
压缩对Hadoop性能影响研究*
2015-07-10 01:11向丽辉张大方
计算机工程与科学 2015年2期
向丽辉,缪 力,张大方
(湖南大学信息科学与工程学院,湖南 长沙 410086)
1 引言
随着数据的高速增长,作为海量数据处理的代表性技术,MapReduce[1]思想越来越被重视。Hadoop作为MapReduce的一个开源实现,具有良好的扩展性和容错性,得到了广泛的研究与应用。然而,Hadoop在数据处理性能和效率方面与并行数据库相差甚远。根据一项实验表明:在100节点规模上处理简单查询,DBMS-X(DataBase Management System-X)平均比Hadoop快了3.2倍,基于列存储的数据库Vertica平均比Hadoop快了2.3倍[2,3];如果处理复杂的关联查询,数据库的效率比Hadoop高出一个数量级。如何在保持Hadoop高扩展性和高容错性等特点的前提下提升Hadoop性能,已经成为一个广泛关注和研究的问题。
现阶段Hadoop性能优化自顶向下主要包括以下四个方面:(1)优化Hadoop应用程序,如减少不必要的reduce阶段[4];(2)Hadoop自身的优化,主要包括参数调优[5~7]、优化调度算法[8]和日志监控[9];(3)优化Hadoop的运行环境,如操作系统的配置调优;(4)改善Hadoop运行的基础设施。目前Intel公司已在致力发展提高Hadoop性能的硬件设备,其中包括使用固态磁盘SSD(Solid-State Drive)技术[10,11]。
多年来,在磁盘存储容量快速增长的同时,磁盘I/O速度却未能成比例地加快;现有的网络带宽越来越难以满足人们的需求,I/O常常成为了磁盘与网络的性能瓶颈。以HDFS(Hadoop Distributed File System)作为分布式文件系统的Hadoop能实现PB级的海量数据存储,I/O问题更加明显,因此I/O操作的优化都有可能带来Hadoop性能的提升。在Hadoop中,由一组配置参数来控制I/O,如块大小、复制因子、压缩算法等。这些参数直接影响Hadoop 的I/O性能:块大小和内存分配对Hadoop性能影响并不十分明显[12];减少复制因子能大大减少集群的写操作[13],从而减少磁盘访问来提高Hadoop性能;压缩技术是提高文件系统效率的重要手段之一,并行数据库系统比Hadoop性能好很多的一个重要原因是使用了压缩。Intel内部测试表明:相比未压缩,使用LZO的作业运行时间减少60%[4]。从这些方面来看,压缩是Hadoop I/O调优的一个重要方法。

Figure 1 Flow diagram of MapReduce’s working图1 MapReduce执行流程图
目前,国内外关于Hadoop压缩的探讨,从作者所知的研究中,只有文献[12]。 文献[12]从一个能量角度评估了压缩的好处:通过对四种不同压缩比例的数据进行实验,得出一个以压缩比例为阈值的决策算法,该算法能平衡CPU代价和I/O收益,实现性能提升。但是,Hadoop输入数据的压缩比例是无法预知的,且未考虑压缩与具体应用之间的关系,也未考虑使用不同压缩算法。本文探讨在输入数据压缩比例未知的前提下,如何使用压缩来提高Hadoop的性能。
文章结构如下:第2节介绍了Hadoop以及Hadoop中的压缩机制,得出一个压缩使用策略。第3节搭建集群,对应用使用不同的压缩配置来验证策略的正确性,并探讨策略在不同的应用、不同的数据格式以及不同的数据规模中的可行性,总结出一个完整的压缩使用策略。最后,在以上两节的基础上,分析了该压缩策略的优劣,并给出展望。
2 介绍
2.1 关于Hadoop
Hadoop由Doug Cutting即Apache Lucene创始人开发,源于开源的网络搜索引擎Apache Nutch。用户可以在不了解分布式底层细节的情况下开发分布式程序。Hadoop实现了一个分布式文件系统HDFS和一个分布式计算模型Hadoop MapReduce。在分布式集群中,HDFS存取MapReduce需要的数据,MapReduce负责调度与计算。两者都是C/S(Client/Server)的服务模式:在HDFS中,Server为namenode,Client为datanodes;在MapReduce中,Server为master,Client为worker。后者的工作原理如图1所示[14]:用户程序首先产生一个master子进程和多个worker子进程;接下来master给各worker分配map任务,将map任务所需的输入块地址传给worker;worker从HDFS中读取相应的输入块,用户自定义的map函数会处理输入块,输出即中间结果存于本地磁盘;reduce阶段再通过网络读取相应的reduce输入,经shuffle/copy 以及sort后的数据由用户自定义的reduce函数处理,输出结果存于HDFS中。
2.2 Hadoop中的压缩
Hadoop通过参数配置来控制压缩,在配置文件core-site.xml、mapred-site.xml中,可以从以下三个方面来配置压缩:
(1)压缩对象:Hadoop允许用户压缩任务的中间结果或者输出,或者对两者都进行压缩。同时,Hadoop会自动检查输入文件是否为压缩格式,并在需要时进行解压缩。
(2)压缩格式:Hadoop支持的各压缩格式及特点如表1所示。
在Hadoop-0.20.203版本中,Hadoop自带三种压缩格式:Default、Gzip和Bzip2。Default 和Gzip[15]实现的是Lempel-Ziv 1977(LZ77)和哈夫曼编码相结合的DEFLATE算法,两者的区别在于Gzip格式在DEFLATE格式的基础上增加了一个文件头和一个文件尾。Bzip2[16]采用了新的压缩算法,压缩效果比传统的LZ77/LZ78压缩算法好。LZO(Lempel-Ziv-Oberhumer)[17]算法实现了以解压速度著称的一种LZ77变体,但LZO代码库拥有GPL的许可,因而未包含在Apache的发行版中,需要自行安装、编译[18]。是否包含多文件:表明压缩文件是否支持文件边界处分割,是否可包含一个或多个压缩文件,当前版本不支持zip,所以各压缩格式都不支持包含多文件。是否可切分:表示压缩算法是否可以搜索数据流的任意位置并进一步往下读取数据,它是处理海量数据时的一个重要属性。例如一个1 GB的压缩文件,如果该压缩文件使用的压缩算法支持可切分,块大小为64 MB,该压缩文件可分割成16块,每块都能由一个独立的mapper处理,从而实现并发。如果该压缩算法不支持可切分,该压缩文件只能由一个mapper串行完成。目前,Hadoop支持的压缩格式中:Bzip2 格式的压缩文件,块与块间提供了一个48位的同步标记,因而支持可切分;LZO格式的压缩文件,加索引后也支持可切分。
(3)压缩单元:Hadoop允许对任务的输出以记录或者块的形式进行压缩,块压缩效果更好。
2.2.1 各种压缩方式的性能
不同压缩方式有不同的性能表现,Hadoop中各压缩算法的性能表现如表2所示[19]。
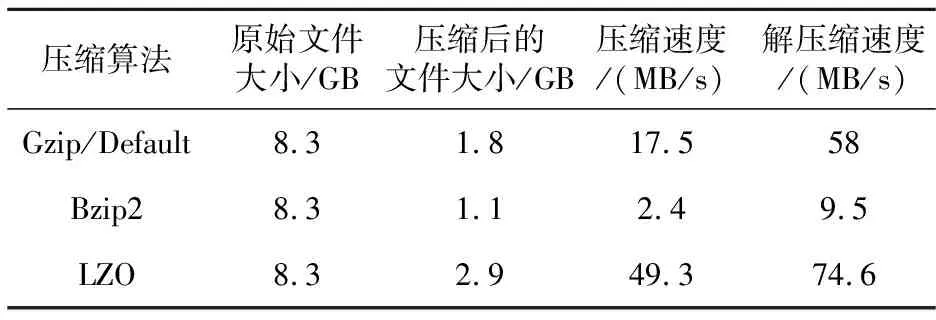
Table 2 Comparison of performance amongdifferent compression algorithms in Hadoop
从表2中可知:在空间/时间性能的权衡中,Gzip/Default居于其他两个压缩方法之间,LZO是最快速度压缩,Bzip2是最优空间压缩。
2.2.2 关于压缩的研究
目前,Hadoop 0.20.x和Hadoop 0.23.x是Hadoop版本的两个分支,其中CDH(Cloud Distribute Hadoop)版本从Hadoop 0.23.x发展而来,而Hadoop 0.20.x是当前的Apache系列[20]。CDH的版本中,Hadoop还支持snappy压缩算法[21],如需使用snappy压缩,只需调用snappy的压缩器/解压缩器即可。同时,数据压缩往往是计算密集型的操作,考虑到性能,常使用本地库(Native Library)来压缩和解压,这与HDFS的初衷不谋而合:移动计算要比移动数据便宜。Hadoop的DEFLATE、gzip和Snappy都支持算法的本地实现。
基于以上调研的启发,可以得出一个压缩使用策略,即LZO主要用于分布式计算场景,Bzip2主要用于分布式存储场景。对于压缩使用策略的正确性与可行性,以下以实验的方式对其进行验证补充。
3 实验
3.1 不同的应用与压缩的关系
3.1.1 任务和数据
实验选择了三个经典的Hadoop基准程序:即Grep、Wordcount和Terasort。这些基准程序都包含map阶段和reduce阶段,能充分体现压缩在各阶段的作用。同时采用由Teragen产生的10 000 000个记录(大小为1 GB)来进行实验。
对于每种压缩算法,它有多种设置。用0表示不压缩,1表示压缩,输入-中间结果-输出的配置有0-0-0、0-1-0、0-0-1、0-1-1这四种可能。其中0-0-1、0-1-1又可以分两种情况,因为输出结果的压缩类型分为block和record两种。每种配置情况下重复运行基准程序10次,取平均值做比较。
集群规模为4,尽管一个4节点的集群规模比较小。一项集群产品的调查表明:70%的MR集群包括不到50台机器,因此小集群上的发现很容易推广到更大规模的集群[22]。在本文中,性能是指各benchmark的反应时间。
3.1.2 不同的压缩配置
为了简化实验,除了复制因子为2,其他配置都采用默认配置。Teragen格式下,Grep、Terasosrt和Wordcount采用不同的压缩配置时运行所需的时间分别如图2~图4所示。其中有些算法未配置成0-0-1-r和0-1-1-r,因为实验需要的是最优压缩配置,如果0-0-1-b配置下平均运行时间比0-0-1-r配置下少,且0-1-1-b配置下平均运行时间比0-0-1-b配置多,为了简化实验,就不再对压缩方式采用0-1-1-r的配置。
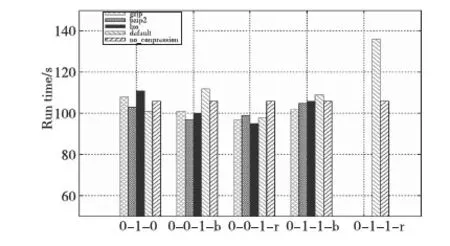
Figure 2 Performance impact of different compression algorithms on Grep图2 不同压缩算法对Grep的性能影响
图2显示,Grep应用的最优压缩配置方式为LZO-0-0-1-r,即使用LZO压缩算法对任务输出进行记录压缩时效率最高。
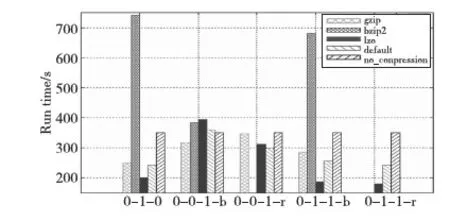
Figure 3 Performance impact of different compression algorithms on Terasort图3 不同压缩算法对Terasort的性能影响
从图3可知,Terasort应用的最优压缩配置方式为LZO-0-1-1-r,即使用LZO压缩算法对任务的中间结果和输出进行记录压缩时效率最高。图4表明,Wordcount应用的最优压缩配置方式也为LZO-0-1-1-r。
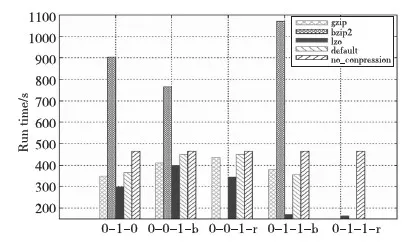
Figure 4 Performance impact of different compression algorithms on Wordcount图4 不同压缩算法对Wordcount的性能影响
比较各图,发现各应用使用合理的压缩配置后,性能提高了10%~65%,其中以Wordcount使用LZO压缩算法的表现最为突出。此外,对比HDFS读、HDFS写以及shuffle数据,虽然Bzip2情况下I/O最不紧张,但Bzip2压缩和解压缩速度慢,压缩产生的CPU代价大于压缩带来的好处。所以在效率方面,LZO最好,Gzip和Default次之,Bzip2最差。对于Terasort、Wordcount这些计算密集型的程序,使用Bzip2的时间是不使用压缩的两倍,但使用Bzip2压缩能节省约90%的空间。所以,压缩使用策略是正确的,同时记录压缩效率高于块压缩。
3.2 不同的数据格式对压缩的影响
Hadoop需要处理的数据类型很多,图5表示各基准采用由Teragen、Randomtextwriter和Randomwriter产生的1 GB数据作为输入后,使用最好压缩配置和不使用压缩的性能表现。
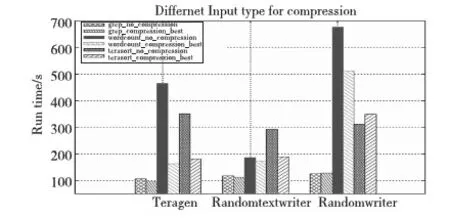
Figure 5 Performance impact of compression_best vs uncompression on benchmarks in different input types图5 不同格式下最好压缩与不压缩对各基准的性能影响
对于不同的数据格式,各benchmarks性能效率变化如表3所示。

Table 3 Change of Benchmarks’ performance efficiencyunder different data formats
从表3可以看出,三种不同的数据格式下,benchmarks在Teragen数据格式下性能提高得最多,Randomtextwriter次之,Randomwriter最差。若对Teragen、Randomtextwriter和Randomwriter生成的文件分别采用Gzip压缩,压缩比例分别为0.13、0.25、1。因而可以得知:随着压缩比例的增大,各benchmarks使用压缩的性能逐渐下降。其次, Randomtextwriter数据格式相比于Teragen:Grep和Terasort性能小幅度下降的同时,Wordcount性能降低了16倍,而Wordcount的输出减少了20倍。因为数据格式的不同,会使得同一应用的中间结果和输出不同,所以最好的压缩配置带来的效益也不一样。同样在Randomwriter格式下,Wordcount采用压缩性能提高了24%,而Grep和Terasort分别下降3%和12%,结合未压缩的输入和压缩后的输出,发现该数据格式下,采用压缩后Wordcount的输出约为输入的两倍。因此:不使用压缩时,若输出远小于输入,即使数据可压缩比例高,性能不会大幅度提升;当输出大于或等于同比例规模的输入且数据可压缩比例高,在本实验中性能可提高35%;即使数据可压缩性不高,如果输出大于输入的同比例规模,压缩也能提高性能。因此,压缩还是不压缩,输出大小是非常重要的,原因在于压缩的属性是针对中间结果和输出设置的。从输出大小可以判断中间结果的大小:如果输出规模大,reduce前的中间结果不会小。无论对中间结果还是输出进行压缩,需要一定的数据规模才能体现压缩的价值。而输出如何本质上由数据格式和Hadoop应用程序共同决定。
3.3 不同数据规模对压缩的影响
Hadoop通常处理的数据规模很大,压缩使用策略是否适用于大规模数据?图6是Wordcount运行由Teragen产生的1 GB、5 GB和10 GB数据的性能表现。实验环境为四个节点的集群,系统存储能力为70 GB,复制因子为1。从图6中可以看出:1 GB、5 GB和10 GB的数据,最好压缩配置使得程序运行的效率分别提高了53%、60%和55%。前两个数据规模之间,压缩带来的效率是成上升状态,原因首先在于数据规模越大,压缩的效果更加明显;其次,在数据增长的过程中,资源特别是CPU资源充足。后两个数据规模之间,压缩带来的效益有所下降,主要原因是数据增倍,压缩占用的CPU资源越来越多,集群资源出现了紧张状态。因此,数据规模在一定程度上能使压缩效益显著,但数据越大,压缩会占用更多的CPU资源,这样会降低压缩效益。
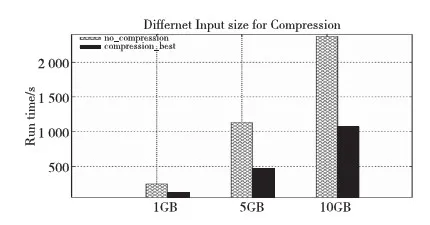
Figure 6 Performance of compression_best vs uncompression to Wordcount in different sizes图6 不同数据规模下最好压缩与不压缩对Wordcount的性能影响
3.4 压缩使用策略
通过实验,首先验证了压缩使用策略:即一个应用采用不同的压缩方式时,使用LZO压缩最好,因为LZO是当前最快速度压缩,Bzip2虽然压缩效果好,但压缩速度慢,所以Bzip2压缩算法适合分布式存储的场景,而LZO压缩算法适合分布式计算的场景;同时记录压缩比块压缩效率更高,虽然块压缩效果好,但速度慢;其次,不同数据格式代表不同的输入类型,输入的压缩比例越大,使用压缩带来的性能会逐渐下降,对于类似图片、视频、音频这些不可压缩的数据,使用压缩不一定能提高性能;对于不同的数据规模,发现数据规模越大,压缩的效益越明显,但数据规模增大到一定程度,压缩使用的CPU资源过多所以效益会下降;最后同一种压缩方式对不同应用的影响不同,因为不同的应用会产生不同数据规模的中间结果和输出,在Hadoop中,相对输入,对数据规模很少的中间结果和输出进行压缩是没意义的。
因此,得出以下压缩使用策略:首先,针对应用类型,若仅为存储,则使用Bzip2进行压缩存储,数据存储之后再用来计算的,则使用LZO压缩,并建立相应索引,虽然Bzip2也支持可拆分,但它的解压速度大大慢于LZO;若为计算型应用,则首选LZO。其次,输入数据的可压缩性是无法预知的,所以根据负载来进行判断:选取小部分负载,运行相应的程序,对于文本类型的输入,如果运行后它的输出大于输入,那么采用中间和输出都采用LZO压缩;如果输出远小于输入,再或者是图片、视频类型的输入,不建议采用压缩,同时在数据库中建立负载档案,将其压缩配置存于档案中,以便运行相同负载时使用;最后,计算应用场景中,首选记录压缩。由此可以非常简单地决定压缩或不压缩以及使用何种压缩。对Hadoop的sort基准使用该压缩策略,由于sort基准是计算类型的应用,所以选择LZO记录压缩,当输入是与图片压缩比例类似的Randomwriter随机数文件时,压缩策略为不使用压缩。实验表明:该策略比使用最好压缩配置的性能提高了26%。
4 结束语
本文分析了Hadoop文件压缩方式及其特点,得出一个压缩使用策略,通过实验分析了不同的文件压缩方式对Hadoop性能的影响,以及压缩使用策略在不同数据格式和不同的数据规模下的可行性,从而对压缩使用策略进行验证补充。虽然本文的实验结果很容易拓展到大规模的数据处理,但不同的应用使用压缩的表现不一样,同时未考虑对中间结果和输出分别采用不同的压缩算法进行测试。希望未来可以通过监控不同负载在Hadoop集群上的运行情况,分析压缩带来的CPU成本、量化压缩的代价和收益,得到一个决策算法来决定如何合理使用压缩。同时对已有的压缩算法进行改进:如LZO需要建立索引才能切分,则可以设计一个简化版的LZO算法,即使用定长的压缩块来避免建立索引的开销;或者研究双压缩策略,对存储类型的数据采用Bzip2压缩来减少空间,对计算类型的数据采用LZO压缩或者snappy压缩来提高速度。
[1] Dean J, Ghemawat S. MapReduce:Simplified data processing on large clusters [J]. Communications of the ACM, 2008, 51(1):107-113.
[2] Abouzeid A, Bajda-Pawlikowski K, Abadi D, et al. HadoopDB:An architectural hybrid of MapReduce and DBMS technologies for analytical workloads [J]. Proceedings of the VLDB Endowment, 2009, 2(1):922-933.
[3] Stonebraker M, Abadi D, DeWitt D J, et al. MapReduce and parallel DBMSs:Friends or foes?[J]. Communications of the ACM, 2010, 53(1):64-71.
[4] Xin Da-xin,Liu Fei.Hadoop cluster performance optimization technology research [J].Computer Knowledge and Technology, 2011, 7(8):5484-5486. (in Chinese)
[5] Herodotou H. Hadoop performance models [J]. arXiv preprint arXiv:1106.0940, 2011:1-16.
[6] Babu S. Towards automatic optimization of MapReduce programs[C]∥Proc of the 1st ACM Symposium on Cloud Computing, 2010:137-142.
[7] Herodotou H, Babu S. Profiling, what-if analysis, and cost-based optimization of MapReduce programs [J]. Proceedings of the VLDB Endowment, 2011, 4(11):1111-1122.
[8] Zaharia M, Borthakur D, Sarma J S, et al. Job scheduling for multi-user mapreduce clusters[R]. Berkeley:Technical Report USB/EECS,EECS Department, University of California, 2009.
[9] Boulon J, Konwinski A, Qi R, et al. Chukwa, a large-scale monitoring system[C]∥Proc of CCA, 2008:1-5.
[10] Claburn T.Google plans to use Intel SSD storage in servers [EB/OL]. [2008-07-02]. http://www.informationwee- k.com.
[11] Wong G. SSD market overview [M]. Netherlands:Springer, 2013.
[12] Chen Y, Ganapathi A, Katz R H. To compress or not to compress-compute vs. I/O tradeoffs for mapreduce energy efficiency[C]∥Proc of 1st ACM SIGCOMM Workshop on Green Networking,2010:23-28.
[13] Chen Y, Keys L, Katz R H. Towards energy efficient mapreduce [R]. EECS Department, University of California, Berkeley, Tech. Rep. UCB/EECS-2009-109, 2009.
[14] White T. Hadoop:the definitive guide [M]. California:O’Reilly Media, 2012.
[15] wiki. Gzip[EB/OL]. [2013-6-24]. http://zh.wikipedia.org/wiki/Gzip.
[16] wiki. Bzip2[EB/OL]. [2013-6-24]. http://zh.wikipedia.org/wiki/Bzip2.
[17] wiki. LZO[EB/OL]. [2013-3-12]. http://zh.wikipedia.org/wiki/LZO.
[18] Kevinweil.Hadoop/LZO[EB/OL].[2011-03-11]. https://github.com/kevinweil/Hadoop-lzo.
[19] Ggjucheng. The compressed file supported by Hadoop and the advantages and disadvantages of algorithm[EB/OL]. [2012-04-23].http://tech.it168.com/a2012/0423/1340/000001340446.shtml. (in Chinese)
[20] Hadoop A. Hadoop [EB/OL]. [2009-03-06]. http://hadoop.apache.org.
[21] wiki.Snappy[EB/OL].[2013-8-31].http://en.wikipedia.org/wiki/Snappy_%28software%29.
[22] wiki.Hadoop Power -ByPage [EB/OL].[2011-03-11]:http://wiki.apacheorg/Hadoop/Powered By.
附中文参考文献:
[4] 辛大欣, 刘飞. Hadoop 集群性能优化技术研究 [J]. 电脑知识与技术, 2011, 7(22):5484-5486.
[19] Ggjucheng.Hadoop对于压缩文件的支持及算法优缺点[EB/OL].[2012-04-23].http://tech.it168.com/a2012/0423/1340/000001340446.shtml.
猜你喜欢
铁道通信信号(2019年9期)2019-11-25
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
电子测试(2018年1期)2018-04-18
中国交通信息化(2017年3期)2017-06-08
电讯技术(2017年4期)2017-04-16
知识就是力量(2017年2期)2017-01-21
电测与仪表(2015年14期)2015-04-09
淮南师范学院学报(2015年3期)2015-03-22
集美大学学报(自然科学版)(2015年1期)2015-02-28
