的周期模式。
1 GMPF算法框架
GPS记录是由一系列 GPS点构成的[6],表示为 P={p1,p2,…,pn},每个GPS点数据由经度,纬度和时间戳构成,pi∈P且pi=(Lat,Lngt,t)。
定义1(GPS轨迹):GPS轨迹可以看成是关于GPS点的时间序列。Tra={p0,p1,…,pn},∀0≤i≤n,pi+1·t>pi·t,其中pi(0≤i≤n)是 GPS 采样点。
定义 2(停留点):一个停留点表示一个区域范围(θd表示区域半径)用户停留的时间超过了设定的时间阈值θt。停留点就是符合以下定义的GPS点的集合P=

表示当前停留点的中心坐标,代表这个停留点的位置,ta表示停留点起始时间点,tl表示停留点的结束的时间点。
定义3(行为的周期模式):一个行为的周期模式可以表示成
从上面的定义,文中提出一个两步骤的周期发现算法GMPF(GPSMulti-Periodic Find)。
算法1:GMPF(多周期模式发现)
输入:一个GPS移动序列LOC=loc1loc2…locn
输出:一系列兴趣点的周期模式
1:/*阶段1:检测GPS中兴趣点*/
2:Find stay spots S={s1,s2,…,sn}; //找到所有的停留点
3:O=ClusterStayPoint(S);//通过聚类停留点,得到兴趣点
4:/*阶段2:检测每个兴趣点的周期模式*/
5:for each oi∈O do
6:P=MinePeriodPattern (oi);//对每个兴趣点进行周期模式挖掘
7:constructPeriodPatternOutput (P);//构造周期模式输出结果
算法1描述了GMPF的基本的框架。在第一个阶段主要是找到所有的兴趣点(2-3行),然后对每一个兴趣点进行周期模式挖掘并输出相应的结果(5-7行)。
2 兴趣点发现
本文主要是处理两类停留点,第一类停留点就是一个人进入了某个区域,然后在这个区域徘徊的时间超过了一个阈值;第二类情形就是一个人GPS记录保持停止状态的时长超过了某个阈值。
兴趣点发现是对上一步得到的停留点集合进行聚类分析,得到其中被访问次数较高的区域。文中提出一个依赖于阈值假定的聚类方法,其思想类似于DBSCAN,但是不需求去计算邻域,而是去扫描已经存在簇,当数据的密度比较高的时候,效率会远高于DBSCAN,在最坏的情况下也要比DBSCAN的时间复杂度要小。由于本文主要挖掘GPS序列中的周期模式,一般来说存在大量周期模式的数据中必然存在大量的高密度数据簇。
首先从停留点集合中抽出一个未处理的点,然后遍历当前所有的簇的集合,检测该点是否属于某个簇,如果存在这样的簇的话,则更新簇的中心。否则认为这个点是一个新的簇。最后检测每个簇的计数是否满足最小计数的要求。
3 周期模式挖掘
3.1 移动序列二值化
现在得到了一系列的兴趣点,下面主要是针对每一个兴趣点进行挖掘,找出其中潜在的周期模式。以其中的一个兴趣点为例,首先对整个移动序列进行采样,将这个移动序列转换成一个二进制序列 B=b1,b2,…,bn,当这个移动对象在时间点i的时候在这个兴趣点区域内,则bi=1,否则 bi=0。
3.2 二进制序列周期挖掘模型
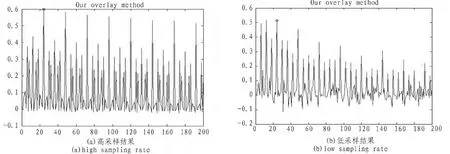
定义4(周期序列)在一个序列X=x(t),0 定义 5 (周期分布向量)定义向量 p=[p0,p1,…,pT-1]∈[0,1]是一个长度为 T的周期分布向量,x(t)是独立且服从pmod(t,T)伯努利分布,则 X=x(t)就是一个服从周期向量分布 p的二值序列。 定义 6:假设 X 是一个二值序列,定义 S+={t:x(t)=1},S-={t:x(t)=0}。 It表示[0:T-1]的幂集,其中 T 表示一个候选周期。对于任何∀I∈It,定义 S+I={t∈S+:FT(t)∈I},S-I={t∈S-:FT(t)∈I},其中 FT(t)=mod(t,T),进一步用比率形式表示 μx+(I,T)= 定理1:对于一个长度为n且服从周期向量分布P的二 现在介绍基于定理1的周期发现方法,对于任意的I∈IT,Δx(I,T)=μx+(I,T)-μx-(I,T)。 当 T 是本序列的周期,则满足下面的条件 γ(T)=Δ(I,T),显然 0≤γx(T)≤1。 当序列 X完全符合以T为周期的时间序列,则γ(T)=1。但是这些只能说明在什么情况下的T是符合要求的,下面还要介绍如何才能找到这个周期T。 可以得到: 经过3.1节的移动序列二值化以后,就可以把得到序列看成是一个服从某个周期向量分布的序列。在3.2节中已经介绍了文中寻找潜在周期T的方法,就是计算每一个周期T的可能性,然后取概率最大的一个,具体的步骤如下: 1)设定一个最大周期Tmax 2)从区间[1,Tmax]中按序取出一个值,赋值给T0 3)用公式(1)和(2)计算T0是目标序列周期的概率 4)重复第二步,直到完全遍历 5)取计算得到的最大P对应的T0,这就是当前序列的周期 假设一个最大可能的周期Tmax,然后通过公式计遍历计算[1,Tmax],取P最大的那个T,作为本条序列的周期。 本实验的运行环境是 Windows 7操作系统,算法的编写使用 Python语言。主要开发软件环境包括:1)Spyder作为实验算法实现和性能测试程序的开发环境;2)MySQL作为数据库存储平台。本文使用的数据集是微软亚洲研究院Geolife项目所采集到的数据。 算法验证1:为了验证文中的对兴趣点的聚类算法的有效性,本文在geolife的编号为0的用户的数据集上进行了实验,同时将实验的结果同Yu文章中使用的聚类方法DBSCAN得到的结果进行比较。 GPS记录点总数是173 870,通过停留点分析,得到 823个停留点。然后通过对停留点分别使用DBSCAN和本文的兴趣点聚类算法进行聚类。实验结果如图1和图2所示。 图1 DBSCAN聚类结果Fig.1 Result of DBSCAN cluster 图2本文方法聚类结果Fig.2 Result of our cluster method 由于DBSCAN密度可达是直接密度可达的传递闭包,并且这种关系是非对称的,使其对数据集的密度极为敏感。如图1所示,数据被聚类成2个簇,其中簇1中包含了764个点,簇2中包含了23个点。如图2所示,文中提出的算法将数据划分成了5个簇,所包含点的个数分别为110,294,118,15,17,50。结合本GPS数据的特点,人们日常生活的移动轨迹数据,可以看出本文的算法更符合现实特点。 算法验证2:二值化序列的周期挖掘算法验证比较,为了验证本文周期挖掘算法在低采样情况下的有效性,将文献中[5]提出的FFT集合自相关系数,以及文献[7]中提出的几种二进制序列周期发现方法和本文的周期挖掘算法进行比较。图3,4,5分别是本文的方法自相关系数结合傅里叶算法、傅里叶结合直方图算法在不同采样率情况下的实验结果。 由图3~5所示,可以发现在高采样的情况下,3种算法都是表现良好,但是当降低采样频率后,后3种方法就不能得到正确的周期了。由此可以看出本文提出的周期算法对低采样的情况有较好的表现。 实验验证3:在geolife的编号为0的用户的数据集上,综合验证本文的算法。在实验1中得到了5个兴趣点,由于后两个兴趣点的密度较小,所以只选用前3个兴趣点进行验证,假设这三兴趣点分别是公司、家、健身馆。最后的得到的实验结果如表1。 图3本文方法Fig.3 Our method 从表中可以看出该用户的周期模式分别是一天和一周为单位的,符合日常的行为习惯。 图4自相关系数结合傅里叶算法Fig.4 Autocorrelation coefficient combined with Fourier algorithm 图5傅里叶结合直方图算法Fig.5 Fourier combined histogram algorithm 表1 用户的周期模式检测结果Tab.1 Result of Person periodic pattern 本文针对移动对象的周期性问题,提出了一个GMPF算法,主要有两个部分构成。第一个部分找到兴趣点,不同的兴趣点在时间上是可以重叠的,这个也就解决了同时存在多个周期模式的问题。第二部分主要是挖掘周期模式,由于GPS[8]数据采样频率的不确定性,采用基于概率统计的方法来寻找周期。实验结果表明本文的方法在数据非常稀疏的情况下,也可以取得较好的表现。本文提出的算法框架在最坏情况下的时间复杂度是O(n*n),这个还可以进一步的改进与提高,也是将来研究的一个方向。 [1]Gonzalez MC,Hidalgo C A,Barabasi A L.Understanding individualhumanmobilitypatterns[J].Nature,2008,453(7196):779-782. [2]Cao H,Mamoulis N,Cheung D W.Discovery of periodic patterns in spatiotemporal sequences[J].IEEE Transactions on Knowledge and Data Engineering,2007,19(4):453-467. [3]Xia Y,Tu Y,Atallah M,et al.Reducing Data Redundancy in Location-Based Services[C]//Geosensor,2006.InProcs.of 2nd International Conference on Geosensor Networks,2006:30-35. [4]Jeung H,Liu Q,Shen H T,et al.A hybrid prediction model for moving objects[C]//IEEE 24th International Conference on.IEEE,2008:70-79. [5]Li Z,Ding B,Han J,et al.Mining periodic behaviors for moving objects[C]//Proceedings of the 16th ACMSIGKDD international conference on Knowledge discovery and data mining.ACM,2010:1099-1108. [6]Zheng Y,Zhang L,Xie X,et al.Mining interesting locations and travel sequences from GPS trajectories[C]//Proceedings of the 18th international conference on World wide web.ACM,2009:791-800. [7]Junier I,Hérisson J,Képès F.Periodic pattern detection in sparse booleansequences[J].Algorithms for Molecular Biology,2010(5):31. [8]雷娟,刘文霞.GPS数据采集分析器设计 [J].电子科技,2013(5):30-33.LEI Juan,LIU Wenxia.Design of a GPS data acquisition analyzer[J].Electronic Science and Technology,2013(5):30-33.

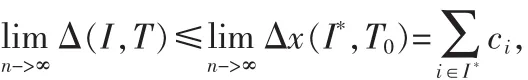

3.3 周期模式挖掘算法
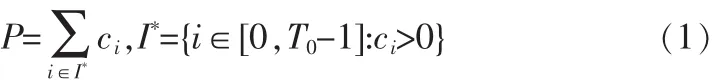

4 实验及结果分析


5 结 论



猜你喜欢
成都信息工程大学学报(2019年4期)2019-11-04
铁道通信信号(2019年6期)2019-10-08
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
雷达学报(2017年6期)2017-03-26
现代防御技术(2016年1期)2016-06-01
互联网天地(2016年1期)2016-05-04
山东青年(2016年1期)2016-02-28
智能系统学报(2015年4期)2015-12-27
当代修辞学(2014年3期)2014-01-21
