
基于时间序列方法适配建模分析的卫生支出预测实证研究*
2015-03-09 11:13李望晨王春平张利平
中国卫生统计 2015年2期
李望晨王春平张利平△
基于时间序列方法适配建模分析的卫生支出预测实证研究*
李望晨1,2,3王春平1,2,3张利平1,2,3△
目的探讨几种代表时间序列预测建模原理和适配性能,根据算例分别建立程序和综合比较。方法卫生支出预测算例以ARIMA、GM、SVM和曲线拟合法制定方案,借助MATLAB、SAS等软件实现,讨论性能差异和应用价值。结果ARIMA法通用性好、GM法拟合失效、SVM技术设计待完善、曲线拟合法有限制而应作预分析,数据资料特点影响方法适配性能。结论ARIMA法拟合长较多期随机时序资料有代表意义;GM法适于贫信息小样本资料建模;SVM泛化性能强但滑动窗多试取、结果对参数敏感;曲线拟合法受数据特点、离群数据和建模数据段等条件限制;各法应对特定问题择优取舍。
时间序列 适配比较 程序设计 卫生预测 实证研究
时间序列法以拟合历史资料而惯性延续外推未来,原理性能和信息提取效果受数据量和资料特点限制,而且适于短期预测。当前卫生领域预测问题较代表性统计方法[1-2]包括ARIMA(autoregressive integrated moving average)、GM(grey method)、SVM(support vector machine)和曲线拟合(curve fit)法。但文献检索发现多以方法实现为主,有必要进行综合适配比较研究。
基本原理
1.GM(1,1):根据原始数据序列进行一次累加生成序列该法包括序列累加、建模、识别、检验、外推和累减过程。对随机不规则序列累加生成为规律性序列,建模提取信息拟合和外推,计算残差序列并作可行性检验、残差检验和后验差检验,然后预测应用。
2.SVM:属于基于结构风险最小化原则的数据挖掘技术,解决样本容量依赖、维数灾难、局部极小点问题,根据样本集训练逼近非线性关系,泛化性能优良。根据SVM智能算法原理建立关系模型,进行数据段组成的样本集训练后,映射关系f以“黑箱”存储,可根据新数据段的输入信息仿真外推和预测应用。
3.曲线拟合法:假定序列随时间变化类似某种曲线特点,可建立与时序t的回归曲线y=f(t),应用时还应对曲线类型进行优选。序列预处理后计算增长特征并与曲线理论性质比较:一阶差分ut大致线性时取直线;二阶差分u(2)t大致线性时选抛物线;lgut特征大致线性时取曲线yt=k+abt;lg(lgyt-lgyt-1)特征大致线性时选曲线yt=kgbt,lg(ut/ytyt-1)特征大致线性时取曲线yt=k/(1+ae-bt)。以特征线性显著择优适配相应曲线,常以与时序t相关系数r优选。优选并识别模型参数后,可将时序t代入表达式拟合或外推计算yt。
4.ARIMA:
基本步骤包括定阶、识别、检验和应用。序列趋势性时应差分实现平稳化。自相关系数q阶截尾则拟合MA(q)模型,偏自相关系数p阶截尾则拟合AR(p)模型,两种相关系数均拖尾则拟合ARIMA(p,q)模型,可根据AIC、SBC信息量选择最佳模型,经条件最小二乘法识别参数。该法以序列低阶差分后的平稳序列建模,提取长期序列变化信息,已成为随机时间序列经典方法,算法复杂成熟。
实证分析
本文拟借助卫生支出算例进行实证比较和适配论证。以1990-2011年医疗卫生服务支出数据为例,资料来自《中国卫生统计年鉴》,数据平滑变化、规律性强、资料连贯丰富、有趋势性,早期长时线性增长而近期起伏显著,见图1:
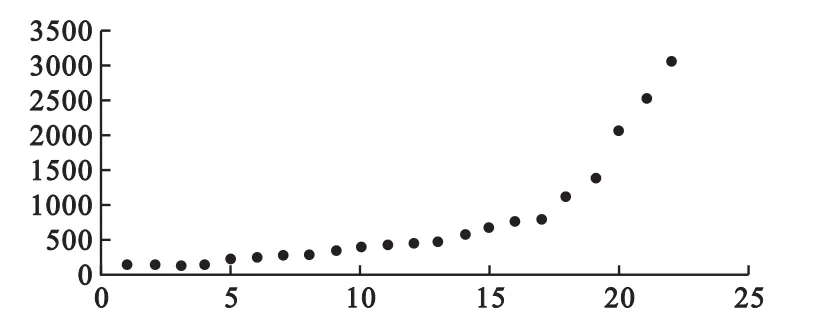
图1 医疗卫生服务支出时序演化
1.GM(1,1)预测。借助excel或MATLAB软件计算实现。将1990-2011年数据组成序列{x(0)},累加计算序列{x(1)}和均值序列{z(1)},最后计算参数a=-0.193056,b=-42.2857。得到序列{x(1)}拟合模型依次回代数值k,并累减还原为拟合或预测值拟合与原始序列x(0)不相符,拟合失效。重新以1990年-2000年早期较平缓数据建立拟合模型-956.9024,经比较与原序列拟合尚可以。最后继续建立模型对少量近期强增长趋势数据拟合仍不太好。
2.SVM预测。借助Matlab软件Libsvm工具箱实现。SVM法是通过样本自组织训练反映时序延续规律及非线性联系。通过设置滑动窗将等间隔数据进行组对,顺次截取组成训练样本和映射关系f:{x(i),x(i+1),x(i+2)}→{x(i+3)},其中输出为x(i+3),输入为x(i),x(i+1),x(i+2)。将训练样本对分别演示如下:{122.86 132.38 144.77}→{164.81};{132.38 144.77 164.81}→{212.85};…;{1397.23 2081.09 2565.6}→{3111.36}。
训练完毕经对原始输入依次测试后得到仿真结果,经验证比较仿真误差几乎为零,说明SVM对训练集有极强“内插”能力再由输入{2081.09 2565.6 3111.36}外推预测值773,与实际差距太远。如果改变滑动窗设置映射f:{x(i),x(i+1)}→{x(i+2)}。重新训练SVM,经验证预测值与实际相差仍很大,滑动窗设置改变对结果影响不大。如调试参数重新训练SVM,结果变化敏感但预测值无法超过3000,与实际不符。原因是原序列训练后融入早期线性信息,对近期新趋势的外推不好但符合该方法原理特点。
3.拟合曲线预测。借助excel和SPSS软件实现。对原序列yt平滑处理后差分计算增长特征发现均与时序t有大致线性变化关系。又计算增长特征与时序t相关系数分别为r1=0.9501,r2=0.749,r3=-0.534。|r1|最大说明修正指数曲线为最优模型。然后用三和法识别参数,去除1990年数据后可将序列(共21个数据)等分为三段,计算参数得预测模型yt=132.5122+36.2046× 1.2417t。令t=21,带入计算2012年预测值3546.73。重取2003-2011年数据建立模型yt=513.7442+115.2188×1.4994t。令t=9计算2012年预测值4927.22,因近期少量数据突增起伏趋势,预测值大于实际值,小样本建模时外推结果受个别数据影响而敏感、不稳定。建模数据段须经调试以保证曲线适配所给该时段特点,该法解释性好但精度欠佳。
4.ARIMA预测。全步骤借助SAS软件编程实现。序列经二阶差分平稳化预处理消除趋势,并经过平稳性检验和纯随机性检验。设置自回归和移动平均最高阶数为5,分别建模后根据AIC、SBC或BIC信息量择优配置阶数,最优定阶q=4时信息量最小,AIC=241.34,SBC=245.32。LB,Q或DW统计量用于检验拟合效果。经残差自相关检验,延迟6阶、12阶和18阶,P值0.4509,0.9864,0.9998>0.05,经确认原序列信息已提取充分,ARIMA(0,1,4)表达式:(1-B)2xt=1-0.3016B+0.7922B2-0.6868B3+0.11B4。经分析模型拟合效果佳,对2012年外推预测值3556.7,与实际情况相符。
讨 论
1.卫生支出时序数据有早期长时平缓、后期起伏递增趋势,GM模型累加后无法拟合指数函数,截取近期强趋势数据后仍不好,对该类特点数据拟合性能不高,有选择性,尤为适配于数据少、贫信息、欠规则、随机时序数据特点问题[3]。
2.卫生支出时序数据SVM法建模时,顺次截取等数据段后,段前数据为输入,段后数据为输出,经反复训练计算,经外推仿真得预测值。数据有强趋势性,虽经参数调试优化,外推预测欠佳,该法未有效适配强趋势数据,预测应用代表意义不应夸大。
3.卫生支出时序数据有平缓光滑曲线增长趋势,类型多而须借助特征计算优选。鉴于对数据量要求低,不应全纳入,否则历史数据干扰近期信息描述力度,外推效果差。该法对趋势反映会过度敏感,引起曲线外推值过大,该法适于短期外推。
4.卫生支出时序数据有明显趋势,且观测期较长(数据丰富),可差分提取趋势信息后平稳序列以ARIMA法建模,算法复杂易实现。简言之,ARIMA法通用性强且长时数据优先应用,短时数据可选GM法,趋势数据可选曲线法,时序数据图预分析和方法性能特点综合论证后预测建模设计有科学性,探索应用对策有必要。
1.徐国祥.统计预测与决策.上海:上海财经大学出版社,2012.
2.王燕.应用时间序列分析.北京:中国人民大学出版社,2012,12:120-177.
3.周林.GM(1,1)模型预测肠道传染病发病趋势的应用.中国卫生统计,2013,30(5):715,718.
(责任编辑:郭海强)
*健康山东重大社会风险预测与治理协同创新中心项目(XT1401001-1401003);山东统计局项目(2014-184);潍坊市科技局项目(201301079)
1.潍坊医学院公共卫生学院(261053)
2.健康领域社会风险预测治理协同创新中心
3.健康山东重大社会风险与治理协同创新中心
△通信作者:张利平
猜你喜欢
数学杂志(2022年5期)2022-12-02
导航定位学报(2022年5期)2022-10-13
湘潭大学自然科学学报(2022年2期)2022-07-28
小猕猴智力画刊(2022年3期)2022-03-28
今日农业(2021年19期)2022-01-12
环境保护与循环经济(2021年7期)2021-11-02
新世纪智能(数学备考)(2021年5期)2021-07-28
电子产品世界(2021年6期)2021-02-10
铁道建筑技术(2020年11期)2020-05-22
电子制作(2017年13期)2017-12-15
