
基于朴素贝叶斯的垂直搜索引擎分类器设计
2015-06-24 14:42于秀丽王阳齐幸辉
无线电工程 2015年11期
于秀丽,王阳,齐幸辉
(1.天津科技大学,天津 300222;
2.河北远东通信系统工程有限公司,河北 石家庄 050200)
基于朴素贝叶斯的垂直搜索引擎分类器设计
于秀丽1,王阳2,齐幸辉2
(1.天津科技大学,天津 300222;
2.河北远东通信系统工程有限公司,河北 石家庄 050200)
随着互联网的网页数量呈现爆炸式增长,传统的通用搜索引擎越来越遭人诟病,查询不准、深度不够等问题,使用户倍感烦恼。因此,针对特定行业的垂直搜索引擎逐渐兴起,与之相关的研究也日益受到重视。网页分类是垂直搜索引擎的基础和难点,分类器的好坏直接决定了一个垂直搜索引擎系统的性能。基于朴素贝叶斯的垂直搜索引擎分类器通过CHI方法进行特征提取,利用朴素贝叶斯模型对从互联网爬取的网页按内容类别进行分类。实验结果表明,该分类器对网页分类有着良好的表现,为构建大型专业的垂直搜索引擎系统奠定了一定的理论基础。
朴素贝叶斯;垂直搜索引擎;特征提取;文档分类
0 引言
所谓垂直搜索引擎,是针对某一个行业或类别的专业搜索引擎,其特点是“专、精、深”,且具有行业色彩,相比传统通用搜索引擎的海量信息无序化,垂直搜索引擎则更加专注、具体和深入[1]。
2006年以来,国内垂直搜索引擎与相关行业相结合,在IT信息、房地产、招聘、购物和医疗等方面发展迅速。但与国外相比,无论是在技术层面还是在行业经验上都还有很大差距,这大大限制了垂直搜索引擎的发展,使得专业化搜索服务还无法在社会的各个领域得到广泛发展[2]。因此,加大对垂直搜索引擎的研究有着重大的现实意义。
而网页分类是垂直搜索引擎的基础和难点,分类器的好坏直接决定了一个垂直搜索引擎系统的性能[3],进而决定了所占市场的比例。本文利用CHI算法进行特征提取,以朴素贝叶斯算法为基础,构建了一个以网页分类为目标的垂直搜索引擎分类器,并对其准确率和招回率进行了详细的研究和分析。结果证明基于朴素贝叶斯算法的分类器对网页文类有着良好的表现。最后,利用Java、JS等Web开发语言和开源的Luence搜索引擎工具包[4],构建简易的基于BS架构的垂直搜索引擎系统。
1 关键技术
1.1 CHI特征选择法
利用CHI方法选择文本的特征是基于如下假设:在指定类别文本中出现频率高的词条与在其他类别文本中出现频率高的词条,对判定文档是否属于该类别是有帮助的[5]。
单词term与类别class依赖关系的CHI统计公示如下:
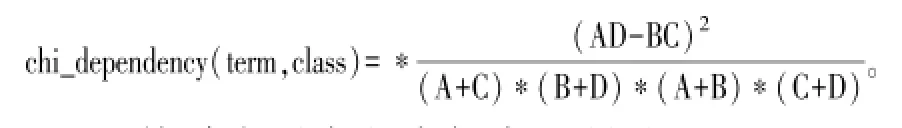
CHI统计变量定义表如表1所示。
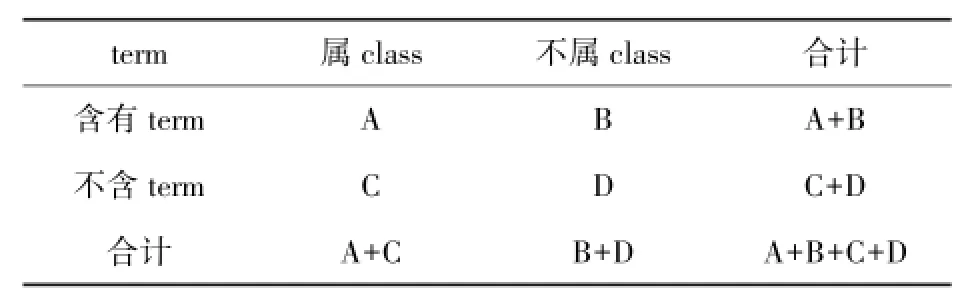
表1 CHI统计变量定义
类别class越依赖于单词term,则CHI统计值越大。如果term和class是相互独立的,则该值接近于0。
1.2 朴素贝叶斯模型
在人工智能领域,贝叶斯方法是一种非常具有代表性的不确定性知识表示和推理方法。简单地说,贝叶斯定理是基于假设的先验概率、给定假设下观察到不同数据的概率,提供了一种计算后验概率的方法[6]。
对朴素贝叶斯算法定义如下:
①设X=[a1,a2,…an]为一个待分类项,每个ai都为X的一个特征属性,而且每个特征属性都是相互独立的;
②设C=[y1,y2,…yn]为一个类别集合;
③计算P(y1|X),P(y2|X),P(y3|X),…P(yn|X)。
④P(yk|X)=max{P(y1|X),P(y2|X),P(y3|X),…P(yn|X)},则X∈yk。
2 垂直搜索引擎分类器的构建
本文以从搜狐网爬取的IT、招聘、体育和军事类网页作为训练集和测试集,利用朴素贝叶斯方法构建垂直搜索引擎分类器,对网页进行分类。
2.1 特征选取
首选通过CHI特征提取法获取每种类别的网页所具有的文本特征。设C、M、S和W分别代表IT类、招聘类、体育类和军事类。以体育类为例,特征选取流程如下:
①构建训练数据集:从网上爬取此种类别的网页N篇作为训练数据集。此处的N应尽量大,使其能够充分挖掘该类别的内容特征[7]。选取权威网站上IT、招聘、体育和军事行业网页各100篇,作为网页的原始训练数据集。
②去噪处理:将训练数据集中的网页进行去噪处理,即去除网页中与内容无关的Html标签和JavaScript代码,获取代表实质内容的中文段落。
③分词处理:将获取的中文段落划分成一个个分词,并且将其中无意义、明显不能作为特征的词去掉,如“的”,“是”,“或者”等等。
经过以上处理,数据集中包含大量文字的网页已经被用一个中文分词集合表示,如某体育类网页可以表示成Si=[体育、NBA、比赛、骑士、凯尔特人、詹皇、速贷球馆……詹姆斯、季后赛、首发、投篮]。
将所有表示体育类网页的中文分词集合做合并运算,即SA=S1∪S2∪S3∪…Sn,则SA便是体育类网页的中文分词库。同理可以得到IT类、招聘类和军事类的中文分词库CA、MA和WA。设TA=SA∪CA∪MA∪WA,则TA为候选分类特征集合。接下来通过CHI统计公式获得类别的真正分类特征。
④设TA=[t1,t2,t3,…tn],依次计算TA中每个候选特征与体育类别S的依赖关系值chi_dependency(ti,S),取使chi_dependency数值最大的n项候选特征词汇组成数组SR,即SR=[sm1,sm2,sm3…,smn],则SR即为体育类的真正分类特征集合。
通过以上方法,可以依次获取IT、招聘、体育和军事类网页的真正分类特征集合,分别设为CR、MR、SR和WR。
2.2 根据分类特征进行分类
根据前文介绍的朴素贝叶斯分类器分类原理,需计算P(yi|X),以此来判断样本属于哪一个类别。由于X=[a1,a2,…an],每个ai都为X的一个特征属性,因此需计算每个特征属性对于该类的影响力。
通过前文的特征选取方法已经得到的体育类的特征集合为SR=[sm1,sm2,sm3…,smn]。由于篇幅的限制,在这里选取n=20即选取与类别最具有依赖关系的前20个中文分词作为类别的分类特征。通过计算,CR=[IT、互联网、网络、andoid、电商、虚拟、阿里巴巴、云计算、支付、…],MR=[招聘、简历、职位、薪资、企业、经验、岗位、行业、技术、…],SR=[体育、比赛、NBA、CBA、中超、亚冠、赛季、对手、欧冠、胜、…],WR=[军事、美国、武器、军方、导弹、战略、南海、解放军、击败、…]。设CMSWR=CR∪MR∪SR∪CWR,CMSWR中的每个分类特征将作为文档属性参与到分类过程中。
以之前的100篇体育类文档作为训练集,来计算SR中每个分类特征对类别的影响力。以“体育”为例,训练集中的100篇体育类文档中有89篇均包含“体育”,则包含“体育”的网页属于体育类的概率为89/100;
假设每个分类特征都是独立的,即出现在网页中的分词都是随机出现的。因此,
P(yi|X)=P(a1|yi)P(a2|yi)…P(an|yi)。
即假设有待测文本X=[a1,a2,…an],属于yi的概率为训练数据中各属性值出现的概率之积[8]。
2.3 分类示例
根据朴素贝叶斯算法定义,假设有类别C=[y1,y2,…yn],待测文本属于哪个类别的概率最高,就将该文本划分为那一类。
假设有网页文本TXT=“马云和王健林关于O2O又展开了一轮对掐,因为涉及电商核心价值,我认为两人在价值的判断上,是真掐,特别是马云,刀刀见肉。特别值得传统企业借鉴。阿里巴巴马云表示,互联网经济不是虚拟经济,互联网经济是实体经济与虚拟经济的结合体。互联网企业要活得好,就要提供普惠性技术。”
经统计,训练集与分类特征是否包含的数量关系如表2所示。
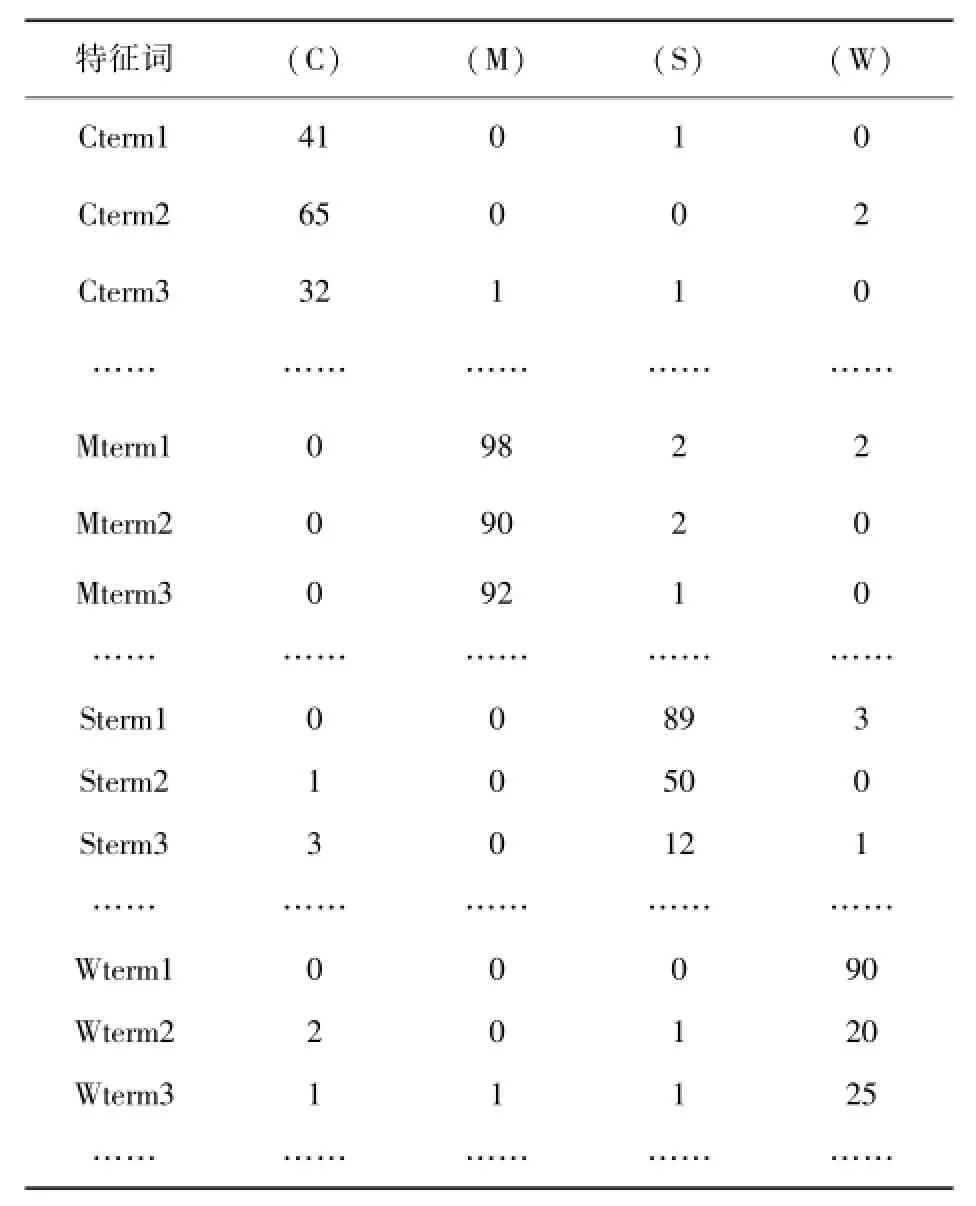
表2 训练集分类特征分布表
其中C、M、S、W分别代表IT类,招聘类、体育类和军事类。Ctermi、Mtermi、Stermi、Wtermi代表CMSWR中属于C、M、S、W的第i个分类特征。如第2行第2列的数字41代表IT类的第1个分类特征,即“IT”这个分词在100篇IT类网页中的其中41篇都出现了。
下面根据朴素贝叶斯算法依次计算网页文本TXT属于C、M、S、W的概率。
将文本TXT表示成一个向量TXT_V,长度为集合CMSWR的大小。向量中的项代表TXT中是否包含CMSWR的分类特征。以IT类为例,由于TXT中包含了“互联网”、“电商”、“虚拟”、“阿里巴巴”4个IT类的分类特征词汇,所以TXT_V=(互联网:1,电商:1,虚拟:1,阿里巴巴:1,网络:0,…,招聘:0;简历:0;公司:1;…体育:0;比赛:0;…军事:0;美国:0;…)。
将TXT_V中的每一项Ti作为文档的一个特征属性,指定一个类别,针对每一个特征属性Ti的属性值计算待测样本属于这个类别的概率Pi。Pi的计算方法为[9]:

设T的长度为len,则TXT属于某类别的概率为:
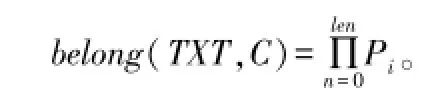
说明:之所以在计算Pi时分子加1/n,是为了防止某个属性值的概率出现0的情况。因为在计算belong(TXT,C)的时候,其他的概率将与这个0相乘,因此不管其他属性的概率有多大,最终的结果都是0,因此根据频率来计算概率的方法,进行一些小的调整,这种方法被成为拉普拉斯估算器[10]。
根据以上公式,分别计算文档TXT属于IT类、招聘类、体育类和军事类的概率,属于哪个类别的概率最高,就将TXT归为哪个类别。为了便于计算,将计算结果取对数得:
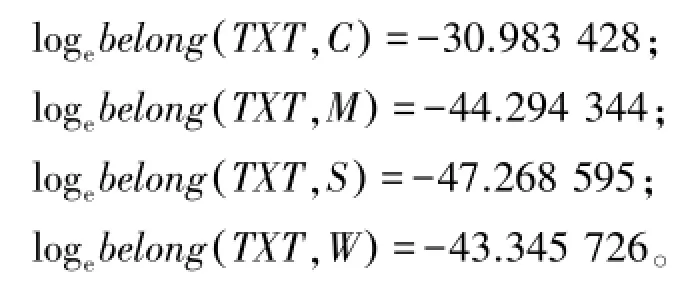
由以上计算结果看出,TXT属于类别C的概率最大,因此将文本TXT归为IT类。
3 分类结果与结论
3.1 实验结果
以不同于训练集的IT类、招聘类、体育类和军事类各100篇作为测试集,来验证朴素贝叶斯模型的分类效果。
经分析可得,分类特征作为判定是否属于某个类别的主要依据,分类特征的选取对于网页分类的效果有着至关重要的影响[11]。与类别最具有依赖关系的前20个中文分词未必能够代表该类别的内容特征,因此在测试过程中,分别选取n=20、n=30和n=50,来验证分类效果。
通过正确率和召回率来量化实验结果[12],具体数据如表3所示。
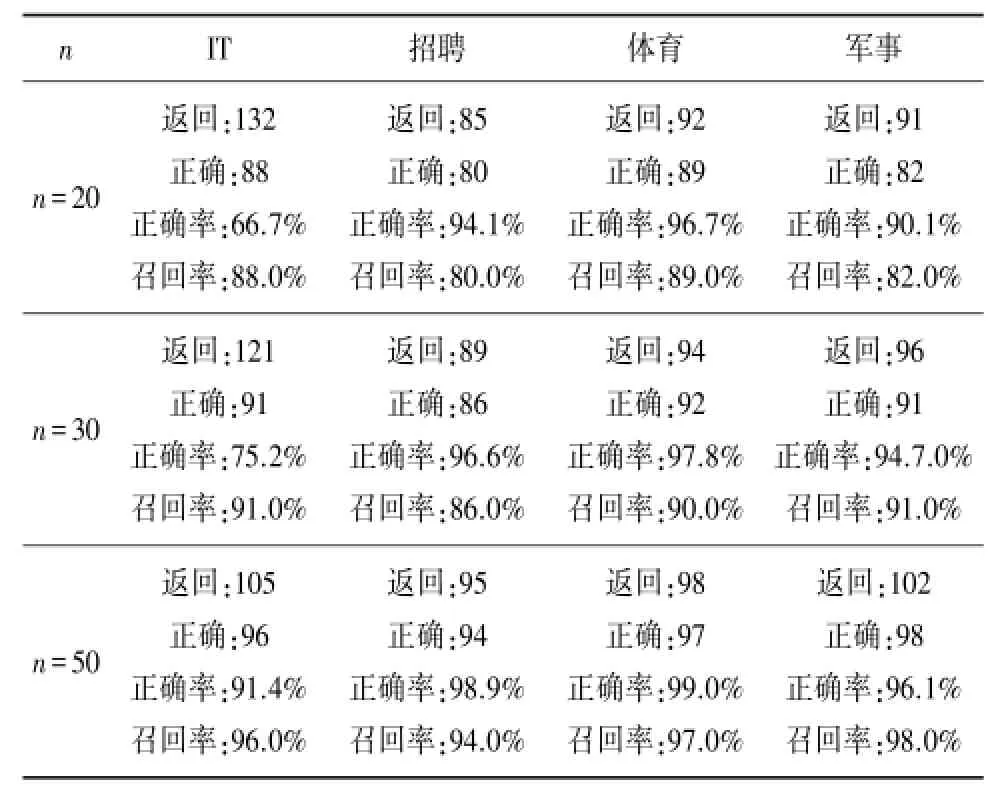
表3 统计结果
3.2 实验结论
根据表数据,可得如下结论:
①当n=50时,统计结果的准确率和召回率都在90%以上,足以说明利用朴素贝叶斯模型进行网页分类是可行的。
②当n=20时,IT类统计结果的正确率只有66.7%,且返回样本数高达132,可知其他类别中往往包含IT类的特征词汇。选出的分类特征区分度不够。
③分类特征的选取对于统计结果有着至关重要的影响[10],n越大,分类特征越能代表整个类别的特征,统计结果越准确。
4 构建简易垂直搜索引擎
有了以上的算法基础,便可以利用Java和JS等Web开发语言和开源的Luence搜索引擎工具包构建一个基于BS架构的简易垂直搜索引擎系统,过程如下:
①用Java编程语言编写网络爬虫,从互联网上抓取有效网页,并进行去重、去噪等处理。
②利用前文基于朴素贝叶斯算法的分类器对抓取到的网页按类别分类。
③利用Luence搜索引擎开源包,为分好类的网页建立索引,将其存储至数据库,并实现排序算法。
④Tomcat服务器搭建B/S环境,利用js和HTML语言编写客户端界面,根据用户输入的类别和关键字展示搜索结果。
5 结束语
介绍了基于朴素贝叶斯模型的垂直搜索引擎分类器的实现算法,实验表明在根据类别进行网页分类的过程中有着良好的表现[13],为构建大型专业的垂直搜索引擎奠定了一定的理论基础。垂直搜索引擎是传统搜索引擎的升级和延伸,是对网页库中某类信息的又一次整合。相信在不久的将来,越来越多的科技工作者会投入到垂直搜索引擎的研究中来。而采用更多数据挖掘的方法,对互联网网页进行有效处理,提高分类的准确度和速度,则是垂直搜索引擎研究的方向[14]。
[1]胡永锋.浅谈垂直搜索引擎的工作原理[J].科学大众(科学教育),2011(6):171.
[2]王文钧,李 巍.垂直搜索引擎的现状与发展研究[J].情报科学,2010,28(3):477-450.
[3]张红斌,曹义亲.混合多层分类和朴素贝叶斯模型的垂直搜索引擎分类器设计[J].现代图书情报技术,2011(3):73-79.
[4]任晓娜.基于Lucene的全文搜索引擎的研究与实现[J].湖北广播电视大学学报,2010,30(5):158-159.
[5]罗 刚,王振东.自己动手写网络爬虫[M].北京:清华大学出版社,2012.
[6]HAN Jiawei,KAMBER Micheline,PEI Jian.数据挖掘概念与技术[M].北京:机械工业出版社,2012.
[7]石志伟,吴功宜.改善朴素贝叶斯在文本分类中的稳定性[C]∥NCIRCS2004第一届全国信息检索与内容安全学术会议论文集,中国上海,2004:143-152.
[8]WITTEN Ian H,FRANK Eibe.数据挖掘实用机器学习技术[M].北京:机械工业出版社,2012.
[9]王树文,郑阔实,陈静博.面向教育主题的垂直搜索引擎的设计与实现[J].长春师范学院学报(自然科学版),2013(2):40-43.
[10]余 芳,姜云飞.一种基于朴素贝叶斯分类的特征选择方法[J].中山大学学报(自然科学版),2004,43(5):118-120.
[11]菅小燕,崔彩霞.基于朴素贝叶斯的文本分类[J].电脑开发与应用,2013(12):58-59.
[12]卢 苇,彭 雅.几种常用文本分类算法性能比较与分析[J].湖南大学学报(自然科学版),2007(6):72-74.
[13]李静梅,孙丽华,张巧荣,等.一种文本处理中的朴素贝叶斯模型[J].哈尔滨工程大学学报,2003,24(1):71-74.
[14]余 淼,杨 丹,赵俊芹.垂直搜索引擎的关键技术研究[J].软件导刊,2007(23):31-33.
Design of Vertical Search Engine Classifier Based on Naive Bayes
YU Xiu-li1,WANG Yang2,QI Xing-hui2
(1.Tianjin University of Science and Technology,Tianjin 300222,China;2.Hebei Far East Communication System Engineering Co.,Ltd.,Shijiazhuang Hebei 050200,China)
Along with the explosive growth of Internet pages,traditional universal search engines are more and more complained for problems such as inaccurate search and insufficient depth.Therefore,vertical search engine for special industries gradually emerges,and the associated researches attract more and more attention.Internet page classification is the basis and difficult point of vertical search engine.The quality of the classifier directly determines the performance of a vertical search engine system.The vertical search engine classifier based on naive Bayes extracts the features through CHI method,and then by using the naive Bayes model,it classifies the pages crawled from the Internet according to the contents.The experimental result shows that such classifier has good performance in classifyingInternet pages,which provides certain theoretical foundation for the construction of large-scale vertical search engine system.
naive Bayes classifier;vertical search engine;featureextraction;document classification
TP391
A
1003-3106(2015)11-0013-04
10.3969/j.issn.1003-3106.2015.11.04
于秀丽,王 阳,齐幸辉.基于朴素贝叶斯的垂直搜索引擎分类器设计[J].无线电工程,2015,45(11):13-16,25.
于秀丽女,(1976—),讲师。主要研究方向:计算机智能计算。
2015-08-06
齐幸辉男,(1977—),高级工程师。主要研究方向:信息通信技术。
猜你喜欢
今传媒(2022年12期)2022-12-22
山西教育·招考(2021年8期)2021-12-17
小资CHIC!ELEGANCE(2021年36期)2021-10-15
活力(2021年6期)2021-08-05
四川文学(2020年11期)2020-02-06
当代陕西(2019年23期)2020-01-06
山西教育·招考(2019年10期)2019-09-10
当代陕西(2019年9期)2019-05-20
中国卫生(2015年12期)2015-11-10
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06
