
基于多级图划分的协同过滤算法研究
2015-02-20 08:20柳先辉徐梦锦
机械设计与制造工程 2015年12期
柳先辉,徐梦锦
(同济大学电子与信息工程学院CAD研究中心,上海 201804)
基于多级图划分的协同过滤算法研究
柳先辉,徐梦锦
(同济大学电子与信息工程学院CAD研究中心,上海201804)
摘要:为克服传统协同过滤推荐算法中存在的局限性,提出了基于多级图划分的协同过滤推荐算法。该算法在对系统中存在的产品使用多级图划分算法进行聚类的基础上应用协同过滤推荐算法对用户进行推荐。实验结果证明,该算法可以在对推荐准确率影响较小的同时有效提高推荐系统的效率。
关键词:协同过滤;多级图划分;聚类
推荐算法作为一种信息过滤技术,已经成为当下解决互联网上信息过载的一种有效工具[1]。在众多推荐方法中,协同过滤是推荐系统中应用最为成功的技术之一[2]。采用协同过滤推荐技术的应用十分广泛,其中Tapestry[3]是最早的推荐系统之一,系统记录每个用户阅读文章的观点,并根据这些观点对用户进行推荐。典型的个性化推荐系统包括Amazon[4]购书推荐、Ebay的购物推荐、MovieLens的电影推荐等。
协同过滤系统普遍存在3大问题:数据稀疏性、冷启动和可扩展性。为了提高系统的推荐精度,国内外学者提出了许多改进的启发式推荐算法。Park等[5]通过将协同过滤与搜索工具相结合提升了雅虎推荐结果的准确度;Koren等[6]提出了基于矩阵分解技术的推荐算法,可以有效提高推荐质量;Sandvig等[7]将数据挖掘技术与协同过滤算法相结合,提出一种基于关联规则挖掘的协同过滤算法,以降低推荐精度为代价获得了较强的鲁棒性。随着大数据时代的到来,协同过滤系统所需处理的数据急剧增多,可扩展性已成了限制协同过滤系统发展的主要因素,本文提出的基于多级图划分的协同过滤推荐算法可以有效解决系统的可扩展性问题,并减少系统的运行时间,能满足对实时性要求较高的系统的需求。
1协同过滤推荐算法
协同过滤的基本假设是如果用户x和y对n个产品的评价或行为是相似的,那么他们对其他产品所持有的观点很可能也是相似的。其具体说明如下:假设有用户集合U={u1,u2,…,un},产品集合C={c1,c2,…,cm},ru,c表示用户u对项目c的评分,由ru,c构成的矩阵表示用户对应产品的行为数据,称为用户-产品(user-item)矩阵[8-9]。算法首先根据用户以往的打分记录计算用户之间的相似度进而得出该用户的邻居用户。常用的相似度计算方法有Pearson相关和矢量余弦。
Cx和Cy分别为用户x和用户y评价过的项目集,Cxy=Cx∩Cy,表示用户x和用户y共同评分过的项目的集合,则用户x和用户y之间的相似度计算方法如下[10]:
1)Pearson相关。
(1)
2)矢量余弦。
(2)
相似度计算完成后,系统进行预测,计算完成的相似度一般作为权重使用,常用的计算方法有以下两种[11-13]:

1)简单加权平均。
(3)
2)改进的加权平均——评分差加权平均。
(4)

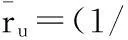
(5)
式中:Cu={c∈C|ru,c≠0}。在实际应用中,为了减少系统的计算量,通常选取相似度排名前k的用户作为邻居用户进行计算,其中k称为活动用户的邻居规模。
2基于多级图划分的协同过滤算法
现有的面向聚类的推荐算法一般都是根据产品的描述信息对产品进行分类,如Usenet[14],它将新闻根据内容分为不同的类别,如对于处于幽默类别中的用户组只对其推荐处于幽默分类下的新闻。但是在实际应用中,可以用于分类的产品信息往往不容易获得[15],并且针对不同的推荐,需要应用不同的基于内容的分类算法来对产品进行分类。笔者使用多级图划分算法对产品进行聚类,该算法使用产品的相似度矩阵作为聚类依据,可以很方便地用于各种协同过滤推荐系统中而不需改变原有算法。
2.1 多级图划分算法
对图的划分是一个NP完全问题,虽然现有的很多算法都对图的划分提出了解决方案,但大多数算法的时间复杂度都很高,或者划分较粗糙,多级图划分算法在缩短运行时间的基础上依旧能得到较好的划分,是现今应用广泛的图划分算法。
多级图划分算法在满足相应目标函数的基础上将图划分为大致相等的k部分,其基本过程如下(如图1所示)。首先通过简化(coarsening)阶段,将图G0的边和顶点进行合并,依次得到图G1,G2,…,Gm,其中图Gm为一个拥有原图特性的但只有很少的顶点的最简图;然后在满足图划分目标函数的情况下将小图Gm平均划分成大致相等的k部分,存储在Pm中,Pm为存储各个顶点所属类别的向量;最后将Pm经过投射依次还原成中间划分Pm-1,Pm-2,…,P0,并且在每一个中间阶段根据目标函数重新调整划分,使其划分更精确,其中P0为图G0所对应的原划分[16-18]。

图1 多级图划分基本原理
用于限制划分的目标函数一般为最小化边割(edge-cut),其中划分的边割为图中跨越不同分区的边的权值之和。
2.2 算法设计
基于多级图划分的协同过滤算法,首先依据产品之间的相似性使用多级图划分算法对产品进行聚类;然后根据用户以往的购买记录计算出用户购买最多的产品属于哪一类别,并在该类别的产品中计算用户之间的相似性;最后根据邻居用户的购买喜好对该用户进行推荐(如图2所示),其具体流程如下:
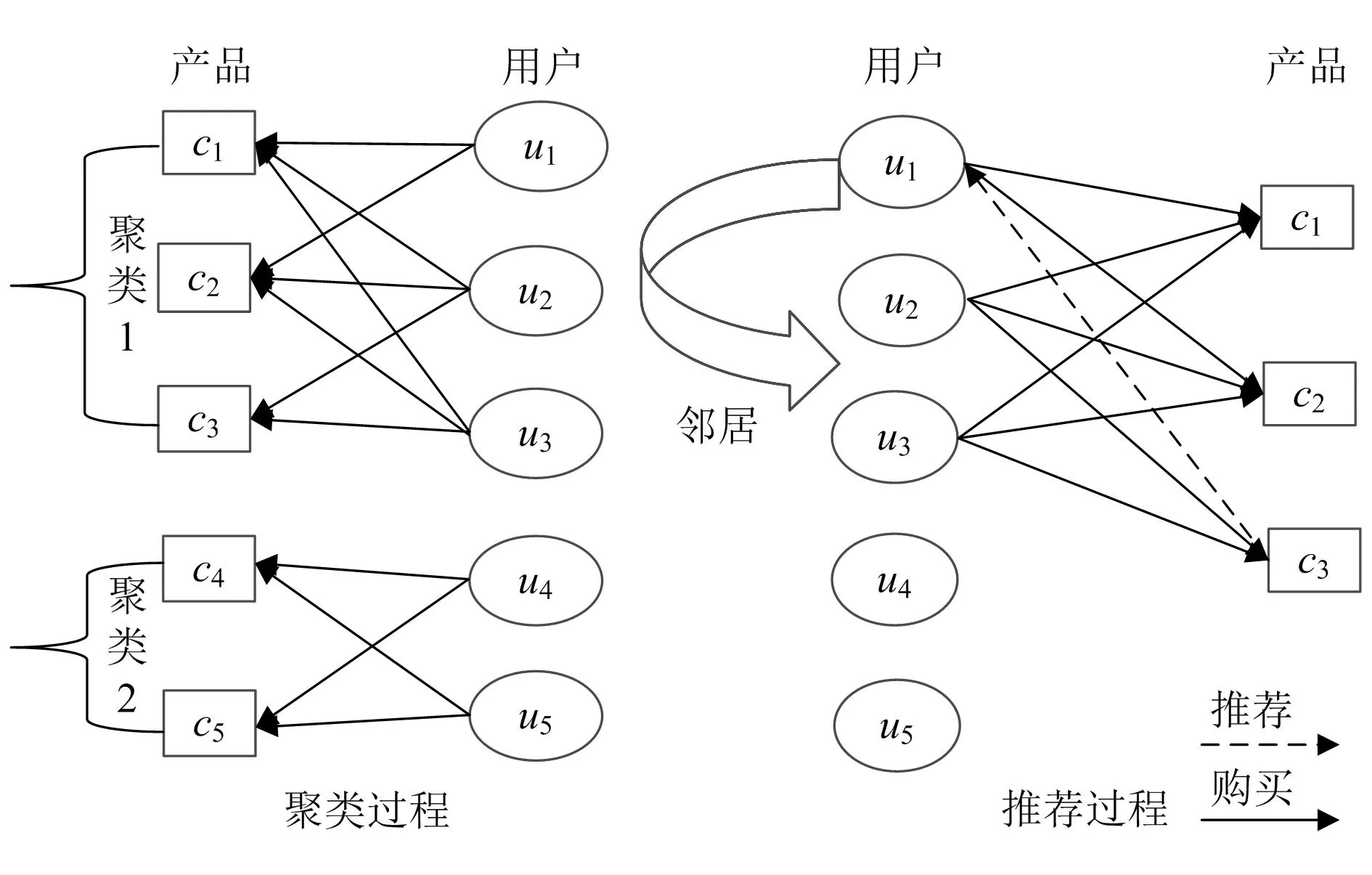
图2 算法设计
第1步,根据原有数据集构建产品-用户矩阵,使用式(6)计算产品的相似度矩阵[4]。
sim(i,j)=
(6)

第2步,将产品的相似度矩阵作为多级图划分算法的输入,即为多级图划分算法中的原图G0(图的数学表达形式为矩阵)。
第3步,找到图G0中的极大匹配(maximal matching)并将匹配中的顶点合并成超顶点(multinode),得到简化后的图G1。其中图的匹配是任意两条边不存在共同顶点的边的集合。
第4步,重复第3步,使图经过G2,G3,…,Gm-1最终得到最简图Gm。
第5步,将最简图Gm在满足最小化边割的要求下划分成k部分,划分的结果存储在向量Pm中,Pm为存储图中各个顶点所属类别的向量。

第7步,调整投射后的划分Pm-1,移动各个分区中的顶点使Pm-1满足最小化边割的要求。
第8步,重复第6、第7步,经过Pm-2,Pm-3,…,P1最终得到存储原图G0划分结果的向量P0。
第9步,对要做出推荐的用户u,首先根据其以往的消费记录统计出用户u在各个产品类别中所消费的产品的数量ni(i∈{1,2,..,k})。
第10步,选取ni排名前2位的产品类别,使用这2个类别的产品构造用户-产品矩阵。
第11步,使用第10步中构造的用户-产品矩阵计算用户u与其他用户的相似度。
第12步,选取相似度排名前k位的用户作为用户u的邻居用户,为每个用户u未消费而其邻居用户已消费的产品使用式(3)计算其预测评分。
第13步,选取预测评分排名前m的产品推荐给用户u。
3实验结果
本实验采用的数据集为movielens网站提供的由943个用户对1 682部电影的100 000条评分记录。实验中使用多级图划分算法将产品分为8类,邻居用户数目为20,为每个用户推荐10个产品,并根据测试数据计算推荐的命中率。在不同大小的测试集上运行的结果如图3,4所示。
从图3、图4中可以看出,基于产品聚类的协同过滤推荐算法虽然在命中率上与原有的协同过滤算法存在轻微差距,而其运行时间比原有的算法少很多,并且随着测试集的加大,两者之间命中率的差距在减少,而运行时间的差距在拉大,说明基于产品聚类的协同过滤推荐算法的稳定性较高、系统伸缩性好。

图3 算法命中率随测试集大小变化曲线

图4 算法执行时间随测试集大小变化曲线
4结束语
本文提出的基于多级图划分的协同过滤推荐算法相对于原有算法,能够在算法性能上获得较大的提高,并且只对算法的准确率产生轻微影响,同时算法在稳定性上有提升,在实时推荐的系统中具有较好的应用前景。
参考文献:
[1]许海岭,吴潇,李晓东,等.互联网推荐系统比较研究[J].软件学报,2009,20(2):350-362.
[2]Ricci F,Rokach L,Shapira B,et al.Recommender Systems Handbook[M].Berlin:Springer,2011:145-186.
[3]Goldberg D,Nichols D,Oki B,et al.Using collaborative filtering to weave an information tapestry[J].Communications of the ACM,1992,35(12):61-70.
[4]Linden G,Smith B,York J.Amazon.com recommendations: Item-to-item collaborative filtering[J].IEEE Internet Computing,2003,7(1):76-80.
[5]Park S-T,Pennock D M.Applying collaborative filtering techniques to movie search for better ranking and browsing[C]//Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and DataMining.San Jose,California,United States:ACM,2007:550-559.
[6]Koren Y,Bell R,Volinsky C.Matrix factorization techniques for recommender system[J].Computer,2009,42(8):30-37.
[7]Sandvig J,Mobasher B,Burke R.Robustness of collaborative recommendation based on association rule mining[C]//Proc of the 2007 ACM Conf on Recommender Systems.New York:ACM,2007:105-112.
[8]Schafer B,Frankowski D,Herlocker J,et al.Collaborative Filtering Recommender Systems[M].Heidelberg:Springer Berlin,2007:291-324.
[9]Sarwar B,Karypis G,Konstan J,et al.Item-based collaborative filtering recommendation algorithms[C]//Proceedings of the 10th International World Wide Web Conference.New York:ACM,2001:285-295.
[10] 姚曜,赵洪利,杨海涛,等.协同过滤技术研究综述[J].装备指挥技术学院学报,2011, 22(5):81-88.
[11] 黄创光,印鉴,汪静,等.不确定近邻的协同过滤推荐算法[J]. 计算机学报,2010,33(8):1369-1377.
[12] 贾冬艳,张付志.基于双重邻居选取策略的协同过滤推荐算法[J].计算机研究与发展,2013,50(5):1076-1084.
[13] 邓爱林,朱扬勇,施伯乐,等.基于项目评分预测的协同过滤推荐算法[J].软件学报,2002,14(9):1621-1628.
[14] Resnick P,Iacovou N,Suchak M,et al.GroupLens:an open architecture for collaborative filtering of netnews[C]//ACM Conference on Computer Supported Cooperative Work.Cambridge:MIT Center for Coordination Science,1994:175-186.
[15] O′ConnerM,HerlockerJ.Clustering items for collaborative filtering[C]//Proceedings of the ACM SIGIR Workshop on Recommender Systems.Berkeley:UC,1999:128.
[16] KarypisG,Kumar V. Multilevel k-way partitioning scheme for irregular graphs[J]. Journal of Parallel and Distributed Computing,1998,48(1):96-129.
[17] George K,Vipin K.A fast and highly quality multilevel scheme for portioning irregular graphs[J].SIAM Journal on Scientific Computing,1999,20(1):359-392.
[18] Karypis G,Kumar V.Multilevel k-way hypergraphpartitioning[J]. Vlsi Design,1998,11(3):285-300.
Research on collaborative filtering algorithm
based on multilevel k-way graph partitioning
LIU Xianhui,XU Mengjin
(College of Electronic and Information Engineering,
Tongji University, Shanghai, 201804, China)
Abstract:To solve the limitations of the collaborative filtering, it proposes collaborative filtering algorithm based on multilevel k-way graph partitioning. This algorithm uses multilevel k-way graph partitioning to cluster items, predictions are then computed independently within each partition. The experiment shows that this algorithm can greatly improve the efficiency of system by slightly decrease the accuracy of prediction.
Key words:collaborative filtering; multilevel k-way partitioning; clustering
作者简介:柳先辉(1979—),男,浙江丽水人,同济大学讲师,博士,主要研究方向为数据挖掘软件工程。
基金项目:国家科技支撑计划项目(2012BAF12B11)
收稿日期:2015-10-21
中图分类号:TP391.1
文献标志码:A
文章编号:2095-509X(2015)12-0014-04
DOI:10.3969/j.issn.2095-509X.2015.12.004
猜你喜欢
电子测试(2017年15期)2017-12-18
计算机时代(2016年12期)2017-01-14
中国新通信(2016年22期)2017-01-13
软件导刊(2016年11期)2016-12-22
现代情报(2016年11期)2016-12-21
电脑知识与技术(2016年27期)2016-12-15
电脑知识与技术(2016年26期)2016-11-24
光学精密工程(2016年5期)2016-11-07
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
