
CbRouter:一种利用交叉开关旁路的双向链路片上网络路由器*
2015-07-10 01:11董德尊王克非
计算机工程与科学 2015年2期
方 磊,董德尊,吴 际,夏 军,王克非
(国防科学技术大学计算机学院,湖南 长沙 410073)
1 引言
未来片上多核体系结构的发展需要片上互连网络NoC(Network-on-Chip)提供更高的通信带宽、更好的可扩展性。片上网络技术的发展面临的一个主要问题是怎样有效利用片上网络所提供的带宽资源[1]。片上网络的带宽资源可分为两类,一类是路由器内部带宽资源,另一类是路由器外部带宽资源[1]。内部带宽资源的高效利用可以采用高效的路由算法[2,3]、先进的流控机制[4]等来实现。在普通的片上网络中,外部带宽资源是由连接路由器之间的两条单向链路带宽所决定的,通常每一条链路只传输一个方向的数据报文。研究发现[5],网络流量在网络中通常不对称分布[6],导致两个相连路由器之间在多数情况下仅会出现单向传输的情况,这造成另一条负责反方向传输的链路常处于空闲状态,链路带宽资源得不到充分的利用。图1是我们利用BookSim[7]模拟器对4×4的Mesh网络测试不同的合成负载所获得的链路平均利用率的统计结果。可以看出,在uniform流量模式下,链路带宽资源利用相对较为平均,链路的平均利用率能达到60%左右,然而在transpose流量模式下,链路的平均利用率的差异尤为巨大,甚至多条链路始终处于空闲状态。

Figure 1 4×4 Mesh network link utilization(the deeper the color the link utilization ratio is lower)图1 4×4 Mesh网络链路利用率(颜色越深链路的利用率越低)
为了实现链路资源的动态分配,将链路资源按需分配,文献[5,8,9]等提出了各自的链路方向调度机制。目前,双向链路调度的难点是怎样在长传输报文的路径中进行尽可能多跳的双向通道传输,建立端到端之间的数据传输通道,以减少局部单条链路传输对缓冲区带来的压力。在之前的研究中,只针对单跳路由器进行双向通道分配策略制定,而没有全局进行链路带宽资源分配以实现在数据包的整个路径上调度链路资源。
本文中,我们首次尝试在数据包的端到端多跳传输路径上实现双向链路调度机制,尽可能为端到端的传输建立更多的双向链路通路。我们提出了一种全新的双向链路调度算法,该算法与已有的各种调度算法的关键不同之处在于,路由器的每一个端口均设置了一条享有最高输出使用权的输出主通道,路由器使用自己的输出主通道无需申请,同时还设置了一条和主通道对应的输出副通道,其使用只需要简单查询即可。
本文提出了一种低开销的路由器内部通路动态加宽机制。为了实现端到端的多跳双向链路通路,需要加宽该路径通过路由器时的传输通路,否则标准的路由器通路将成为带宽瓶颈。在已有的双向链路方案中,无一例外均在路由器内部使用了输入端口加速(Speedup)和交叉开关加速的方法。根据已有的相关研究成果[9,10],交叉开关以及输入缓冲的面积和功耗往往占据了NoC路由器面积和功耗的90%以上,如果选择增加交叉开关端口数,端口数由n变为2n时,交叉开关的面积将由n2变成4n2,这些机制还将面临链路两头的切片重排序问题。而且,双向通道的同时同向传输并不是在多数情况下出现,这就会造成预置的多余资源多数时间处于空闲状态。我们根据相关旁路设计思想[11],在原有交叉开关数据通路之外重新设置一条低开销的旁路数据传输通道。该数据通路能够允许数据不经过开关仲裁只需一个时钟就能路由通过,并将该通路命名为快速通道FC(Fast Channel)。
我们在片上网络模拟器BookSim[7]上实现了本文所设计的双向链路路由器,并在Mesh网络中评估了双向链路路由器的性能,网络模拟的结果显示,使用该双向链路路由器比使用一般的单向链路路由器能提高60%左右的网络吞吐率。通道平均利用率能够得到20%以上的提升。
2 研究背景
提升片上网络的性能有两种方法,一种是提供更多的网络资源,第二种是高效地利用片上网络已有的资源。第一种方法,在面积、功耗等日益受限的情况下变得越来越不可取。据相关研究,片上网络已经占据了芯片功耗的30%左右[10],因此必须研究各种能够更加高效地利用片上网络资源的方法。
链路资源同片上网络路由器中的其他带宽资源一样,对网络性能的提升至关重要。在芯片日益微小化的未来,硅片面积资源将变得十分紧缺,然而在采用片上网络的片上多核体系结构中,更多的连线将带来更复杂的布线工作,同时系统也将变得更加脆弱。并且,如图1所示,目前一般的单向链路路由器所组成的网络中,即使在网络达到饱和的情况下,链路资源的利用率平均最高只能达到60%,网络中的链路资源在很多流量模式下处于严重的使用不平衡状态。目前已有相关研究链路带宽资源动态调度。
文献[8]首次提出了一种双向链路的动态调度方法。它在一条链路的两头分别设置一个拥有三种状态的有限状态机FSM(Finite Stete Machine)以控制链路的传输方向。该机制是一种基于申请和应答的方法,链路两头的路由器分别通过一条信号线向另一头的链路控制FSM请求链路使用权。由于需要等待应答,这种方法中状态机由输入状态向输出状态翻转必须由一个计数器来控制,该计数器记录未收到输入请求的时钟数,这使得链路常需要至少四个时钟周期才能改变传输方向,并且这种调度方法将会出现两条链路均向一个方向传输而另一方向的数据包需等待链路可用的情形。文献[9]提出了一种更加细粒度的通道资源分配机制,它将数据切片分成更小的传输单元phit,将链路分成更小的多条lane。以链路两头的请求数量来按一定的比例分配带宽资源,即lane的数量。该方案中数据切片在链路的两头需要复杂的flit切分与组装机制,这不仅增加了数据包的网络延迟、又需要输出缓冲,大大地降低了资源的利用率。除此之外,文献[5]也提出了类似于文献[8]的双向通道方案。这些方案具有共同的特点,即都加宽了基础路由器的原有数据通路,例如交叉开关的带宽、输入缓冲区带宽等,基于请求应答的通道调度不能有效保障服务质量的同时,还给链路方向转换带来了不必要的等待时间。
基于上述背景,本文设计了一种新的双向通道调节机制,该机制不需要请求应答。每条双向链路仅需一条传输电平信号的信号线就已足够交互链路使用信息。路由器为每个输出端口均设置了一条叫做输出主链路的双向链路,路由器对自己的输出主链路享有最高的使用权限,这样保证了路由器随时可以使用链路发送数据包。为了支持两倍链路带宽,该设计不加宽路由器内部交叉开关的带宽,而是采用旁路的思想,设置一条不需要经过原有交叉开关的通道——快速通道,该通道动态连接输入端口和可用的输出副链路。由于采用了一种简单的查询机制,不需要复杂的仲裁,使用该通道的切片仅需要一个周期便能够从输出副通道流出。并且,该路由器的快速通道调度机制利用了一定的全局信息,提升双输入端口的优先级,使得使用两条链路同向传输的数据包将会有更大的概率再次使用两条同向传输,该数据包的传输路径上将会建立更长的两倍带宽。
3 详细设计
本节将基于Mesh网络拓扑讨论本文所设计路由器的详细构造和工作机制。并以文献[1]所提出的虚通道片上网络路由器为基础。该路由器拥有四级流水线,分别是路由计算(RC)、虚通道分配(VA)、开关分配(SA)以及交叉开关通过(ST)阶段。每一级流水线需要一个时钟周期。同时假设Mesh网络的链路延迟为一个时钟周期,并根据文献[1]将链路传输阶段记为LT。为了便于描述,首先将引入输出主链路和副链路的概念。然后基于这两个概念介绍链路方向调度算法。第3.3节将介绍快速通道的结构与工作原理,第3.4节将给出支持同时读取和写入两个数据切片的输入缓冲区结构以及流控。
3.1 输出主链路与输出副链路
一般的单向链路网络中,路由器之间由两条单向链路连接。图2是普通网络中相连的路由器A和B。路由器A的南输入端口与西输入端口竞争东输出,最终南输入端口建立了一条与东输出端口的虚链路连接。由于其余各端口无数据发送,链路C2等一直处于空闲状态。如果此时A能够利用空闲的输入链路C2作为输出链路,这将大大提高网络的性能。在图3中,路由器A、B之间的单向链路被双向链路所替代,并且路由器内部结构已经加上了支持利用双向链路的功能模块。
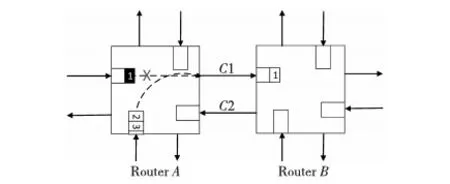
Figure 2 Unidirectional network图2 单向链路网络
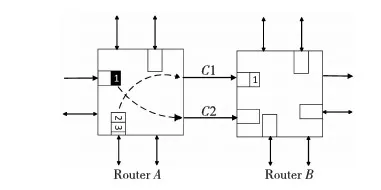
Figure 3 Bidirectional network图3 双向链路网络
路由器对端口间的两条双向链路的其中一条享有最高的输出使用优先权,并将此链路叫做该路由器的输出主链路,而另外一条只有在其空闲的时候才能用作输出的链路叫做输出副链路。为了简化链路方向调节机制,所有输出主链路空闲时均默认为输入状态,并通过多路选择器连接到对应的输入端口。在图3中,链路C1为路由器A的输出主链路,因为A需要使用输出端口,故将其传输方向改为输出;链路C2为路由器B的输出主链路、路由器A的输出副链路,由于路由器B的西向无数据需要输出,故A可以将其申请作为输出。在图3的情形中,路由器的东端口赢得了输出副链路,并通过链路C2建立了一条连接路由器B东输入端口的数据通路。
引入输出主链路和副链路机制保证了任何路由器在需要发送数据的时候均有链路可用,而无需等待链路空闲。当路由器的某端口同时收到两个数据切片,并且这两个数据切片均来自同一个数据包时,输入端口默认将输出副链路收到的切片放在输出主链路收到的数据切片之前。
3.2 链路方向控制协议
链路方向控制协议将根据输出请求和输出副通道的可用状态来调节链路的传输方向,是一种基于请求和查询的方法。
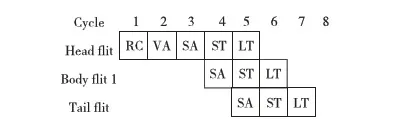
Figure 4 Pipeline of NOC router:RC(Routing Computation) VA(Virtual Channel Allocation),SA(Switch Allocation),ST(Switch Traversal), and LT(Link Traversal)图4 片上网络路由器四级流水线:RC(路由计算)、VA(输出虚拟通道分配)、SA(开关分配)、ST(开关通过)、LT(链路传输)
图4是经典路由器的四级流水线流程。数据包的头切片将经由RC、VA、SA和ST四个流水级再加上一个链路传输LT总共是五级流水才进入下一跳路由。在Mesh网络中,这通常需要五个时钟周期。在流水线的RC阶段路由器就能够知道该数据包所需的输出端口,基于信用的流控中,在SA阶段的末尾输入端口将检查相应端口的信用情况,确定是否可以申请交叉开关。
在本文所设计的协议中,链路方向的调整同样需要相连路由器之间交换有关链路的使用信息,与已有的方法相比,通道请求不再由输入端口发出,代替的是为每一个输出端口设置一个请求数寄存器来记录该输出端口的请求数量。路由器为每个输出端口的输出主链路设置一个方向控制器,该方向控制器监控输出端口请求寄存器中相应端口的寄存器值。同时也为输出副链路设置了一个方向寄存器,接收对方路由器输出主链路方向控制器所发出的电平信号。在已有的方法中,请求信号到达相连路由器的方向控制器需要两个时钟,然而在本文提出的信息传输由于方向控制器与输出请求并行工作,所以只需要一个链路延迟就能够将链路可用信息传递到相连路由器。
图5是本文所设计的链路接口逻辑框图。图中Main为输出主链路,Sub为输出副链路。VA、SA、ST表示数据切片经过的三个流水线阶段(没有画出RC)。输出副链路状态寄存器Dir_reg,输出主链路方向控制器Dir_controller,输出端口请求数寄存器 Outputs_req Register。输出主链路在输出空闲的时候均用作输入,而输出副链路在Dir_reg值为零时用作输出。链路方向控制的工作过程如下:在每一个头切片成功完成虚通道(VC)分配以后,对应的输出端口请求寄存器加1,输出主链路方向控制器(Dir_controller)一旦发现相应的寄存器值不为零,首先将data_out信号线拉高以通知相连路由器,并在两个时钟之后将方向设置为输出,因为两个时钟周期之后申请输出的数据切片刚好穿过交叉开关到达输出端口。只要输出端口请求数目不变为零,方向控制器一直维持端口的输出状态。为了降低硬件复杂度,同一个数据包只有在尾切片SA成功的时候才将输出端口的请求撤销,如果此时输出请求寄存器的值变成了零,输出主链路方向控制器将Data_out信号线拉低,并在两个时钟周期之后将主输出链路的方向设置为输入状态。在很大程度上路由器只负责调节自己各端口的输出主链路的传输方向。输出副链路的使用主要靠快速通道控制器来调度。
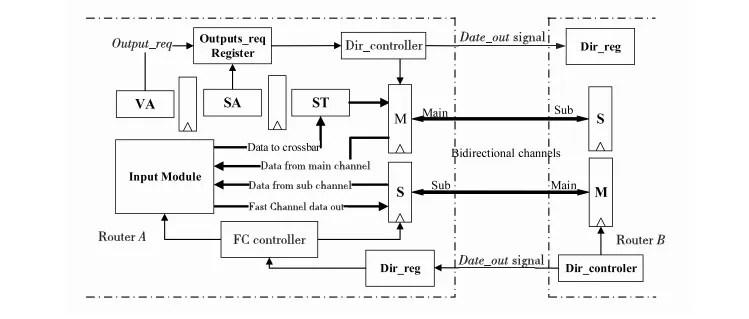
Figure 5 Bidirectional link scheduling interface图5 双向链路调度接口
3.3 快速通道
图6是本文所设计的交叉开关旁路结构框图,FC表示快速通道(Fast Channel)。假设该路由器有四个端口,输入端口缓冲的两个输出分别连接交叉开关和一个4到1的多路选择器,多路选择器的输出再连接到一个1到4的多路选择器。多路选择器的四个输出分别连接到每个输出端口的输出副链路。每一条VC分配成功的非空输入VC均可向FC控制器(FC Controller)申请快速通道的使用权,FC控制器根据输出副链路可用状态来屏蔽输出副链路不可用以及所申请的输出端只有一个待发送数据切片的请求。FC控制器每个时钟周期只选择一个请求。过程如下:
(1)首先确定输出副链路的可用状态,屏蔽不满足条件的申请;
(2)找到同时接收两个切片的VC(双输入VC),给予其最高的优先级;
(3)寻找双输入VC失败,找到输入缓冲占用率最高的VC,给予FC使用权;
(4)如遇到占用率相同的VC,选出输出端口最为拥挤的申请,即比较输出端口请求数。
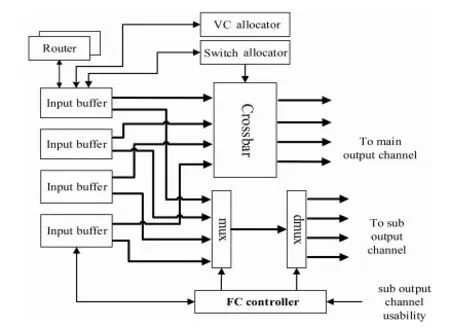
Figure 6 Crossbar bypass structure图6 交叉开关旁路结构框图
FC控制器将会利用各输出端口以及VC中的循环优先级寄存器来最终确定获胜的VC。通常在大部分情况下总能找到一个占用率最高的VC。为了在数据包传输的路径上可以使用更多的两倍带宽,所以如果某输入虚通道在同一时钟收到了两个数据切片,则增加其申请快速通道的优先级。这样在这个数据包的整个传输路径上将会有更多的机会形成一条更长的两倍带宽的路径,加宽端到端的链路带宽。同时给予较拥堵VC较高优先级,能加快其数据流出,这往往能够解决在单向链路网络中所遇到的链路拥塞问题。通过在模拟器上对各种方案进行对比,这样的方案能够获得最好的性能。
图7在一般路由器流水线的基础上展示了快速通道的操作时序。结合图5,它的工作原理如下:在cycle1时,路由器A收到了第一个数据包头切片并完成了路由计算,输出VC分配成功之后,在cycle2申请输出主链路,输出主链路方向控制器在cycle5将方向设置为输出。尾切片在cycle5Switch分配成功并将输出请求减1使得请求数变为0,输出主链路方向控制器在两个周期之后将链路设置为输入。链路另一头的路由器B,其FC控制器在cycle3检测出副输出通道可用,并让一个目的端口为该端口的切片flit1获得了快速通道的使用权而进入FC流水级,在cycle4使用副输出链路传输到路由器A中。在cycle4输出副链路不可用,flit2不能进入快速通道,直到cycle7收到输出副链路的释放信号。从框图可以看出,两个路由器对链路方向的调节可以使链路时分复用,高效地使用链路带宽资源。

Figure 7 Fastchannel operation timing sequence图7 快速通道操作时序
3.4 缓冲区管理及流控
(1)输入缓冲管理。有缓冲路由比无缓冲路由有无可比拟的性能优势,所以本设计仍然采用有缓冲路由器。双向链路路由器的输入缓冲必须支持同时写入和读取两个数据切片。参考文献[5]使用了类似参考文献[6]在异构片上网络中采用的将输入缓冲分成两部分的设计方法,在他们的基础上,本文设计了一种同样基于将缓冲分成两部分的组织结构。

Figure 8 Structure of input port图8 输入端口结构
图8a为双向链路路由器的输入缓冲结构。设每一个输入端口的VC数量为v,每个端口需要两个1到v的多路选择器,第一条连接到副输出通道(sub_out),第二条连接到主输出通道(main_out)。每一条VC需要一个组装器,用于将收到的切片写入缓冲区,组装器会将从副输出通道收到的数据切片放在主输出通道收到的切片之前。VC缓冲分成两部分,分别命名为主缓冲区和副缓冲区,数据包头切片只能存放在主缓冲区,数据包体切片依次交错存放在主副缓冲区中,如图中切片头切片a,体切片b、c、d、e和尾切片f。除了参考文献[1]中路由器输入端口VC所需要的几组标志寄存器外,增加一个标志位F,用于指示目前该VC中最靠前的切片是处于主缓冲区还是副缓冲区,F位为0表示最靠前切片位于主缓冲区,为1表示位于副缓冲区。增加标志位D指示该VC是否同时收到两个数据切片。当输入端口单独获得交叉开关或者快速通道的时候,只需要将标志位F所指定的缓冲区头切片发送出去即可。如果同时需要读取两个切片,则将最靠前的切片发送到Crossbar、将接下来的切片发送到快速通道。图8b为组装器的内部结构,它使用来自副输出链路的数据有效信号(Data_valid)和标志位F信号控制数据的写入位置。Main buffer和Sub buffer分别表示主和副缓冲区。
(2)流控。双向链路路由器的流控机制采用片上网络中常用的基于信用(Credit)的流控机制。由于快速通道和交叉开关并行工作,且有可能会同时传输同一数据包的两个切片,所以FC控制器需要两个信用才能向输出副通道发送数据。同时为每一条双向链路设置两条信用通道,分别用来传送相反方向的信用。路由计算模块等其他模块功能不变,并由它们解决诸如死锁避免等问题。相关内容请参考文献[2,3]等。
4 性能评估
4.1 实验设置
本文在片上网络模拟器BookSim[7]中实现了本文提出的双向链路路由器。实验使用的拓扑为Mesh。实验发现,在不同的路由器资源下性能提升具有相似的趋势,单一网络资源配置并未失去一般性,所以在此处本文的实验讨论的配置为:路由器每一个输入端口均有四个虚拟通道(VC),VC深度为8 flit。每个数据包由10个flit构成,每一个切片的大小为128 bit。Mesh网络使用DOR路由,采用基于信用的流控机制。一般路由器使用单向链路。实验评估了4×4 和 8×8两种不同网络规模下双向链路路由器的性能。同时,本文在一条交叉开关旁路的基础上又另外实现了一种拥有两条交叉开关旁路(即快速通道)双向链路路由器。每一个输入端口仍然最多只能同时发送两个数据切片。两条快速通道的实现中FC控制器采用了随机选择的方法。除此之外三种不同的路由器均采用相同的配置。
在已有的几种双向链路调度机制中,比如文献[5,8,9]等,它们均采用了直接加宽路由器内部数据通路的做法,比如加宽输入缓冲的带宽,同时加倍交叉开关的输入和输出端口数等。一方面,它们使用了比我们的方案更多的硬件资源和硅片面积,另一方面它们所使用的方案与我们的理念不同。比如文献[9]使用的是切片切分的方法。我们的方案是追求空闲资源的高效利用,并在一定程度上站在全局的角度调度双向链路的使用。所以,在性能比较方面,我们的方案与之前的方案没有直接比较的意义。但是,根据这些论文里面实验的设置来测试我们的设计发现,在同等设置条件下,我们的设计性能不低于上述设计方案。在实验中,我们采用了多种不同合成负载来评估各种配置网络的性能,由于篇幅所限,我们将重点讨论uniform、transpose、shuffle 流量模型下网络的性能。
4.2 实验结果
(1)网络吞吐率性能比较。
图9为4×4和 8×8两种不同规模的Mesh网络中网络性能的评估结果。Baseline表示使用单向链路的基础路由器,CbRouter-1fc表示一条快速通道的双向链路路由器,CbRouter-2fc表示拥有两条快速通道的双向链路路由器。由实验结果可以看出,在网络资源相同时,双向链路路由器在uniform流量模式下所获得的性能提升是三种流量下最少的,却仍然能够获得16.67%(4×4)和10.8%(8×8)左右的性能提升。因为uniform流量模式下,节点向网络中任意节点发送数据包可能性相同,各自输出主链路的空闲状态出现概率小,并且网络规模越大双向链路发挥的余地越少。然而,在大多数流量模式下双向链路路由器都能够发挥良好的性能。比如在transpose和shuffle流量模式下,与基础路由器相比,8×8 Mesh网络中一条快速通道能分别获得83.3%和73%左右的性能提升,饱和吞吐率差不多是基础路由器的两倍。
从实验数据可以看出,双向链路路由器在更大规模的Mesh网络中往往能够获得更好的性能,比如,transpose流量下一条快速通道在4×4 Mesh比基础路由器性能提升65.71%,在8×8 Mesh网络中能够获得73%的性能提升。这是因为,数据包在更大的网络中传输将会获得更多的机会,同时使用两条同方向传送的链路,而且越大规模的网络往往能够使更多的数据包使用空闲的输出主链路。这说明双向链路路由器具有良好的可扩展性。
同时,实验数据表明设置两条快速通道所获得的性能提升有限。在最好的shuffle流量模式下,两条快速通道最多也只能比一条快速通道性能提高8.23% 。因为在多数情况下并不会出现多个端口的输出副链路同时可用的情况。并且由于两条双向链路路由器的FC控制器需要更长的时钟周期来完成FC比较,加上需要更多的资源,导致其并不会有多大的优势。所以,一条快速通道将是资源效率折衷的最佳选择。
(2)通道利用率以及实现代价分析。
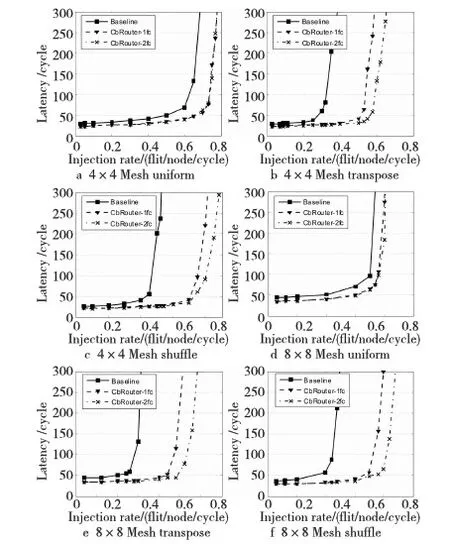
Figure 9 Latency versus injection rate results obtained by running uniform, transpose, shuffle traffics图9 uniform、transpose、shuffle流量模式下不同注入率与数据包延迟的对比曲线

Figure 10 Comparison of link utilization图10 链路平均利用率对比
图10为在4×4的Mesh网络中链路平均利用率提升对比结果。
对比结果显示,在uniform流量模式下通道平均利用率提升最小,只有8.43%,且两条快速通道和一条快速通道通道平均利用率相差不超过0.3%。在transpose和shuffle流量模式下通道平均利用率提升较大,均能提升18.77%~24.53%不等,这与网络性能的提升是一致的,因为链路的更高效利用往往能够带来更高的网络吞吐率、更低的数据包延迟。
(3)面积功耗开销分析。
同一般的单向链路路由器相比,我们的设计需要增加一定的面积功耗开销,这些开销主要来自交叉开关旁路和快速通道仲裁所需要的控制逻辑等所带来的面积功耗开销。根据上文的分析可知,交叉开关旁路通道中两个多路器所需要的面积与功耗开销一定会少于已有双向链路调度机制所需要的面积功耗开销,因为它们均采用了加倍交叉开关输入输出端口数量的方法。并且,根据第3节的分析可知,我们的双向链路调度机制能保证增加的资源处于较高的利用状态。分析可知,其他双向链路路由器为每个输入输出端口增加的带宽资源只有在同时使用两条双向链路的时候才发挥作用,然而无论在什么情况下,这些增加的带宽资源最大只能达到50%的利用率,比如在四端口路由器中两个端口输入和两个端口作为输出的情况。
5 结束语
本文为链路方向动态可调设计了一种新型的调度算法,并设计了对应的新型路由器。该双向链路路由器不是简单增加原有数据通道的带宽,而是在考虑链路资源和实现代价的基础上设计了一条叫做快速通道的数据旁路,该数据通路采用了一种简单的查询比较机制,从而能够使得数据切片只需要一个时钟周期就可以路由通过。同时,为了支持两个切片的同时读写,我们根据已有的相关设计提出了一种新的输入缓冲组织结构。综合流量模式下的模拟结果显示,本文所设计的双向链路路由器能够高效利用链路资源而获得较高的性能提升。本文中,我们只在Mesh网络上讨论了本文所设计的方案,但通过适当修改该方案也可以应用在其他网络拓扑中。
[1] Dally W, Towles B. Principles and practices of interconnection networks[M]. Burlington:Morgan Kaufmann Publishers Inc, 2003.
[2] Cho M H, Lis M, Shim K S, et al. Oblivious routing in on-chip bandwidth-adaptive networks[C]∥Proc of the 2009 18th International Conference on Parallel Architectures and Compilation Techniques, 2009:181-190.
[3] Zhen Z, Greiner A, Taktak S. A reconfigurable routing algorithm for a fault-tolerant 2D-Mesh Network-on-Chip[C]∥Proc of the 45th Conference on Design Automation, 2008:441-446.
[4] Chen L,Pinkston T M.Worm-bubble flow control[C]∥Proc of High Performance Computer Architecture, 2013:366-377.
[5] Qian Zhi-liang, Ying Fei Teh, Chi-Ying Tsui, et al. A flit-level speedup scheme for network-on-chip using self-reconfigurable bi-directional channels[C]∥Proc of Design, Automation Test in Europe Conference, 2012:1295-1300.
[6] Mishra A K, Vijaykrishnan N, Das C R. A case for heterogeneous on-chip interconnects for CMPs[C]∥Proc of the 38th Annual International Symposium on Computer Architecture, 2011:389-400.
[7] Jiang N,Becker D U,Michelogiannakis G,et al. A detailed and flexible cycle-accurate network-on-chip simulator[C]∥Proc of Performance Analysis of Systems and Software, 2013:86-96.
[8] Lan Ying-Cherng,Lin Hsiao-An,Shih-Hsin Lo,et al. BiNoC:A bidirectional NoC architecture with dynamic self-reconfigurable channel[C]∥Proc of the 3rd IEEE/ACM International Symposium on Networks on Chip, 2009:266-275.
[9] Hesse R, Nicholls J, Jerger N. Fine-grained bandwidth adaptivity in networks-on-chip using bidirectional channels[C]∥Proc of the 6th IEEE/ACM International Symposium on Networks on Chip, 2012:132-141.
[10] Moscibroda T, Mutlu O. A case for bufferless routing in on-chip networks[C]∥Proc of the 36th Annual International Symposium on Computer Architecture, 2009:196-207.
[11] Koibuchi M, Matsutani H, Amano H, et al. A lightweight fault-tolerant mechanism for network-on-chip[C]∥Proc of the 2nd ACM/IEEE International Symposium on Networks-on-Chip, 2008:13-22.
[12] Faruque A, Ebi M A T, Henkel J. Configurable links for runtime adaptive on-chip communication[C]∥Proc of Design, Automation Test in Europe Conference, 2009:256-261.
[13] Kim J, DallyW J, Abts D. Flattened butterfly:A cost-efficient topology for high-radix networks[C]∥Proc of the 34th Annual International Symposium on Computer Architecture, 2007:126-137.
[14] Dally W J, Towles B. Route packets, not wires:On-chipinterconnection networks[C]∥Proc of the 38th Conference on Design Automation, 2001:684-689.
[15] Michelogiannakis G,Balfour J,Dally W.Elastic-buffer flow control for on-chip networks[C]∥Proc of the High Performance Computer Architecture, 2009:151-162.
猜你喜欢
出版人(2022年11期)2022-11-15
科教新报(2022年24期)2022-07-08
中国药学药品知识仓库(2022年10期)2022-05-29
作文小学中年级(2021年10期)2021-12-26
科教新报(2021年23期)2021-07-21
原子与分子物理学报(2021年1期)2021-03-29
大众用电(2018年7期)2018-04-12
中国交通信息化(2016年8期)2016-06-06
通信电源技术(2016年5期)2016-03-22
电源技术(2015年9期)2015-06-05
