
数据挖掘在电信客户细分中的应用研究
2015-08-02 01:54中国移动通信集团上海有限公司上海200030
山东工业技术 2015年9期
张隽(中国移动通信集团上海有限公司,上海200030)
数据挖掘在电信客户细分中的应用研究
张隽
(中国移动通信集团上海有限公司,上海200030)
摘要:电信企业在经营管理过程中积累了大量的客户信息,依据这些信息可以将客户划分为不同的群体,这就为企业实施精准化营销奠定了基础。本文对k-means聚类算法进行改进,利用遗传算法的全局优化特点,设计了自动确定聚类数、优化初始中心选取且消除噪声数据干扰的GK-means算法,构建了客户细分模型。最后,以以XX电信公司作为研究对象,构建其客户细分模型,依据客户细分结果分析了各个客户群体的特征,并针对性地提出了若干营销策略与建议。
关键字:客户细分;数据挖掘;K-means算法
0引言
在电信企业客户关系管理中,通过聚类等数据挖掘技术进行客户细分,然后归纳总结各个细分群体的特征,是提升营销效率及效果的有效途径。传统的客户细分通常是采用了定性的经营描述与定量的统计学相结合的方法。随着数字化信息的增长,数据挖掘(DataMining)技术被广泛应用于商业、金融业、企业生产以及市场营销等方面,它已逐渐发展成为一种智能过程,可以和信息技术、统计技术等一起支持运营决策。
1研究现状
数据挖掘作为一门交叉学科,在整个数据挖掘过程中需要涉及和利用多领域的知识,以高度智能化的在线分析企业数据库的信息,从大量的、混杂的原始数据中,提取出潜在的和有价值的信息的一个过程[1]。随着数据挖掘技术的进一步发展和完善,数据挖掘技术的应用越来越广泛,从最初的金融业拓展到现在的零售业、服务业等,在具体应用方面除了最初的价值评价,目前更多的用于顾客细分、识别潜在顾客等领域。数据挖掘应用于客户细分的相关研究中,Zakrzewska&Mnrlewski以银行积累的大量一手客户资料为分析对象,利用K-means方法进行客户细分,但是发现细分结果对于噪声数据的敏感性较强。Zamir&Etzioni分别利用K-means聚类,SOM和模糊K-means将股票操作者按照一定的标准如交易量、交易频率等进行了细分,发现模糊K-means的适用性最强、效果最好。
2客户细分算法
在众多的聚类算法中,由于k-means算法具有明显优于其他算法的特性,使得它获得广泛地应用。但是,k-means算法仍然存在明显的不足之处,需要相应的改进,才能有效地实现客户细分。
2.1k-means算法
k-means算法是一个经典的聚类算法,它是采用动态的聚类过程,通过一步步的迭代逐渐达到收敛,并最终实现聚类分析。总的来说,k-means聚类算法的基本原理是:先随机选取k个样本作为初始聚类中心,计算其他样本与这个k个初始聚类中心的欧式距离并相关比较大小,然后将各个样本归入与其距离最近的初始类中,接着再计算迭代后的各个类簇的中心点位置,并重复上述步骤,直至得到误差最小的聚类结果。
虽然k-means算法具有非常明显的优势,但是其仍然存在如下几点不足之处:(1)初始聚类中心的选取对于聚类结果影响比较大,不恰当的初始聚类中心可能会导致搜索不到最优解;(2)在使用k-means算法之前必须输入簇的数目k值,但是这k值通常是无法事前确定的,并且当k值的选取不适合时会导致聚类质量显著地下降,不具有分析价值;(3)k-means算法对于噪声数据与异常数据非常敏感,少量的“噪声”数据就可能导致聚类结果无法令人满意。故本文考虑采用遗传算法对k-means算法进行改进,提高算法的性能。
2.2初始中心的优化
由于传统k-means算法在选取初始中心的时候都只考虑距离因素,容易选取噪声点作为初始聚类中心,降级聚类质量,致使聚类结果难以令人满意,故现在同时考虑距离与密度因素来优化初始中心的选取,即选取相距最远的k个处于高密度区域的点作为中心点。̓̓
为此,首先将样本数据所处区域的密度定义为:̓̓
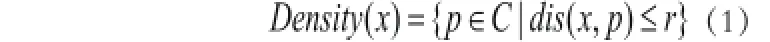
分析上述初始聚类中心的选取方法,其基本原理是选取欧式距离最大的高密度点集作为初始聚类中心,从而避免了选取的盲目性,保证了聚类质量。
2.3消除噪声和孤立点数据̓̓
在对数据所包含的信息进行分析的时候,不同的样本中所含有的信息量与价值不尽相同。为了对此加以区分,本文提出对每个样本数据赋予一个权值,其计算公式如下所示:
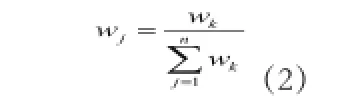
此处,为了减小“噪声”数据的负面影响,提高聚类质量,故提出加权平均的方法来计算各个类簇的均值,即:̓̓

上述加权平均法虽然会增加计算工作量,但是由于其能够有效地降低对噪声与异常数据的敏感性,即便是数据集中存在少量的噪声与异常数据也不会对权重的计算产生太大的影响。
3结论
本文研究综合运用了计算机信息技术、数据挖掘技术、管理学和市场营销学等多个领域的知识,并结合电信行业的具体行业特征,构建了基于数据挖掘的电信客户细分模型,将数据挖掘技术应用到电信客户细分中。为此,本文采用遗传算法对常用的k-means聚类算法进行改进,提出了基于GK-means算法的客户细分算法。最后,以XX电信公司作为研究对象,构建其客户细分模型,依据客户细分结果分析了各个客户群体的特征,并针对性地提出了若干营销策略与建议。
参考文献:
[1]ChenLD,SakaguchiT,FrolickMN.Dataminingmethods,applications,andtools[J].Informationsystemsmanagement,2000,17(01):1-6.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
九江学院学报(自然科学版)(2022年2期)2022-07-02
大众投资指南(2021年35期)2021-02-16
北京航空航天大学学报(2020年10期)2020-11-14
华人时刊(2020年23期)2020-04-13
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
电子技术与软件工程(2016年24期)2017-02-23
互联网天地(2016年1期)2016-05-04
专用汽车(2016年9期)2016-03-01
