
利用2-hop随机游走进行异质网络社区发现
2015-02-18 08:01杨海陆张健沛杨静
哈尔滨工程大学学报 2015年12期
杨海陆, 张健沛, 杨静
(1.哈尔滨理工大学 计算机科学与技术博士后流动站,黑龙江 哈尔滨150080; 2.哈尔滨理工大学 计算机科学与技术学院,黑龙江 哈尔滨150080; 3.哈尔滨工程大学 计算机科学与技术学院,黑龙江 哈尔滨150001)
利用2-hop随机游走进行异质网络社区发现
杨海陆1,2,3, 张健沛3, 杨静3
(1.哈尔滨理工大学 计算机科学与技术博士后流动站,黑龙江 哈尔滨150080; 2.哈尔滨理工大学 计算机科学与技术学院,黑龙江 哈尔滨150080; 3.哈尔滨工程大学 计算机科学与技术学院,黑龙江 哈尔滨150001)
摘要:针对异质社交网络社区识别问题,提出一种基于随机游走层次社区识别算法。提出异质网络层级吸引力度量函数,构建异质网络随机游走模型;设计了一种基于2-hop互随机游走的异质网络节点相似性度量函数;通过将该相似性函数推广到层次聚类并设计相应的相似矩阵校准方案,异质社区识别任务可以在较短的时间内迭代完成。人工合成网络和真实网络上的仿真实验验证了算法的可行性和有效性。
关键词:异质社交网络;社区识别;随机游走;相似性度量;层次聚类
网络出版地址:http://www.cnki.net/kcms/detail/23.1390.u.20151106.1328.018.html

张健沛(1956-),男,教授,博士生导师.
社区识别是社会计算领域重要的研究内容。总体上讲,社区结构是一种介于宏观和微观之间的特殊结构[1],它是网络节点的一种聚集形式,使得社区内部链接密度高于社区间的链接密度。社区的量化形式是模块度函数[2],以模块度为优化目标的社区识别是当前最热门的方法之一,但精准求解模块度最大的社区划分是NP-完全问题[3],因此现有研究多采用启发式方法[2-4]解决这一技术难点。除此之外,统计推理[5]、多目标优化[6]、图分割[5]等方法同样能够有效的挖掘复杂网络中的社区结构。
传统的社区识别研究通常假定社会网络中只含有一种社会关系,然而在真实的网络环境下,节点间通常是多种关系协同交互,由此构成了维度更高的异质社会网络。异质社会网络社区识别旨在从多种社会关系中识别出隐含的社区结构。目前这一领域的研究成果较少,并缺乏长期且系统化的研究体系。Mucha等[7]提出异质社区模块度函数,并将之用于分析美国东北部某大学在校学生以4种社会关系构成的异质关系网络。Radicchi[8]证实了基于模块度函数挖掘异质社区的可行性,并给出基于模块度优化挖掘异质社区的必要条件。文献[9-10]选择将传统的数据挖掘方法推广到异质网络,但由于异质系统各子网通常波动较大,因此这类方法识别的社区通常不具有现实意义。文献[11-13]将异质数据映射至低维空间进行社区识别,但这种方法通常会造成信息损失。Tang等[14]将单质网络社区挖掘分为4个子目标进行优化,设计了一种异构目标整合策略,并以新目标作为优化对象完成社区挖掘任务。
归纳而言,挖掘异质社区的难点主要在于各子网内部链接模式不同且分布不均匀,因此需要一种新的节点局部相似性度量方法。此外,异质社会网络具有数据量大、数据维度高等特点,因此算法普遍时间开销过高,挖掘效率较低。为解决上述问题,本文提出一种基于随机游走的异质社区识别方法,该方法模拟了社交节点在异质系统中的自然选择过程,不仅可以避免子系统链接的分布波动,同时具有较高的运行效率。
1随机游走的基本概念
在统计学中,随机游走的基本原理是从一个或多个节点开始遍历全图,对于任意节点而言,“游走者”将以转移概率Pt随机跳跃到图中任何一个与其距离为t的节点。用di表示节点i的邻居数,Aij为图的邻接矩阵,σ[u1~uk]={u1,u2},…,{uk-1,uk}⊂E表示一条从节点u1到节点uk的路径,则“游走者”在任意节点的转移概率为Puk,uk-1=Auk,uk-1/duk,进而有节点u1到节点uk的游走概率为
(1)
(2)
这说明节点u1到节点uk和节点uk到节点u1的游走概率并不相同,与各自的出发节点度成正比。
对于任意具有强社区结构的图来讲,由于社区内部的链接较为稠密,因此当“游走者”游走到社区边缘时有极大的概率再次回到社区内部。这说明社区内部节点之间的游走可达概率相对较高,而分属于不同社区的节点具有较低的游走概率。根据这一原理,通过度量节点或社区之间的游走可达概率,量化节点或社区之间的相似程度,进而合并相似性较高的节点或社区为新社区。
2基于随机游走的节点相似性度量


2.1 多关系社会网络随机游走模型

(3)

(4)
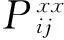
(5)
进而可知异质社交网络任意两节点间的游走概率(即任意层任意节点间的游走的概率)为
(6)


图1 异质社会网络上的随机游走Fig.1 Random walks in heterogeneous social networks

(7)
2.2 节点相似性度量
在获得异质网络随机游走模型后,对游走路径施以2-hop约束以度量节点间的相似程度。首先定义以下3种条件约束:
约束1:如果节点u和节点v在同一社区,则u到v的可达概率必定很高,但是u到v的可达概率很高并不意味着节点u和节点v必定在同一社区。
约束2:最小化社区内部节点的互可达性差异,如果节点u和节点v在同一社区,则u到v的可达概率与v到u的可达概率彼此接近,即Puv≈Pvu。
约束3:同一社区内的2个节点之间的最大可达路径为2-hop路径。
之所以将游走路径约束在2-hop以内,是由于1-hop路径和2-hop路径能够捕获节点间的直接相似性和结构相似性。然后,设计了一种以直接相似性为主导的权衡式,当节点间不具备1-hop路径时,适当的为其添加2-hop可达概率,进而可得x层节点i到节点j实际的可达概率为
(8)

(9)
如图1所示,节点(d,L1)与节点(b,L1)不具有直接链接,因此(d,L1)到(b,L1)的1-hop可达性为0。通过观察发现(d,L1)与(b,L1)之间存在2-hop路径{(d,L1),(a,L1)},{(a,L1),(b,L1)},根据式(8)可得节点实际的可达概率为δ(d,L1),(b,L1)=1/d(d,L1)d(a,L1)=1/9。
结合2.2节定义的3类随机游走约束,设计了基于游走可达概率的节点相似性度量函数。在式(10)中,分子部分保证社区内部节点具有较高的游走概率,而分母作为惩罚因素,降低了互可达差异过大的节点存在于相同社区的可能性。
(10)
2.3 社区相似性度量
通过简单的扩展即可将节点相似性度量扩展至社区相似性度量。节点i与社区C之间的可达性定义为i与C内部所有节点可达概率的平均值,即
(11)
(12)
同理可定义社区之间的可达性为
(13)
3异质社区的层次聚类算法
上节所讨论的相似性度量方法使得具有较高互可达性的节点具有较高的相似程度。这种方式从全局的角度来看实际上保证了社区边缘节点的入度大于出度。不同于Newman等[2]提出的基于割边的层次社区检测算法,本文采用了一种贪婪的层次化聚类策略。具体为:1)将每个节点视为独立的划分结果;2)迭代选择相似性最大的2个划分进行合并,直至形成一个单一划分,合并过程形成层次化树;3)在层次化树中,选取模块度值最大的划分方式作为最终的社区发现结果。
3.1 社区合并选择
上述策略中,社区合并后相似矩阵必然发生变化。直观上讲,如果每次合并操作后都重新计算该矩阵,势必造成过高的计算开销。借鉴文献[15]的思想,本文将“寻找相似矩阵最大元素”问题,转化为“合并社区后,新社区内部节点相似程度改变最小”问题。因此,通过对相似性改变矩阵进行局部校准,避免迭代过程中的冗余计算。
在聚类分析中,相似性的改变被描述为最小化新聚簇与中心点的平方距离,即
(14)
本文在合并社区的过程中遵循这样一种启发式思想:合并操作只发生在相邻的社区之间(合并不相邻的社区会使社区内部链接过于稀疏)。因此如果社区C1和C2合并为新社区C3=C1∪C2,可得C3内部节点的相似性改变程度为
(15)

(16)
将式(16)代入式(15)并参照式(12)可得新社区C3内部节点最终的相似性改变量为
(17)
对式(17)进行整理,可得C3与其邻接社区C之间的相似性改变量为
(18)
因此,算法在迭代过程中采用式(18)对相似性改变矩阵进行局部校准,而无需对所有元素重新计算,可见这种局部选择策略具有较高的效率。
3.2 输出质量最优的社区划分结果
算法的迭代过程最终会生成层次化树,为了获得最优的社区结构,本文采用Mucha等[7]提出的异质模块度函数度量社区质量,具体为
(19)
由于篇幅限制,式中各参数不做过多介绍。需要说明的是,参数γs为层级Ls的分辨率参数,在实验中该值采用文献[7]的默认设置,即γs=1。
3.3 基于多层随机游走的异构社区挖掘算法
基于随机游走的异构社区挖掘算法MLW(multi-layerwalker)采用一种贪婪思想,伪代码如算法1所示。
算法1异构网络社区挖掘算法MLW
1) 根据式(13)、(17)计算相似改变矩阵ξ;

4)选定Δζ最小的社区Ca,Cb∈C;
5)Ck←Ca∪Cb;
8)使用式(18)校准矩阵Δζ;
9)删除矩阵行列a,b并添加行列k;
10)endwhile
11)Ctree={C1,C2,…,CH};
12)CP=argmaxCi∈CtreeQM(Ci);
13)returnCP.
算法在计算相似性改变矩阵时,最复杂的是计算2-hop路径中转节点。中转节点的邻接情况与平均节点度成正比,因此时间开销为O(n2d)=O(mn)。循环次数为层次树的高度H。由于合并操作的最小量级为节点,因此H≤N。算法选择邻接社区进行合并,因此循环部分的复杂度为O(d)≤O(n)。可见算法1最终的时间复杂度为O(mn+dH)=O(mn)。
4实验结果与分析
本节将给出算法在人工合成数据集和真实数据集上的运行结果。实验的运行环境为IntelPentiumIV3.0GHz处理器,2GB内存,WindowsXP操作系统,算法采用C++与MATLAB7.1混合编程。选择Dong等[13]提出的SC-ML(spectralclusteringonmulti-layergraphs)算法以及Tang等[14]提出的LBSM(latentblockspectralmodularity)算法进行比对。前者是1种新的多层级聚类算法,后者采用多目标优化并被认为具有较高的社区识别精度。
4.1 人工合成网络社区挖掘性能
人工合成网络在生成时可根据相应的规则生成一些“固有存在”的社区(Ground-truth),因此与固有社区之间的差距越小则所提出的算法性能越优。本文用归一化互信息(normalizedmutualinformation,NMI)[16]度量2种划分结果之间的差别,其定义为
(20)
当划分CA与CB完全一致时NMI(CA,CB)=1,当划分CA与划分CB完全不同时NMI(CA,CB)=0。
实验1利用文献[14]提供的MATLAB人工数据生成器,生成含有350个节点,4种不同社会关系的异质社会网络,其中内含3个Ground-truth社区,每个社区约含50,100以及200个节点。
如图2所示,在分别标记为L1~L4的单质网络中,3种算法的NMI指数平均约为0.8(MLK)、0.74(LBSM)以及0.72(SC-ML),可见本文算法所得的社区结果与Ground-truth社区更为接近,因此具有较高的性能。当处理对象为异构网络时(在本文中被标记为LM),由于异质关系的纠缠特性,3种算法普遍所得NMI值较低。在本情况中,MLW算法的NMI指数约为0.65,平均超出LBSM和SC-ML约24%,这说明本文提出的异构随机游走方案是有效的,能够真实的挖掘异构网络潜在的社区结构。

图2 人工合成网络性能比较(数据源自文献[14])Fig.2 Performance comparison of synthetic datasets (data comes from [14])
实验2人工合成数据集LFRBenchmark[16]。本实验考察子网络链接关系波动较大时各算法的表现。首先生成了2个具有5 000个节点的单质网络,然后以此为基础,通过随机添加或删除链接来获得4种不同的社会关系,其中各子网的链接改变量(networkrandomchange,NRC)分别为NRC=200和NRC=2 000。实验结果在图3和图4中给出。
通过分析发现,当网络改变量较小时(图3),各算法的性能与实验1类似;但网络变化较大时(图4),MLW算法的优势逐渐变得明显。这主要是由于:SC-ML算法和LBSN算法采用了模型生成的方法,因此当网络变化较大时,该方法使得构建的新网络与各子网之间的差距都很大,因此偏离了真实社区所具有的表现形式。
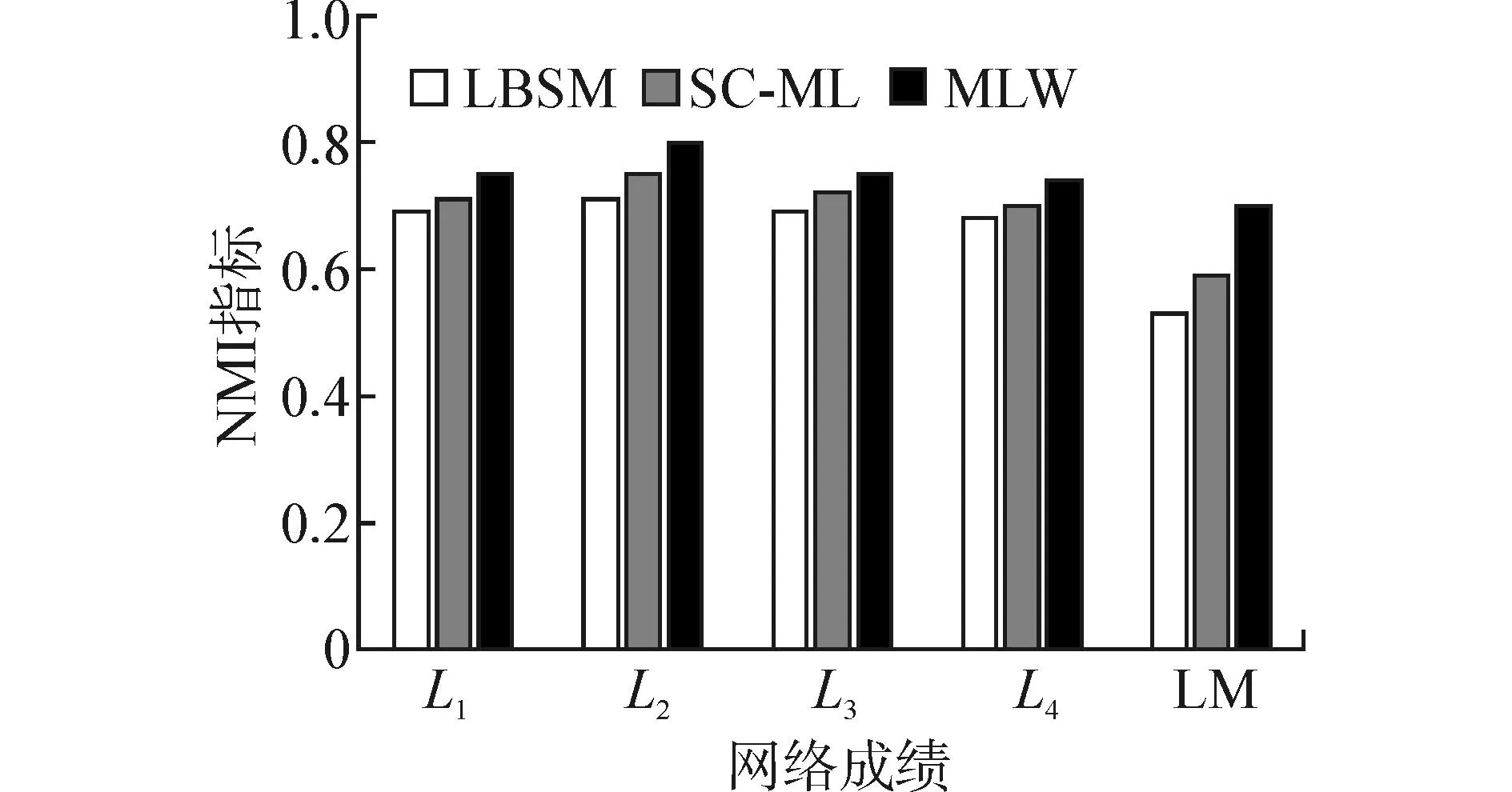
图3 人工合成网络性能比较(LFR Benchmark,NRC=200)Fig.3 Performance comparison of synthetic datasets (LFR Benchmark, NRC=200)

图4 人工合成网络性能比较(LFR Benchmark,NRC=2 000)Fig.4 Performance comparison of synthetic datasets (LFR Benchmark, NRC=2 000)
实验3LFRBenchmark运行效率分析。本节考察MLW在不同规模网络上的运行效率,用LFRBenchmark生成了8个节点个数从1 000~8 000不等的网络结构。如图5所示,MLW算法的运行时间随着数据集规模的增大近似呈线性增长,算法在节点数为8 000时运行时间约为7.2s。实际上MLW算法在网络规模不断变大的情况下竞争力更强,这是因为虽然算法在计算初始相似改变矩阵时占据了部分时间,但后续的运行仅需校准原矩阵。可见MLW算法在规模较大的数据集上也可以令人满意的时间开销挖掘网络中的社区结构。

图5 各算法的运行时间Fig.5 The runtime of the different algorithms
4.2 真实网络社区挖掘性能
实验4DBLP数据集。来源于2000~2010年计算机科学权威会议网站,按会议等级从中抽取了13个不同的学科领域(如表1所示),将其压缩为约35个会议、18 000个学者和10 000篇文献。本文将研究者作为网络节点,将13种研究领域作为节点间的异构链接,进而生成了异构关系图。真实网络不存在Ground-truth社区,因此本实验主要考察算法的模块度(文献[7])和运行效率。
图6的横坐标标记各领域的类别,合成后的异构网络用NM加以标识。MLW算法具有最高的模块度指标,而LBSM和SC-ML算法则模块度相对较低。这主要是由于这2种算法在社区识别的过程中忽略了各子网间节点的吸引力。LBSM采用了模块度优化,因此略胜于SC-ML。此外SC-ML算法将相似程度较低的领域整合为同一网络也是其模块度较低的原因。在运行时间方面,LBSM和SCML需要大量的准备工作,因此时间开销较大。相比之下,MLW除在算法初期需要计算相似改变矩阵外,其他过程均为校准操作,因此具有较高的效率。

表1 13种会议领域清单Table 1 The details of 13 conferences

(a) 模块度

(b)运行时间图6 DBLP网络各算法性能比较Fig.6 Performance comparison on DBLP networks

如图7所示,由于该数据集的社区结构不是十分明显,因此3种算法模块度均较低。相比之下MLW算法约超出LBSM算法和SC-ML算法12.3%和22.1%。在社区个数方面,由于MLW算法充分考虑了各子网间的吸引程度,因此稳定性较强,从图7(b)中可以看出,MLW始终能够保持识别的社区个数为3,而LBSM和SC-ML则波动较大。不同的是LBSM在单质网络上较为稳定,但网络合成为异构网络时,由于其多目标的优化策略,因此识别出的社区数大于Ground-truth社区数。与之相反,SC-ML选择在合成后的网络上进行社区识别,因此当处理对象为异构网络时,准确率提高。

(a)模块度

(b)社区个数图7 Iris数据网络各算法性能比较Fig.7 Performance comparison on Iris data networks
5结束语
本文提出一种基于随机游走的异质社区识别算法,重要研究了随机游走在异质网络中的跨层级游走特性。首先设计了节点的同社区互可达游走约束,进而提出异质网络节点相似性度量函数;然后基于贪婪的层次化聚类算法将相似性较高的节点合并为同一社区。由于算法在迭代过程中采用了局部化的校准策略,因此具有较低的时间开销。在今后的工作中,将重点研究动态社交网络中的异质社区识别方法,实现对真实世界的精准感知。
参考文献:
[1]XIE J, KELLEY S, SZYMANSKI B K. Overlapping community detection in networks: the state of the art and comparative study[J]. ACM Computing Surveys, 2013, 45(4): 43.
[2]NEWMAN M E J, GIRVAN M. Finding and evaluating community structure in networks[J]. Physical Review E, 2004, 69(2): 026113.
[3]BRANDES U, DELLING D, GAERTLER M, et al. On modularity clustering[J]. IEEE Transactions on Knowledge and Data Engineering, 2008, 20(2): 172-188.
[4]邓琨, 张健沛, 杨静. 利用改进遗传算法进行复杂网络社团发现[J]. 哈尔滨工程大学学报, 2013, 34(11): 1438-1444.DENG Kun, ZHANG Jianpei, YANG Jing. Community detection in complex networks using an improved genetic algorithm[J]. Journal of Harbin Engineering University, 2013, 34(11): 1438-1444.
[5]DUAN Lian, STREET W N, LIU Yanchi, et al. Community detection in graphs through correlation[C]//Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York,USA, 2014: 1376-1385.
[6]LIU Chenlong, LIU Jing, JIANG Zhongzhou. A multiobjective evolutionary algorithm based on similarity for community detection from signed social networks[J]. IEEE Transactions on Cybernetics, 2014, 44(12): 2274-2287.
[7]MUCHA P J, RICHARDSON T, MACON K, et al. Community structure in time-dependent, multiscale, and multiplex networks[J]. Science, 2010, 328(5980): 876-878.
[8]RADICCHI F. Detectability of communities in heterogeneous networks[J]. Physical Review E, 2013, 88(1): 010801.
[9]DONG Xiaowen, FROSSARD P, VANDERGHEYNST P, et al. Clustering with multi-layer graphs: A spectral perspective[J]. IEEE Transactions on Signal Processing, 2012, 60(11): 5820-5831.
[10]BERLINGERIO M, PINELLI F, CALABRESE F. ABACUS: frequent pattern mining-based community discovery in multidimensional networks[J]. Data Mining and Knowledge Discovery, 2013, 27(3): 294-320.
[11]YIN Qiyue, WU Shu, HE Ran, et al. Multi-view clustering via pairwise sparse subspace presentation[J]. Neurocomputing, 2015, 156: 12-21.
[12]FIORI S, KANEKO T, TANAKA T. Tangent-bundle maps on the Grassmann manifold: Application to empirical arithmetic averaging[J]. IEEE Transactions on Signal Processing, 2015, 63(1): 155-168.
[13]DONG Xiaowen, FROSSARD P, VANDERGHEYNST P, et al. Clustering on multi-layer graphs via subspace analysis on Grassmann manifolds[J]. IEEE Transactions on Signal Processing, 2014, 62(4): 905-918.
[14]TANG Lei, WANG Xufei, LIU Huan. Community detection via heterogeneous interaction analysis[J]. Data Mining and Knowledge Discovery, 2012, 25(1): 1-33.
[15]PONS P, LATAPY M. Computing communities in large networks using random walks[J]. Journal of Graph Algorithms and Applications, 2006, 10(2): 191-218.
[16]LANCICHINETTI A, FORTUNATO S. Benchmarks for testing community detection algorithms on directed and weighted graphs with overlapping communities[J]. Physical Review E, 2009, 80: 016118.
Community detection in heterogeneous
social networks using 2-hop random walks
YANG Hailu1,2,3, ZHANG Jianpei3, YANG Jing3
(1. Computer Science and Technology Postdoctoral Workstation, Harbin University of Science and Technology, Harbin 150080; 2. College
of Computer Science and Technology, Harbin University of Science and Technology, Harbin 150080, China; 3. College of Computer Science and Technology, Harbin Engineering University, Harbin 150001, China)
Abstract:In order to solve the problem of identifying community structures in heterogeneous social networks, a hierarchical community detection algorithm was proposed based on random walks. A heterogeneous random walk model was built by measuring the attraction between network layers and the transition probability between nodes in homogeneous networks. Then, a heterogeneous network node similarity function was proposed based on 2-hop mutual random walks. Finally, the similarity function was extended to hierarchical clustering so the multi-relational community structure could be obtained iteratively in a relatively short period of time. Competitive experiments on both synthesized and real-world social networks demonstrate the effectiveness and feasibility of the proposed algorithm.
Keywords:heterogeneous social networks; community detection; random walks; similarity measurement; hierarchical clustering
通信作者:张健沛,E-mail:zhangjianpei@hrbeu.edu.cn.
作者简介:杨海陆(1985-),男,讲师;
基金项目:国家自然科学基金资助项目(61202274,61370083,61402126);高等学校博士学科点专项科研基金资助项目(20112304110011,20122304110012).
收稿日期:2014-11-03.网络出版日期:2015-11-06.
中图分类号:TP301.6
文献标志码:A
文章编号:1006-7043(2015)12-1626-06
doi:10.11990/jheu.201411008
