
基于人工情感的Q-学习算法在机器人行为决策中的应用
2015-01-27 03:02谷学静高贝贝朱朝月
自动化与仪表 2015年7期
谷学静,高贝贝,朱朝月
(华北理工大学 电气工程学院,唐山 063009)
随着计算机和人工智能技术的发展,智能机器人在人类的生产生活方面应用愈加广泛。为使机器人能够产生拟人情感并与人类自然和谐地进行人机交互[1],将人工情感引入到机器人智能控制中逐渐成为人工智能领域一个新的研究方向。
目前大部分人工情感的研究集中在情感识别、情感建模及情感表达[2],人工情感的研究不应仅局限在和谐的人机交互,而应充分发挥情感因素对机器人自主学习和行为决策的作用。在机器人的行为决策中引入人工情感,能够使机器人更逼真地模拟人类智能行为。
强化学习是有效的机器学习方法之一。在强化学习算法的基础上引入情感因素,有了情感模型的指导,学习和决策过程将具有更加明确的目的性和方向性,而不是在庞大的求解空间中盲目地尝试[3]。首先,机器人根据外界环境的刺激模拟产生特定状态下的情感值,并反向抉择出引发正向情绪的经验知识。然后,机器人从择优的经验知识中学习最优控制策略,以改善机器人行为决策中的学习效率和收敛速度,提高机器人的自主学习和自主行为决策能力。
1 人工情感建模
情感是人类对客观事物的态度体验,同人的切身需求有关。它能够帮助人们在不同的需求下选择恰当的行为,增强人类对周围环境的自适应能力[4]。文献[5-6]的研究表明情感在智能决策中起着重要作用,位于大脑皮层边缘系统的杏仁核能够快速获得感觉输入,并做出迅速的情绪反应。情绪自身便可激发行为动作,而不需理智思维的调控。这种急速的反应可以帮助人类快速做出趋利避害的行动。
本文仿效情绪本身即可触发行为的机制,实现机器人自然情感调控行为的功能,构建了基于随机事件处理的情感模型。机器人利用传感器采集外界环境中的离散信号(如压力、温度、高度),将获得的信号传到情感模型中产生与之对用的情感状态。其中情感模型的情感输出符合人类的情感变化规律。积极的情绪状态会成为行为的积极诱因,消极的情绪状态则起消极诱因作用,情感在自主学习和自主行为决策中扮演着驱动角色。
情感模型系统的工作过程如下:首先将采集的一组传感器信息作为一个离散事件 et(e1,e2,…en),根据当前情感状态把 et(e1,e2,…en)转换为基本情绪向量 Xt(x1,x2,x3,x4)。 然后将基本情绪向量 Xt(x1,x2,x3,x4)输入到情感空间,得到模型输出 Yt(y1,y2,y3,y4),嵌入该模型的机器人可以根据Yt做出带有情感的决策。为了方便机器人在行为决策中应用情感模型,将情感模型产生的情感均值Yt转化为可以直接利用的数值,因此设 μt, μt∈[0,1]为情感均值变换后的情感系数值。其情感模型系统框架和情感系数变换函数如图1所示。

图1 情感模型系统框架和情感系数变换函数Fig.1 Emotional factor model framework and emotional transformation function
图中第一个节点代表正向与负向情绪分类函数,其中k+,k-分别为正向和负向情感函数的系统反馈系数,εt为对采集到外界刺激进行修正后的值,η(+,-(i))为正向与负向情绪分类函数值。 图中第二个节点代表情感输出值变换为情感系数的变换函数。具体情感模型系统原理论述见文献[7]。
2 Q-学习算法
强化学习是从动物学习、参数扰动自适应控制等理论演化出来的[8]。强化学习的目的是要学习从状态到动作的最佳映射,以便获得奖赏信号最大[9]。其中Q-学习算法在机器人行为最优控制策略中应用广泛,它是Markov决策过程的一种演化形式。Q-学习的目标是寻找一个策略π,使在学习的时间内获得的累积折扣回报Rdπ最大:

式中:γ(0<γ<1)为折扣因子;t=1,2,…,为每个时间步;rt为执行每一步动作后的立即回报;i为到达最优策略π时所经历的时间步数值。
Q(s,a)值是机器人在环境状态下选择对应动作后执行策略π的回报折扣和的数学期望:

式中:S=[s1,s2,…,st]为机器人在环境中的状态集;A=[a1,a2,…,at]为对应状态选择的动作集;rt为在状态 st下执行动作 at得到的立即回报;P(st,at,st+1)为机器人在状态st下执行动作at转移到下一个状态st+1的概率。
实现在线Q-学习方法按如下的递归公式进行:
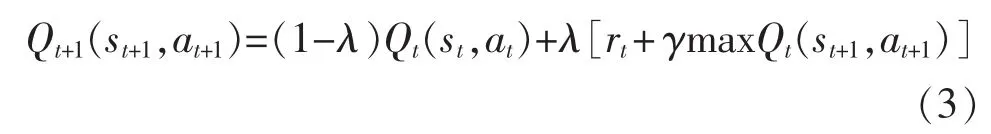
式中:λ为学习率,控制学习速度,λ越大则收敛越快。但是,过大的λ有可能导致不收敛。在一定条件下当t→∞ 时,式(3)进行无穷次迭代,Qt(s,a)以概率 1收敛到关于最优策略的Q*(s,a)。
3 基于人工情感改进的Q-学习算法
Q-学习的目标是在不确定的环境下根据评价信号来选择最优控制策略,可以理解为是一个在线最优决策学习过程。由于Q-学习是一种不依靠环境模型进行的自学习的算法,也就是机器人一点都不熟知外环境信息。它只能通过有限的试错法来学习,因此学习的效率非常低。对于强化学习收敛速度较慢问题,本文在利用环境模型提高强化学习收敛速度的基础上[10],将人类情感具有的趋利避害生存机理引入到环境模型经验知识的学习中。利用情感决策调整经验知识的学习强度,进而加快机器人在线地完善环境模型的收敛速度。
环境模型是从一个状态动作对(si+1,a)转换到邻近状态强度值(si+1,r)的函数,确定环境模型有2种方法:一是在学习的开始状态时,根据已知数据离线确定模型;二是机器人在与环境接触时在线构建或完善环境模型。环境模型可以利用之前完成过的任务获取的经验来构建,机器人再反向的从模型中获得经验知识,进而帮助它学习最优控制策略。因此在标准的Q-学习算法中引入自定义的经验知识函数H:S×A→R,此函数可在线保存状态st下执行相关动作at的经验信息。然后机器人利用人类情感具有的趋利避害生存机理,通过经验函数H(st,at)选择最优控制策略的经验信息,其相应环境下情感-状态-动作选择规则如下:

步骤1初始化状态st动作at下回报折扣和的数学期望Q(st,at),初始化情感模型离散事件et(e1,e2,…,en)值和个性因子ki值;
步骤2观察当前状态st,更新et;
步骤3根据 μt←et(e1,e2,…,en)更新情感输出值;
步骤4使用行动选择规则选择出环境模型中记录的经验知识引发积极情绪的状态st动作at:

步骤5得到回报率r(st,at),同时观察下一个状态st+1;
步骤6根据式(3)更新Qt(st,at)函数值;
步骤7更新状态st到st+1状态;
步骤8如果满足学习结束条件,则转到步骤9,否则转到步骤2;
步骤9结束。
基于人工情感改进的Q-学习算法描述的程序实现流程如图2所示。

图2 改进的Q-学习算法程序流程图Fig.2 Flow chart of improved Q-learning algorithm
4 改进Q-学习算法在机器人行为决策应用及仿真
4.1 仿真试验描述
机器人的任务是在的二维有障碍的栅格环境中路径寻优,实验环境如图3所示。机器人在环境中的基本动作有上行、下行、左行、右行4种行进动作,图中每个栅格代表机器人的一种状态。其中黑色部分为障碍物,为机器人的起始位置,T1,T2为机器人的目标位置。环境中的所有事物都是静止的,初始时对于机器人而言环境模型是未知的。机器人4个方向上配有探测障碍物的传感器,传感器将环境中每个状态采集的信息记为离散事件 et(e1,e2,…,en)。机器人在行进过程中如果与障碍物或边界相碰,则返回上一状态。实验初始时机器人的目标在T1位置,30个学习周期后,目标变为栅格上的T2位置。

图3 有障碍的二维栅格环境Fig.3 Two-dimensional grid environment barrier
在目标导航任务时,立即回报设计为r={100,-50,-1},每个动作都是正确的,执行后会得-1的奖励(可以理解为消耗),完成导航任务可以获得+100的奖励,如果错误的执行了基本动作则将得到-50的奖励(相当于惩罚)。折扣因子γ=0.9,学习效率η=0.1。
4.2 仿真试验结果分析
实验仿真结果如图4所示。实验开始的前30个学习周期,机器人使用带情感系数的Q-学习算法,但不启用情感输出系数,此时用常数代替情感系数μt,故其算法过程同利用环境模型的Q-学习算法一样。此后的30个学习周期(即第31个学习周期开始),机器人分别使用利用环境模型的Q-学习算法和基于情感模型改进的Q-学习算法,依次完成二维有障碍的栅格环境中路径寻优任务。

图4 实验仿真结果Fig.4 Experimental simulation result
实验仿真结果可见第15个学习周期,2种学习算法的收敛性趋于平稳,第30个学习周期时已经收敛到最优。在图4中可以看出机器人的目标改变后(第31学习周期开始),需要消耗很多的步数到达新的目标,这是因为前期获得的经验知识使机器人再次移动到原来的目标T1。路径S→T1→T2不是最佳的寻优路径,所以机器人再次重新尝试新的策略。在第30到第40学习周期之间学习策略跃迁较大,直至算法收敛到最优状态。机器人路径寻优目标T1的最优策略回报为Vπ*(s1)=89,目标 T2最优策略回报为Vπ*
(s2)=86。为了进一步研究2种学习算法的收敛情况,利用最小二乘法对32到45周期内的离散数据进行3次多项式曲线拟合,得到的结果如图5所示。

图5 最小二乘法曲线拟合结果Fig.5 Least squares curve fitting result
从图5的仿真结果不难看出,加入情感决策的Q-学习算法在第37学习周期趋于收敛到最优策略,而利用环境模型的Q-学习算法在第42学习周期趋于收敛到最优策略,由此说明前者用了较少的学习时间使算法收敛。2种学习算法的拟合曲线结果显示,在32到38周期内改进Q-学习算法的曲线斜率要大于利用环境模型的Q-学习算法的拟合曲线斜率,也就是说前者较后者在最优控制策略的学习收敛速度快。
虽然标准Q-学习算法利用环境模型较多的经验知识,缩短了机器人的学习周期,但是在线完善环境模型消耗较长时间。而本文提出的基于情感模型的Q-学习算法充分利用了情感决策,使机器人在线学习过程中动作的选择由情感因素调控,而非单纯的知识推理和逻辑判断方法,加快了机器人在线完善环境模型的收敛速度。
5 结语
本文在基于环境模型的Q-学习算法基础上引入情感行为决策,通过利用人类情感产生的趋利避害生存机理,来强化执行任务过程中有利的经验信息,加快机器人在线完善环境模型的收敛速度。此外,降低了机器人在庞大的求解空间中盲目试错的次数,缩短了机器人的学习时间。实验仿真结果证明了该算法可以提高机器人的自主决策及学习能力,验证了该算法的有效性和实用性。将人工情感与人工智能相结合,设计出更智能化和拟人化的机器人,是智能及和谐机器人的发展趋势。
[1]王志良.人工心理与人工情感[J].智能系统学报,2006,1(1):38-43.
[2]王国江,王志良,杨国亮,等.人工情感研究综述[J].计算机应用研究,2006(11):7-11.
[3]张迎辉,林学誾.情感可以计算—情感计算综述[J].计算机科学,2008,35(5):5-8.
[4]Mochida T,Ishiguro A,Aoki T,et al.Behavior arbitration for autonomous mobile robots using emotion mechanisms[C]//IEEE/RSJ International Conference on Intelligent Robots&Systems 95 Human Robot Interaction&Cooperative Robots,1995:516-521.
[5]LeDoux J,Bemporad J R.The emotional brain[J].Journal of the American Academy of Psychoanalysis,1997,25(3):525-528.
[6]王为.基于情感计算的机器人学习系统研究[D].浙江:浙江工业大学,2009.
[7]王飞,王志良,赵积春,等.基于随机事件处理的情感建模研究[J].微计算机信息,2005(3):101-102.
[8]王雪松,程玉虎.机器学习理论方法及应用[M].北京:科学出版社,2009:56-57.
[9]高阳,陈世福,陆鑫.强化学习研究综述[J].自动化学报,2004,30(1):86-100.
[10]张汝波.提高强化学习速度的方法研究[J].计算机工程与应用,2001(22):38-40.
猜你喜欢
纺织科学研究(2021年9期)2021-10-14
小学生作文(低年级适用)(2019年5期)2019-07-26
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
读友·少年文学(清雅版)(2018年12期)2018-04-04
山东青年(2016年3期)2016-02-28
少儿科学周刊·少年版(2015年4期)2015-07-07
少儿科学周刊·少年版(2015年4期)2015-07-07
少儿科学周刊·少年版(2015年4期)2015-07-07
军事历史(1997年5期)1997-08-21
军事历史(1991年5期)1991-08-16
